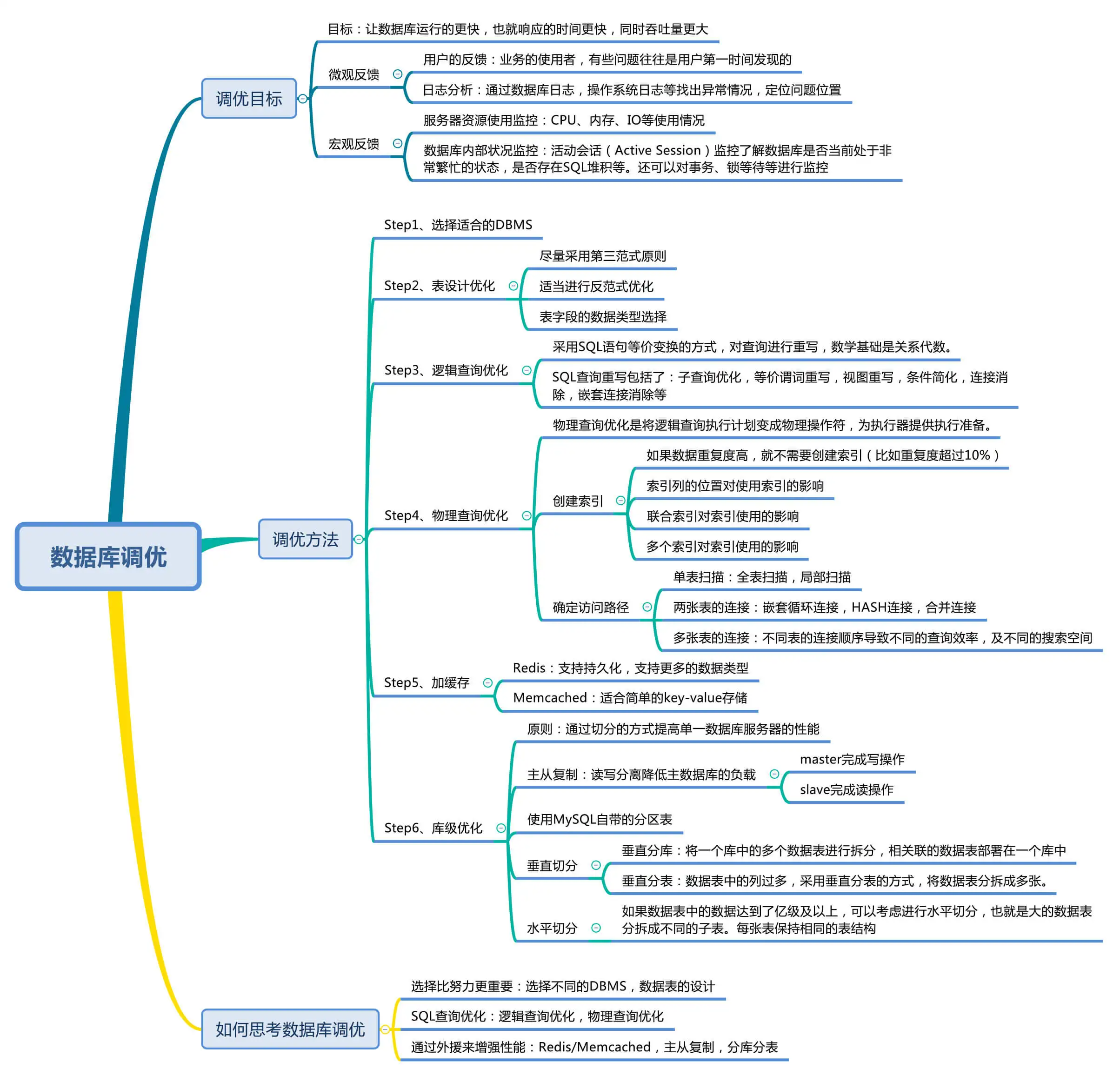
数据库调优
范式与反范式
相关概念
- 超键: 能唯一表示元祖的属性集叫做超键
- 候选键: 如果超键不包括多余的属性, 那么这个超键就是候选键
- 主键: 用户可以从候选键中选择一个作为主键
- 外键: 如果数据表R1中的某属性集不是R1的主键, 二是另一个数据表R2的主键, 那么这个属性集就是数据表R1的外键
- 主属性: 包含在任意候选键中的属性称为主属性
非主属性: 与主属性相对, 只的是不包含任何一个候选键中的属性
1NF: 数据库表中的任何属性都是原子性的, 不可再分. 事实上, 任何的DBMS都满足第一范式.
