分析排序算法
排序算法的执行效率
- 最好情况、最坏情况、平均情况时间复杂度
- 时间复杂度的系数、常数 、低阶
(在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。)
- 比较次数和交换(或移动)次数
排序算法的内存消耗
- 空间复杂度
- 原地排序, 原地排序算法, 特指空间复杂度是 O(1) 的排序算法。
排序算法的稳定性
如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
实际应用中, 比如要求先按订单金额排序, 金额一致的再按订单创建时间排序.
冒泡排序
一次排序后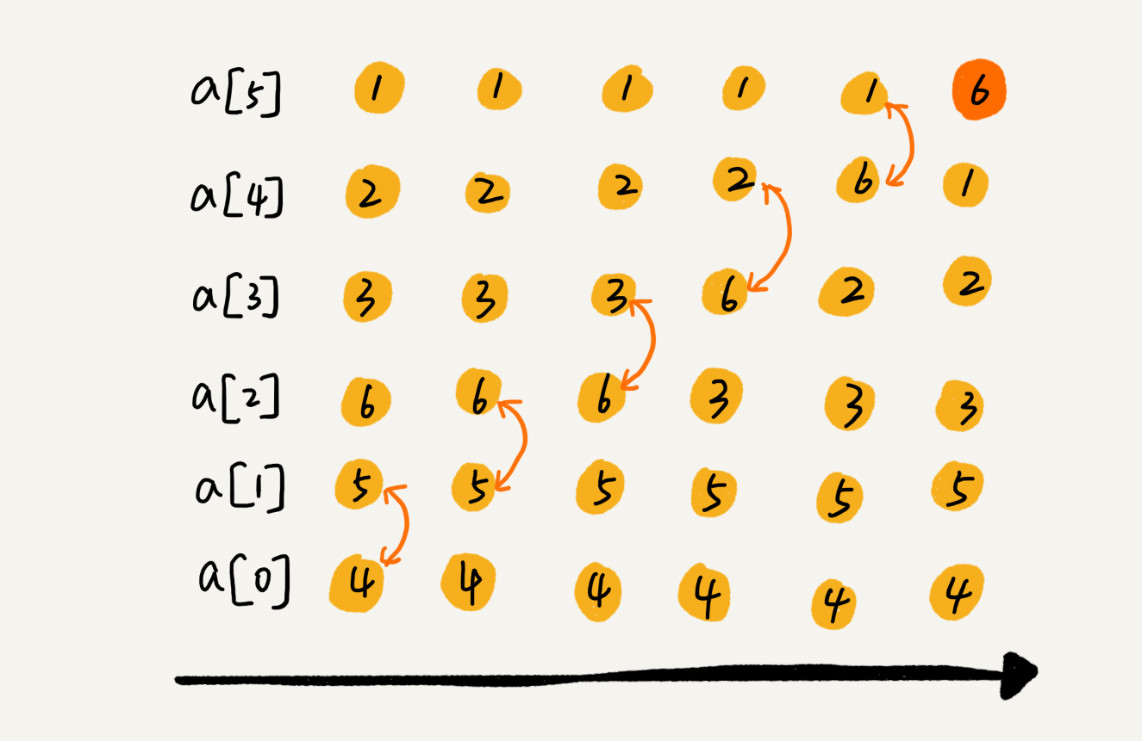
n次排序后
优化, 如果有序则提前结束排序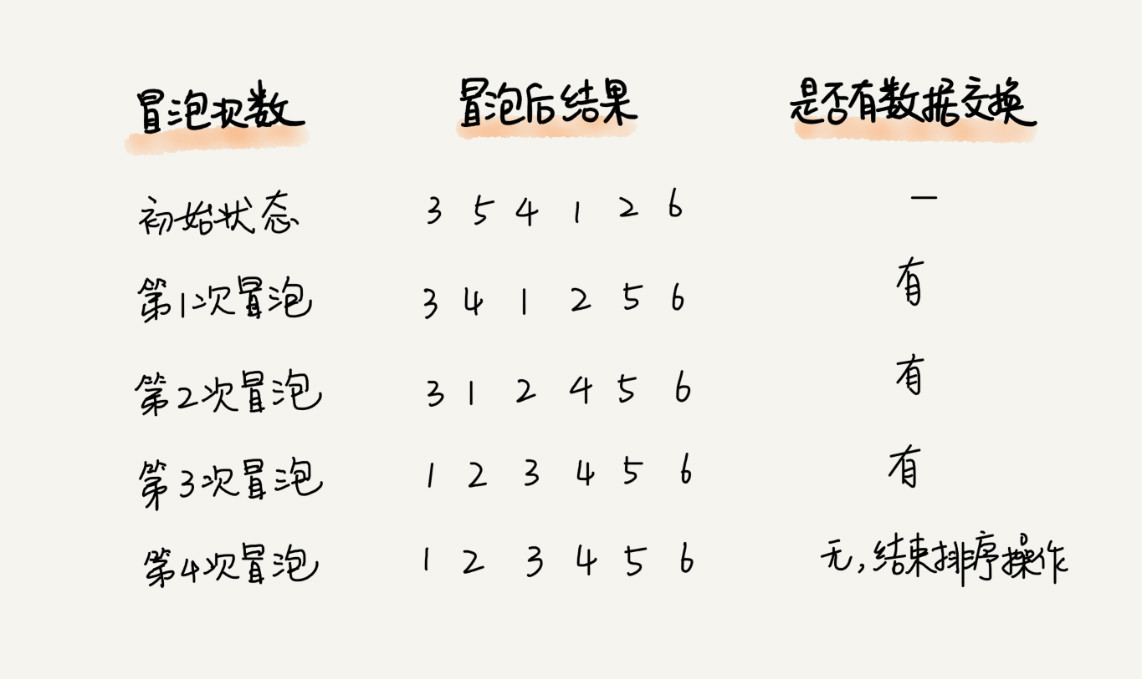
// 冒泡排序,a表示数组,n表示数组大小public void bubbleSort(int[] a, int n) {if (n <= 1) return;for (int i = 0; i < n; ++i) {// 提前退出冒泡循环的标志位boolean flag = false;for (int j = 0; j < n - i - 1; ++j) {if (a[j] > a[j+1]) { // 交换int tmp = a[j];a[j] = a[j+1];a[j+1] = tmp;flag = true; // 表示有数据交换}}if (!flag) break; // 没有数据交换,提前退出}}
