SageDB: 一个自学习数据系统 Kraska et al., CIDR’19
一篇题为“学习型指数结构的案例”的论文(第一部分,第二部分)引起了很多兴奋和争论。今天的论文选择是建立在这个基础之上的,它提出了一个学习模型在数据库系统的各个方面渗透的愿景。
SageDB的核心思想是建立一个或多个关于数据和工作负载分布的模型,并在此基础上为数据库系统的所有组件自动构建最佳的数据结构和算法。这种我们称之为“数据库合成”的方法将使我们能够通过将每个数据库组件的实现专门化到特定的数据库、查询工作负载和执行环境来获得前所未有的性能。
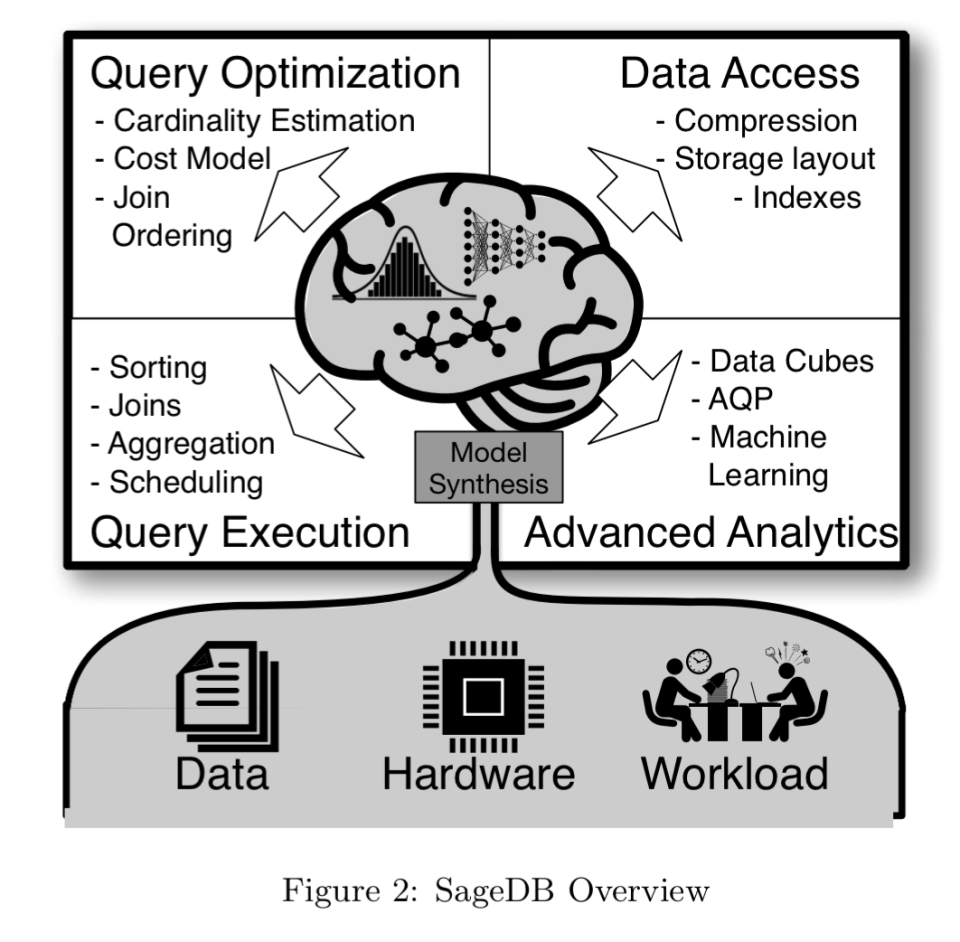
针对一个模型所必须的
在缺乏实时学习和适配的情况下,数据库系统是为通用目的而设计的,没有充分利用手头工作负载和数据的具体特点。SageDB的机会大小是这样一种方法与在充分了解数据分布和工作负载的情况下设计专业解决方案之间的差距。
考虑一个极端的情况:我们希望用连续整数键存储和查询固定长度记录的范围。在这里使用常规索引没有意义,因为键本身可以用作偏移量。一个C程序将100万个整数加载到一个数组中,并在一个范围内求和,大约需要300毫秒。在Postgres中执行相同的操作大约需要150秒:一般用途的设计需要500倍的开销。
