进程与线程
进程是程序的一次执行过程,是系统运行程序的基本单位. 系统运行一个程序即是一个进程从创建,运行到消亡的过程。
线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。
并发与并行
并发: 同一时间段, 多个任务都在执行
并行: 单位时间内, 多个任务同时执行
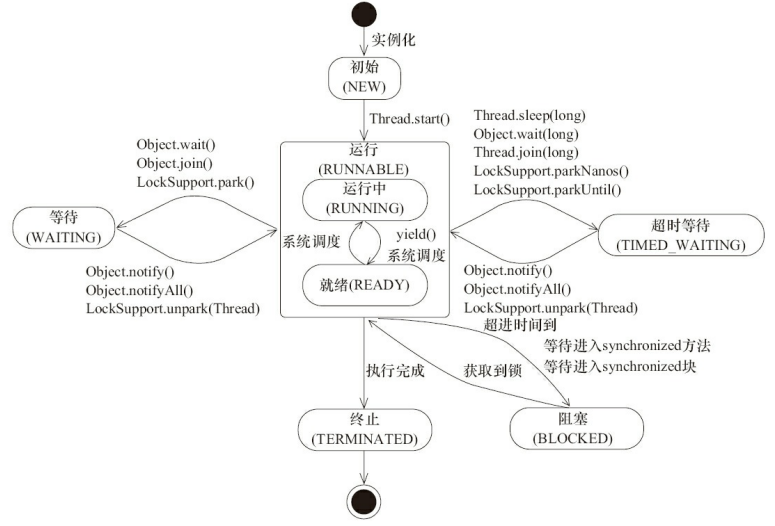
线程生命周期
这里再放一次, 这个图要能画出来
wait与sleep方法的区别
参考: https://www.cnblogs.com/loren-Yang/p/7538482.html
- sleep方法属于Thread类中方法, 表示让当前线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可运行状态. 一个线程对象调用了sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。
- wait属于Object的成员方法,一旦一个对象调用了wait方法,必须要采用notify()和notifyAll()方法唤醒该进程;如果线程拥有某个或某些对象的同步锁,那么在调用了wait()后,这个线程就会释放它持有的所有同步资源,而不限于这个被调用了wait()方法的对象。
- wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用(使用范围)
补充两个重要的方法:yield()和join()
- yield方法
暂停当前正在执行的线程对象。
yield()方法是停止当前线程,让同等优先权的线程或更高优先级的线程有执行的机会。如果没有的话,那么yield()方法将不会起作用,并且由可执行状态后马上又被执行。
- join方法
join方法是用于在某一个线程的执行过程中调用另一个线程执行,等到被调用的线程执行结束后,再继续执行当前线程。如:t.join();//主要用于等待t线程运行结束,若无此句,main则会执行完毕,导致结果不可预测。
synchronized关键字与ReentrantLock区别
synchronized是依赖于 JVM 实现的,线程试图获取锁也就是获取 对象监视器monitor的持有权。ReentrantLock是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成)。
相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:
- 等待可中断 :
ReentrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。 - 可实现公平锁 :
ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。ReentrantLock默认情况是非公平的,可以通过ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。 - 可实现选择性通知(锁可以绑定多个条件):
synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制。ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition()方法。
ThreadLocal的原理
Thread类中含有ThreadLocalMap类型的变量,而ThreadLocalMap是ThreadLocal的静态内部类, Map的key是ThreadLocal对象, value是对应的值;ThreadLocal可以看做是ThreadLocalMap的封装,传递了变量值,当当前线程调用ThreadLocal进行get, set方法时, 就会创建或者往ThreadLocalMap中添加键值对。即,实际的数据存储在Thread的map变量中,因此线程安全。
ThreadLocal内存泄漏
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后 最好手动调用remove()方法
线程池优点
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
补充:
4种线程池参见: https://www.yuque.com/fvy7xd/xinzhang/mqn3ca#txV6Z
线程池参数意义参见: https://www.yuque.com/fvy7xd/xinzhang/scpzae
确定线程池大小
有一个简单并且适用面比较广的公式:
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
如何判断是 CPU 密集任务还是 IO 密集任务?
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。单凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。

若有收获,就点个赞吧
0 人点赞
