如何学习开源代码?
- 优先看文档, 且优先英文
先Quick Start—>Introduction—>Basic Concept, 再看使用场景, 功能特性以及生态系统
- 带着问题的答案去看源码实现
注意一样是先找问题的实现文档, 了解原理, 再看源码实现细节
设计消息队列
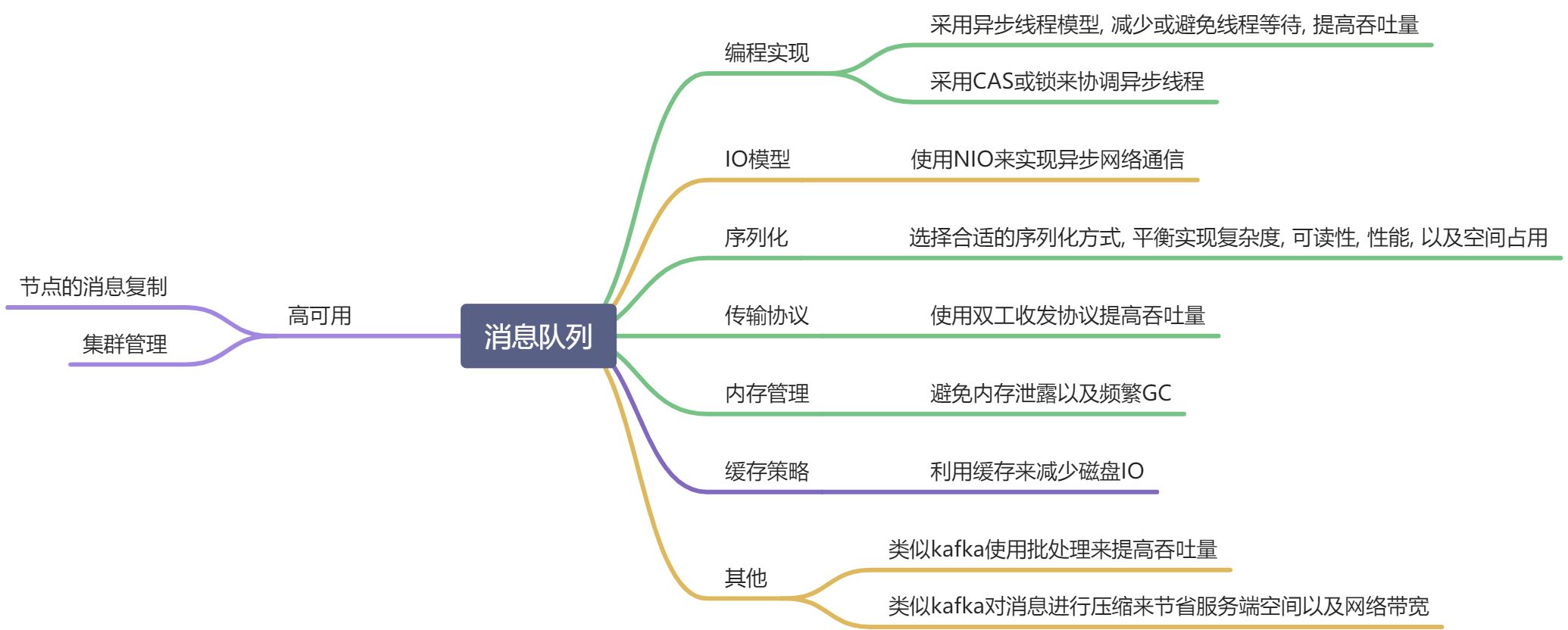
异步如何提高系统性能?
异步编程是通过分工的方式,是为了减少了cpu因线程等待的可能,让CPU一直处于工作状态.
