课程大纲
消息引擎
Apache Kafka 是一款开源的消息引擎系统。
消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
消息引擎的设计
- 传输消息的格式: Kafka使用纯二进制的字节序列
- 传输协议, Kafka支持以下两种:
- 点对点(消息队列), 一个发送只能有一个接收者, 如一个客户呼入只能被一个客服处理
- 发布/订阅, 有主题(Topic)概念, 主题是逻辑语义相近的消息容器, 可能存在多个发布者向相同的主题发送消息, 也可以存在多个订阅者订阅主题, 都能接收到相同主题的消息, 如报纸订阅
消息引擎的作用:
- “削峰填谷”. 缓冲上下游瞬时突发流量, 使其更平滑, 避免流量冲击
- 解耦消息发送方与接收方, 简化应用
Kafka术语
基础
- Topic(主题): 在kafka中, 发布订阅的对象是主题, 可以为每个业务, 每个应用甚至是每类数据都创建专属的主题
- Producer(生产者): 生产者程序通常持续不断地向一个或多个主题发送消息
- Consumer(消费者): 订阅这些主题消息的客户端应用程序就被称为消费者
Clients(客户端): 生产者和消费者统称为客户端(Clients)
Broker: Kafka的服务器端称为Broker, 一个kafka集群由多个Broker组成, Broker处理客户端发送过来的请求, 以及对消息进行持久化, 常将Broker分散在不同机器上, 以实现高可用
- Replica(副本): Relication(备份机制), kafka有两种副本
- Leader Replica(领导者副本): 对外提供服务
- Flower Relica(追随者副本): 不与外界交互, 仅同步领导者副本中的数据
- Partitioning(分区): 将数据分隔多份, 分区机制以实现Scalability(伸缩性)
- 分区是将每个主题划分为多个分区
- 每个分区是一组有序的消息日志, 生产者生产的每条消息只会被发送到一个分区中, 假设向一个有两个分区的主题发送一条消息, 那这条消息要么在分区0, 要么在分区1
- 分区编号从0开始, 假设有100个分区, 那分区号就是0-99
- 每个分区可以配置若干个副本, 其中只能有1个领导者副本和N-1个追随者副本
- Offset(位移): 每条消息在分区中的位置信息由位移来表征, 分区位移总是从0开始, 假设一个生产者向一个空分区写入了10条消息, 那么这10条消息的位移依次是0,1…9
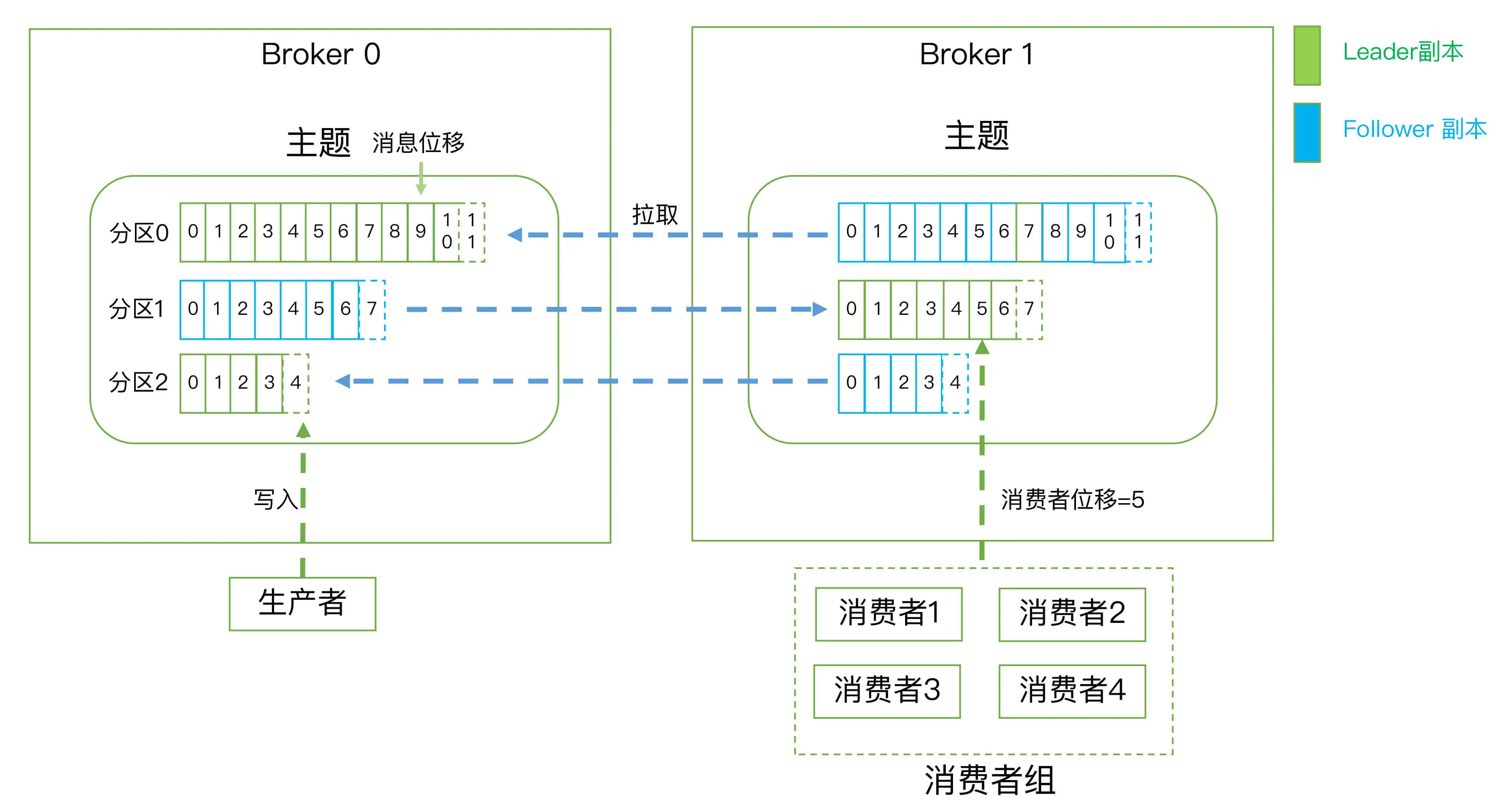
Kafka的三层消息架构
- 主题层, 每个主题可以配置M个分区, 每个分区又可以配置N个副本
