概览
主要分两种- URI Search示例: curl -XGET "http://localhost:9200/test_index/_search?q=cusomer"- Request Body Search示例: curl -XGET "http://localhost:9200/test_index/_search" -H 'Content-Type: application/json' -d'{"query":{"match_all":{}}}'
URI Search
示例GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s{"profile":true}- q 指定查询语句, 使用Query String Syntax- df 默认字段, 不指定会对所有字段进行查询, q=2012&df=title 等价于 q=title:2012- sort 排序, from size 分页- profile 可以查看查询是如何被执行的具体不同查询类型操作, 略
Request Body Search
示例POST /movies/_search{"script_fileds":{ // 脚本字段"new_filed":{"script":{"lang":"painless","source":"doc['order_date'].value+'hello'"}}},"_source":["order_date","category.keyword"], // 指定返回的字段"sort":[{"order_date":"desc"}],"from":10,"size":20,"query":{"match_all":{}}}- 使用查询表达式POST movies/_search{"query": {"match": {"title": {"query": "last christmas","operator": "and"}}}}POST movies/_search{"query": {"match_phrase": {"title":{"query": "one love","slop": 1}}}}
Query String & Simple Query String
简单来说后者禁止了一些高级查询并忽略了一些语法错误
Mapping
Mapping类似数据库的schema定义, 作用:
- 定义索引中字段名称
- 定义字段数据类型
- 定义字段的倒排索引的相关配置, 如analyzed, analyzer
字段数据类型:
- 简单类型
- Text/Keyword
- Date
- Integer/Floating
- Boolean
- IPv4/IPv6
- 复杂类型-对象和嵌套对象
- 特殊类型
- geo_point&geo_shape/percolator
Dynamic Mapping
写入文档时, 如果索引不存在, 则会自动创建索引, 此时es会根据文档信息, 推断出字段类型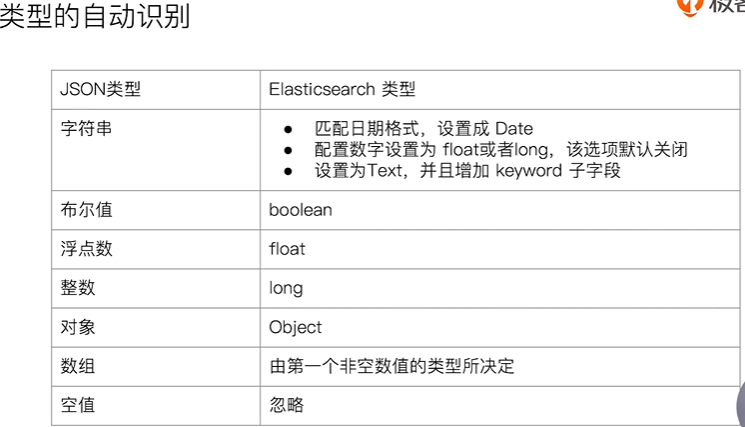
示例:# dynamic mapping,推断字段的类型PUT mapping_test/_doc/1{"uid" : "123","isVip" : false,"isAdmin": "true","age":19,"heigh":180}# 查看 DynamicGET mapping_test/_mapping从下面结果可以看到uid,isAdmin只会被识别为字符串, 被设置为Text, 并添加了keyword子字段{"mapping_test" : {"mappings" : {"properties" : {"age" : {"type" : "long"},"heigh" : {"type" : "long"},"isAdmin" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"isVip" : {"type" : "boolean"},"uid" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}
Dynamic Mapping配置
#修改为dynamic falsePUT dynamic_mapping_test/_mapping{"dynamic": "false"}
显式定义Mapping
示例:PUT movies{"mappings":{...}}初建时可以基于dynamic mapping进行修改
常见参数:
- index, 控制当前字段是否被索引, 默认为true
- index options, 控制倒排索引记录的内容, text默认position, 其他默认docs
- docs, 记录doc id
- freqs, 记录doc id/term frequencies
- positions. 记录doc id/term frequencies/term position
- offsets, 记录doc id/term frequencies/term position/character offects
- null_value, 需要对Null值实现搜索, 只有keyword类型支持设定null_value
- copy_to, 字段拷贝
```json
设置 index 为 false
PUT users { “mappings” : {
} }"properties" : {"firstName" : {"type" : "text"},"lastName" : {"type" : "text"},"mobile" : {"type" : "text","index": false}}
