Immutability模式:如何利用不变性解决并发问题?
解决并发问题,其实最简单的办法就是让共享变量只有读操作,而没有写操作
设计模式:不变性(Immutability)模式。所谓不变性,简单来讲,就是对象一旦被创建之后,状态就不再发生变化。
**
快速实现具备不可变性的类
将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了。更严格的做法是这个类本身也是 final 的,也就是不允许继承。
例如: String, Long, Integer, Double等基础类型的包装类都具备不可变性, 满足: 类和属性都是final的, 所有方法均是只读的
可变对象提供修改的功能==>创建并返回一个新的不可变对象
利用享元模式避免创建重复对象
Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。以减少创建对象的数量, 减少内存占用.
享元模式本质上其实就是一个对象池,利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。
**
Long 这个类并没有照搬享元模式,Long 内部维护了一个静态的对象池,仅缓存了[-128,127]之间的数字,这个对象池在 JVM 启动的时候就创建好了,而且这个对象池一直都不会变化,也就是说它是静态的。之所以采用这样的设计,是因为 Long 这个对象的状态共有 264 种,实在太多,不宜全部缓存,而[-128,127]之间的数字利用率最高。下面的示例代码出自 Java 1.8,valueOf() 方法就用到了 LongCache 这个缓存,你可以结合着来加深理解。
Long valueOf(long l) {final int offset = 128;// [-128,127]直接的数字做了缓存if (l >= -128 && l <= 127) {return LongCache.cache[(int)l + offset];}return new Long(l);}//缓存,等价于对象池//仅缓存[-128,127]直接的数字static class LongCache {static final Long cache[]= new Long[-(-128) + 127 + 1];static {for(int i=0; i<cache.length; i++)cache[i] = new Long(i-128);}}
“Integer 和 String 类型的对象不适合做锁”,其实基本上所有的基础类型的包装类都不适合做锁,因为它们内部用到了享元模式,这会导致看上去私有的锁,其实是共有的。
**
示例代码: A和B公用的一把锁
class A {Long al=Long.valueOf(1);public void setAX(){synchronized (al) {//省略代码无数}}}class B {Long bl=Long.valueOf(1);public void setBY(){synchronized (bl) {//省略代码无数}}}
使用 Immutability 模式的注意事项
- 对象的所有属性都是 final 的,并不能保证不可变性;
在 Java 语言中,final 修饰的属性一旦被赋值,就不可以再修改,但是如果属性的类型是普通对象,那么这个普通对象的属性是可以被修改的。在使用 Immutability 模式的时候一定要确认保持不变性的边界在哪里,是否要求属性对象也具备不可变性。
- 不可变对象也需要正确发布。
不可变对象虽然是线程安全的,但是并不意味着引用这些不可变对象的对象就是线程安全的。例如在下面的代码中,Foo 具备不可变性,线程安全,但是类 Bar 并不是线程安全的,类 Bar 中持有对 Foo 的引用 foo,对 foo 这个引用的修改在多线程中并不能保证可见性和原子性。
示例代码:
//Foo线程安全final class Foo{final int age=0;final int name="abc";}//Bar线程不安全class Bar {Foo foo;void setFoo(Foo f){this.foo=f;}}
如果你的程序仅仅需要 foo 保持可见性,无需保证原子性,那么可以将 foo 声明为 volatile 变量,这样就能保证可见性。如果你的程序需要保证原子性,那么可以通过原子类来实现。
示例代码:
public class SafeWM {class WMRange{final int upper;final int lower;WMRange(int upper,int lower){//省略构造函数实现}}final AtomicReference<WMRange>rf = new AtomicReference<>(new WMRange(0,0));// 设置库存上限void setUpper(int v){while(true){WMRange or = rf.get();// 检查参数合法性if(v < or.lower){throw new IllegalArgumentException();}WMRange nr = newWMRange(v, or.lower);if(rf.compareAndSet(or, nr)){return;}}}}
具备不变性的对象,只有一种状态,这个状态由对象内部所有的不变属性共同决定。其实还有一种更简单的不变性对象,那就是无状态。无状态对象内部没有属性,只有方法。除了无状态的对象,你可能还听说过无状态的服务、无状态的协议等等。无状态有很多好处,最核心的一点就是性能。在多线程领域,无状态对象没有线程安全问题,无需同步处理,自然性能很好;在分布式领域,无状态意味着可以无限地水平扩展,所以分布式领域里面性能的瓶颈一定不是出在无状态的服务节点上。
Copy-on-Write模式:不是延时策略的COW
String 这个类在实现 replace() 方法的时候,并没有更改原字符串里面 value[]数组的内容,而是创建了一个新字符串,这种方法在解决不可变对象的修改问题时经常用到. 本质上是一种 Copy-on-Write 方法。所谓 Copy-on-Write,经常被缩写为 COW 或者 CoW,顾名思义就是写时复制。不可变对象的写操作往往都是使用 Copy-on-Write 方法解决的.
