普通索引和唯一索引比较
选择普通索引还是唯一索引?
- 业务正确性优先
在一些”归档库”的场景, 可以考虑普通索引.
(归档数据已经是确保没有唯一键冲突了, 由于唯一索引用不上 change buffer 的优化机制,因此如果业务可以接受,从性能角度出发建议优先考虑非唯一索引) ``` 选择普通索引还是唯一索引? 对于查询过程来说: a、普通索引,查到满足条件的第一个记录后,继续查找下一个记录,知道第一个不满足条件的记录 b、唯一索引,由于索引唯一性,查到第一个满足条件的记录后,停止检索 但是,两者的性能差距微乎其微。因为InnoDB根据数据页来读写的。 对于更新过程来说: 概念:change buffer 当需要更新一个数据页,如果数据页在内存中就直接更新,如果不在内存中,在不影响数据一致性的前提下,InnoDB会将这些更新操作缓存在change buffer中。下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中的与这个页有关的操作。
change buffer是可以持久化的数据。在内存中有拷贝,也会被写入到磁盘上
purge:将change buffer中的操作应用到原数据页上,得到最新结果的过程,成为purge 访问这个数据页会触发purge,系统有后台线程定期purge,在数据库正常关闭的过程中,也会执行purge
唯一索引的更新不能使用change buffer
change buffer用的是buffer pool里的内存,change buffer的大小,可以通过参数innodb_change_buffer_max_size来动态设置。这个参数设置为50的时候,表示change buffer的大小最多只能占用buffer pool的50%。
将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。 change buffer 因为减少了随机磁盘访问,所以对更新性能的提升很明显。
change buffer使用场景 在一个数据页做purge之前,change buffer记录的变更越多,收益就越大。 对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在change buffer,但之后由于马上要访问这个数据页,会立即触发purge过程。 这样随机访问IO的次数不会减少,反而增加了change buffer的维护代价。所以,对于这种业务模式来说,change buffer反而起到了副作用。
索引的选择和实践: 尽可能使用普通索引。 redo log主要节省的是随机写磁盘的IO消耗(转成顺序写),而change buffer主要节省的则是随机读磁盘的IO消耗。
<a name="eTTxR"></a>## MySQL优化器选错索引优化优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的 CPU 资源越少。当然,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。**索引选择异常时的处理方式**1. **采用 force index 强行选择一个索引.**MySQL 会根据词法解析的结果分析出可能可以使用的索引作为候选项,然后在候选列表中依次判断每个索引需要扫描多少行。如果 force index 指定的索引在候选索引列表中,就直接选择这个索引,不再评估其他索引的执行代价。<br />2. **考虑修改语句,引导 MySQL 使用我们期望的索引**之前优化器选择使用索引 b,是因为它认为使用索引 b 可以避免排序(b 本身是索引,已经是有序的了,如果选择索引 b 的话,不需要再做排序,只需要遍历),所以即使扫描行数多,也判定为代价更小。现在 order by b,a 这种写法,要求按照 b,a 排序,就意味着使用这两个索引都需要排序。因此,扫描行数成了影响决策的主要条件,于是此时优化器选了只需要扫描 1000 行的索引 a。3. 在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。<a name="1i6ER"></a>## 字符串加索引1. 直接创建完整索引,这样可能比较占用空间;2. 创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引;索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低。但使用前缀索引就用不上覆盖索引对查询性能的优化了.建立索引时关注的是区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。因此,我们可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。<br />首先,你可以使用下面这个语句,算出这个列上有多少个不同的值:```sqlmysql> select count(distinct email) as L from SUser;
然后,依次选取不同长度的前缀来看这个值,比如我们要看一下 4~7 个字节的前缀索引,可以用这个语句:
mysql> selectcount(distinct left(email,4))as L4,count(distinct left(email,5))as L5,count(distinct left(email,6))as L6,count(distinct left(email,7))as L7,from SUser;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如 5%。然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满足,你就可以选择前缀长度为 6。
- 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题;
比如身份证的查询, 身份证前6位是地址码, 区分度太低, 可以倒序做索引优化
mysql> select field_list from t where id_card = reverse('input_id_card_string');
- 创建 hash 字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
比如身份证号的查询, 可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
然后每次插入新记录的时候,都同时用 crc32() 这个函数得到校验码填到这个新字段。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
倒序存储和使用 hash 字段这两种方法的异同点
相同点:
- 都不支持范围查询。
不同点:
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。如果只从这两个函数的计算复杂度来看的话,reverse 函数额外消耗的 CPU 资源会更小些。
从查询效率上看,使用 hash 字段方式的查询性能相对更稳定一些。因为 crc32 算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近 1。而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
如何释放表空间
增删改查会产生数据空洞
- delete 命令其实只是把记录的位置,或者数据页标记为了“可复用”,但磁盘文件的大小是不会变的。也就是说,通过 delete 命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是“空洞”。
- 不止是删除数据会造成空洞,插入数据也会。如果数据是随机插入的,就可能造成索引的数据页分裂。
- 另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。不难理解,这也是会造成空洞的。也就是说,经过大量增删改的表,都是可能是存在空洞的。所以,如果能够把这些空洞去掉,就能达到收缩表空间的目的。
重建表能去掉空洞
你可以新建一个与表 A 结构相同的表 B,然后按照主键 ID 递增的顺序,把数据一行一行地从表 A 里读出来再插入到表 B 中。由于表 B 是新建的表,所以表 A 主键索引上的空洞,在表 B 中就都不存在了.
