Term查询
Term Query / Range Query / Exists Query / Prefix Query / Wildcard Query
特点:
- 对输入不做分词, 因此应检索keyword
- 会为每个包含该词项的文档进行相关度算分
- 可用constant score将查询转换成一个filtering, 避免算分, 并利用缓存, 提高性能
```json
term查询
GET movies/_search { “query”: { “term”: {
} } }"title.keyword": {"value": "2012"}
利用constant_score转为filter
GET movies/_search { “query”: { “constant_score”: { “filter”: { “term”: { “title.keyword”: “2012” } } } } }
<a name="cI3dY"></a>## 全文查询Match Query / Match Phrase Query / Query String Query <br />特点:- 索引和搜索时都会分词, 查询字符串会先分词生成一个共查询的词项列表- 会算分```json# 全文查询POST movies/_search{"query": {"match": {"title": {"query": "Matrix reloaded","operator": "and"}}}}POST movies/_search{"query": {"match": {"title": {"query": "Matrix reloaded","minimum_should_match": 2}}}}POST movies/_search{"query": {"match_phrase": {"title": {"query": "Matrix reloaded","slop": 1}}}}
结构化搜索
结构化搜索是指对结构化数据的搜索, 其中日期, 布尔类型和数字都是结构化的, 文本也可以是结构化的.
# 对布尔类型, 数字类型直接term查询, 可以用constant_score转filter, 避免算分# 当term查询的字段是数组类型时, 是包含关系, 而不是等值# 如果要求等值, 则需在索引中加一个计数字段, 然后通过bool查询叠加条件实现#数字类型 termsPOST products/_search{"query": {"constant_score": {"filter": {"terms": {"price": ["20","30"]}}}}}#字符类型 termsPOST products/_search{"query": {"constant_score": {"filter": {"terms": {"productID.keyword": ["QQPX-R-3956-#aD8","JODL-X-1937-#pV7"]}}}}}#数字 Range 查询GET products/_search{"query" : {"constant_score" : {"filter" : {"range" : {"price" : {"gte" : 20,"lte" : 30}}}}}}# 日期 rangePOST products/_search{"query" : {"constant_score" : {"filter" : {"range" : {"date" : {"gte" : "now-1y"}}}}}}#exists查询POST products/_search{"query": {"constant_score": {"filter": {"exists": {"field": "date"}}}}}# 查询不存在date字段的文档POST products/_search{"query": {"constant_score": {"filter": {"bool": {"must_not": {"exists": {"field": "date"}}}}}}}
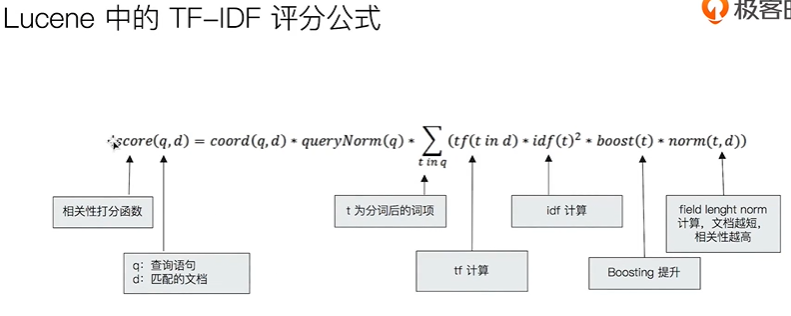
相关性算分
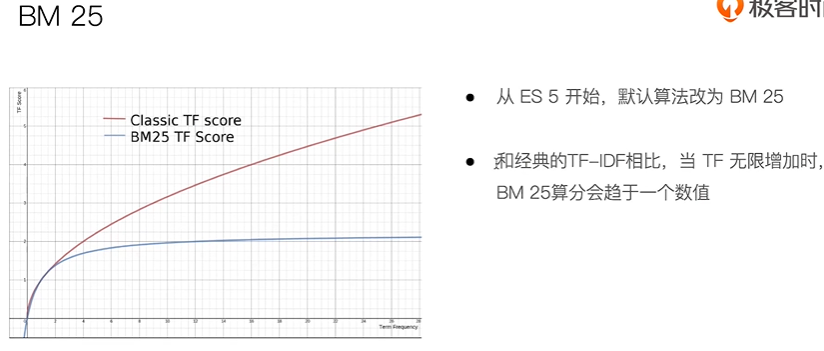
搜索的相关性算分, 描述了一个文档和查询语句匹配的程度. 打分的本质是排序, 需要把最符合用户需求的文档排在前面, es5后默认的相关性算分采用BM25.