Copy-on-Write 模式的应用领域
用 Copy-on-Write 更多地体现的是一种延时策略,只有在真正需要复制的时候才复制,而不是提前复制好, Copy-on-Write 还支持按需复制.
Java 提供的 Copy-on-Write 容器,由于在修改的同时会复制整个容器,所以在提升读操作性能的同时,是以内存复制为代价的。
CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器,它们背后的设计思想就是 Copy-on-Write;通过 Copy-on-Write 这两个容器实现的读操作是无锁的,由于无锁,所以将读操作的性能发挥到了极致。
CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器在修改的时候会复制整个数组,所以如果容器经常被修改或者这个数组本身就非常大的时候,是不建议使用的。反之,如果是修改非常少、数组数量也不大,并且对读性能要求苛刻的场景,使用 Copy-on-Write 容器效果就非常好了。
Copy-on-Write 最大的应用领域还是在函数式编程领域。函数式编程的基础是不可变性(Immutability),所以函数式编程里面所有的修改操作都需要 Copy-on-Write 来解决。
案例
我曾经写过一个 RPC 框架,有点类似 Dubbo,服务提供方是多实例分布式部署的,所以服务的客户端在调用 RPC 的时候,会选定一个服务实例来调用,这个选定的过程本质上就是在做负载均衡,而做负载均衡的前提是客户端要有全部的路由信息。例如在下图中,A 服务的提供方有 3 个实例,分别是 192.168.1.1、192.168.1.2 和 192.168.1.3,客户端在调用目标服务 A 前,首先需要做的是负载均衡,也就是从这 3 个实例中选出 1 个来,然后再通过 RPC 把请求发送选中的目标实例。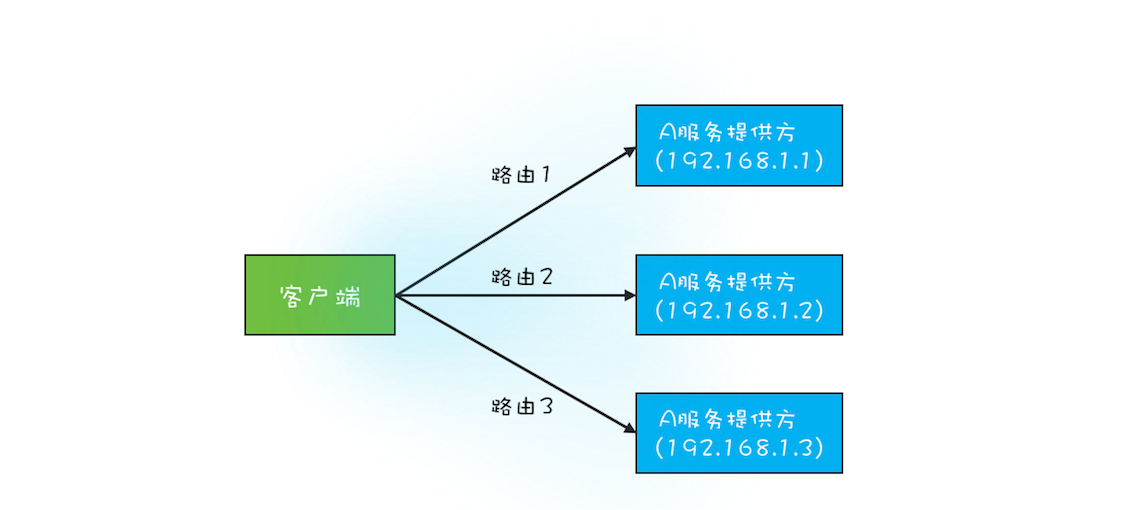
RPC 路由关系图RPC 框架的一个核心任务就是维护服务的路由关系,我们可以把服务的路由关系简化成下图所示的路由表。当服务提供方上线或者下线的时候,就需要更新客户端的这张路由表。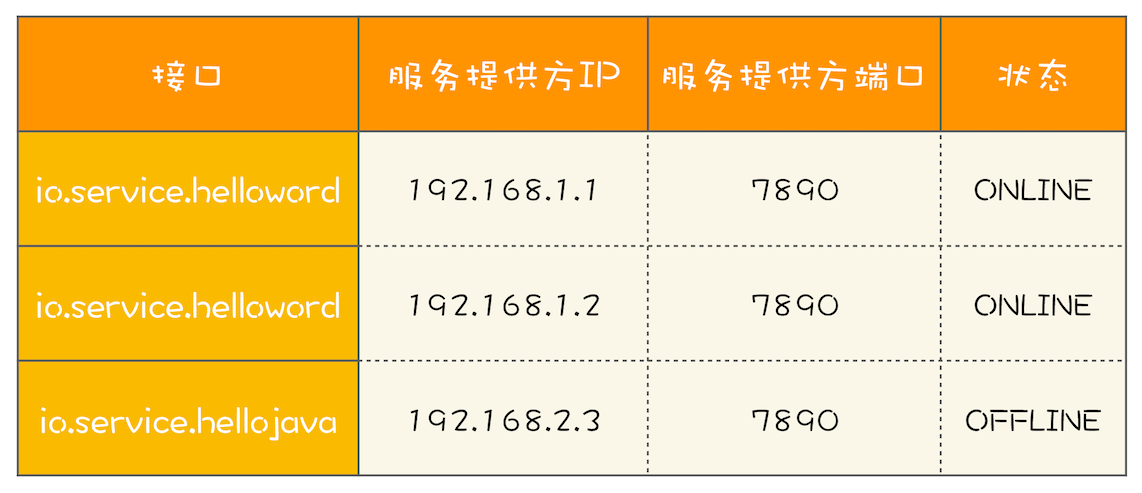
我们首先来分析一下如何用程序来实现。每次 RPC 调用都需要通过负载均衡器来计算目标服务的 IP 和端口号,而负载均衡器需要通过路由表获取接口的所有路由信息,也就是说,每次 RPC 调用都需要访问路由表,所以访问路由表这个操作的性能要求是很高的。不过路由表对数据的一致性要求并不高,一个服务提供方从上线到反馈到客户端的路由表里,即便有 5 秒钟,很多时候也都是能接受的(5 秒钟,对于以纳秒作为时钟周期的 CPU 来说,那何止是一万年,所以路由表对一致性的要求并不高)。而且路由表是典型的读多写少类问题,写操作的量相比于读操作,可谓是沧海一粟,少得可怜。
