Kafka控制器
控制器组件(Controller),是 Apache Kafka 的核心组件。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。在运行过程中,只能有一个 Broker 成为控制器
Zookeeper
Apache ZooKeeper 是一个提供高可靠性的分布式协调服务框架。它使用的数据模型类似于文件系统的树形结构,根目录也是以“/”开始。该结构上的每个节点被称为 znode,用来保存一些元数据协调信息。
如果以 znode 持久性来划分,znode 可分为持久性 znode 和临时 znode。持久性 znode 不会因为 ZooKeeper 集群重启而消失,而临时 znode 则与创建该 znode 的 ZooKeeper 会话绑定,一旦会话结束,该节点会被自动删除。
ZooKeeper 赋予客户端监控 znode 变更的能力,即所谓的 Watch 通知功能。一旦 znode 节点被创建、删除,子节点数量发生变化,抑或是 znode 所存的数据本身变更,ZooKeeper 会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端。
依托于这些功能,ZooKeeper 常被用来实现集群成员管理、分布式锁、领导者选举等功能。Kafka 控制器大量使用 Watch 功能实现对集群的协调管理。我们一起来看一张图片,它展示的是 Kafka 在 ZooKeeper 中创建的 znode 分布。你不用了解每个 znode 的作用,但你可以大致体会下 Kafka 对 ZooKeeper 的依赖。
控制器选举
Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
控制器功能
- 主题管理, 主题创建, 删除, 分区增加等, kafka-topics 脚本相关
- 分区重分配, kafka-reassign-partitions 脚本相关
Preferred领导者选举