设定Null_value
PUT users { “mappings” : { “properties” : { “firstName” : { “type” : “text” }, “lastName” : { “type” : “text” }, “mobile” : { “type” : “keyword”, “null_value”: “NULL” }
}}
}
设置 Copy to
PUT users { “mappings”: { “properties”: { “firstName”:{ “type”: “text”, “copy_to”: “fullName” }, “lastName”:{ “type”: “text”, “copy_to”: “fullName” } } } }
PUT users/_doc/1 { “firstName”:”Ruan”, “lastName”: “Yiming” }
GET users/_search?q=fullName:(Ruan Yiming)
POST users/_search { “query”: { “match”: { “fullName”:{ “query”: “Ruan Yiming”, “operator”: “and” } } } }
<a name="NjWSn"></a>### 多字段特性- mapping中的keyword指的是不需要分词的精确值, text是会被分词的.- text类型字段自动生成mapping时, 会自动添加一个keyword子字段供精确检索- 此外, 还可以添加自定义子字段, 采用自定义分词器, 以满足不同条件下的搜索自定义分词补充1. Character Filters, 提前进行文本处理, 如增加删除以及替换字符, 可配置多个自带的Character Filters:- HTML strip, 去除html标签- Mapping, 字符串替换- Pattern replace, 正则匹配替换2. Tokenizer, 将原始文本按照一定的规则, 切分为词es内置的Tokenizers:<br />whitespace/standard/uax_url_email/pattern/keyword/path hierarchy3. Token Filters, 将Tokenizer输出的单词进行增加修改删除自带的Token Filters:<br />Lowercase/stop/synonym(添加近义词)```jsonPUT logs/_doc/1{"level":"DEBUG"}GET /logs/_mappingPOST _analyze{"tokenizer":"keyword","char_filter":["html_strip"],"text": "<b>hello world</b>"}POST _analyze{"tokenizer":"path_hierarchy","text":"/user/ymruan/a/b/c/d/e"}#使用char filter进行替换POST _analyze{"tokenizer": "standard","char_filter": [{"type" : "mapping","mappings" : [ "- => _"]}],"text": "123-456, I-test! test-990 650-555-1234"}//char filter 替换表情符号POST _analyze{"tokenizer": "standard","char_filter": [{"type" : "mapping","mappings" : [ ":) => happy", ":( => sad"]}],"text": ["I am felling :)", "Feeling :( today"]}// white space and snowballGET _analyze{"tokenizer": "whitespace","filter": ["stop","snowball"],"text": ["The gilrs in China are playing this game!"]}// whitespace与stopGET _analyze{"tokenizer": "whitespace","filter": ["stop","snowball"],"text": ["The rain in Spain falls mainly on the plain."]}//remove 加入lowercase后,The被当成 stopword删除GET _analyze{"tokenizer": "whitespace","filter": ["lowercase","stop","snowball"],"text": ["The gilrs in China are playing this game!"]}//正则表达式GET _analyze{"tokenizer": "standard","char_filter": [{"type" : "pattern_replace","pattern" : "http://(.*)","replacement" : "$1"}],"text" : "http://www.elastic.co"}
Index Template & Dynamic Template
Index Template