通过以上分析,你会发现一些关键词:对读的性能要求很高,读多写少,弱一致性。它们综合在一起,你会想到什么呢?CopyOnWriteArrayList 和 CopyOnWriteArraySet 天生就适用这种场景啊。所以下面的示例代码中,RouteTable 这个类内部我们通过ConcurrentHashMap>这个数据结构来描述路由表,ConcurrentHashMap 的 Key 是接口名,Value 是路由集合,这个路由集合我们用是 CopyOnWriteArraySet。
下面我们再来思考 Router 该如何设计,服务提供方的每一次上线、下线都会更新路由信息,这时候你有两种选择。一种是通过更新 Router 的一个状态位来标识,如果这样做,那么所有访问该状态位的地方都需要同步访问,这样很影响性能。另外一种就是采用 Immutability 模式,每次上线、下线都创建新的 Router 对象或者删除对应的 Router 对象。由于上线、下线的频率很低,所以后者是最好的选择。
Router 的实现代码如下所示,是一种典型 Immutability 模式的实现,需要你注意的是我们重写了 equals 方法,这样 CopyOnWriteArraySet 的 add() 和 remove() 方法才能正常工作。
示例代码:
//路由信息public final class Router{private final String ip;private final Integer port;private final String iface;//构造函数public Router(String ip,Integer port, String iface){this.ip = ip;this.port = port;this.iface = iface;}//重写equals方法public boolean equals(Object obj){if (obj instanceof Router) {Router r = (Router)obj;return iface.equals(r.iface) &&ip.equals(r.ip) &&port.equals(r.port);}return false;}public int hashCode() {//省略hashCode相关代码}}//路由表信息public class RouterTable {//Key:接口名//Value:路由集合ConcurrentHashMap<String, CopyOnWriteArraySet<Router>>rt = new