…我们可以利用精确的数据分布知识来优化数据库使用的几乎任何算法或数据结构。这些优化有时甚至可以改变众所周知的数据处理算法的复杂性类别。
数据分布的知识以(学习)模型的形式出现。有了这样一个模型,作者认为我们可以自动综合索引结构、排序和连接算法,甚至整个查询优化程序,利用数据分布模式提高性能。
过度匹配是正确的
什么样的模型才有意义?例如,直方图是一个非常简单的模型,但是对于这里讨论的用例,要么太粗粒度,要么太大而没有用处。在频谱的另一端,深度和广度神经网络的成本很高(尽管随着硬件的进步,这些成本预计会降低)。结合这个事实,对于这个用例来说,“过度装配”是很好的!我们希望尽可能准确地捕捉精确数据的细微差别。(迄今为止的研究计划主要集中在分析工作负载上,一旦我们开始考虑更新,某种程度的概括显然是有益的)。
我们发现我们经常需要生成特殊的模型来看到显著的好处。
作为一个例子,考虑“学习型索引结构的情况”中的RMI模型:
- 在数据上拟合一个简单的模型(线性回归、简单的神经网络等)
- 使用模型的预测来选择另一个模型,一个专家,它更精确地建模数据的子集
- 重复这个过程,直到leaf模型做出最终预测
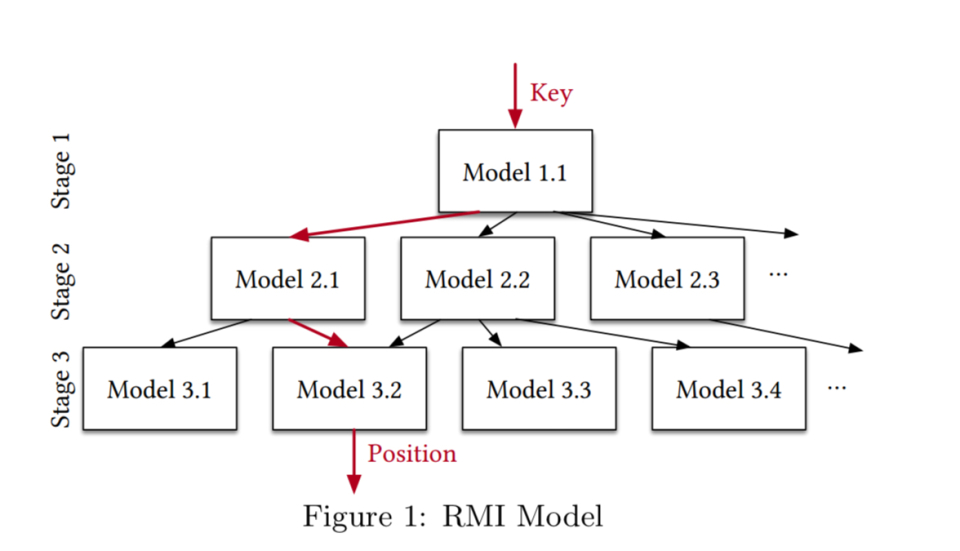
RMI只是一个起点。例如,可以使顶部模型或底部模型更复杂,用其他类型的模型替换特定级别阶段的部分模型,使用量化,改变特征表示,将模型与其他数据结构组合,等等。因此,我们相信,对于如何最有效地为数据库组件生成模型,以便在给定工作负载的精确性、低延迟、空间和执行时间之间实现正确的平衡,我们将看到大量的新想法。
数据存取
**
去年关于“学习型索引结构的案例”的论文表明,基于RMI的索引可以比最先进的B树实现性能提高两倍,同时具有更小的数量级(“注意,更新的arXiv版本包含了新的结果”)。随后的工作将此扩展到存储在磁盘上的数据、压缩插入和多维数据。
对于多维数据,基线是一个R树(与B树相反)。R树将矩形映射到索引范围列表,这样矩形中每个点的索引都包含在这些范围的并集中。我们可以用学习模型代替R-树,就像我们可以用B-树一样。使RMI B-树替换工作的技巧之一是,模型足以让我们“在正确的位置”,然后我们可以围绕预测进行本地搜索来完成这项工作。对于R树,我们还需要一个能够实现高效本地化搜索的布局。
