安装
ES
使用版本7.2.0
rpm相关命令- 查询已安装的软件包rpm -q {xxx}rpm -qa |grep {xxx}- 安装软件包rpm -ivh {xxx.rpm}- 卸载rpm -e {xxx.rpm}- 查看软件包的文件列表rpm -ql {xxx.rpm}
下载rpm包, 安装
rpm -ivh elasticseachxxx.rpm, 安装的文件夹在/usr/share/elasticsearch修改配置, 配置在
/etc/elasticseach- 修改jvm.options, Xmx与Xms设置成一样, 不超过机器内存的50%, 不超过30GB
- 修改elasticseach.yml, 改http端口
- 修改elasticseach.yml, 改data以及log目录, 并需要创建对应目录并给elasticseach用户授权
path.data: /opt/elasticsearch/data
path.logs: /opt/elasticsearch/logs
查询服务看到组和用户都是elasticsearch,
cat /usr/lib/systemd/system/elasticsearch.service因此给文件夹授权,chown -R elasticsearch:elasticsearch /opt/elasticsearch
- es7.0以上版本需要JDK11, 由于环境变量为JDK8, 因此修改es配置文件使其指向ES自带的JDK11
参考: https://blog.csdn.net/xiaoxiong_web/article/details/105597150
修改/usr/share/elasticsearch/bin/elasticsearch-env文件, 注释掉红框部分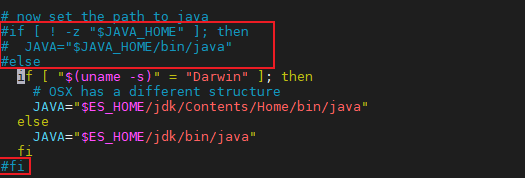
- 启动
systemctl start elasticseach
IK分词器
- 找对应版本, https://github.com/medcl/elasticsearch-analysis-ik
- 在/usr/share/elasticsearch下执行
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip
补充: 也可以通过_cat来查看
Kibana
- 下载安装
- 修改
/etc/kibana/kibana.yml配置文件server.port: 40008server.host: '0.0.0.0'elasticsearch.hosts: ['http://192.168.3.123:40009']
Logstash
- 下载安装
- 修改配置, 配置在
/etc/logstash
win下启用es集群
- 安装docker-desktop, https://docs.docker.com/desktop/windows/install/
执行命令, 以解决内存不足的
在Windows下如果是使用Docker Desktop WSL 2 backend后端,需要在命令行里面这样调整。
wsl -d docker-desktop
sysctl -w vm.max_map_count=262144启动, docker compose up ```bash version: ‘2.2’ services: cerebro: image: lmenezes/cerebro:0.8.3 container_name: cerebro ports:
- “9000:9000” command: -Dhosts.0.host=http://elasticsearch:9200 networks:
- es72net
kibana:
image: docker.elastic.co/kibana/kibana:7.2.0
container_name: kibana72
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED=”true” ports:
- “5601:5601” networks:
- es72net elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 container_name: es72_01 environment:
- cluster.name=geektime
- node.name=es72_01
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
- discovery.seed_hosts=es72_01,es72_02
- cluster.initial_master_nodes=es72_01,es72_02 ulimits: memlock: soft: -1 hard: -1 volumes:
- es72data1:/usr/share/elasticsearch/data ports:
- 9200:9200 networks:
- es72net elasticsearch2: image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 container_name: es72_02 environment:
- cluster.name=geektime
- node.name=es72_02
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
- discovery.seed_hosts=es72_01,es72_02
- cluster.initial_master_nodes=es72_01,es72_02 ulimits: memlock: soft: -1 hard: -1 volumes:
- es72data2:/usr/share/elasticsearch/data networks:
- es72net
