数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
**
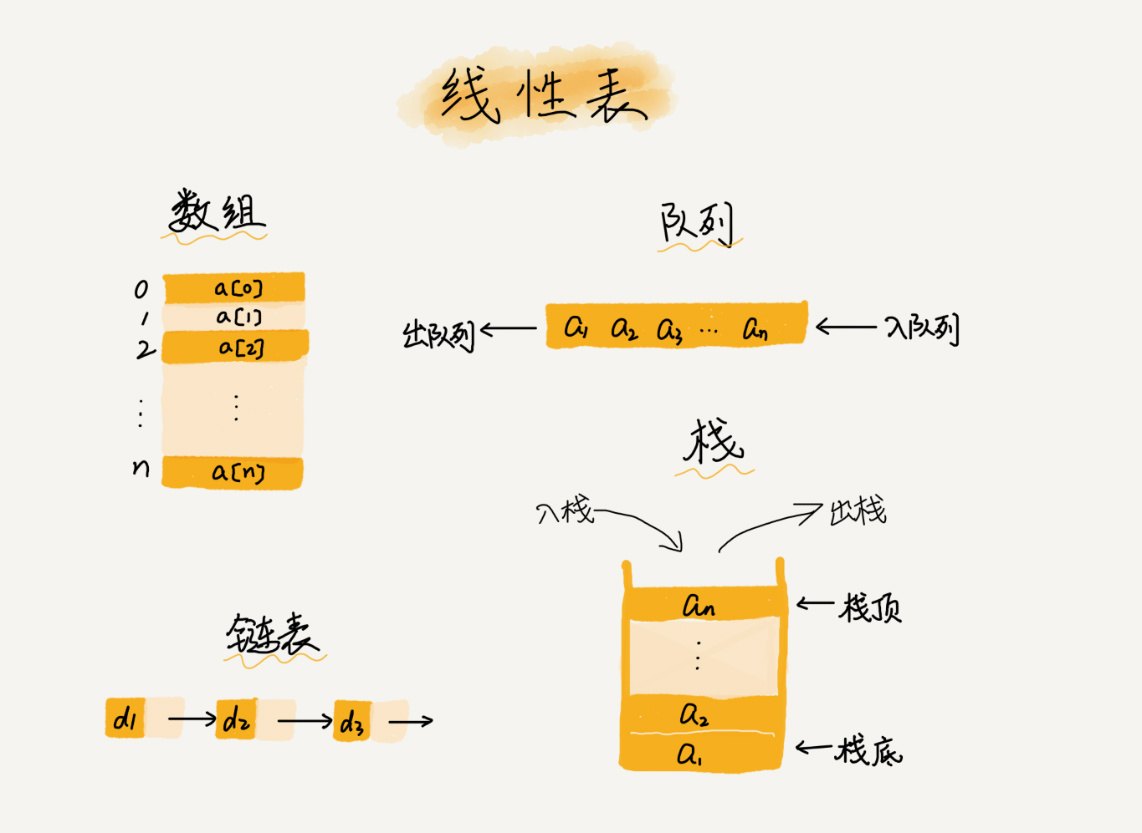
线性表
线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。
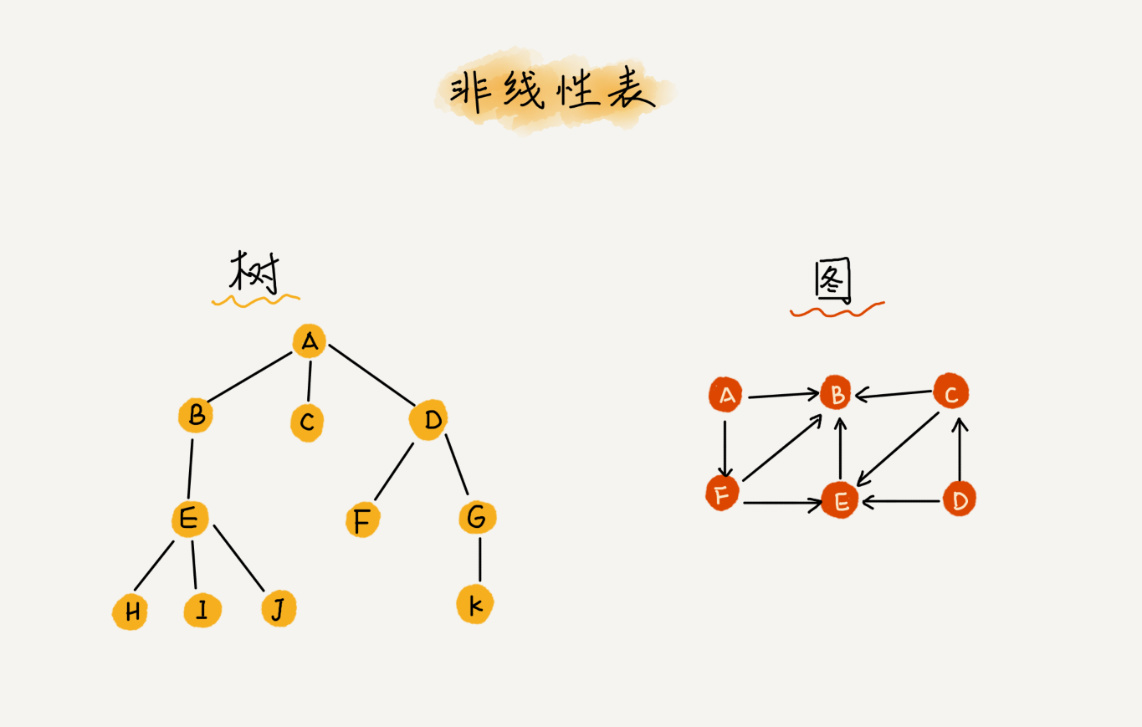
而与它相对立的概念是非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
连续的内存空间和相同类型的数据
这两个特性支持的随机访问.
示例, 假设数组的内存分配如下, 数组的寻址逻辑为 a[i]_address = base_address + i * data_type_size, 其中 data_type_size 表示数组中每个元素的大小。