StampedLock:有没有比读写锁更快的锁?
StampedLock性能比读写锁更好, 支持三种模式
- 写锁
- 悲观锁
- 乐观读
写锁、悲观读锁的语义和 ReadWriteLock 的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。不同的是:StampedLock 里的写锁和悲观读锁加锁成功之后,都会返回一个 stamp;然后解锁的时候,需要传入这个 stamp。
final StampedLock sl =new StampedLock();// 获取/释放悲观读锁示意代码long stamp = sl.readLock();try {//省略业务相关代码} finally {sl.unlockRead(stamp);}// 获取/释放写锁示意代码long stamp = sl.writeLock();try {//省略业务相关代码} finally {sl.unlockWrite(stamp);}
StampedLock 的性能之所以比 ReadWriteLock 还要好,其关键是 StampedLock 支持乐观读的方式。ReadWriteLock 支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;而 StampedLock 提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。
注意这里,乐观读这个操作是无锁的,所以相比较 ReadWriteLock 的读锁,乐观读的性能更好一些。
Java SDK中的乐观读代码示例:
class Point {private int x, y;final StampedLock sl =new StampedLock();//计算到原点的距离int distanceFromOrigin() {// 乐观读long stamp =sl.tryOptimisticRead();// 读入局部变量,// 读的过程数据可能被修改int curX = x, curY = y;//判断执行读操作期间,//是否存在写操作,如果存在,//则sl.validate返回falseif (!sl.validate(stamp)){// 升级为悲观读锁stamp = sl.readLock();try {curX = x;curY = y;} finally {//释放悲观读锁sl.unlockRead(stamp);}}return Math.sqrt(curX * curX + curY * curY);}}
进一步理解乐观读
数据库里的乐观锁,查询的时候需要把 version 字段查出来,更新的时候要利用 version 字段做验证。这个 version 字段就类似于 StampedLock 里面的 stamp。
数据库的乐观锁示例:
// 如果SQL执行成功并且返回的条数为1, 说明没有其他线程修改过这条数据update product_docset version=version+1,...where id=777 and version=9
StampedLock 使用注意事项
- StampedLock 不支持重入
- StampedLock 的悲观读锁、写锁都不支持条件变量
- 如果线程阻塞在 StampedLock 的 readLock() 或者 writeLock() 上时,此时调用该阻塞线程的 interrupt() 方法,会导致 CPU 飙升; 所以, 使用 StampedLock 一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁 readLockInterruptibly() 和写锁 writeLockInterruptibly() ```java
final StampedLock lock = new StampedLock(); Thread T1 = new Thread(()->{ // 获取写锁 lock.writeLock(); // 永远阻塞在此处,不释放写锁 LockSupport.park(); }); T1.start(); // 保证T1获取写锁 Thread.sleep(100); Thread T2 = new Thread(()-> //阻塞在悲观读锁 lock.readLock() ); T2.start(); // 保证T2阻塞在读锁 Thread.sleep(100); //中断线程T2 //会导致线程T2所在CPU飙升 T2.interrupt(); T2.join();
<a name="yUgL0"></a>### StampedLock使用最佳模板StampedLock 读模板:```javafinal StampedLock sl =new StampedLock();// 乐观读long stamp =sl.tryOptimisticRead();// 读入方法局部变量......// 校验stampif (!sl.validate(stamp)){// 升级为悲观读锁stamp = sl.readLock();try {// 读入方法局部变量.....} finally {//释放悲观读锁sl.unlockRead(stamp);}}//使用方法局部变量执行业务操作......
StampedLock 写模板:
long stamp = sl.writeLock();try {// 写共享变量......} finally {sl.unlockWrite(stamp);}
CountDownLatch和CyclicBarrier:如何让多线程步调一致?