集群成员管理, 新增Broker, Broker主动关闭, Broker宕机
这是控制器提供的第 4 类功能,包括自动检测新增 Broker、Broker 主动关闭及被动宕机。这种自动检测是依赖于前面提到的 Watch 功能和 ZooKeeper 临时节点组合实现的。
比如,控制器组件会利用 Watch 机制检查 ZooKeeper 的 /brokers/ids 节点下的子节点数量变更。目前,当有新 Broker 启动后,它会在 /brokers 下创建专属的 znode 节点。一旦创建完毕,ZooKeeper 会通过 Watch 机制将消息通知推送给控制器,这样,控制器就能自动地感知到这个变化,进而开启后续的新增 Broker 作业。
侦测 Broker 存活性则是依赖于刚刚提到的另一个机制:临时节点。每个 Broker 启动后,会在 /brokers/ids 下创建一个临时 znode。当 Broker 宕机或主动关闭后,该 Broker 与 ZooKeeper 的会话结束,这个 znode 会被自动删除。同理,ZooKeeper 的 Watch 机制将这一变更推送给控制器,这样控制器就能知道有 Broker 关闭或宕机了,从而进行“善后”。
- 数据服务
控制器的最后一大类工作,就是向其他 Broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 Broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据
控制器保存的数据
- 所有主题信息。包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
- 所有 Broker 信息。包括当前都有哪些运行中的 Broker,哪些正在关闭中的 Broker 等。
- 所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