网络IO模型
关于JAVA的网络,之前有个比喻形式的总结,分享给大家:
例子:有一个养鸡的农场,里面养着来自各个农户(Thread)的鸡(Socket),每家农户都在农场中建立了自己的鸡舍(SocketChannel)
1、BIO:Block IO,每个农户盯着自己的鸡舍,一旦有鸡下蛋,就去做捡蛋处理;
2、NIO:No-Block IO-单Selector,农户们花钱请了一个饲养员(Selector),并告诉饲养员(register)如果哪家的鸡有任何情况(下蛋)均要向这家农户报告(select keys);
3、NIO:No-Block IO-多Selector,当农场中的鸡舍逐渐增多时,一个饲养员巡视(轮询)一次所需时间就会不断地加长,这样农户知道自己家的鸡有下蛋的情况就会发生较大的延迟。怎么解决呢?没错,多请几个饲养员(多Selector),每个饲养员分配管理鸡舍,这样就可以减轻一个饲养员的工作量,同时农户们可以更快的知晓自己家的鸡是否下蛋了;
4、Epoll模式:如果采用Epoll方式,农场问题应该如何改进呢?其实就是饲养员不需要再巡视鸡舍,而是听到哪间鸡舍的鸡打鸣了(活跃连接),就知道哪家农户的鸡下蛋了;
5、AIO:Asynchronous I/O, 鸡下蛋后,以前的NIO方式要求饲养员通知农户去取蛋,AIO模式出现以后,事情变得更加简单了,取蛋工作由饲养员自己负责,然后取完后,直接通知农户来拿即可,而不需要农户自己到鸡舍去取蛋。
参考: https://www.jianshu.com/p/5bb812ca5f8e
NIO是种同步非阻塞的IO模型, 采用类似”事件-通知”的机制, 使用一个后端线程监听多个socket连接, 降低了线程资源开销.
在实现上, NIO设立了Buffer缓冲区以及多个Channel通道, 数据总是从通道读到缓冲区或是从缓冲区写到通道, 同时有个多路复用器Selector监听多个通道的事件, 以达到单个线程监听多个数据通道.
序列化
选择序列化方式要考虑几个因素:
- 序列化后的数据是否易阅读;
- 实现的复杂度;
- 性能;
- 信息密度, 也可以说序列化后的空间占用
传输协议
- 断句问题—>采用”分隔符”或是”前置长度”解决
- 采用双工通信提高吞吐量—>”使用ID来标识请求与响应对应关系”
JMQ的设计参考
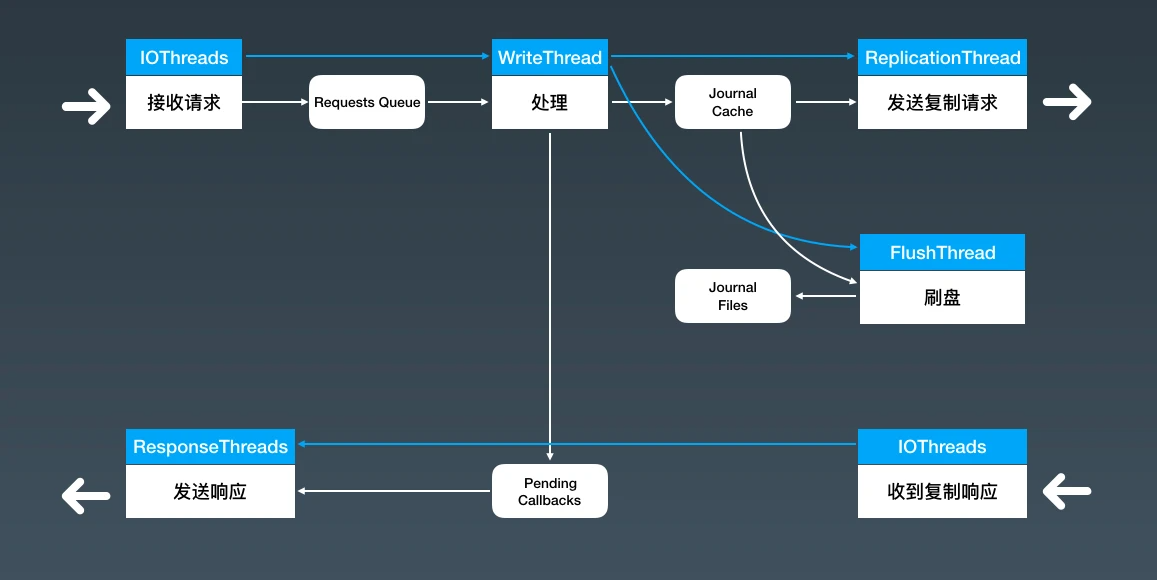
这个里面有很重要的几点优化:
一是我们使用异步设计,把刷盘和复制这两部分比较慢的操作从这个流程中分离出去异步执行;
第二是,我们使用了一个写缓存 Journal Cache 将一个写磁盘的操作,转换成了一个写内存的操作;
第三是,这个处理的全流程是近乎无锁的设计,避免了线程因为等待锁导致的阻塞;
第四是,我们把回复响应这个需要等待资源的操作,也异步放到其他的线程中去执行。
涉及的技术包括:异步的设计、缓存设计、锁的正确使用、线程协调、序列化和内存管理,等等
Kafka如何实现高性能IO?