特征:
- 只使用了一个临时变量, 空间复杂度是O(1), 因此是原地排序算法
- 两元素相等不换位置, 是稳定的排序算法
- 时间复杂度, 平均情况下时间复杂度为O(n), 推导过程太复杂了略

插入排序
我们将数组中的数据分为两个区间,已排序区间和未排序区间。
初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。

插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
// 插入排序,a表示数组,n表示数组大小public void insertionSort(int[] a, int n) {if (n <= 1) return;for (int i = 1; i < n; ++i) {int value = a[i];int j = i - 1;// 查找插入的位置for (; j >= 0; --j) {if (a[j] > value) {a[j+1] = a[j]; // 数据移动} else {break;}}a[j+1] = value; // 插入数据}}
特征:
- 空间复杂度是O(1), 是原地排序算法
- 在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变,所以插入排序是稳定的排序算法。
- 如果数组有序, 只用循环一次, 最好时间复杂度是O(n); 如果数组逆序, 最坏时间复杂度是O(n); 平均时间复杂度是O(n)
选择排序
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。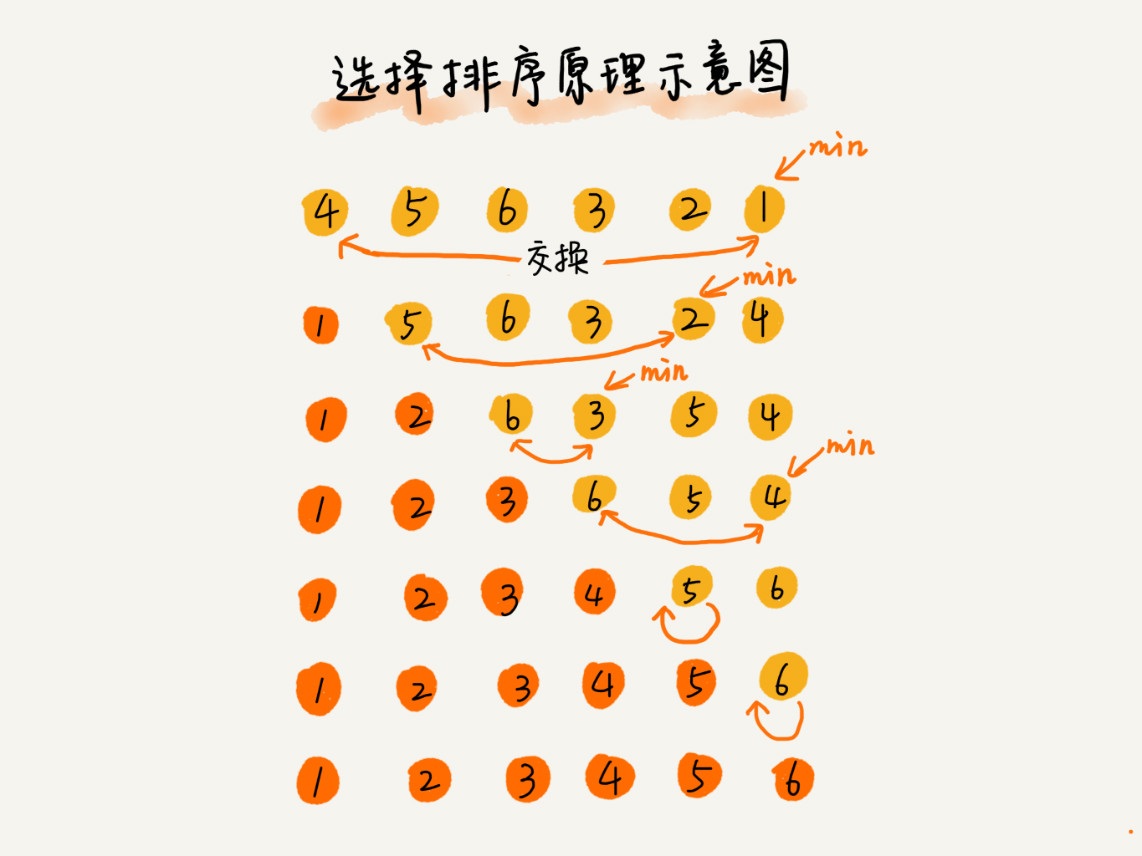
private static void sort2(int[] arr) {if (arr.length <= 1) {return;}for (int i = 0; i < arr.length; i++) {int min = i;for (int j = i + 1; j < arr.length; j++) {if (arr[j] < arr[min]) {min = j;}}if (i != min) {int temp = arr[i];arr[i] = arr[min];arr[min] = temp;}}}
特征:
- 空间复杂度为O(1), 是原地排序算法不用说了
- 不是稳定的
- 最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n2)
为什么插入排序要比冒泡排序更受欢迎呢?
