原子类:无锁工具类的典范
原子类使用无锁方案
原子类使用示例:
public class Test {long count = 0;void add10K() {int idx = 0;while(idx++ < 10000) {count += 1;}}}---------------利用原子类的改造后变成线程安全public class Test {AtomicLong count =new AtomicLong(0);void add10K() {int idx = 0;while(idx++ < 10000) {count.getAndIncrement();}}}
无锁方案相对于互斥锁方案, 最大的好处是性能:
- 互斥锁为保证互斥, 加锁与解锁操作消耗性能;
- 互斥锁拿不到锁的线程阻塞, 触发线程切换, 消耗性能
无锁方案的实现原理
CPU的CAS指令
CPU 为了解决并发问题,提供了 CAS 指令(CAS,全称是 Compare And Swap,即“比较并交换”)。CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
补充: 使用 CAS 来解决并发问题,一般都会伴随着自旋,而所谓自旋,其实就是循环尝试。
CAS需要注意ABA问题
原子化的更新对象很可能就需要关心 ABA 问题,因为两个 A 虽然相等,但是第二个 A 的属性可能已经发生变化了。所以在使用 CAS 方案的时候,一定要先 check 一下。
原子类 AtomicLong 的 getAndIncrement() 方法内部就是基于 CAS 实现的.
在 Java 1.8 版本中,getAndIncrement() 方法会转调 unsafe.getAndAddLong() 方法。这里 this 和 valueOffset 两个参数可以唯一确定共享变量的内存地址。
final long getAndIncrement() {return unsafe.getAndAddLong(this, valueOffset, 1L);}---------------getAndAddLong()方法源码public final long getAndAddLong(Object o, long offset, long delta){long v;do {// 读取内存中的值v = getLongVolatile(o, offset);} while (!compareAndSwapLong(o, offset, v, v + delta));return v;}//原子性地将变量更新为x//条件是内存中的值等于expected//更新成功则返回truenative boolean compareAndSwapLong(Object o, long offset,long expected,long x);
getAndAddLong() 方法的实现,基本上就是 CAS 使用的经典范例。所以请再次体会下面这段抽象后的代码片段,它在很多无锁程序中经常出现。
do {// 获取当前值oldV = xxxx;// 根据当前值计算新值newV = ...oldV...}while(!compareAndSet(oldV,newV);
原子类概览

原子化的基本数据类型
相关实现有 AtomicBoolean、AtomicInteger 和 AtomicLong, 提供的方法主要有以下这些:
getAndIncrement() //原子化i++getAndDecrement() //原子化的i--incrementAndGet() //原子化的++idecrementAndGet() //原子化的--i//当前值+=delta,返回+=前的值getAndAdd(delta)//当前值+=delta,返回+=后的值addAndGet(delta)//CAS操作,返回是否成功compareAndSet(expect, update)//以下四个方法//新值可以通过传入func函数来计算getAndUpdate(func)updateAndGet(func)getAndAccumulate(x,func)accumulateAndGet(x,func)
原子化的对象引用类型
相关实现有 AtomicReference、AtomicStampedReference 和 AtomicMarkableReference,利用它们可以实现对象引用的原子化更新。
AtomicReference 提供的方法和原子化的基本数据类型差不多, 但注意, 对象引用的更新需要重点关注 ABA 问题,AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题。
解决 ABA 问题的思路其实很简单,增加一个版本号维度就可以了, 每次执行 CAS 操作,附加再更新一个版本号,只要保证版本号是递增的,那么即便 A 变成 B 之后再变回 A,版本号也不会变回来(版本号递增的)。AtomicStampedReference 实现的 CAS 方法就增加了版本号参数,方法签名如下:
boolean compareAndSet(V expectedReference,V newReference,int expectedStamp,int newStamp)
AtomicMarkableReference 的实现机制则更简单,将版本号简化成了一个 Boolean 值,方法签名如下:
boolean compareAndSet(V expectedReference,V newReference,boolean expectedMark,boolean newMark)
原子化数组
相关实现有 AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray,利用这些原子类,我们可以原子化地更新数组里面的每一个元素。这些类提供的方法和原子化的基本数据类型的区别仅仅是:每个方法多了一个数组的索引参数
原子化对象属性更新器
相关实现有 AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater,利用它们可以原子化地更新对象的属性,这三个方法都是利用反射机制实现的,创建更新器的方法如下:
public static <U>AtomicXXXFieldUpdater<U>newUpdater(Class<U> tclass,String fieldName)
需要注意的是,对象属性必须是 volatile 类型的,只有这样才能保证可见性;如果对象属性不是 volatile 类型的,newUpdater() 方法会抛出 IllegalArgumentException 这个运行时异常。
原子化的累加器
DoubleAccumulator、DoubleAdder、LongAccumulator 和 LongAdder,这四个类仅仅用来执行累加操作,相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。如果你仅仅需要累加操作,使用原子化的累加器性能会更好
总结:
无锁方案相对于互斥锁方案,优点非常多,首先性能好,其次是基本不会出现死锁问题(但可能出现饥饿和活锁问题,因为自旋会反复重试).