- 2NF: 数据表里的非主属性完全依赖于候选键.
- 3NF: 任何非主属性直接依赖于候选键.
- 反范式: 允许少量冗余, 空间换时间
示例: 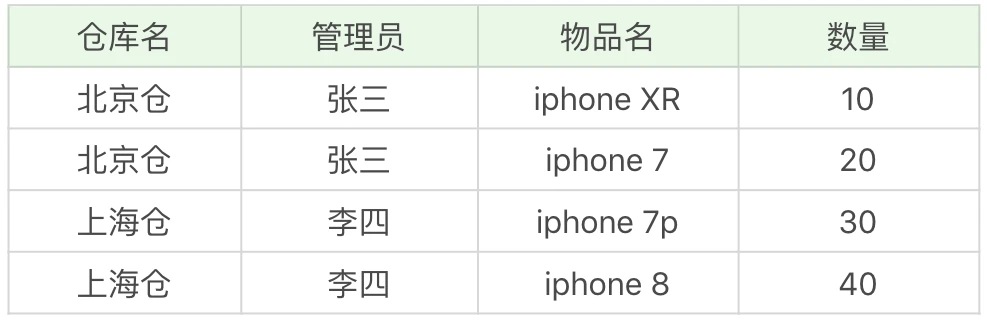
仓库和管理员是严格绑定的一对一关系, 同时仓库+物品能决定数量这个属性, 管理员+物品也能决定数量, 因此
- 候选键是(管理员, 物品名)和(仓库名, 物品名), 可选一个主键, 比如(仓库名, 物品名)
- 主属性是仓库名, 物品名, 管理员, 非主属性是数量, 由上面分析可知, 数量直接依赖于(管理员, 物品名)或(仓库名, 物品名)的候选键, 因此满足三大范式
但依然有问题, 如:
- 新增仓库, 可以不存任何物品, 但要求主键(仓库名, 物品名)不能为空, 会出现异常;
- 若仓库换管理员, 则需要修改多条记录;
- 若仓库商品卖空, 则仓库以及管理员记录没有了
因此引入BCNF(巴斯-科德范式), 在3NF基础上消除了主属性对候选键的部分依赖或传递依赖关系.
按BCNF要求, 上面示例表需被拆分为: 仓库表(仓库名, 管理员), 库存表(仓库名, 物品名, 数量)
