论文地址:RDBMS上的声明性递归计算…或者,为什么应该使用数据库来进行分布式机器学习Jankov等人,VLDB’19
如果你想一个像Procella这样的系统,它将事务性和分析性工作负载结合在云原生架构之上,扩展到SQL以实现流式处理,基于数据流的物化视图(参见Naiad、Noria、Multiverses,还可以查看物化在这里做什么),使用SQL接口查询半结构化和非结构化数据的能力,等等,然后一个画面开始出现一个统一的大型数据平台,上面有一个SQL查询引擎,可以满足一个一站式组织的所有数据需求。除了列表中有一个明显的遗漏:处理所有的机器学习用例。
以前在关系数据库中进行过机器学习,最显著的是MADlib的形式,在我在Pivotal工作期间,MADlib被集成到Greenplum中。Apache MADLib项目仍在进行中,最近(2019年7月)的1.16版本甚至包含了一些对深度学习的支持。
为了实现一站式解决组织所有数据需求的愿景,我们需要能够处理要求最高的大规模机器学习任务——那些需要分布式学习的任务。今天的论文选择,副标题“为什么你应该使用分布式机器学习数据库”试图填补这一空白。这将是对TensorFlow等人目前采用的基于DSL的深度学习方法的大胆背离,但同时它也提供了一些引人注目的优势。即使在深入学习中,所有的道路最终都会回到SQL吗??
我们考虑如何对现代关系数据库管理系统(RDBMS)进行一系列非常小的更改,使其适合于分布式学习计算……我们还表明,使用RDBMS作为机器学习平台具有关键的优势。
为什么会有人想这么做???
为什么有人想在RDBMS中运行深度学习计算??
- 一方面,因为当前的分布式深度学习方法只能使用基于数据并行的方法(一个模型,拆分数据),而只能推进模型并行,以达到下一个层次(将模型本身拆分到多个节点)。
大多数现有的大数据ML系统(如TensorFlow和Petuum)所青睐的分布式键值存储(称为参数服务器)使得构建模型并行计算变得困难,甚至是“手工”的。
- 另一方面,通过切换到计算的关系模型,模型并行看起来与数据并行非常相似,并且我们可以利用高度优化的分布式数据库引擎。SQL提供了一个声明式的编程接口,在这个接口下,系统本身可以根据数据大小和统计数据、布局、计算硬件等找出最有效的执行计划。。
小心你的要求(具体化)
**
如果我们假设一个RDBMS‘轻微扩展’来处理矩阵和向量数据类型,比如SimSQL,那么我们实际上离用SQL来表示机器学习计算已经不远了。
给定一个权重表W存储权重矩阵的块,一个激活表a存储激活,一个AEW表存储下一次迭代计算权重所需的值,我们就可以在SQL中表示一个具有八个隐藏层的前向机器学习模型的迭代i的后向通过。

除了看起来不太好看(参见MADLib中的MLP)之外,对于SQL来说也是非常必要的(注意for循环)。由此引起的问题是用于具体化迭代之间传递的状态的AEW表:该状态可以非常迅速地增长到非常大。我们想去掉for循环的命令,这样我们就可以在声明式查询表达式后面实现流水线。
递归SQL扩展
经典的SQL已经通过一个叫做“公共表表达式”的东西获得了递归支持,这里我们需要一些与此不同的东西,本质上是在任意大的表序列上表示延迟物化的能力。
作者以Pascal三角形为例,介绍了通过数组样式索引访问表的多个版本的概念。
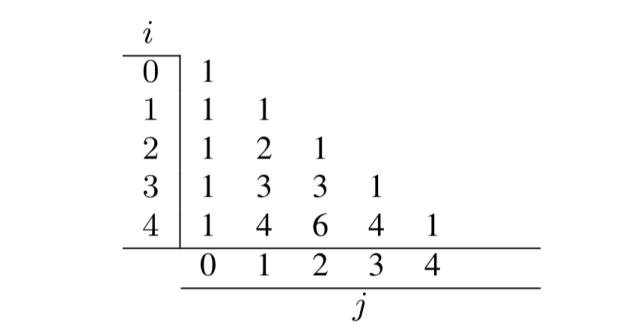
给定一个基表,例如。
然后,我们可以递归地定义其他版本,例如,对于Pascal三角形(j=i)的对角线:
例如where j = 0:

对于其他一切:
这样,稍后我们就可以发出一个查询,比如pascalsTri[56][23]中的SELECT*,系统将展开递归以将所需的计算表示为一个关系代数语句。
EXECUTE关键字允许同时查询一个表的多个版本。例如:
我们还可以使用MATERIALIZE关键字(对于动态编程)请求表显式物化,并且可以使用UNION合并多个递归定义的表。
SQL中的递归学习
有了这些新的扩展,我们可以定义一个前向传递计算(计算每一层神经元的激活水平),如下所示: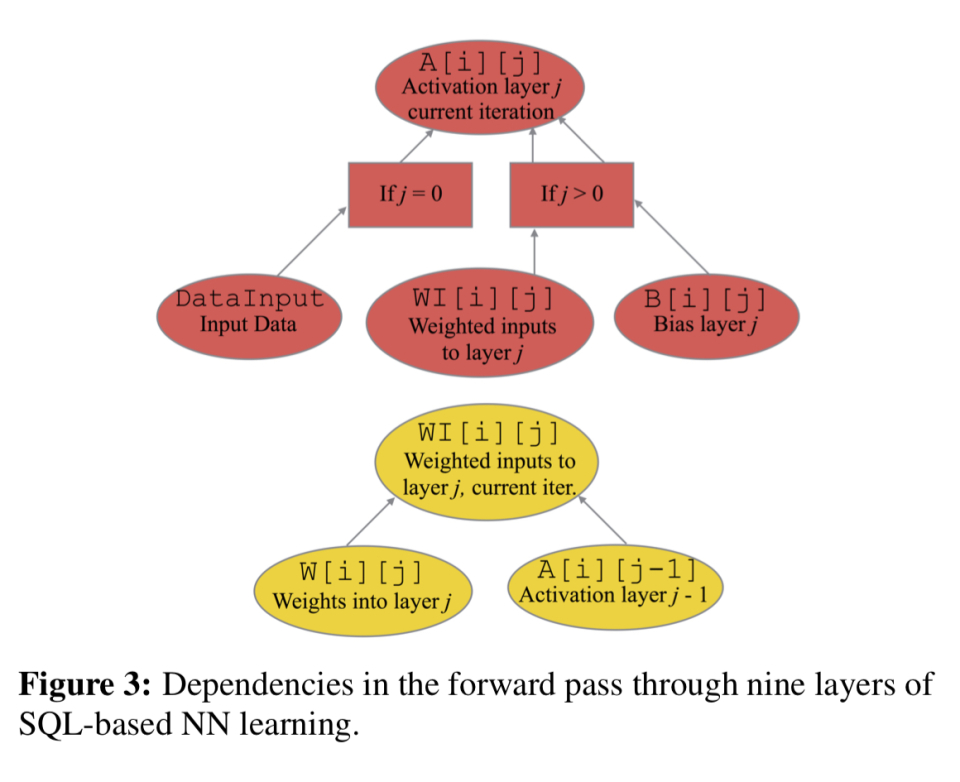