虽然存在许多可能的投影策略,但我们发现,沿着维度序列将点依次排序和划分为大小相等的单元,会产生一种高效计算、可学习(例如,与非常难学习的z顺序相反)和紧凑(即。,索引范围并集中的几乎所有点都满足查询)。
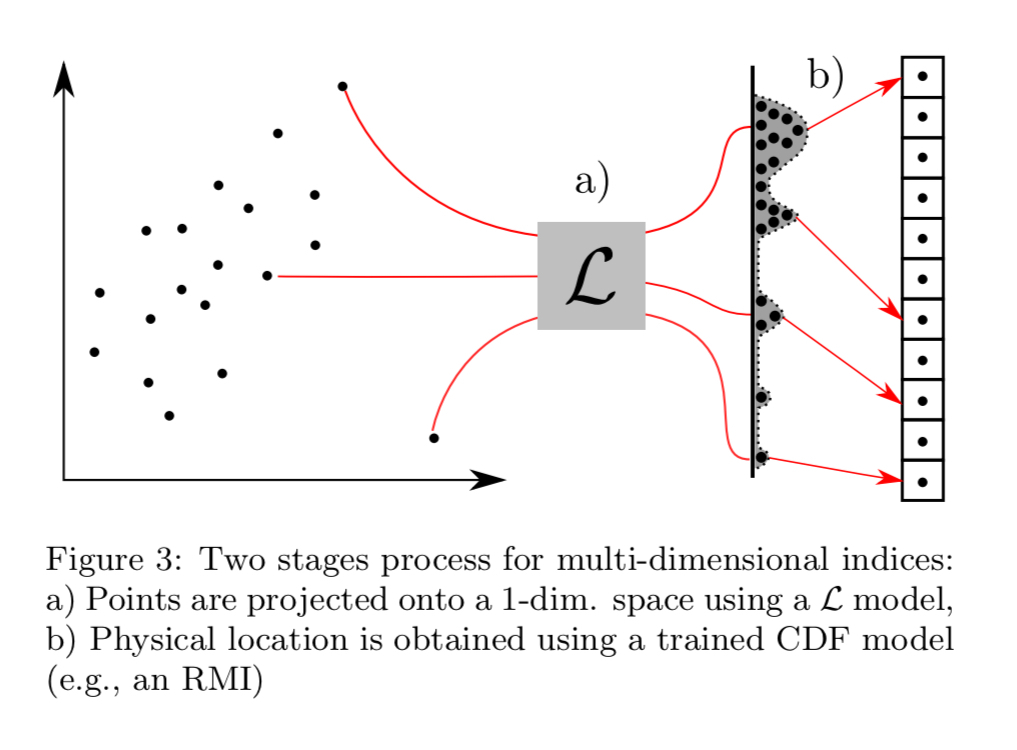
作者通过压缩在内存中的列存储上实现了这样一个学习索引,并将其与完整列扫描、聚集索引(按提供最佳总体性能的列排序)和R树进行了比较。这些基准使用了来自TPC-H基准的lineitem表的6000万条记录,查询选择性为0.25%。
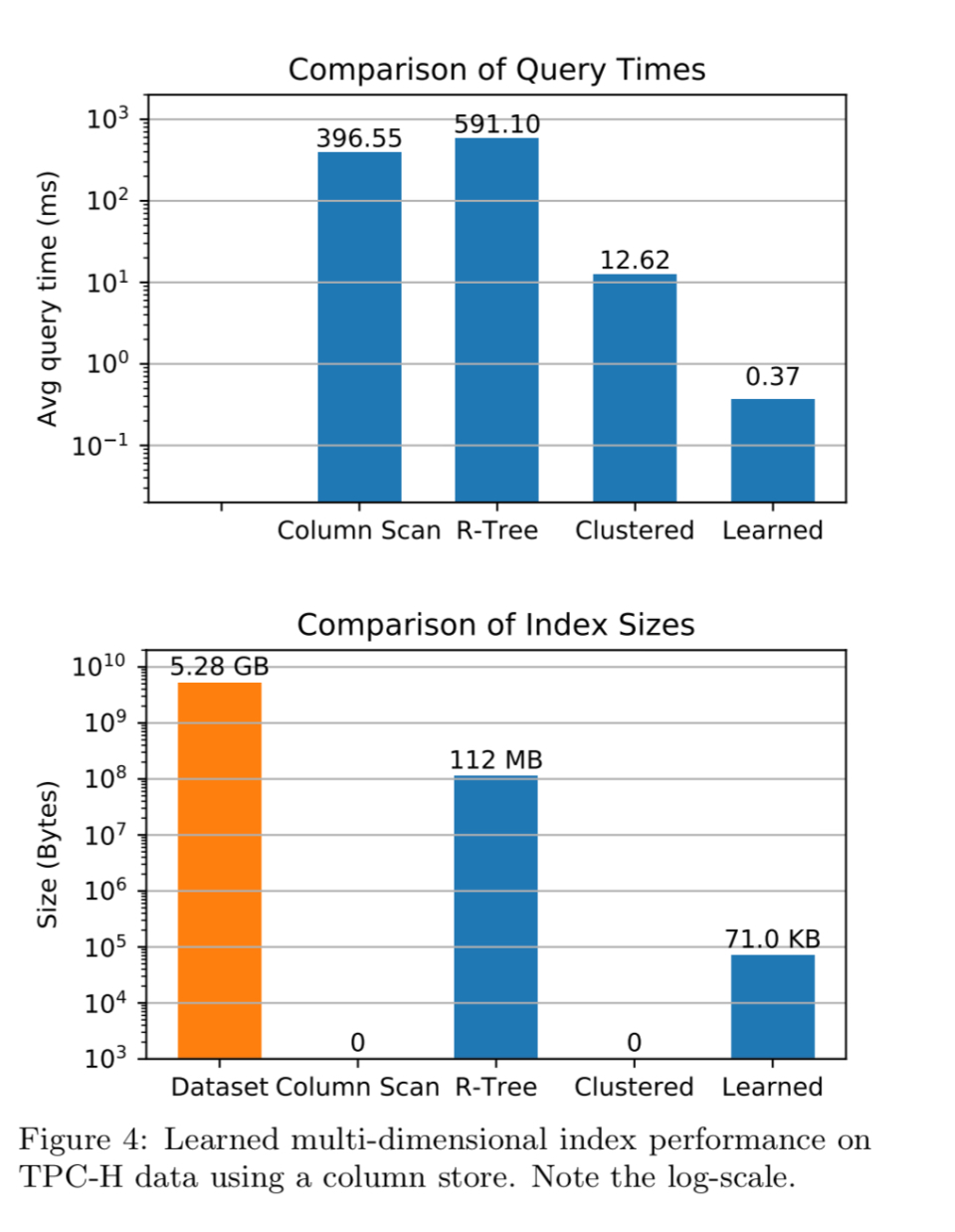
学习到的索引比下一个性能最好的实现高出34x(注意图表上的日志比例),与集群解决方案相比,它的空间开销很小。
进一步的分析表明,学习的索引在几乎所有类型的查询中都优于聚集索引,但聚集索引中的聚集维度是查询中的唯一维度时除外。
查询执行
**
这是我最喜欢的部分之一,因为它展示了学习的模型如何帮助在卑微和古老的排序案例。排序的方法是使用一个学习的模型将记录大致按正确的顺序排列,然后作为最后一步更正近乎完美的排序数据。为此,可以使用高效的本地排序(如插入排序),这对于几乎已排序的数组来说非常快。