值得注意的是,这些数据其实在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。有了这些数据,控制器就能对外提供数据服务了。这里的对外主要是指对其他 Broker 而言,控制器通过向这些 Broker 发送请求的方式将这些数据同步到其他 Broker 上。
控制器故障转移(Failover)
故障转移指的是,当运行中的控制器突然宕机或意外终止时,Kafka 能够快速地感知到,并立即启用备用控制器来代替之前失败的控制器。这个过程就被称为 Failover,该过程是自动完成的,无需你手动干预。
高水位与Leader Epoch
高水位
高水位(High Watermark)的定义
- 在时刻 T,任意创建时间(Event Time)为 T’,且 T’≤T 的所有事件都已经到达或被观测到,那么 T 就被定义为水位。
- 水位是一个单调增加且表征最早未完成工作(oldest work not yet completed)的时间戳。
- Kafka 的水位不是时间戳,更与时间无关。它是和位置信息绑定的,具体来说,它是用消息位移来表征的。

高水位作用
在 Kafka 中,高水位的作用主要有 2 个。
- 定义消息可见性,即用来标识分区下的哪些消息是可以被消费者消费的。
- 帮助 Kafka 完成副本同步。
分区Leader副本的高水位图示例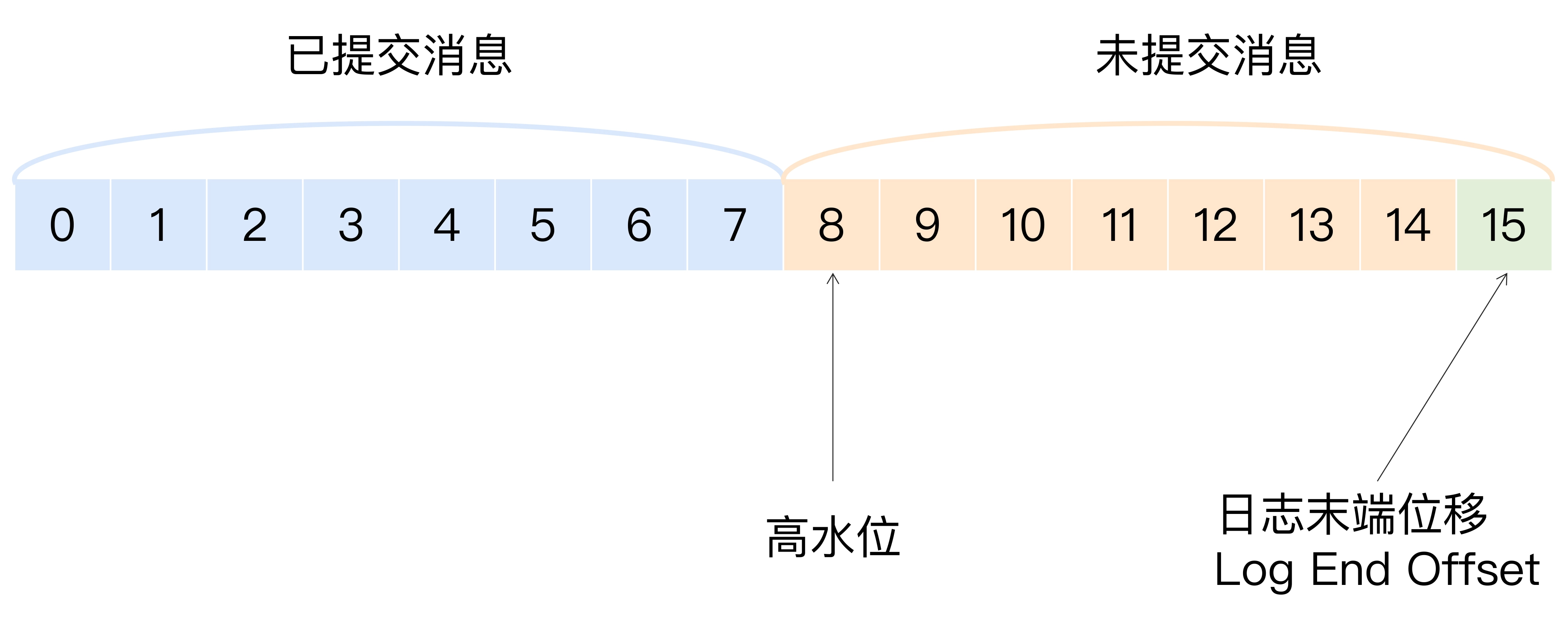
- 分区高水位以下的消息被认为是已提交消息, 反之是未提交消息, 消费者只能消费已提交消息, 即图中小于8的所有消息
注意,这里我们不讨论 Kafka 事务,因为事务机制会影响消费者所能看到的消息的范围,它不只是简单依赖高水位来判断。它依靠一个名为 LSO(Log Stable Offset)的位移值来判断事务型消费者的可见性。
- 图中Log End Offset, 即LEO日志末端位移, 表示副本写入下一条消息的位移值, 如图中下一条消息的位移为15, 介于高水位与LEO之间的消息属于未提交消息, 同一个副本对象, 其高水位值不会大于LEO值
- Kafka所有副本都有其高水位以及LEO值, Kafka使用Leader副本的高水位来定义其所在分区的高水位