索引模板, 可以设定一个模板固化mapping和setting, 并按照一定规则, 自动匹配到新创建的索引上
- 模板仅在索引新建时有用, 修改模板不会影响已有的索引
- 可以设定多个索引模板, 指定order, 多个设置会按规则merge
- 优先级为: 用户指定 > order高的Index Template > order底的index Template
```json
Create a default template
PUT _template/template_default { “index_patterns”: [“*”], “order” : 0, “version”: 1, “settings”: { “number_of_shards”: 1, “number_of_replicas”:1 } }
PUT /_template/template_test { “index_patterns” : [“test*”], “order” : 1, “settings” : { “number_of_shards”: 1, “number_of_replicas” : 2 }, “mappings” : { “date_detection”: false, “numeric_detection”: true } }
查看template信息
GET /_template/template_default GET /_template/temp*
DELETE /_template/template_default DELETE /_template/template_test
<a name="xfObH"></a>### Dynamic Template应用在某一个具体的索引上, 可以自定义一些字段类型推断的规则, 如:- is开头的字段都设置成boolean```json#Dynaminc Mapping 根据类型和字段名DELETE my_indexPUT my_index/_doc/1{"firstName":"Ruan","isVIP":"true"}GET my_index/_mappingDELETE my_index#示例, 字符串设置成boolean, 字符串设置成keywordPUT my_index{"mappings": {"dynamic_templates": [{"strings_as_boolean": {"match_mapping_type": "string","match":"is*","mapping": {"type": "boolean"}}},{"strings_as_keywords": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]}}DELETE my_index#示例, 结合路径, 组合姓名PUT my_index{"mappings": {"dynamic_templates": [{"full_name": {"path_match": "name.*","path_unmatch": "*.middle","mapping": {"type": "text","copy_to": "full_name"}}}]}}PUT my_index/_doc/1{"name": {"first": "John","middle": "Winston","last": "Lennon"}}GET my_index/_search?q=full_name:John
聚合分析
es的聚合(aggregation)是对数据进行统计分析的功能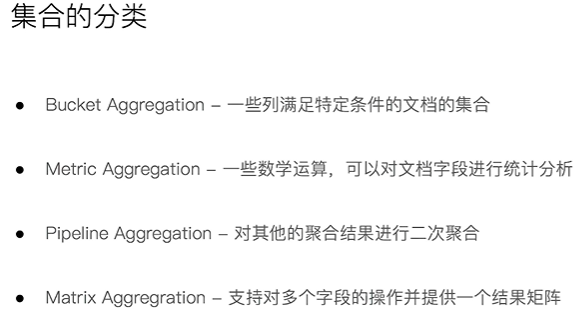
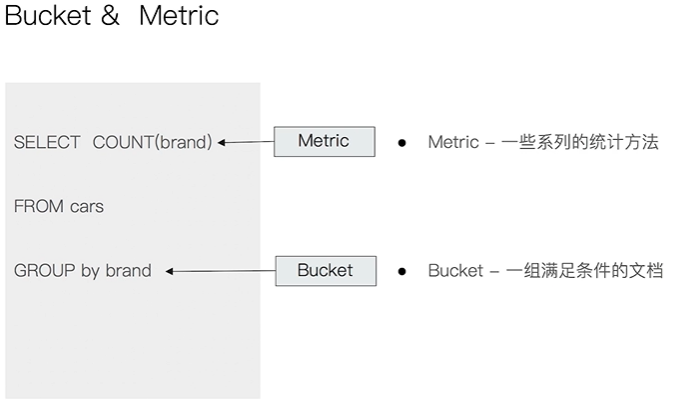
Elasticsearch聚合分析简介课程Demo需要通过Kibana导入Sample Data的飞机航班数据。具体参考“2.2节-Kibana的安装与界面快速浏览”#按照目的地进行分桶统计GET kibana_sample_data_flights/_search{"size": 0,"aggs":{"flight_dest":{"terms":{"field":"DestCountry"}}}}#查看航班目的地的统计信息,增加平均,最高最低价格GET kibana_sample_data_flights/_search{"size": 0,"aggs":{"flight_dest":{"terms":{"field":"DestCountry"},"aggs":{"avg_price":{"avg":{"field":"AvgTicketPrice"}},"max_price":{"max":{"field":"AvgTicketPrice"}},"min_price":{"min":{"field":"AvgTicketPrice"}}}}}}#价格统计信息+天气信息GET kibana_sample_data_flights/_search{"size": 0,"aggs":{"flight_dest":{"terms":{"field":"DestCountry"},"aggs":{"stats_price":{"stats":{"field":"AvgTicketPrice"}},"wather":{"terms": {"field": "DestWeather","size": 5}}}}}}相关阅读https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-aggregations.html

若有收获,就点个赞吧
0 人点赞