下图显示了从正态分布随机抽样的64位双倍大数据量排序的学习方法的结果。在比较中,Timsort是java和python的默认排序,STD::排序是从C++库中得到的。学习到的变量平均比次优(本例中为基数排序)快18%。
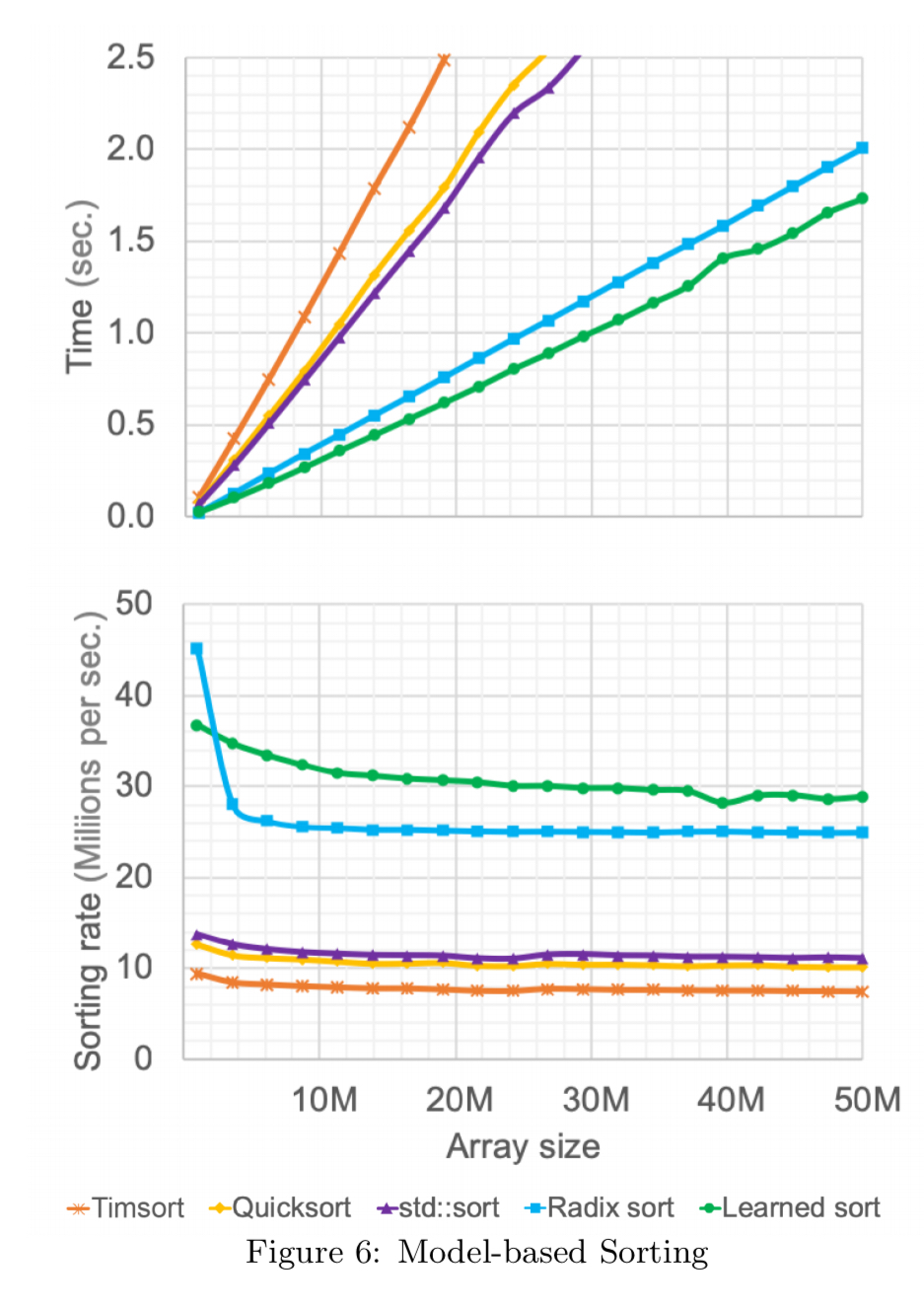
(这不包括学习模型所需的时间)。
学习的模型也可以用于改进连接。例如,考虑一个合并联接,其中包含两个存储的联接列和每列一个模型。我们可以使用该模型跳过不连接的数据(作者没有详细说明“本地修补”在这种情况下应该如何工作,这对我来说并不明显)。
作者还试验了具有工作负载意识的调度程序,使用图形神经网络实现了一个基于强化学习的调度系统:
我们的系统将调度算法表示为一个神经网络,它将数据(例如,使用一个CDF模型)和查询工作负载(例如,使用一个在以前执行查询时训练过的模型)作为输入信息,以做出调度决策。
在10个TPC-H查询的示例中,学习的调度程序将平均作业完成时间比Spark的默认FIFO调度程序提高了45%。