- 使用批量处理的方式来提升系统吞吐能力。
- 基于磁盘文件高性能顺序读写的特性来设计的存储结构。
- 利用操作系统的 PageCache 来缓存数据,减少 IO 并提升读性能。
- 使用零拷贝技术加速消费流程。
RocketMQ与Kafka的消息复制如何实现?
在服务端, 消息队列通过持久化和复制来保证可靠性. 通过将数据写入多个节点来提高可靠性以及可用性. 并且采用”主-从”的复制方式, 能够保证数据一致性, 既不丢消息也保证严格顺序.
RocketMQ
- RocketMQ中, 复制的基本单位是Broker, 也就是服务端的进程, 复制采用的也是主从方式, 通常是一主一从, 也支持一主多从
- RockectMQ的Dledger在写入消息的时候, 要求消息至少复制到半数以上的节点之后, 才给客户端返回写入成功, 并且支持通过选举来动态切换主节点.
Kafka
- Kafka中, 复制的基本单位是分区, 每个分区的几个副本之间, 构成一个小的复制集群, Broker只是这些分区副本的容器, 所以Kafka的Broker是不分主从的
- 分区的多个副本中一是采用一主多从的方式, 采用异步复制写入消息, 消息写入主节点, 并且有足够多的节点都复制成功后再返回成功, 这个足够多即ISR(保持数据同步的副本, 包含主节点)的数量是可配的
- Kafka使用ZooKeeper来对分区的节点进行监控选举等
RokectMQ如何在集群中找到节点?
RocketMQ NameServer在集群中为客户端提供路由信息.
每个 NameServer 节点上都保存了集群所有 Broker 的路由信息,可以独立提供服务。Broker 会与所有 NameServer 节点建立长连接,定期上报 Broker 的路由信息。客户端会选择连接某一个 NameServer 节点,定期获取订阅主题的路由信息,用于 Broker 寻址。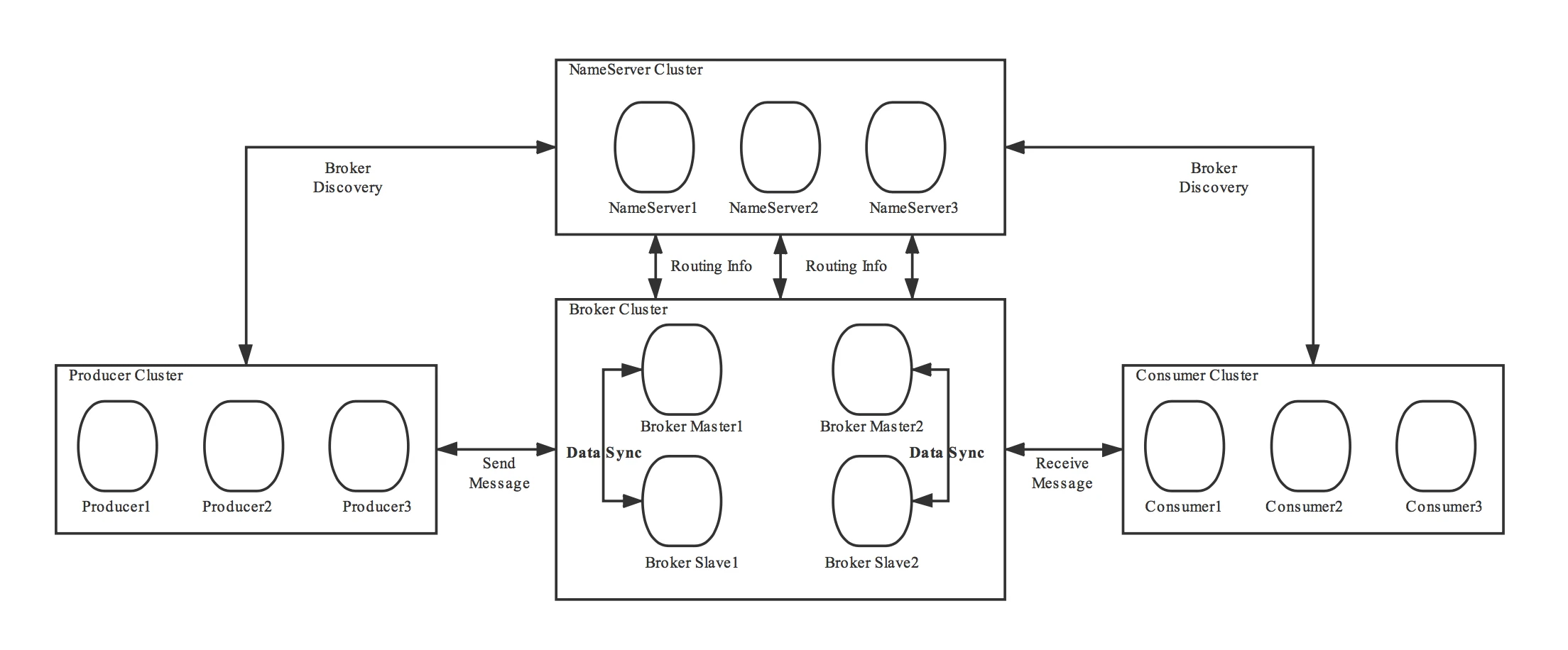
NamingService 的设计思想。