我们举的这个例子里,数组中存储的是 int 类型数据,所以 data_type_size 就为 4 个字节。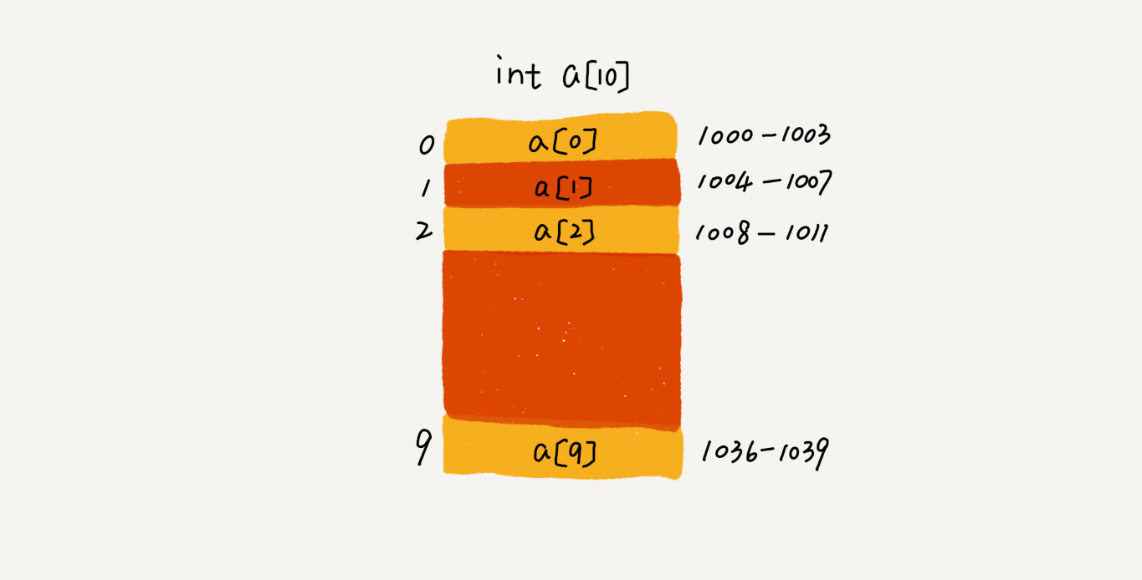
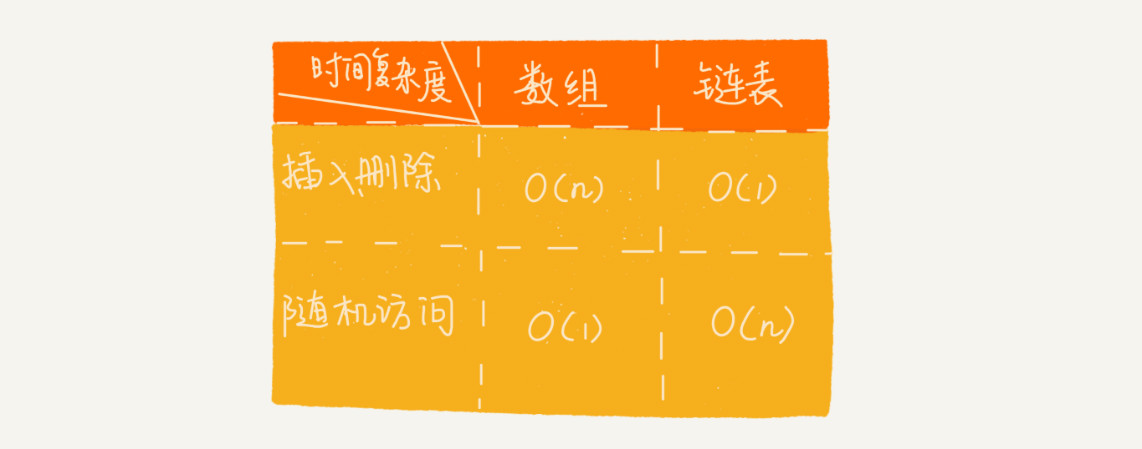
这里我要特别纠正一个“错误”。我在面试的时候,常常会问数组和链表的区别,很多人都回答说,“链表适合插入、删除,时间复杂度 O(1);数组适合查找,查找时间复杂度为 O(1)”。
实际上,这种表述是不准确的。数组是适合查找操作,但是查找的时间复杂度并不为 O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是 O(logn)。所以,正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
数组和容器的区别
ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容。
1.Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
还有一个是我个人的喜好,当要表示多维数组时,用数组往往会更加直观。比如 Object[][] array;而用容器的话则需要这样定义:ArrayList > array。
总结一下,对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
链表
底层存储结构
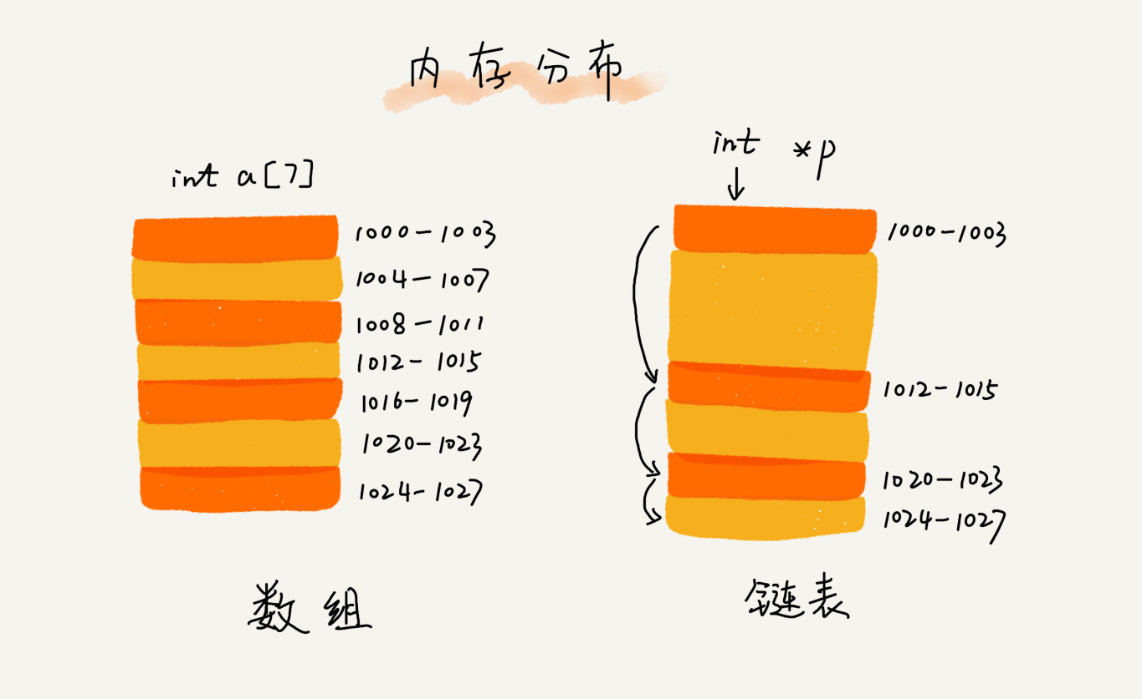
数组需要一块连续的内存空间来存储,对内存的要求比较高。
而链表并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用.