反向通过可以类似地表示: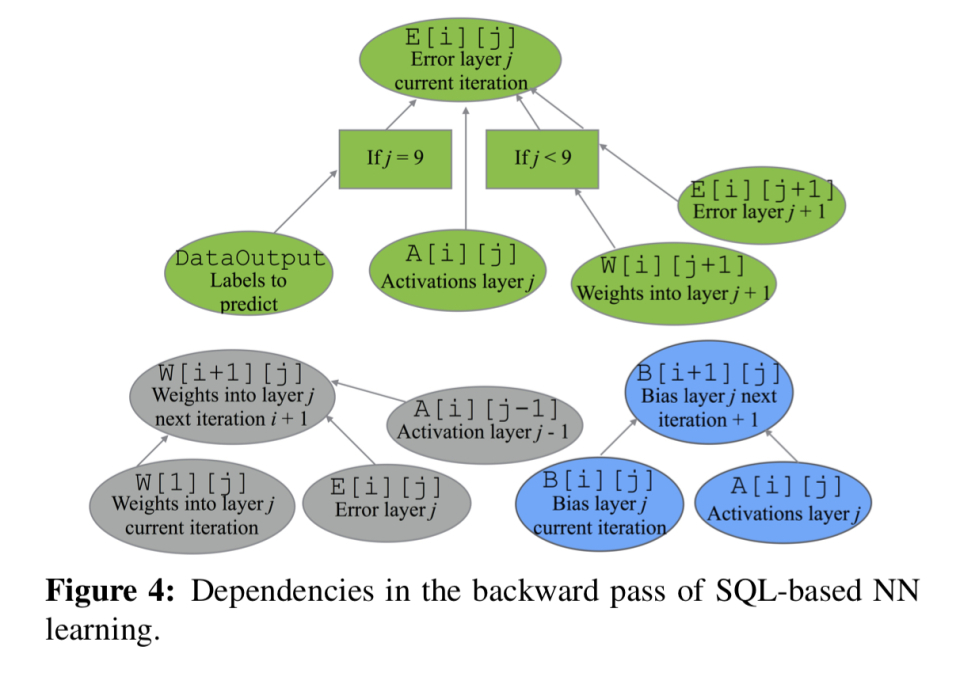

高效率的执行计划
本文详细介绍了如何用关系数据库管理系统(RDBMS)高效地编译和执行ML工作负载的SQL规范所隐含的大型复杂计算。这里我就来谈谈亮点。
从查询中,我们可以展开递归以创建单个未优化的关系代数计划(DAG)。下一步是将计划分解成若干部分,每个子计划都称为一个框架。显然,选择的分解会对结果查询性能产生很大影响。如果我们走得太细,我们可能会失去在一个框架内找到好的优化的机会(例如,最佳连接顺序)。所以框架有最小的尺寸。下一个主要考虑是给定分解所需的帧间通信量。一个很好的近似值是引入的管道断路器的数量。
当一个操作符的输出必须具体化到磁盘或通过网络传输,而不是通过CPU缓存或在最坏的情况下通过RAM从操作符直接传送到操作符时,就会发生管道中断。诱导破管器是一种不会出现在最佳物理计划中,但被切割所强制的破管器。
即使计算出一个给定的切割是否会引入一个管道断路器也不是一件简单的事情,但可以通过概率来估计。作为著名的广义二次分配问题(GQAP)的一个实例,该成本被输入到整体优化中,以找到最佳的计划分解。GQAP的一个众所周知的问题是它是一个非常困难的问题!你也许能猜到接下来会发生什么…。贪婪的近似。
从一个源操作符开始,我们贪婪地向帧添加操作符,选择产生最小的帧成本增加的操作符,直到帧大小超过最小阈值。结果取决于您碰巧选择的初始源节点,但这可以通过对每个可能开始的操作运行一次贪婪算法来修正。
实验结果
评估比较了多层前向神经网络(FFNN)、Word2Vec算法和LDA分布式折叠Gibbs采样器的分布式实现。实现需要SQL和一些用C++编写的UDF。下表显示了与TensorFlow和Spark相比具有代表性的行数。当然,一旦建立了udf库,它们就可以在计算中重用。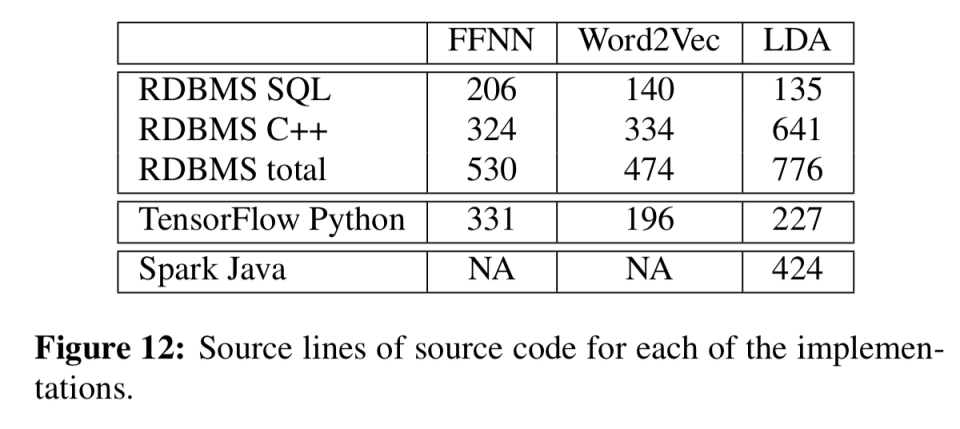
对于前向神经网络,使用gpu的TensorFlow仍然明显更快,隐藏层更小,但无法扩展。除此之外,RDBMS还赢得了:
对于Word2Vec和LDA计算来说,随着维度/主题数量的增加,速度提高非常显著(例如,对于具有50000个主题的LDA,8.5分钟比几乎5小时)。

我们已经证明,与TensorFlow相比,基于RDBMS的模型并行ML计算具有很好的规模,对于Word2Vec和LDA,基于RDMBS的计算可以比TensorFlow更快。然而,对于基于GPU的神经网络实现,RDBMS比TensorFlow慢。尽管其中的一些差异是由于我们在一个研究原型、高延迟Java/Hadoop系统上实现了我们的想法,但减少这种差距是未来工作的一个有吸引力的目标。

若有收获,就点个赞吧
0 人点赞