volumes: es72data1: driver: local es72data2: driver: local
networks: es72net: driver: bridge
启用后观察es集群状况: [http://localhost:9200/_cat/health?v](http://localhost:9200/_cat/health?v)<br />kibana: [http://localhost:5601/app/kibana](http://localhost:5601/app/kibana)<br />cerebro: [http://localhost:9000/#/overview?host=http:%2F%2Felasticsearch:9200](http://localhost:9000/#/overview?host=http:%2F%2Felasticsearch:9200)---<a name="qBLBh"></a>## 入门<a name="SWV1g"></a>### 基本概念- 文档(Document), 文档是es中可搜索数据的最小单位- 文档的元数据- _index, 文档所属索引- _type, 文档所属类型- _id, 文档唯一id- _source, 文档的原始json数据- _all, 整合所有字段内容到该字段, 从7.0已被废除- _version, 文档的版本信息- _score, 相关性打分- 索引(Index), 索引是文档的容器, 是一类文档的结合- 索引中的数据分布在分片(shard)上- 每个索引都有自己的Mapping定义, 用于定义包含的文档的字段名和字段类型- 索引的setting定义不同的数据分布与传统关系型数据库对比| RDBMS | Elasticsearch || --- | --- || Table | Index(Type) || Row | Document || Column | Filed || Schema | Mapping || SQL | DSL |- 节点- 节点就是一个es实例, 本质上是一个java进程- 每个节点都有名字- 每个节点启动之后, 会分配一个UID, 保存在data目录下- Master-eligible nodes & Master Node- 每个节点启动后, 默认就是一个master eligible节点, 可以设置 node.master:false禁止- master eligible节点可以参加选主流程, 成为master节点- 当第一个节点启动时, 会将自己选举为master节点- 每个节点都保存了集群的状态, 只有master节点才能修改集群的状态信息(所有的节点信息, 所有的索引以及相关的mapping, setting, 分片的路由信息等)- Data Node & Coordinating Node- Data Node, 指可以保存数据的节点- Coordinating Node负责接受Client的请求, 将请求分发到合适的节点, 将结果汇总, 每个节点默认都起到了Coordinating Node的职责- 其他节点类型- Hot & Warm Node, 冷热节点, 根据不同硬件配置不同的Data Node, 降低成本- Machine Learning Node, 负责跑机器学习的Job, 用来做异常检测- Tribe Node- 分片(primary shard & replica shard)- 主分片, 解决水平扩展问题, 通过主分片, 可以将数据分布到集群的所有节点之上- 一个分片就是一个运行的lucene实例- 主分片数在索引创建时指定, 后续不允许修改, 除非ReIndex- 副本, 解决数据高可用问题, 分片是主分片的拷贝- 副本分片数, 可以动态调整- 增加副本数, 还可以在一定程度上提高服务的可用性(读取的吞吐)<br /><a name="m0NF0"></a>### 文档的CRUD与批量操作```json基本格式为 {请求方式} {索引}/_doc/{文档id}- 索引, 先删掉旧的再添加新的, 版本号+1PUT test_index/_doc/1{"user":"haha","comment":"this is a test!"}- 新增, 指定id时, 重复操作会报错PUT test_index/_create/1{"user":"haha","comment":"this is a test!"}POST test_index/_doc{"user":"haha","comment":"this is a test!"}- 查询GET test_index/_doc/1- 修改POST test_index/_update/1{"user":"haha","comment":"this is a test!"}- 删除DELETE test_index/_doc/1---------------------------------------------------------------Bulk API 支持在一次API调用中, 对不同索引进行操作, 略批量获取mget批量查询msearch
常见错误返回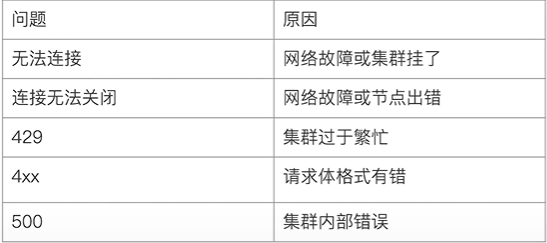
倒排索引

分词
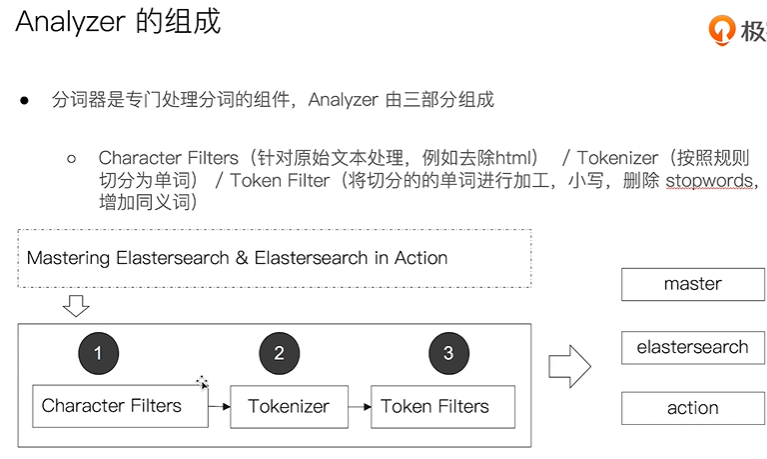
_analyzer API- 直接指定analyzer进行测试GET /_analyze{"analyzer":"standard","test":"this is a test!"}- 指定索引的字段进行测试POST test_index/_analyze{"filed":"title","text":"Mastering Elasticsearch"}- 自定义分词器进行测试POST /_analyze{"tokenizer":"standard","filter":["lowercase"],"text::"Mastering Elasticsearch"}

若有收获,就点个赞吧
0 人点赞