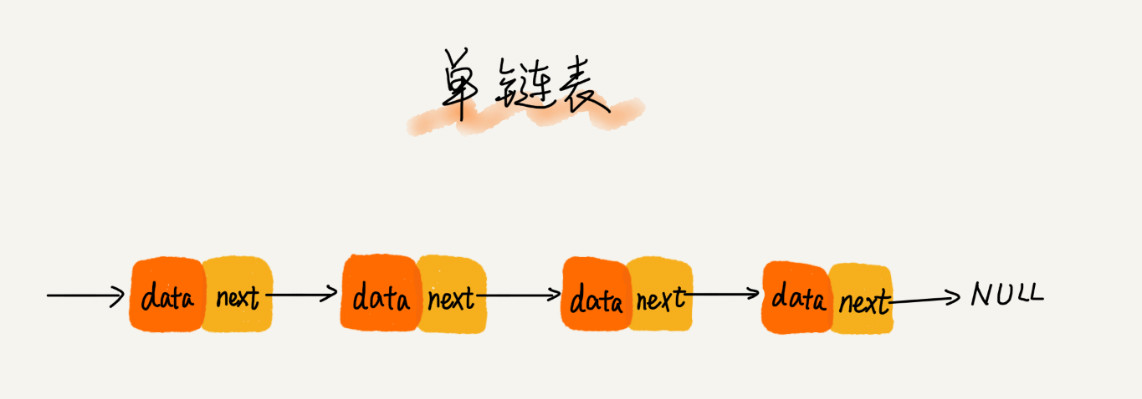
单链表
包括节点和后继指针, 尾节点的指针指向空地址null
- 针对链表的插入和删除操作,我们只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。
- 链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
循环链表
而循环链表的尾结点指针是指向链表的头结点
当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题。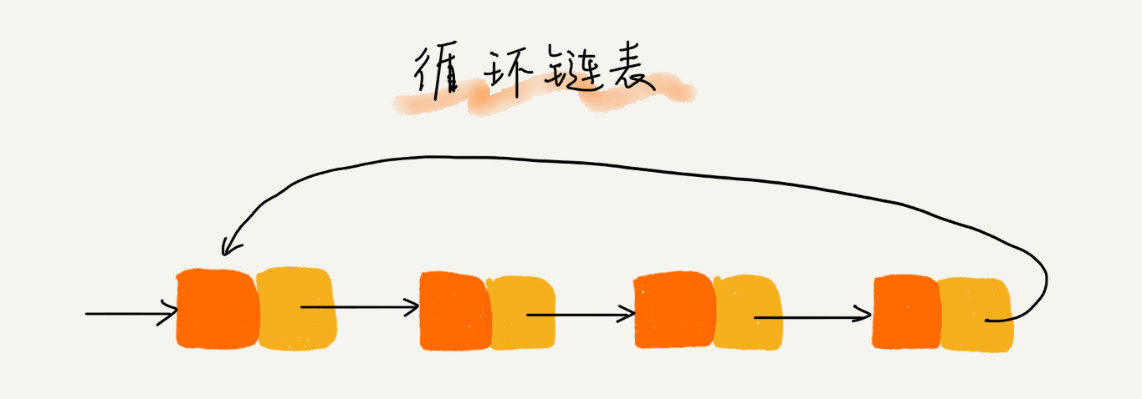
双向链表
除了后继指针以外还有前驱指针prev指向前一个节点
双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。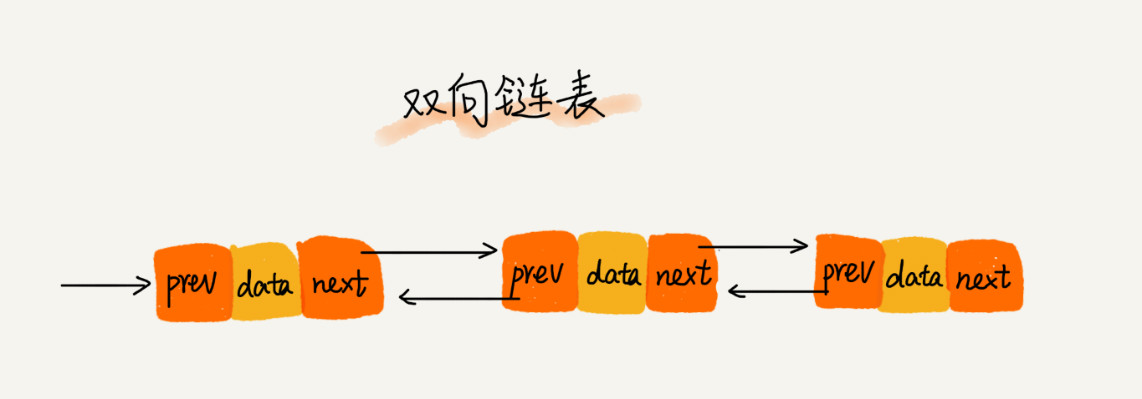
空间换时间的设计思想。 当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来用时间换空间的设计思路。
双向循环链表