Executor与线程池:如何创建正确的线程池?
线程池的优势:
创建对象,仅仅是在 JVM 的堆里分配一块内存而已;而创建一个线程,却需要调用操作系统内核的 API,然后操作系统要为线程分配一系列的资源,这个成本就很高了,所以线程是一个重量级的对象,应该避免频繁创建和销毁。
线程池是一种生产者 - 消费者模式
目前业界线程池的设计,普遍采用的都是生产者 - 消费者模式。线程池的使用方是生产者,线程池本身是消费者, 示例代码如下, 帮助理解线程池的工作原理
//简化的线程池,仅用来说明工作原理class MyThreadPool{//利用阻塞队列实现生产者-消费者模式BlockingQueue<Runnable> workQueue;//保存内部工作线程List<WorkerThread> threads= new ArrayList<>();// 构造方法MyThreadPool(int poolSize,BlockingQueue<Runnable> workQueue){this.workQueue = workQueue;// 创建工作线程for(int idx=0; idx<poolSize; idx++){WorkerThread work = new WorkerThread();work.start();threads.add(work);}}// 提交任务void execute(Runnable command){workQueue.put(command);}// 工作线程负责消费任务,并执行任务class WorkerThread extends Thread{public void run() {//循环取任务并执行while(true){ ①Runnable task = workQueue.take();task.run();}}}}/** 下面是使用示例 **/// 创建有界阻塞队列BlockingQueue<Runnable> workQueue =new LinkedBlockingQueue<>(2);// 创建线程池MyThreadPool pool = new MyThreadPool(10, workQueue);// 提交任务pool.execute(()->{System.out.println("hello");});
如何使用 Java 中的线程池
ThreadPoolExecutor
ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
- corePoolSize:表示线程池保有的最小线程数。有些项目很闲,但是也不能把人都撤了,至少要留 corePoolSize 个人坚守阵地。
- maximumPoolSize:表示线程池创建的最大线程数。当项目很忙时,就需要加人,但是也不能无限制地加,最多就加到 maximumPoolSize 个人。当项目闲下来时,就要撤人了,最多能撤到 corePoolSize 个人。
- keepAliveTime & unit:上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?很简单,一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这个“一段时间”的参数。也就是说,如果一个线程空闲了keepAliveTime & unit这么久,而且线程池的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。
- workQueue:工作队列,和上面示例代码的工作队列同义。
- threadFactory:通过这个参数你可以自定义如何创建线程,例如你可以给线程指定一个有意义的名字。
- handler:通过这个参数你可以自定义任务的拒绝策略。如果线程池中所有的线程都在忙碌,并且工作队列也满了(前提是工作队列是有界队列),那么此时提交任务,线程池就会拒绝接收。至于拒绝的策略,你可以通过 handler 这个参数来指定。ThreadPoolExecutor 已经提供了以下 4 种策略。
- CallerRunsPolicy:提交任务的线程自己去执行该任务。
- AbortPolicy:默认的拒绝策略,会 throws RejectedExecutionException。
- DiscardPolicy:直接丢弃任务,没有任何异常抛出。
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入到工作队列。
- Java 在 1.6 版本还增加了 allowCoreThreadTimeOut(boolean value) 方法,它可以让所有线程都支持超时,这意味着如果项目很闲,就会将项目组的成员都撤走。
使用线程池要注意些什么
- 不建议使用 Java 并发包中的静态工厂类Executors , 原因是:Executors 提供的很多方法默认使用的都是无界的 LinkedBlockingQueue,高负载情境下,无界队列很容易导致 OOM,而 OOM 会导致所有请求都无法处理,这是致命问题。所以强烈建议使用有界队列。