从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个
所以,虽然冒泡排序和插入排序在时间复杂度上是一样的,都是 O(n2),但是如果我们希望把性能优化做到极致,那肯定首选插入排序。插入排序的算法思路也有很大的优化空间,我们只是讲了最基础的一种。如果你对插入排序的优化感兴趣,可以自行学习一下希尔排序。
冒泡排序中数据的交换操作:if (a[j] > a[j+1]) { // 交换int tmp = a[j];a[j] = a[j+1];a[j+1] = tmp;flag = true;}插入排序中数据的移动操作:if (a[j] > value) {a[j+1] = a[j]; // 数据移动} else {break;}
总结: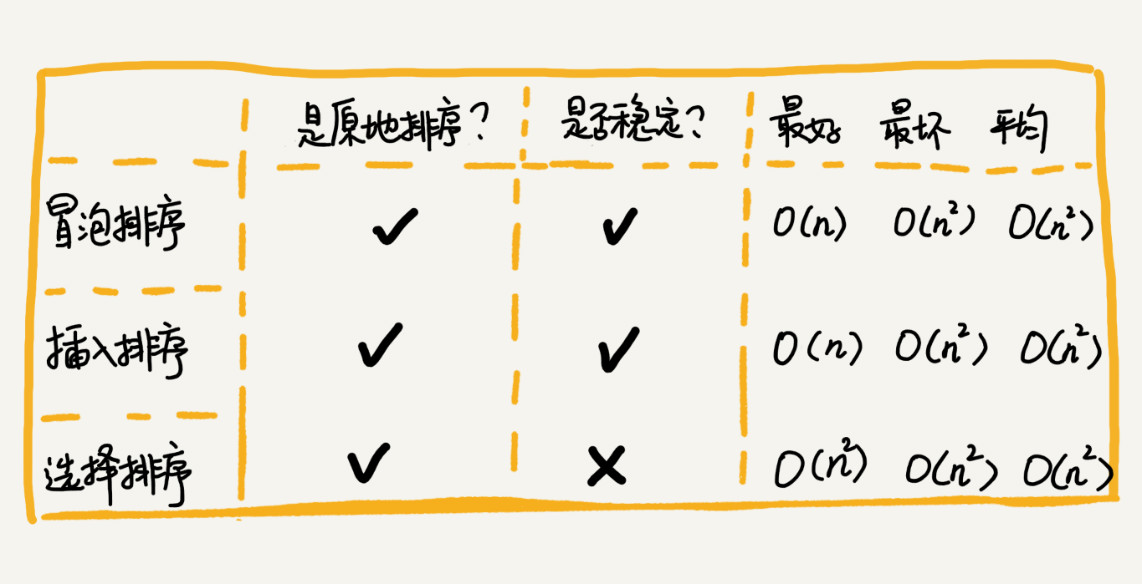
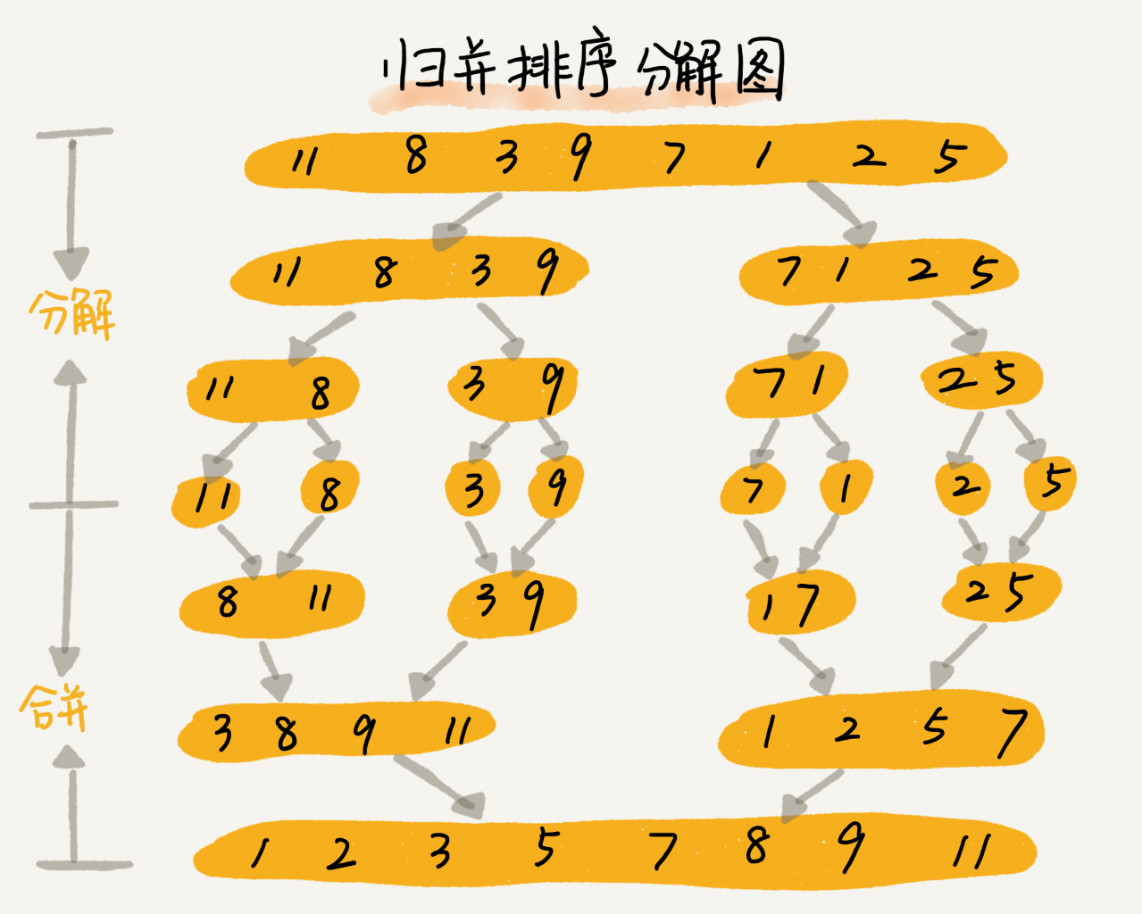
归并排序
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。
如何用递归代码来实现归并排序?
