慢查询基础: 优化数据访问
查询性能低下的最基本的原因是访问的数据太多, 分析两大方面:
- 应用程序是否在检索大量超过需要的数据, 通常意味着访问了太多的行或列
错误的典型案例:
- 查询不需要的记录, 分页不加limit
- 多表关联时返回全部的列
- 总是取出所有列
- 重复查询相同的数据, 而不缓存数据
- mysql服务器是否在分析大量超过需要的数据行
衡量查询开销的三个指标:
- 响应时间
- 扫描的行数
- 返回的行数和访问类型(type)

重构查询的方式
- 一个复杂查询还是多个简单查询
- 切分查询, 简言之就是批量处理
- 分解关联查询
分解的好处:
- 让缓存效率更高
- 执行单个查询可以较少锁的竞争
- 在应用层做关联, 方便对库进行拆分
- 查询本身效率有所提升
- 可以减少冗余记录的查询
个人认为, 在应用设计的时候一个组合查询拆解成多个查询是不明智的, 但对于子查询做缓存的情况下, 可以考虑拆解, 在应用中聚合
查询执行的基础
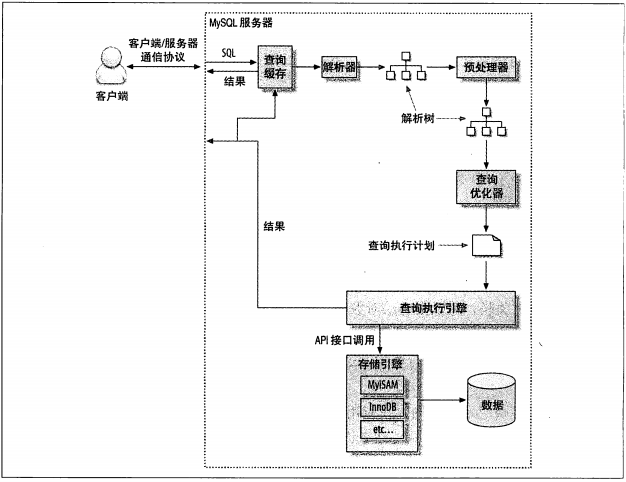

MYSQL查询优化器的局限性
关联子查询
书中所写
实际测试:
可见第一种写法并没有被优化, 第一种写法的效率更高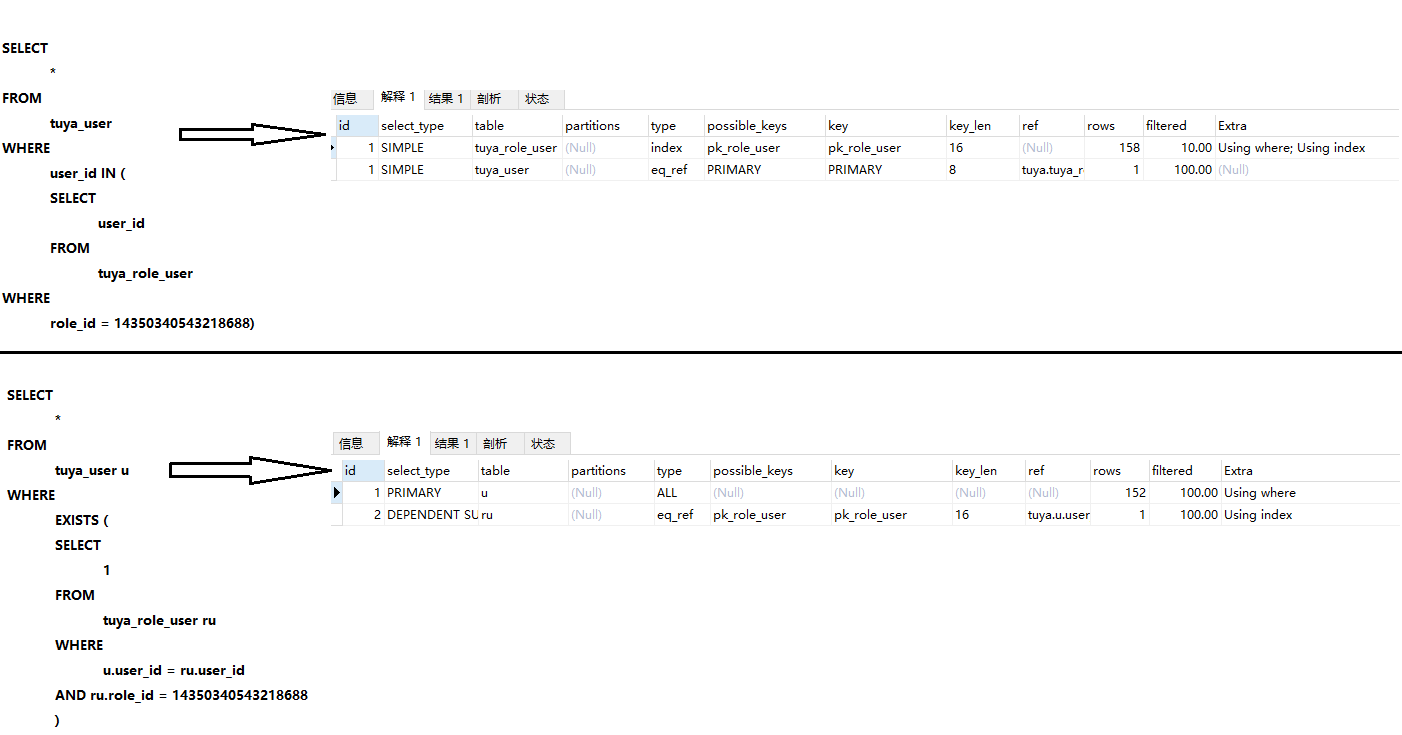
如何用好关联子查询?
EXISTS 查询和子查询的性能在不同的场景下可能会不一样, 具体要通过测试来判断
UNION的限制