索引
索引种类
- 普通索引
- 唯一索引: 在普通索引上添加了唯一性约束
- 主键索引: 在唯一索引上添加了非空约束
- 全文索引
索引数据结构
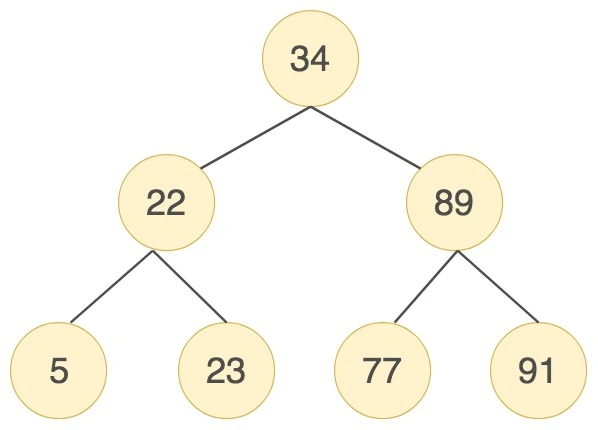
- 二叉搜索树
- 查询时间复杂度为O(logn), 特殊情况退化成链表则为O(n)
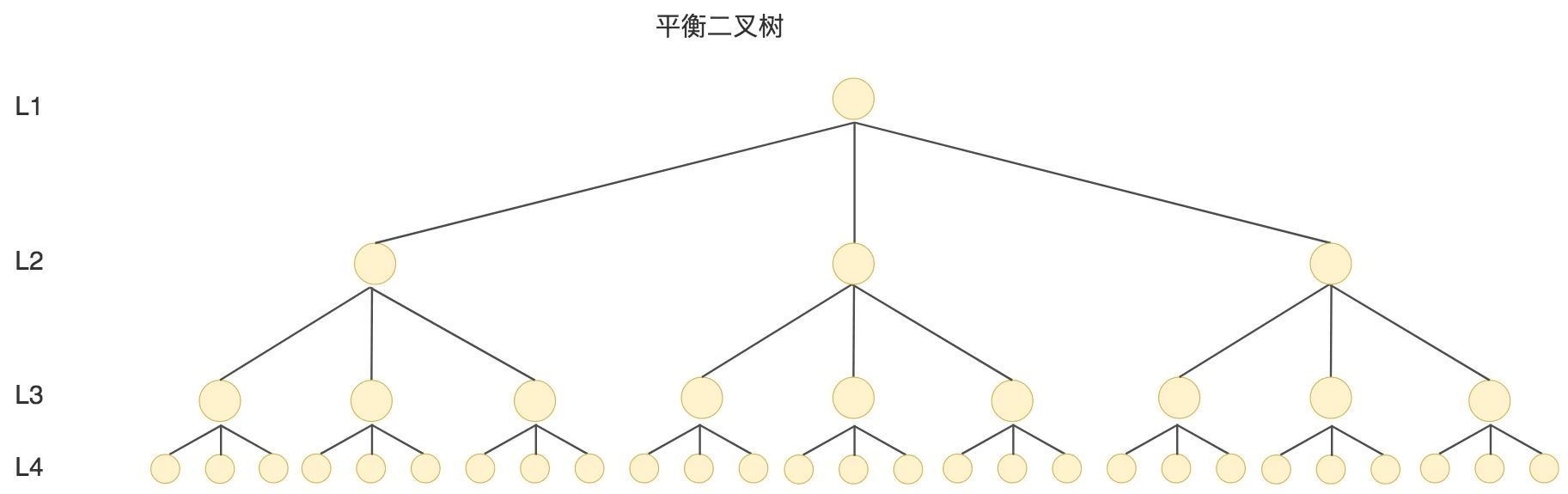
- 平衡二叉树, 即AVL树(平衡二叉搜索树, 红黑树, 数堆, 伸展树)
- 在二分搜索树的基础上增加了约束,每个节点的左子树和右子树的高度差不能超过 1,也就是说节点的左子树和右子树仍然为平衡二叉树
- 查询时间复杂度为O(logn), 时间复杂度取决于树的深度, 树的深度是O(logn)
- M叉树
- 通过增加分叉来降低深度, 提高查找效率
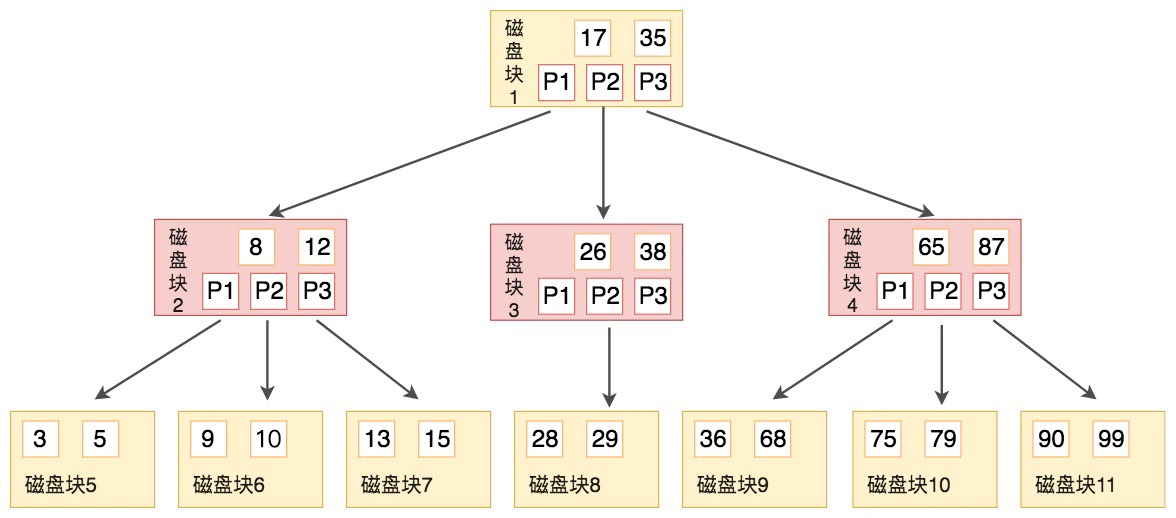
- B树, 平衡的多路搜索树
- 每个节点最多可以包括M个子节点, M成为B树的阶
- 每个磁盘块中包含关键字和子节点的指针