高水位更新机制
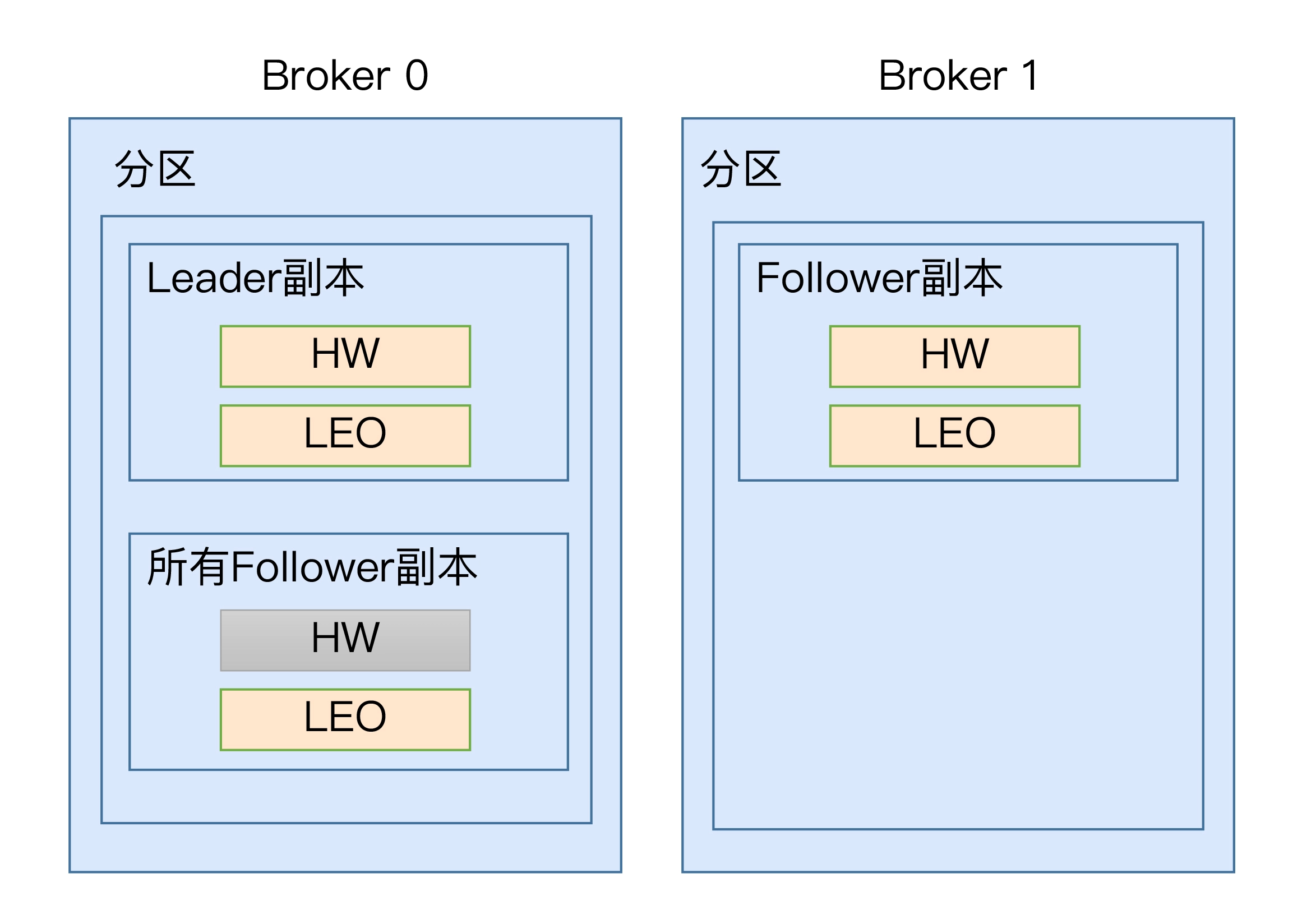

从 Leader 副本和 Follower 副本两个维度,来总结一下高水位和 LEO 的更新机制。
Leader 副本
处理生产者请求的逻辑如下:
- 写入消息到本地磁盘。
- 更新分区高水位值。
i. 获取 Leader 副本所在 Broker 端保存的所有远程副本 LEO 值(LEO-1,LEO-2,……,LEO-n)。
ii. 获取 Leader 副本高水位值:currentHW。
iii. 更新 currentHW = max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)}。
处理 Follower 副本拉取消息的逻辑如下:
- 读取磁盘(或页缓存)中的消息数据。
- 使用 Follower 副本发送请求中的位移值更新远程副本 LEO 值。
- 更新分区高水位值(具体步骤与处理生产者请求的步骤相同)。
Follower 副本从 Leader 拉取消息的处理逻辑如下:
- 写入消息到本地磁盘。
- 更新 LEO 值。
- 更新高水位值。
i. 获取 Leader 发送的高水位值:currentHW。
ii. 获取步骤 2 中更新过的 LEO 值:currentLEO。
iii. 更新高水位为 min(currentHW, currentLEO)。
副本同步机制
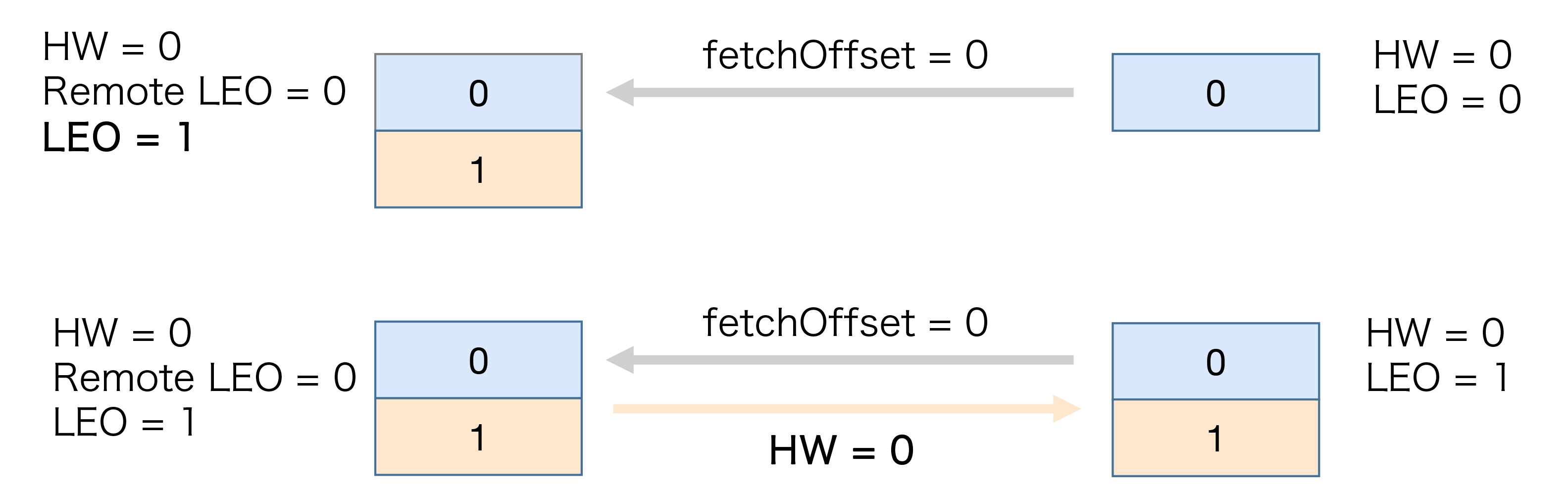
上面那一坨看得不是很懂, 感觉应该很简单的流程被描述的很复杂, 我来总结下
- 初始状态, 都是0

- 当生产者发一条消息后, Leader副本成功将消息写入磁盘, 故LEO=1, Follower从Leader拉取位移为0的消息, 同时将自身LEO同步为1
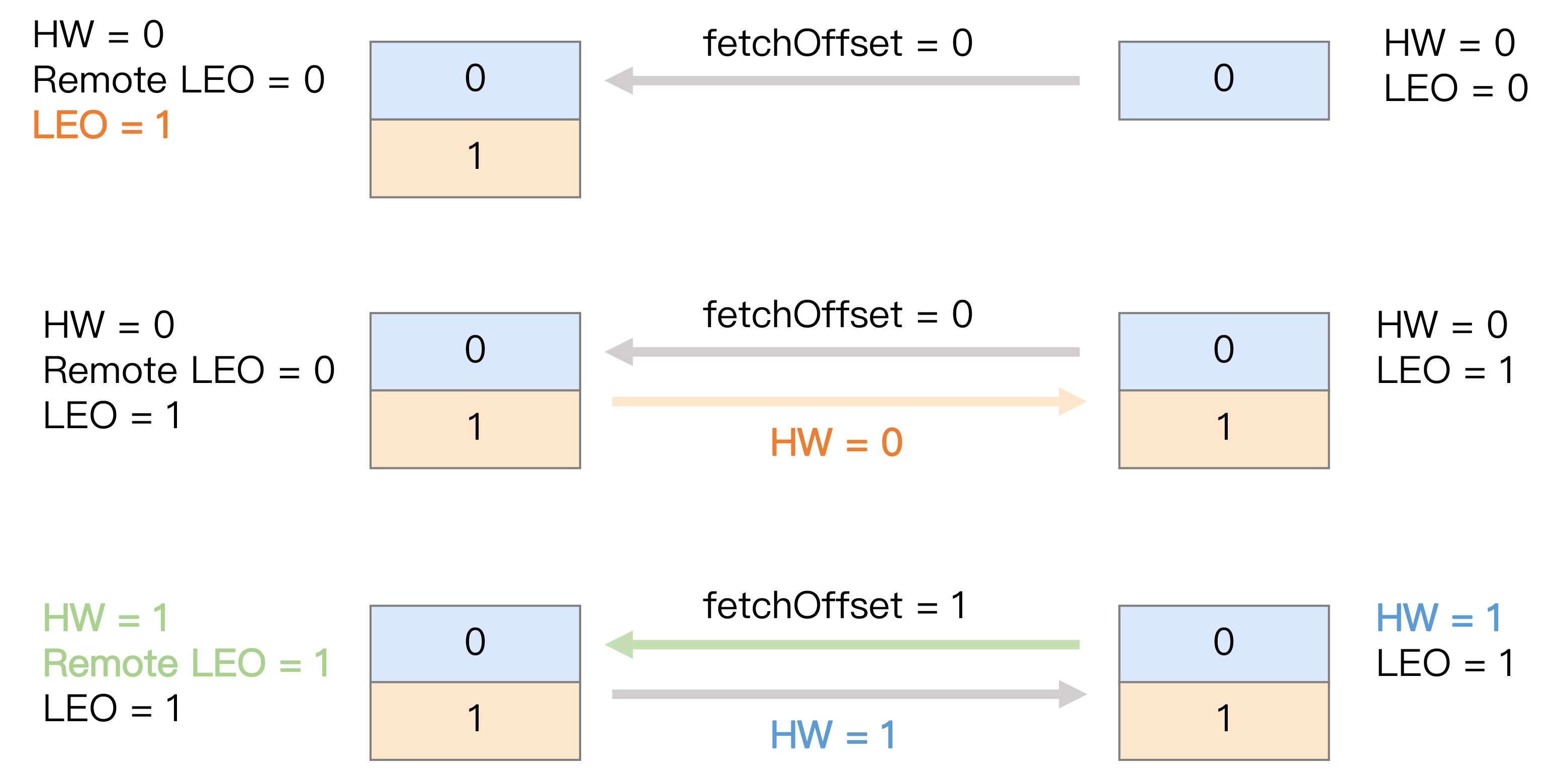