在同一个表上执行查询和更新
这个好说, 例子如下:
UPDATE oms_sales_order a,sales_order_backup_20200208 bSET a.is_manual = 0AND a.is_oos = 1WHEREa.sales_order_id = b.sales_order_idAND is_manual =1
优化特定类型的查询
优化COUNT()查询
- 如果count()的括号中指定了列或列的表达式, 则统计的是这个表达式有值的结果数
- 当括号内的表达式不可能为空时, 比如count(*), 则统计的是所有的行数
利用count()来分别统计
优化关联查询
- 确保ON的列上有索引, 在创建索引时就要考虑到关联的顺序, 当表A和表B用列c进行关联的时候, 如果优化器的关联顺序是B,A, 那么就不需要在B表的对应列上建立索引, 一般来说, 除非有其他理由, 否则只需要在关联顺序的第二个表的相应列上创建索引
- 确保任何的group by和order by的表达式只涉及到一个表中的列, 这样MYSQL才有可能使用索引来优化这个过程
优化子查询
尽可能使用关联查询代替, 但不绝对
优化group by 和distinct
如果需要对关联查询做分组, 并且是按照查找表中的某个列进行分组, 那么通常采用查找表的标识列分组的效率会比其他列更高, 比如
select a.name from a inner join b using(id) group by a.name- 比上一条效率高select a.name from a inner join b using(id) group by a.id- 比上一条效率高select a.name from a inner join b using(id) group by b.id
优化limit分页
1.当偏移量非常大的时候, 尽可能使用索引覆盖扫描, 而不是查询所有的列, 然后根据需要再做一次关联操作再返回所有的列.
select name from a limit 50,5;- 若表非常大, 可优化如下select name inner join (select id from a limit 50,5) as lim using(id);
这里的”延迟关联”将大大提高查询效率, 它让mysql尽可能扫描少的页面, 获取需要访问的记录后再根据关联列回原表查询需要的所有列.
2.有时候也可以将limit查询转换为已知位置的查询, 通过范围扫描获得对应的结果, 例如在一个位置上有索引, 并且预先计算出了边界值, 上面的查询可以改写为:
select name from a where position between 50 and 54;
3.limit和offset的问题, 其实是offset问题, 会导致mysql扫描大量不需要的行然后抛弃掉, 因此可以用书签记录上次取数据的位置, 下次直接从该位置进行扫描, 可以避免使用offset
select * from a order by a.id limit 20;- 第二次查询, 条件加上第一次查询的末尾idselect * from a where a.id<20 order by a.id limit 20;
优化union查询
mysql总是通过创建并填充临时表的方式来执行union查询, 因此很多优化策略在union查询中都没法很好的使用, 经常需要手工的将where, limit, order by等子句”下推”到union的各个子查询中, 以便优化器利用这些条件充分进行优化, 简言之, 需要将这些冗余的写一份到各个子查询.
此外, 除非确实需要服务器消除重复的行, 否则一定要用union all. 这很重要, 如果没有all, MYSQL会给临时表添加distinct选项, 会导致对整个临时表数据做唯一性检查, 代价非常高.
使用用户自定义变量

示例: 统计演员的排名, 若演员出演的电影数相同, 则排名并列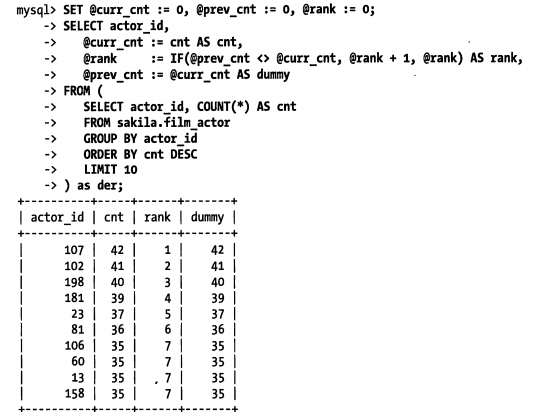
避免重复查询刚更新的数据

确定取值的顺序
这一段比较强,需要用的时候再注意下

编写偷懒的union

用户自定义变量的其他用处


若有收获,就点个赞吧
0 人点赞