写递归代码的技巧就是,分析得出递推公式,然后找到终止条件,最后将递推公式翻译成递归代码。
递推公式:merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))终止条件:p >= r 不用再继续分解
public class MergeSort {public static void main(String[] args) {int[] arr = {2, 4, 3, 1, 2, 6, 3, 4};sort(arr);Arrays.stream(arr).forEach(System.out::print);}private static void sort(int[] arr) {// 排序前先申请临时存储空间int[] temp = new int[arr.length];mergeSort(arr, 0, arr.length - 1, temp);}private static void mergeSort(int[] arr, int left, int right, int[] temp) {if (left >= right) {return;}int middle = (left + right) / 2;mergeSort(arr, left, middle, temp);mergeSort(arr, middle + 1, right, temp);merge(arr, left, middle, right, temp);}private static void merge(int[] arr, int left, int middle, int right, int[] temp) {int i = left;int j = middle + 1;int index = 0;while (i <= middle && j <= right) {if (arr[i] <= arr[j]) {temp[index++] = arr[i++];} else {temp[index++] = arr[j++];}}// 将序列剩余元素填充进tempwhile (i <= middle) {temp[index++] = arr[i++];}while (j <= right) {temp[index++] = arr[j++];}// 将temp赋给arrindex = 0;while (left <= right) {arr[left++] = temp[index++];}}}
特征:
- 稳定, 稳定性看merge方法, 最后合并俩数组时, 如果有相同的元素, 是先将左边数组元素复制到temp中, 因此次序与原数组一致, 是稳定的
- 时间复杂度, O(nlogn)
- 空间复杂度, O(n)
快速排序
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
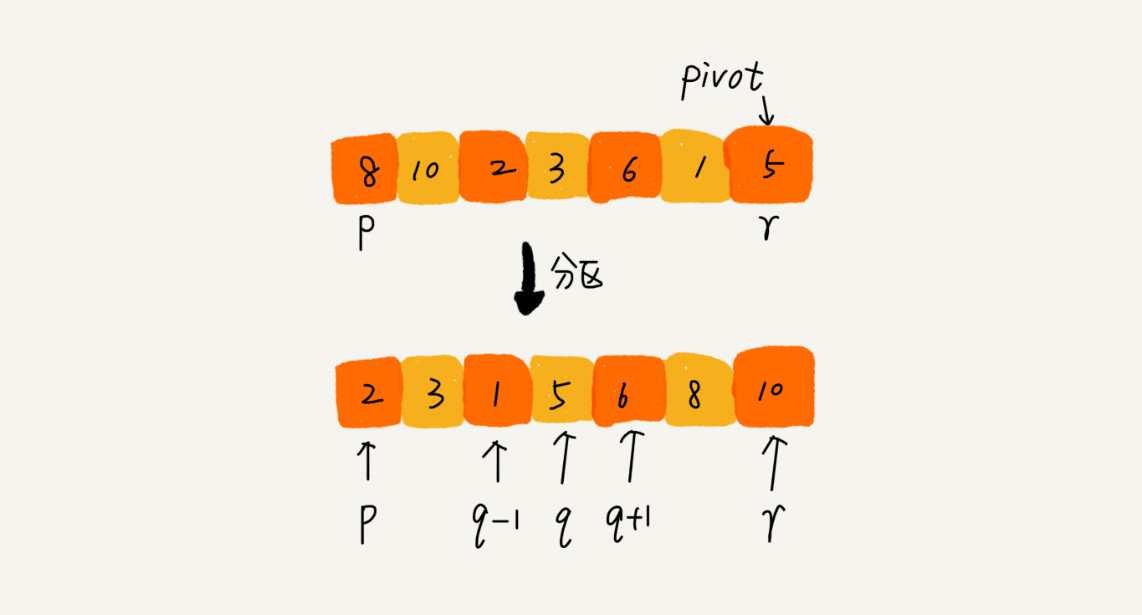
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。如果我们用递推公式来将上面的过程写出来的话,就是这样:
递推公式:quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)终止条件:p >= r
再转成伪代码