- 分区层, 每个分区的N个副本只有一个为领导者副本, 向外提供服务, 其余N-1个副本只作为追随者副本提供数据冗余
- 消息层, 分区中包含若干条消息, 每条消息的位移从0开始, 依次递增
最后, 客户端程序只能与分区的领导者副本进行交互
Kafka持久化数据机制
Kafka通过消息日志来保存数据
- 日志只能追加写(Append-only), 避免了随机I/O, 改为性能较好的顺序I/O
- 一个日志会被切分成多个日志段(Log Segment), 当写满一个日志段后, 会自动切分出一个新的日志段, 并将老的封存, 且后台会有定时任务定期检查老的日志段是否能够被删除, 以回收磁盘空间
消费者组
多个消费者实例共同组成一个消费者组来消费一组主题. 以提高吞吐量.
- 在点对点模型中, 组内的每个分区都会被组内的一个消费者实例消费.
- 假设组内某个消费者实例挂掉, Kafka能够自动检测到, 并将该实例负责的分区转移给其他消费者, 这即是Kafka的”重平衡”(Rebalance).
消费者位移
消费者位移是记录每个消费者消费到分区的哪个位置的字段, 是消费者消费进度的指示器, 是不断变化的.
- 注意”分区位移”指的是消息在分区内的位置, 一旦消息被成功写入分区即固定下来, 不会变更
架构图
补充: 为什么 Kafka 不像 MySQL 那样允许追随者副本对外提供读服务?
参考: https://www.zhihu.com/question/327925275/answer/705690755
- 场景不匹配, Kafka是一个消息引擎,有频繁的消息写入操作,不是典型的读多写少的场景;
- 消费位移难以维护
- 数据一致性无法保证, 消息从主节点同步到从节点需要时间,可能造成主从节点的数据不一致
- 设计天然支持集群对外服务负载均衡, Kafka中的领导者副本一般均匀分布在不同的broker中,已经起到了负载的作用
理解kafka
kafka是消息引擎系统, 也是分布式流处理平台(DIstributed Streaming Platform).
作为流处理平台,Kafka 与其他主流大数据流式计算框架相比的优势:
- 更容易实现端到端的正确性(Correctness). 由于所有的数据流转和计算都在 Kafka 内部完成,故 Kafka 可以实现端到端的精确一次处理语义。其他框架与外部消息引擎系统结合使用时, 只能保证框架内部仅处理一次.
- 定位轻量。官网上明确标识 Kafka Streams 是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统。也就是说 Kafka 没有提供类似于集群调度、弹性部署等开箱即用的运维特性,需要自己选择适合的工具或系统来帮助 Kafka 流处理应用实现这些功能, 但对于中小企业来说比较轻量, 合适.