ConcurrentHashMap<>();//根据接口名获取路由表public Set<Router> get(String iface){return rt.get(iface);}//删除路由public void remove(Router router) {Set<Router> set=rt.get(router.iface);if (set != null) {set.remove(router);}}//增加路由public void add(Router router) {Set<Router> set = rt.computeIfAbsent(route.iface, r ->new CopyOnWriteArraySet<>());set.add(router);}}
线程本地存储模式:没有共享,就没有伤害
多个线程同时读写同一共享变量存在并发问题, 从共享变量出发—>避免共享
ThreadLocal 的使用方法
示例代码:下面这个静态类 ThreadId 会为每个线程分配一个唯一的线程 Id,如果一个线程前后两次调用 ThreadId 的 get() 方法,两次 get() 方法的返回值是相同的。但如果是两个线程分别调用 ThreadId 的 get() 方法,那么两个线程看到的 get() 方法的返回值是不同的。
static class ThreadId {static final AtomicLongnextId=new AtomicLong(0);//定义ThreadLocal变量static final ThreadLocal<Long>tl=ThreadLocal.withInitial(()->nextId.getAndIncrement());//此方法会为每个线程分配一个唯一的Idstatic long get(){return tl.get();}}
**
示例代码: 如何在并发场景下使用SimpleDateFormat (SimpleDateFormat线程不安全)
static class SafeDateFormat {//定义ThreadLocal变量static final ThreadLocal<DateFormat>tl=ThreadLocal.withInitial(()-> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));static DateFormat get(){return tl.get();}}//不同线程执行下面代码//返回的df是不同的DateFormat df =SafeDateFormat.get();
ThreadLocal 的工作原理