// 快速排序,A是数组,n表示数组的大小quick_sort(A, n) {quick_sort_c(A, 0, n-1)}// 快速排序递归函数,p,r为下标quick_sort_c(A, p, r) {if p >= r then returnq = partition(A, p, r) // 获取分区点quick_sort_c(A, p, q-1)quick_sort_c(A, q+1, r)}
如果我们不考虑空间消耗的话,partition() 分区函数可以写得非常简单。我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p….r]。
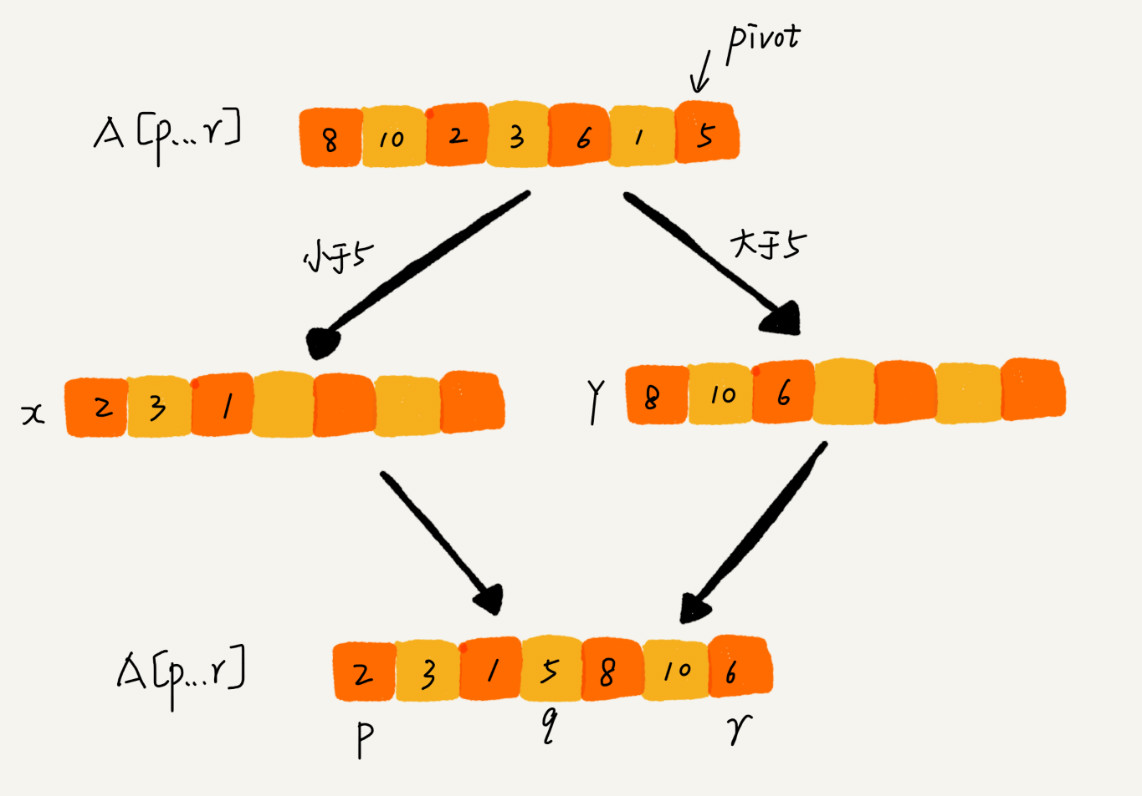
但是,如果按照这种思路实现的话,partition() 函数就需要很多额外的内存空间,所以快排就不是原地排序算法了。如果我们希望快排是原地排序算法,那它的空间复杂度得是 O(1),那 partition() 分区函数就不能占用太多额外的内存空间,我们就需要在 A[p…r]的原地完成分区操作。
实现思路如下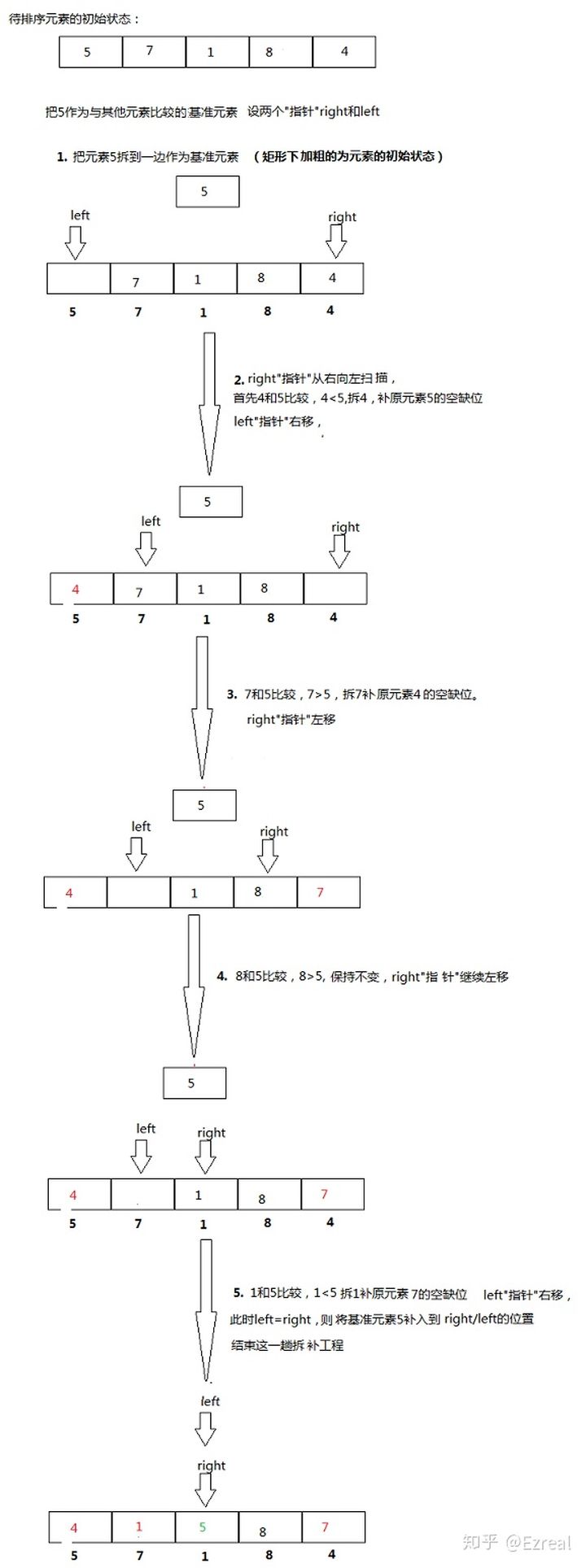
public class QuickSort {public static void main(String[] args) {int[] arr = {2, 4, 3, 1, 2, 6, 3, 4};sort(arr);Arrays.stream(arr).forEach(System.out::print);}private static void sort(int[] arr) {quickSort(arr, 0, arr.length - 1);}private static void quickSort(int[] arr, int p, int r) {if (p >= r) {return;}// 获取分区点int q = partition(arr, p, r);quickSort(arr, p, q - 1);quickSort(arr, q + 1, r);}private static int partition(int[] arr, int p, int r) {// 将区间第一个数作为基准数int temp = arr[p];int i = p;int j = r;while (i < j) {// 从右边开始找, 比temp大的不动while (i < j && arr[j] > temp) {j--;}// 找到第一个比temp小的, 填到i的位置, 此时j位置空余arr[i] = arr[j];// 再从左边找, 同理, 比temp小的不动while (i < j && arr[i] <= temp) {i++;}// 找到第一个比temp大的, 填到j的空余位置, 使i位置空余arr[j] = arr[i];}// 最后将基准数填到i位置, i位置左侧都小于arr[i], 右侧都大于arr[i]arr[i] = temp;return i;}}
特征:
- 原地排序算法
- 不稳定
- 时间复杂度也是 O(nlogn)
- 与归并对比
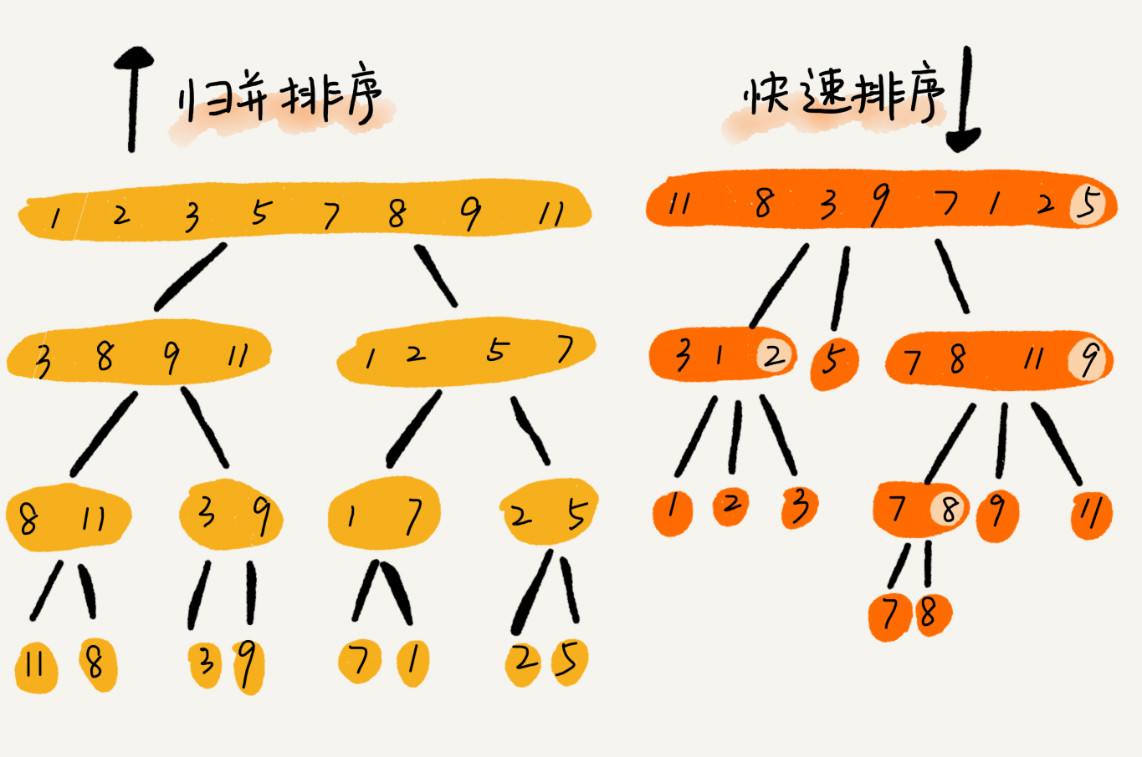
归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。
归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
总结:
冒泡排序、插入排序、选择排序这三种排序算法,它们的时间复杂度都是 O(n2),比较高,适合小规模数据的排序。
归并排序和快速排序。这两种排序算法适合大规模的数据排序,比上面那三种排序算法要更常用。

若有收获,就点个赞吧
0 人点赞