- 默认拒绝策略要慎重使用, 默认的拒绝策略会 throw RejectedExecutionException 这是个运行时异常,对于运行时异常编译器并不强制 catch 它,所以开发人员很容易忽略, 在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
- 注意异常处理, 如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常了,但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。最稳妥和简单的方案还是捕获所有异常并按需处理, 如下示例代码 ```java
try { //业务逻辑 } catch (RuntimeException x) { //按需处理 } catch (Throwable x) { //按需处理 }
---<a name="hEvIa"></a>## Future:如何用多线程实现最优的“烧水泡茶”程序?<a name="bZnvw"></a>### 如何获取任务执行结果使用 ThreadPoolExecutor 的时候,如何获取任务执行结果<br />Java 通过 ThreadPoolExecutor 提供的 3 个 submit() 方法和 1 个 FutureTask 工具类来支持获得任务执行结果的需求。```java// 提交Runnable任务Future<?>submit(Runnable task);// 提交Callable任务<T> Future<T>submit(Callable<T> task);// 提交Runnable任务及结果引用<T> Future<T>submit(Runnable task, T result);
这 3 个 submit() 方法之间的区别在于方法参数不同,下面我们简要介绍一下。
1.提交 Runnable 任务 submit(Runnable task) :这个方法的参数是一个 Runnable 接口,Runnable 接口的 run() 方法是没有返回值的,所以 submit(Runnable task) 这个方法返回的 Future 仅可以用来断言任务已经结束了,类似于 Thread.join()。
2.提交 Callable 任务 submit(Callable task):这个方法的参数是一个 Callable 接口,它只有一个 call() 方法,并且这个方法是有返回值的,所以这个方法返回的 Future 对象可以通过调用其 get() 方法来获取任务的执行结果。
3.提交 Runnable 任务及结果引用 submit(Runnable task, T result):这个方法很有意思,假设这个方法返回的 Future 对象是 f,f.get() 的返回值就是传给 submit() 方法的参数 result。这个方法该怎么用呢?下面这段示例代码展示了它的经典用法。需要你注意的是 Runnable 接口的实现类 Task 声明了一个有参构造函数 Task(Result r) ,创建 Task 对象的时候传入了 result 对象,这样就能在类 Task 的 run() 方法中对 result 进行各种操作了。result 相当于主线程和子线程之间的桥梁,通过它主子线程可以共享数据。
ExecutorService executor= Executors.newFixedThreadPool(1);// 创建Result对象rResult r = new Result();r.setAAA(a);// 提交任务Future<Result> future =executor.submit(new Task(r), r);Result fr = future.get();// 下面等式成立fr === r;fr.getAAA() === a;fr.getXXX() === xclass Task implements Runnable{Result r;//通过构造函数传入resultTask(Result r){this.r = r;}void run() {//可以操作resulta = r.getAAA();r.setXXX(x);}}
返回Future接口, Future 接口有 5 个方法, 需要注意的是:这两个 get() 方法都是阻塞式的,如果被调用的时候,任务还没有执行完,那么调用 get() 方法的线程会阻塞,直到任务执行完才会被唤醒。
// 取消任务boolean cancel(boolean mayInterruptIfRunning);// 判断任务是否已取消boolean isCancelled();// 判断任务是否已结束boolean isDone();// 获得任务执行结果get();// 获得任务执行结果,支持超时get(long timeout, TimeUnit unit);