在解释 ThreadLocal 的工作原理之前, 你先自己想想:如果让你来实现 ThreadLocal 的功能,你会怎么设计呢?ThreadLocal 的目标是让不同的线程有不同的变量 V,那最直接的方法就是创建一个 Map,它的 Key 是线程,Value 是每个线程拥有的变量 V,ThreadLocal 内部持有这样的一个 Map 就可以了。你可以参考下面的示意图和示例代码来理解。
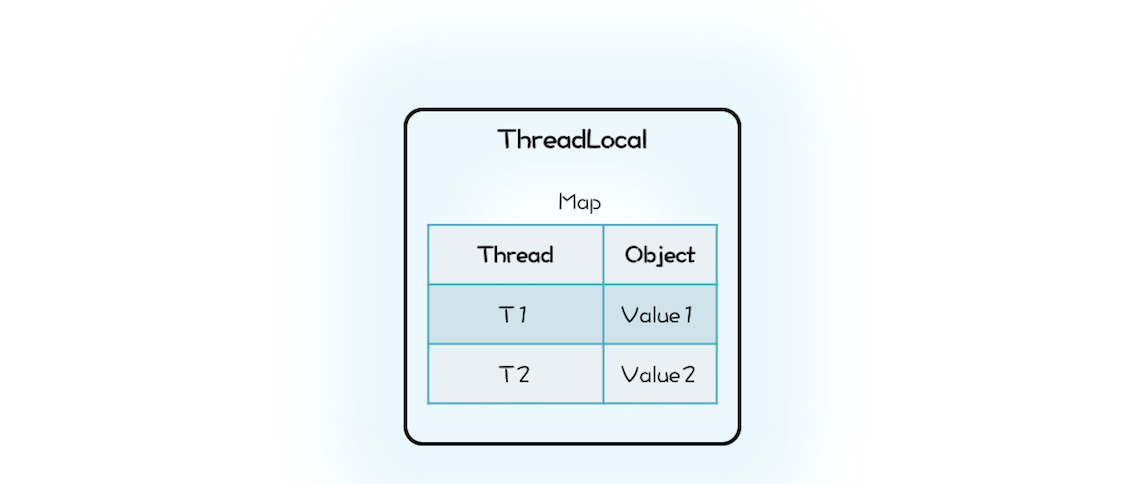
class MyThreadLocal<T> {Map<Thread, T> locals =new ConcurrentHashMap<>();//获取线程变量T get() {return locals.get(Thread.currentThread());}//设置线程变量void set(T t) {locals.put(Thread.currentThread(), t);}}
那 Java 的 ThreadLocal 是这么实现的吗?这一次我们的设计思路和 Java 的实现差异很大。Java 的实现里面也有一个 Map,叫做 ThreadLocalMap,不过持有 ThreadLocalMap 的不是 ThreadLocal,而是 Thread。Thread 这个类内部有一个私有属性 threadLocals,其类型就是 ThreadLocalMap,ThreadLocalMap 的 Key 是 ThreadLocal。你可以结合下面的示意图和精简之后的 Java 实现代码来理解。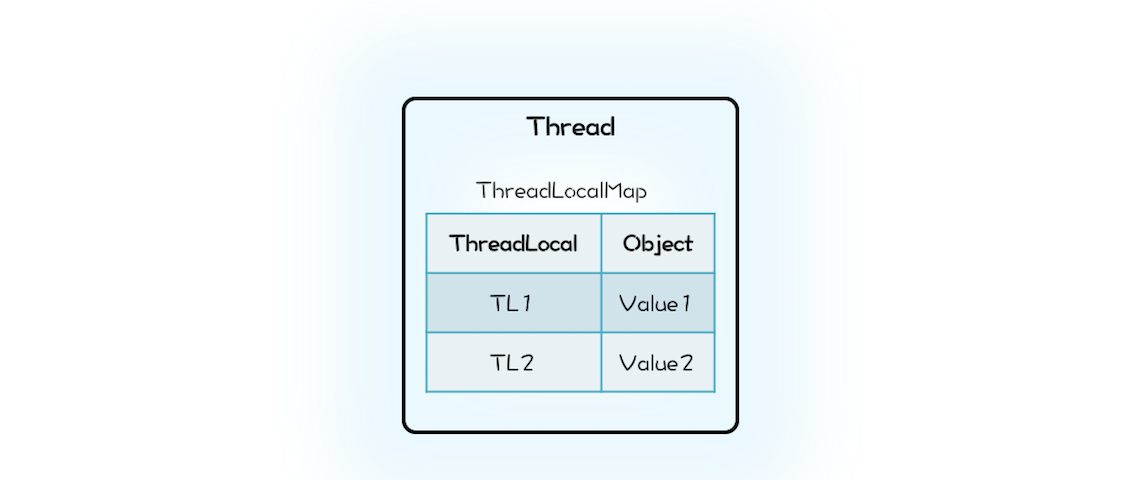
**
class Thread {//内部持有ThreadLocalMapThreadLocal.ThreadLocalMapthreadLocals;}class ThreadLocal<T>{public T get() {//首先获取线程持有的//ThreadLocalMapThreadLocalMap map =Thread.currentThread().threadLocals;//在ThreadLocalMap中//查找变量Entry e =map.getEntry(this);return e.value;}static class ThreadLocalMap{//内部是数组而不是MapEntry[] table;//根据ThreadLocal查找EntryEntry getEntry(ThreadLocal key){//省略查找逻辑}//Entry定义static class Entry extendsWeakReference<ThreadLocal>{Object value;}}}
ThreadLocal 与内存泄露