- 当Follower拉取位移为0的消息成功后, 往Leader拉取位移为1的消息, Leader收到请求将内部持有的远程副本LEO更新为1, 并更新自身HW=1, 再将HW=1同步给Follower, 自此, 一个完整的消息同步周期就o了~
Leader Epoch
从刚才的分析可见, Follower 副本的高水位更新需要一轮额外的拉取请求才能实现, 若多个副本, 则需要多轮拉取请求, 即Leader 副本高水位更新和 Follower 副本高水位更新在时间上是存在错配的。这种错配是很多“数据丢失”或“数据不一致”问题的根源.
基于此,社区在 0.11 版本正式引入了 Leader Epoch 概念,来规避因高水位更新错配导致的各种不一致问题。
所谓 Leader Epoch,我们大致可以认为是 Leader 版本。它由两部分数据组成。
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。
- 起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
我举个例子来说明一下 Leader Epoch。假设现在有两个 Leader Epoch<0, 0> 和 <1, 120>,那么,第一个 Leader Epoch 表示版本号是 0,这个版本的 Leader 从位移 0 开始保存消息,一共保存了 120 条消息。之后,Leader 发生了变更,版本号增加到 1,新版本的起始位移是 120。
Kafka Broker 会在内存中为每个分区都缓存 Leader Epoch 数据,同时它还会定期地将这些信息持久化到一个 checkpoint 文件中。当 Leader 副本写入消息到磁盘时,Broker 会尝试更新这部分缓存。如果该 Leader 是首次写入消息,那么 Broker 会向缓存中增加一个 Leader Epoch 条目,否则就不做更新。这样,每次有 Leader 变更时,新的 Leader 副本会查询这部分缓存,取出对应的 Leader Epoch 的起始位移,以避免数据丢失和不一致的情况。

若有收获,就点个赞吧
0 人点赞