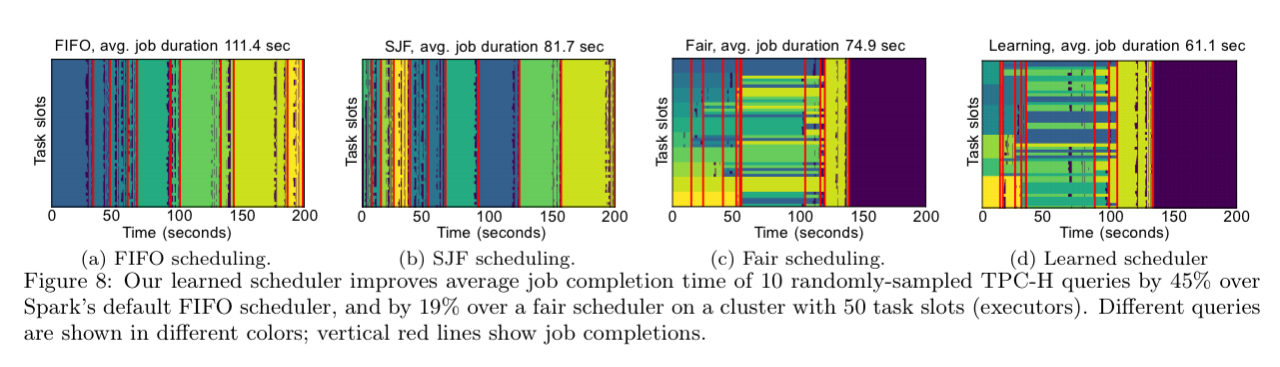
调度器学习到的获得这一改进的策略是将快速完成短作业与最大化集群效率结合起来,学习在并行性“最佳点”附近运行作业
查询优化程序
传统的查询优化器极难构建、维护,而且常常产生次优的查询计划。优化器的脆弱性和复杂性使得它很适合学习…
最初的实验从传统的成本模型开始,并随着时间的推移通过学习对其进行改进,结果表明模型质量可以得到提高,但要获得大的收益,就需要对基数估计进行显著的改进。研究方向是探索基于混合模型的基数估计方法。这些混合模型结合了底层数据模式和相关性的学习模型,异常/异常值侦听捕获数据的特定实例的极端(和难以学习的)异常。
其他领域
其他建议的学习模型在未来可能会证明是有益的领域包括近似查询处理、预测建模以及包括插入和更新的工作负载。
总结
SageDB提出了一种全新的构建数据库系统的方法,它将ML模型与程序综合相结合,生成系统组件。如果成功,我们相信这种方法将产生新一代的大数据处理工具,这些工具可以更好地利用gpu和tpu,在存储消耗和空间方面提供显著的好处,在某些情况下,甚至可以改变某些数据操作的复杂性类别。

若有收获,就点个赞吧
0 人点赞