alter table A engine=InnoDB
在 MySQL 5.5 版本之前,这个命令的执行流程跟我们前面描述的差不多,区别只是这个临时表 B 不需要你自己创建,MySQL 会自动完成转存数据、交换表名、删除旧表的操作。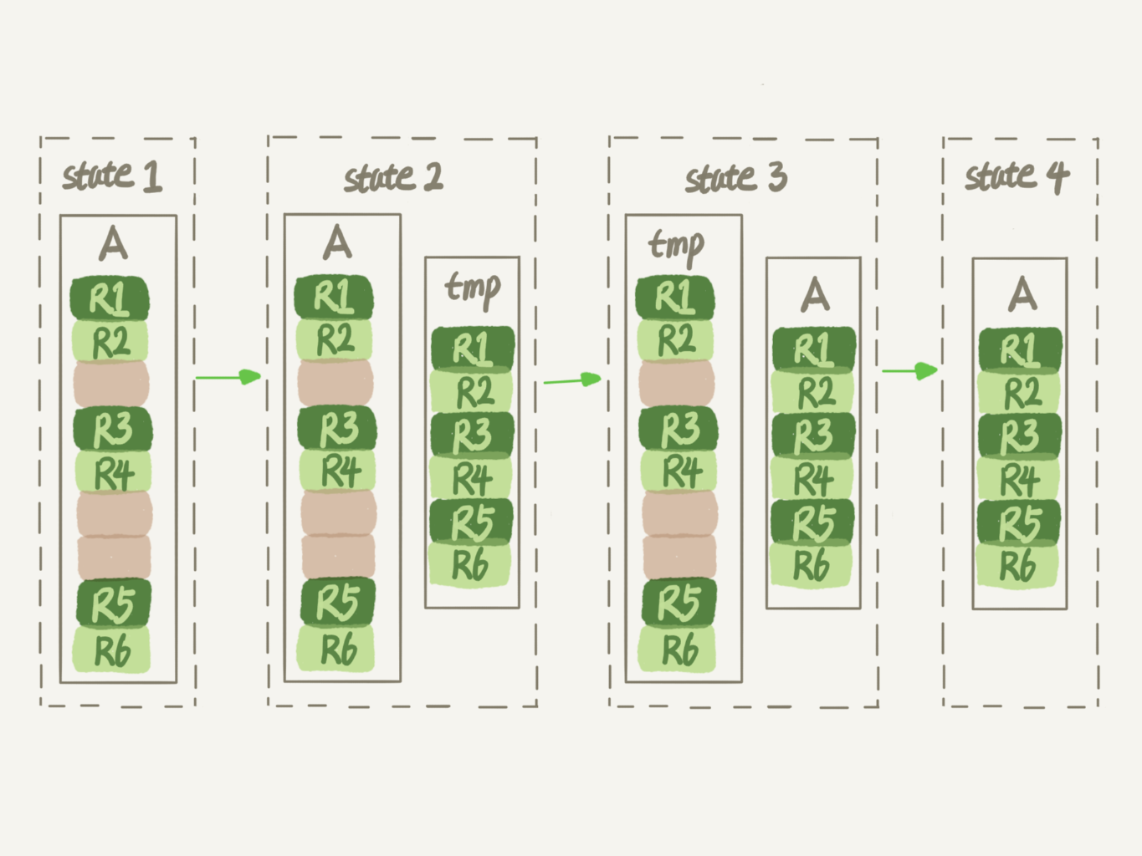
显然,花时间最多的步骤是往临时表插入数据的过程,如果在这个过程中,有新的数据要写入到表 A 的话,就会造成数据丢失。因此,在整个 DDL 过程中,表 A 中不能有更新。也就是说,这个 DDL 不是 Online 的。
而在 MySQL 5.6 版本开始引入的 Online DDL,对这个操作流程做了优化。
我给你简单描述一下引入了 Online DDL 之后,重建表的流程:
- 建立一个临时文件,扫描表 A 主键的所有数据页;
- 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;