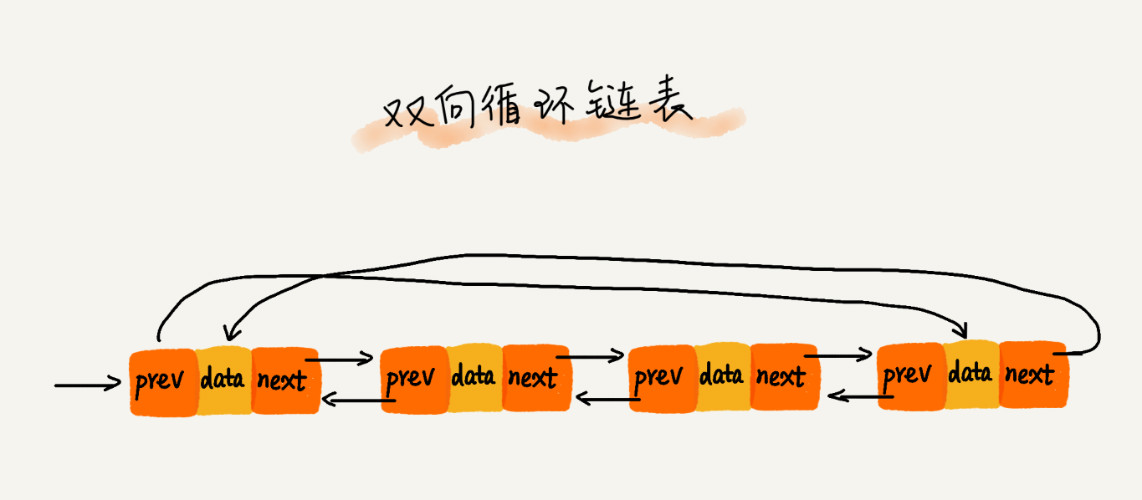
链表与数组的对比
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
如何基于链表实现 LRU 缓存淘汰算法? 我的思路是这样的: 我们维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
如果此数据没有在缓存链表中,又可以分为两种情况:如果此时缓存未满,则将此结点直接插入到链表的头部;如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
如何轻松写出正确的链表代码?
技巧一:理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
技巧二:警惕指针丢失和内存泄漏
技巧三:利用哨兵简化实现难度
通过添加节点指向头结点, 或者添加尾节点指向节点来解决边界节点的特殊处理问题
技巧四:重点留意边界条件处理
技巧五:举例画图,辅助思考
技巧六:多写多练,没有捷径
常见链表操作
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点

若有收获,就点个赞吧
0 人点赞