Kafka生态
Kafka Connect
Kafka Connect组件将Kafka与上下游通过一个个具体的连接器(connector)串联起来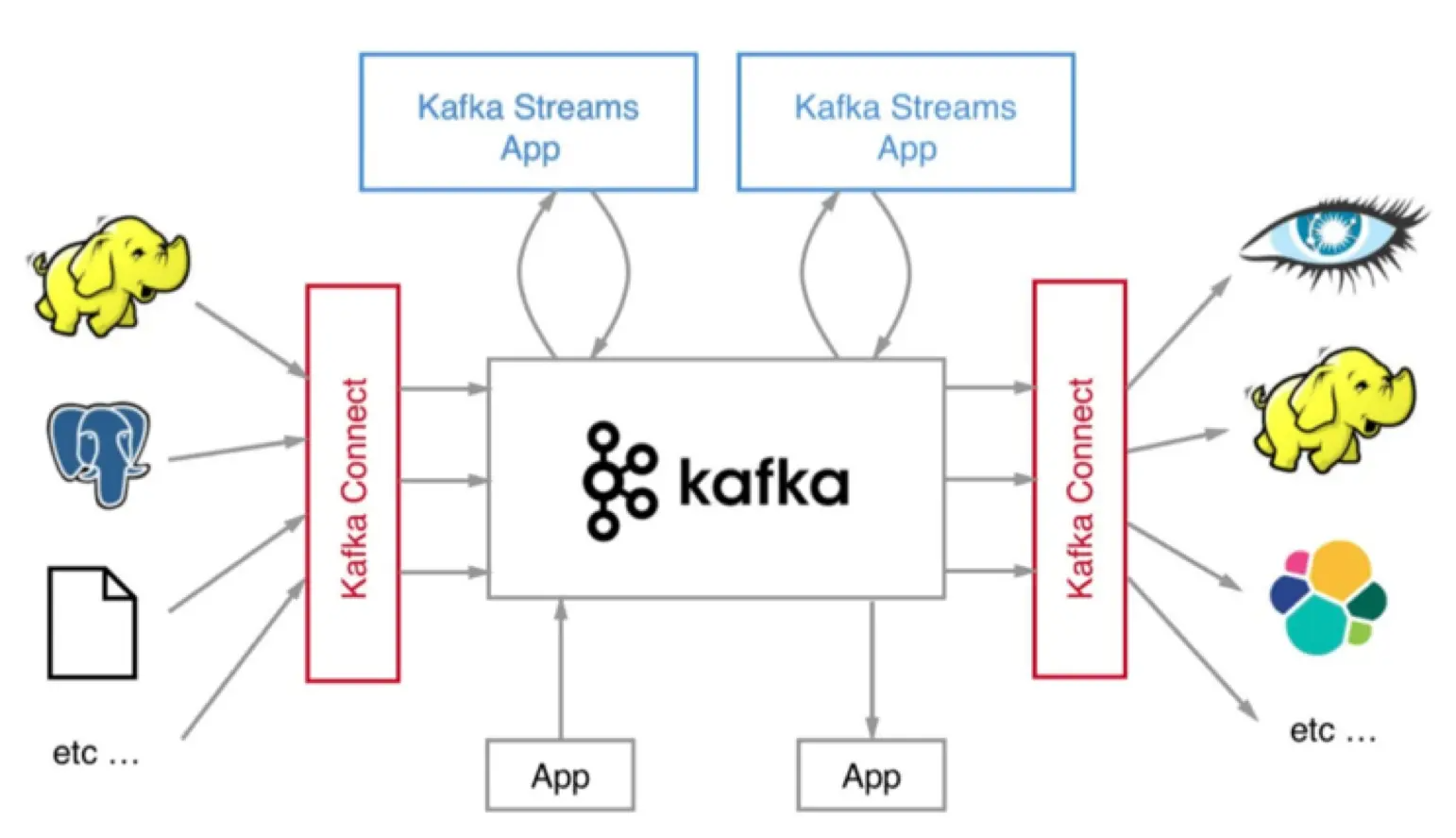
Kafka开源版本
- Apache Kafka,也称社区版 Kafka。优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;缺陷在于仅提供基础核心组件,缺失一些高级的特性。
- Confluent Kafka,Confluent 公司提供的 Kafka。优势在于集成了很多高级特性且由 Kafka 原班人马打造,质量上有保证;缺陷在于相关文档资料不全,普及率较低,没有太多可供参考的范例。
- CDH/HDP Kafka,大数据云公司提供的 Kafka,内嵌 Apache Kafka。优势在于操作简单,节省运维成本;缺陷在于把控度低,演进速度较慢。
Kafka监控套件
- kafka eagle, kafka manager
- JMXTrans + InfluxDB + Grafana
- kafka tools ,能够清晰的看到kafka存储结构。 granafa,能看到消费的折线图。
- 滴滴开源https://github.com/didi/Logi-KafkaManager,是目前市面上最好用的一站式 Kafka 集群指标监控与运维管控平台
Apache Kafka版本号


若有收获,就点个赞吧
0 人点赞