- 生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中,对应的是图中 state2 的状态;
- 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件,对应的就是图中 state3 的状态;
- 用临时文件替换表 A 的数据文件。
与图 3 过程的不同之处在于,由于日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表 A 做增删改操作。这也就是 Online DDL 名字的来源。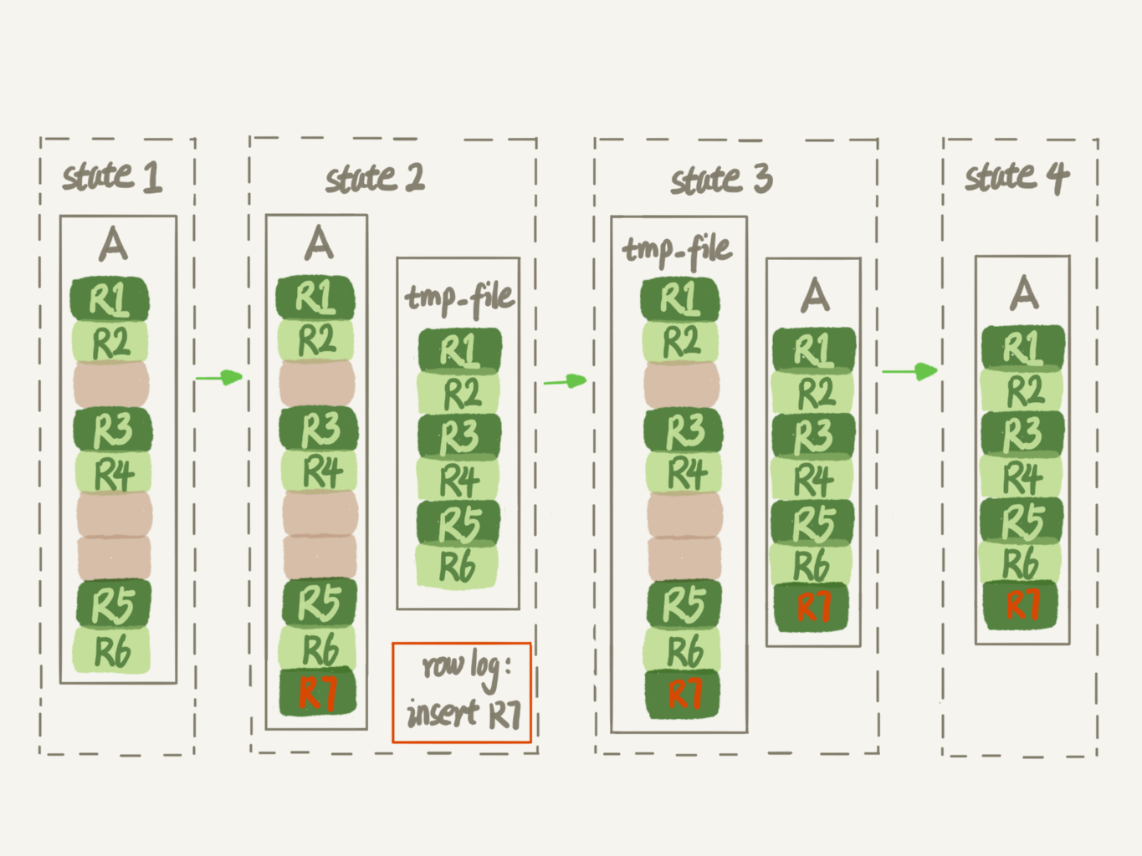
Online DDL建议使用Github开源的gh-ost, 参考:
https://zhuanlan.zhihu.com/p/83770402
以后用到再详细学习

若有收获,就点个赞吧
0 人点赞