词频TF(Term Frequency): 检索词在一篇文档中出现的频率=检索词出现次数/文档总字数
- 度量一条查询与结果文档相关性的简单方法, 是将搜索中每一个词的TF进行相加
- Stop Word除外, 比如”的”, “地”, 不贡献相关度, 不应考虑它们的TF
逆文档频率IDF, 词在所有文档中出现的越少, 值越大
- DF: 检索词在所有文档中出现的频率
- IDF: Inverse Document Frequency=log(全部文档数/检索词出现过的文档总数)
TF-IDF: 本质上将TF求和变成了加权求和
比如搜索”区块链的应用”, TF-IDF=TF(区块链)IDF(区块链)+TF(的)IDF(的)+TF(应用)*IDF(应用)
# 可以打开explain了解算分POST movies/_search{"explain": true,"query": {"match": {"title": {"query": "Matrix reloaded","operator": "and"}}}}# 通过Boosting来控制相关度# boost>1, 提升相关性# 0<boost<1, 降低相关性# boost<0, 贡献负分# 1. 设置索引以及mapping时可以设置字段的boost# 2. 查询时可以设置, 如下POST testscore/_search{"query": {"boosting" : {"positive" : {"term" : {"content" : "elasticsearch"}},"negative" : {"term" : {"content" : "like"}},"negative_boost" : 0.2}}}
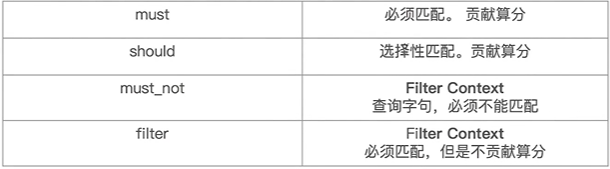
Query&Filtering与多字符串多字段查询
- Query: 查询, 有算分
- Filter: 过滤, 不需要算分, 可以利用缓存, 提升性能
bool查询, 一个或多个查询子句组合
- 子查询可以任意顺序
- 可以嵌套多个
- 如果没有must条件, 则should必须至少满足一个
# bool查询POST /products/_search{"query": {"bool" : {"must" : {"term" : { "price" : "30" }},"filter": {"term" : { "avaliable" : "true" }},"must_not" : {"range" : {"price" : { "lte" : 10 }}},"should" : [{ "term" : { "productID.keyword" : "JODL-X-1937-#pV7" } },{ "term" : { "productID.keyword" : "XHDK-A-1293-#fJ3" } }],"minimum_should_match" :1}}}#嵌套,实现了 should not 逻辑POST /products/_search{"query": {"bool": {"must": {"term": {"price": "30"}},"should": [{"bool": {"must_not": {"term": {"avaliable": "false"}}}}],"minimum_should_match": 1}}}# bool查询嵌套的层级会影响算分POST /animals/_search{"query": {"bool": {"should": [{ "term": { "text": "brown" }},{ "term": { "text": "red" }},{ "term": { "text": "quick" }},{ "term": { "text": "dog" }}]}}}POST /animals/_search{"query": {"bool": {"should": [{ "term": { "text": "quick" }},{ "term": { "text": "dog" }},{"bool":{"should":[{ "term": { "text": "brown" }},{ "term": { "text": "brown" }},]}}]}}}# Boosting QueryPOST news/_search{"query": {"boosting": {"positive": {"match": {"content": "apple"}},"negative": {"match": {"content": "pie"}},"negative_boost": 0.5}}}
单字符串多字段查询, Dis Max Query
总结: 这种场景还是要用dis_max+tie_breaker合适
# 文档1PUT /blogs/_doc/1{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}# 文档2PUT /blogs/_doc/2{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}# 上面两篇文档# 单字符串多字段查询如下示例, 通过bool查询来实现# 当bool查询的条件为should时, 此时会简单的将所有匹配的得分相加,# 由于brown在第一篇文档中出现两次, 因此文档1优先于文档2, 但语义上文档2的brown fox才更接近POST /blogs/_search{"query": {"bool": {"should": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}}# 此时, 使用dis_max查询即可达到效果, dis_max会简单返回匹配更高者的分数, 得到文档2优先于1POST blogs/_search{"query": {"dis_max": {"queries": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}}# 另一种场景, 当查询的字段是Quick pets时, dis_max算法会使得2个文档评分一样POST blogs/_search{"query": {"dis_max": {"queries": [{ "match": { "title": "Quick pets" }},{ "match": { "body": "Quick pets" }}]}}}# 这时, 可以引入tie_breaker, tie_breker决定了剩余匹配的贡献度,# 引入后匹配了2个单词的文档2评分就会高于文档1POST blogs/_search{"query": {"dis_max": {"queries": [{ "match": { "title": "Quick pets" }},{ "match": { "body": "Quick pets" }}],"tie_breaker": 0.2}}}
单字符串多字段查询: Multi Match