FutureTask 工具类
FutureTask(Callable<V> callable);FutureTask(Runnable runnable, V result);
那如何使用 FutureTask 呢?其实很简单,FutureTask 实现了 Runnable 和 Future 接口,由于实现了 Runnable 接口,所以可以将 FutureTask 对象作为任务提交给 ThreadPoolExecutor 去执行,也可以直接被 Thread 执行;又因为实现了 Future 接口,所以也能用来获得任务的执行结果。下面的示例代码是将 FutureTask 对象提交给 ThreadPoolExecutor 去执行。
// 创建FutureTaskFutureTask<Integer> futureTask= new FutureTask<>(()-> 1+2);// 创建线程池ExecutorService es =Executors.newCachedThreadPool();// 提交FutureTaskes.submit(futureTask);// 获取计算结果Integer result = futureTask.get();
FutureTask 对象直接被 Thread 执行的示例代码如下所示
// 创建FutureTaskFutureTask<Integer> futureTask= new FutureTask<>(()-> 1+2);// 创建并启动线程Thread T1 = new Thread(futureTask);T1.start();// 获取计算结果Integer result = futureTask.get();
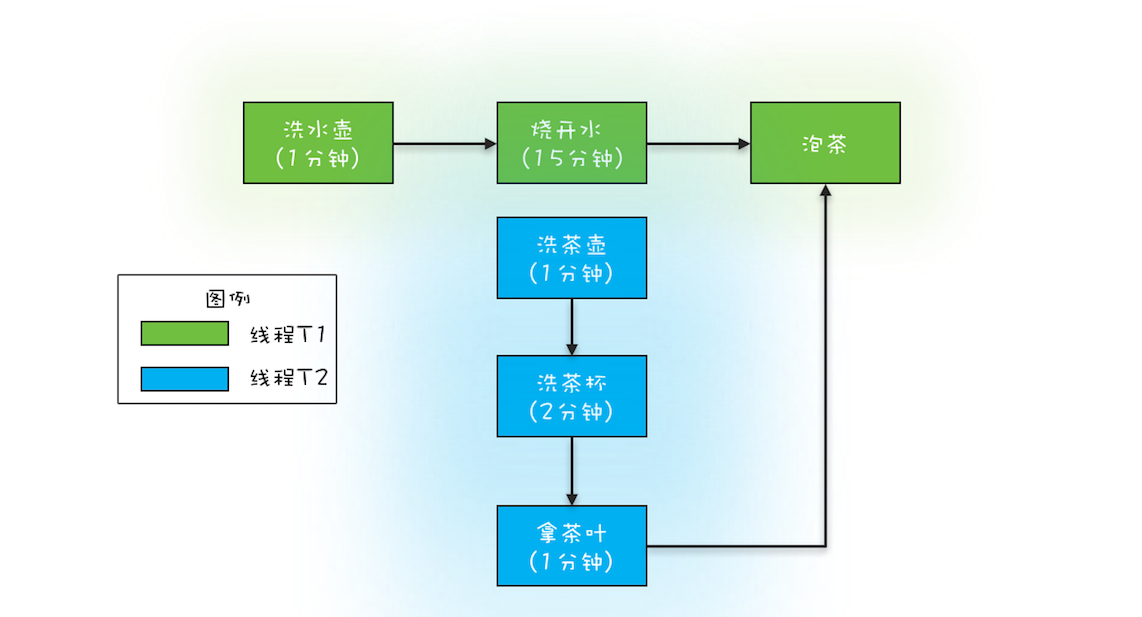
烧水泡茶的例子
// 创建任务T2的FutureTaskFutureTask<String> ft2= new FutureTask<>(new T2Task());// 创建任务T1的FutureTaskFutureTask<String> ft1= new FutureTask<>(new T1Task(ft2));// 线程T1执行任务ft1Thread T1 = new Thread(ft1);T1.start();// 线程T2执行任务ft2Thread T2 = new Thread(ft2);T2.start();// 等待线程T1执行结果System.out.println(ft1.get());// T1Task需要执行的任务:// 洗水壶、烧开水、泡茶class T1Task implements Callable<String>{FutureTask<String> ft2;// T1任务需要T2任务的FutureTaskT1Task(FutureTask<String> ft2){this.ft2 = ft2;}@OverrideString call() throws Exception {System.out.println("T1:洗水壶...");TimeUnit.SECONDS.sleep(1);System.out.println("T1:烧开水...");TimeUnit.SECONDS.sleep(15);// 获取T2线程的茶叶String tf = ft2.get();System.out.println("T1:拿到茶叶:"+tf);System.out.println("T1:泡茶...");return "上茶:" + tf;}}// T2Task需要执行的任务:// 洗茶壶、洗茶杯、拿茶叶class T2Task implements Callable<String> {@OverrideString call() throws Exception {System.out.println("T2:洗茶壶...");TimeUnit.SECONDS.sleep(1);System.out.println("T2:洗茶杯...");TimeUnit.SECONDS.sleep(2);System.out.println("T2:拿茶叶...");TimeUnit.SECONDS.sleep(1);return "龙井";}}// 一次执行结果:T1:洗水壶...T2:洗茶壶...T1:烧开水...T2:洗茶杯...T2:拿茶叶...T1:拿到茶叶:龙井T1:泡茶...上茶:龙井
总结:
利用多线程可以快速将一些串行的任务并行化,从而提高性能;如果任务之间有依赖关系,比如当前任务依赖前一个任务的执行结果,这种问题基本上都可以用 Future 来解决。在分析这种问题的过程中,建议你用有向图描述一下任务之间的依赖关系,同时将线程的分工也做好,类似于烧水泡茶最优分工方案那幅图。对照图来写代码,好处是更形象,且不易出错。

若有收获,就点个赞吧
0 人点赞