在线程池中使用 ThreadLocal 为什么可能导致内存泄露呢?原因就出在线程池中线程的存活时间太长,往往都是和程序同生共死的,这就意味着 Thread 持有的 ThreadLocalMap 一直都不会被回收,再加上 ThreadLocalMap 中的 Entry 对 ThreadLocal 是弱引用(WeakReference),所以只要 ThreadLocal 结束了自己的生命周期是可以被回收掉的。但是 Entry 中的 Value 却是被 Entry 强引用的,所以即便 Value 的生命周期结束了,Value 也是无法被回收的,从而导致内存泄露。那在线程池中,我们该如何正确使用 ThreadLocal 呢?其实很简单,既然 JVM 不能做到自动释放对 Value 的强引用,那我们手动释放就可以了。如何能做到手动释放呢?估计你马上想到 try{}finally{}方案了,这个简直就是手动释放资源的利器。示例的代码如下,你可以参考学习。
ExecutorService es;ThreadLocal tl;es.execute(()->{//ThreadLocal增加变量tl.set(obj);try {// 省略业务逻辑代码}finally {//手动清理ThreadLocaltl.remove();}});
InheritableThreadLocal 与继承性
通过 ThreadLocal 创建的线程变量,其子线程是无法继承的。也就是说你在线程中通过 ThreadLocal 创建了线程变量 V,而后该线程创建了子线程,你在子线程中是无法通过 ThreadLocal 来访问父线程的线程变量 V 的。
如果你需要子线程继承父线程的线程变量,那该怎么办呢?其实很简单,Java 提供了 InheritableThreadLocal 来支持这种特性,InheritableThreadLocal 是 ThreadLocal 子类,所以用法和 ThreadLocal 相同,这里就不多介绍了。
不过,我完全不建议你在线程池中使用 InheritableThreadLocal,不仅仅是因为它具有 ThreadLocal 相同的缺点——可能导致内存泄露,更重要的原因是:线程池中线程的创建是动态的,很容易导致继承关系错乱,如果你的业务逻辑依赖 InheritableThreadLocal,那么很可能导致业务逻辑计算错误,而这个错误往往比内存泄露更要命。
总结
线程本地存储模式本质上是一种避免共享的方案,由于没有共享,所以自然也就没有并发问题。如果你需要在并发场景中使用一个线程不安全的工具类,最简单的方案就是避免共享。避免共享有两种方案,一种方案是将这个工具类作为局部变量使用,另外一种方案就是线程本地存储模式。这两种方案,局部变量方案的缺点是在高并发场景下会频繁创建对象,而线程本地存储方案,每个线程只需要创建一个工具类的实例,所以不存在频繁创建对象的问题。

若有收获,就点个赞吧
0 人点赞