三种场景:
- 最佳字段(Best Fields)
当字段之间互相竞争, 又相互关联, 评分来自最匹配字段
补充: 效果就相当于上面的dis_max query
POST blogs/_search{"query": {"dis_max": {"queries": [{ "match": { "title": "Quick pets" }},{ "match": { "body": "Quick pets" }}],"tie_breaker": 0.2}}}POST blogs/_search{"query": {"multi_match": {"type": "best_fields","query": "Quick pets","fields": ["title","body"],"tie_breaker": 0.2,"minimum_should_match": "20%"}}}
- 多数字段(Most Fields)
处理英文内容时, 常见手段是, 在主字段(English Analyzer), 抽取词干, 加入同义词, 以匹配更多的文档, 相同的文本, 加入子字段(Standard Analyzer), 以提供更加精确的匹配, 其他字段作为匹配文档提高相关度的信号, 匹配字段越多则越好
# standard分词器不会对单词进行处理GET /_analyze{"analyzer":"standard","text":"barking dogs"}------------------------{"tokens" : [{"token" : "barking","start_offset" : 0,"end_offset" : 7,"type" : "<ALPHANUM>","position" : 0},{"token" : "dogs","start_offset" : 8,"end_offset" : 12,"type" : "<ALPHANUM>","position" : 1}]}# english分词器会去除单词的时态, 单复数等特征GET /_analyze{"analyzer":"english","text":"barking dogs"}------------------------{"tokens" : [{"token" : "bark","start_offset" : 0,"end_offset" : 7,"type" : "<ALPHANUM>","position" : 0},{"token" : "dog","start_offset" : 8,"end_offset" : 12,"type" : "<ALPHANUM>","position" : 1}]}
案例
# 现有titles这样的索引, 对title字段设定了english分词器PUT /titles{"mappings": {"properties": {"title": {"type": "text","analyzer": "english"}}}}POST titles/_bulk{ "index": { "_id": 1 }}{ "title": "My dog barks" }{ "index": { "_id": 2 }}{ "title": "I see a lot of barking dogs on the road " }# 写入上面两篇文档后, 有如下搜索, 由于两篇文档都有俩单词匹配, 且第一篇文档更短,# 因此文档1优先于文档2, 但是明显文档2才是我们想要的GET titles/_search{"query": {"match": {"title": "barking dogs"}}}# 解决方式, 修改mapping, 对title字段, 添加一个使用standard分词器的子字段stdDELETE /titlesPUT /titles{"settings": { "number_of_shards": 1 },"mappings": {"my_type": {"properties": {"title": {"type": "string","analyzer": "english","fields": {"std": {"type": "string","analyzer": "standard"}}}}}}}# 再使用most_fields的multi_match查询, 此时文档2的title以及子字段都有匹配, 因此优先于文档1GET /titles/_search{"query": {"multi_match": {"query": "barking dogs","type": "most_fields","fields": [ "title", "title.std" ]}}}
专业解释如下: 
- 混合字段(Cross Field)
对于某些实体, 例如人名, 地址, 图书信息, 需要在多个字段中确定信息, 单个字段只能作为整体的一部分, 希望在任何这些列出的字段中找到尽可能多的词
# Cross Field的multi_match常用于跨字段查询, 比如地区字段如下# 这种情形的另一个解决方式是使用copy_to, 新增一个字段, 但是会占用更多索引空间# 此外使用Cross Field还可以设定每个字段的权重PUT address/_doc/1{"street": "5 Poland Street","city": "London","country" : "UK","postcode": "W1V 3DG"}POST address/_search{"query": {"multi_match": {"query": "Poland Street W1V","type": "cross_fields","operator": "and","fields": ["street","city","country","postcode"]}}}

若有收获,就点个赞吧
0 人点赞