NamingService 负责保存集群内所有节点的路由信息,NamingService 本身也是一个小集群,由多个 NamingService 节点组成。这里我们所说的“路由信息”也是一种通用的抽象,含义是:“客户端需要访问的某个特定服务在哪个节点上”。
集群中的节点主动连接 NamingService 服务,注册自身的路由信息。给客户端提供路由寻址服务的方式可以有两种,一种是客户端直接连接 NamingService 服务查询路由信息,另一种是,客户端连接集群内任意节点查询路由信息,节点再从自身的缓存或者从 NamingService 上进行查询。
Kafka如何利用ZooKeeper协调服务?
ZooKeeper是一个分布式协调服务, 提供了包括读写元数据, 节点监控, 选举, 节点间通信和分布式锁等功能.
kafka主要使用ZooKeeper来保存它的元数据, 监控Broker和分区的存活状态, 并利用ZooKeeper进行选举.
如下图, Kafka 在 ZooKeeper 中保存的元数据,主要就是 Broker 的列表和主题分区信息两棵树。这份元数据同时也被缓存到每一个 Broker 中。客户端并不直接和 ZooKeeper 来通信,而是在需要的时候,通过 RPC 请求去 Broker 上拉取它关心的主题的元数据,然后保存到客户端的元数据缓存中,以便支撑客户端生产和消费。
补充:
- Kafka利用ZooKeeper选举的过程—“抢占模式”
每个 Broker 在启动后,都会尝试在 ZooKeeper 中创建同一个临时节点:/controller,并把自身的信息写入到这个节点中。由于 ZooKeeper 它是一个可以保证数据一致性的分布式存储,所以,集群中只会有一个 Broker 抢到这个临时节点,那它就是 Leader 节点。其他没抢到 Leader 的节点,会 Watch 这个临时节点,如果当前的 Leader 节点宕机,所有其他节点都会收到通知,它们会开始新一轮的抢 Leader 游戏。
- RocketMQ/Dledger的选举—“Raft一致性算法”

若有收获,就点个赞吧
0 人点赞