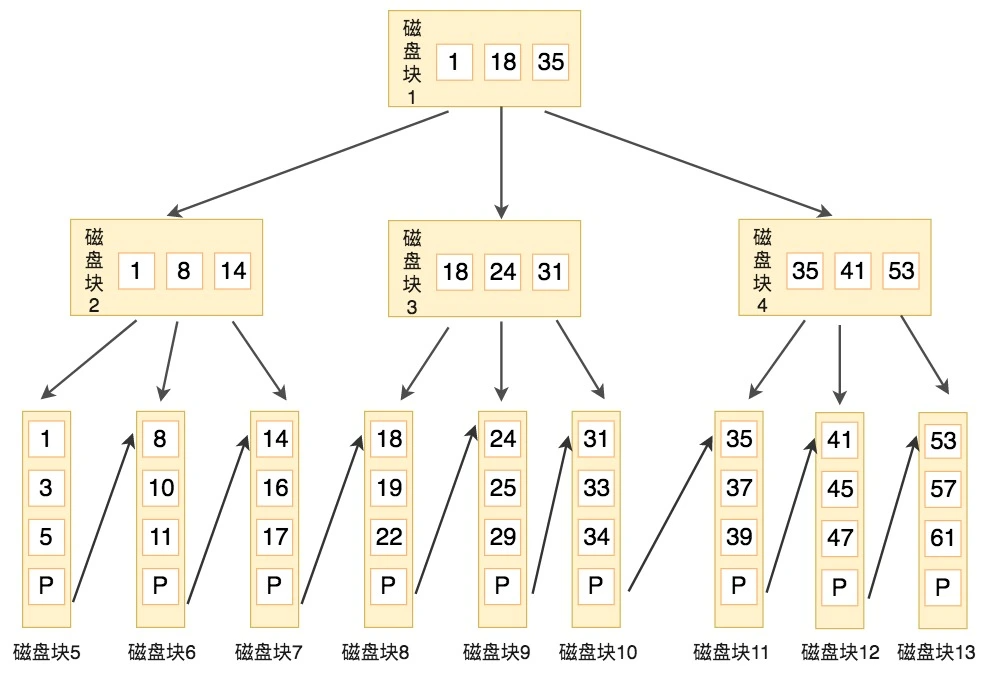
- B+树
与B树相比, 结构上:
- 子节点个数=关键字树, 而B树子节点数=关键字数+1
- 非叶子节点仅用于索引, 不保存数据记录, 而B数非叶子节点既保存索引也保存数据记录
- 所有关键字在叶子节点出现, 并且叶子节点构成一个有序链表
这些结构上的优化, 带来:
- B+树查询效率更稳定, 因为所有数据都保存在叶子结点, 无需在非叶子节点去查找
- B+树查询效率更高, 同样的磁盘页大小, B+树可以存储更多的节点关键字, 使得B+树的阶数更大, 分叉越多, 深度更低, 更”矮胖”, 因此查询所需的磁盘I/O更少
- 在范围查询上, B+树的效率也更高, 因为B+树的叶子节点形成了有序链表结构
Hash索引与B+树索引的区别
- Hash索引指向的数据是无序的, 因此Hash索引不能范围查询, 也不支持ORDER BY排序
- Hash索引是对索引键计算Hash值, 因此不支持联合索引的最左匹配原则, 也不支持模糊查询

若有收获,就点个赞吧
0 人点赞