线程的join()方法:
- 在A线程中调用了B线程的join()方法时,表示只有当B线程执行完毕时,A线程才能继续执行。
- 如果A线程中掉用B线程的join(10),则表示A线程会等待B线程执行10毫秒,10毫秒过后,A、B线程并行执行。需要注意的是,jdk规定,join(0)的意思不是A线程等待B线程0秒,而是A线程等待B线程无限时间,直到B线程执行完毕,即join(0)等价于join()。
- join方法必须在线程start方法调用之后调用才有意义. ```java
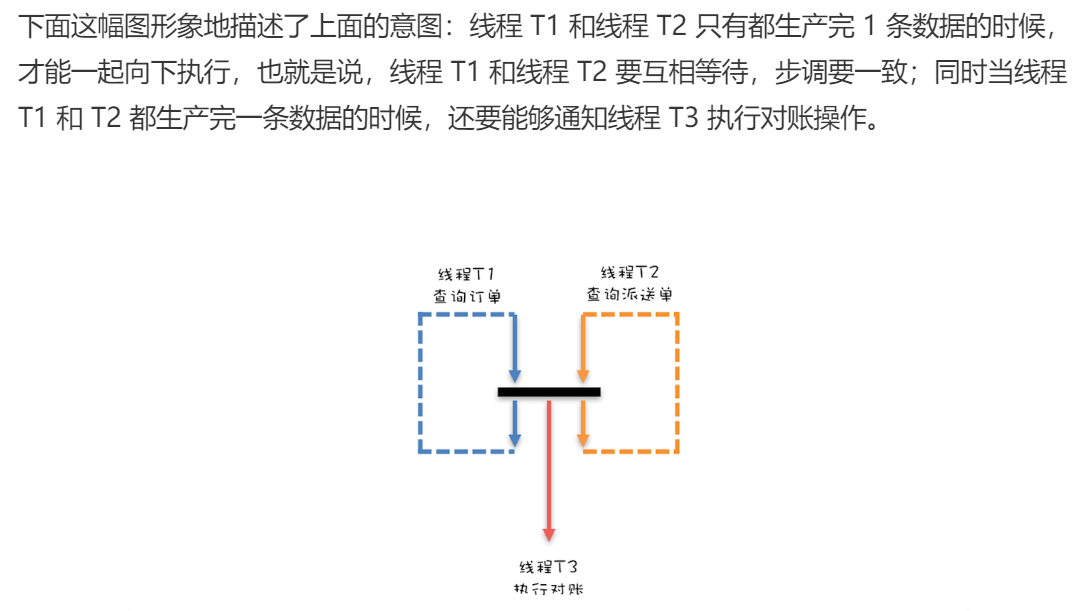
while(存在未对账订单){ // 查询未对账订单 Thread T1 = new Thread(()->{ pos = getPOrders(); }); T1.start(); // 查询派送单 Thread T2 = new Thread(()->{ dos = getDOrders(); }); T2.start(); // 等待T1、T2结束 T1.join(); T2.join(); // 执行对账操作 diff = check(pos, dos); // 差异写入差异库 save(diff); }
<a name="yeavH"></a>###<a name="5coAW"></a>### CountDownLatch用法```java// 创建2个线程的线程池Executor executor =Executors.newFixedThreadPool(2);while(存在未对账订单){// 计数器初始化为2CountDownLatch latch =new CountDownLatch(2);// 查询未对账订单executor.execute(()-> {pos = getPOrders();latch.countDown();});// 查询派送单executor.execute(()-> {dos = getDOrders();latch.countDown();});// 等待两个查询操作结束latch.await();// 执行对账操作diff = check(pos, dos);// 差异写入差异库save(diff);}
用 CyclicBarrier 实现线程同步
示例代码
补充说明:
1.为啥要用线程池,而不是在回调函数中直接调用?
使用线程池是为了异步操作,否则回掉函数是同步调用的,也就是本次对账操作执行完才能进行下一轮的检查。
2.线程池为啥使用单线程的?
线程数量固定为1,防止了多线程并发导致的数据不一致,因为订单和派送单是两个队列,只有单线程去两个队列中取消息才不会出现消息不匹配的问题。
// 订单队列Vector<P> pos;// 派送单队列Vector<D> dos;// 执行回调的线程池Executor executor =Executors.newFixedThreadPool(1);// 创建计数器初始值为 2 的 CyclicBarrier, 当计数器减到 0 的时候,会调用回调函数, 且自动重置到初始值2final CyclicBarrier barrier =new CyclicBarrier(2, ()->{executor.execute(()->check());});void check(){P p = pos.remove(0);D d = dos.remove(0);// 执行对账操作diff = check(p, d);// 差异写入差异库save(diff);}void checkAll(){// 循环查询订单库Thread T1 = new Thread(()->{while(存在未对账订单){// 查询订单库pos.add(getPOrders());// 等待, 计数器-1barrier.await();}});T1.start();// 循环查询运单库Thread T2 = new Thread(()->{while(存在未对账订单){// 查询运单库dos.add(getDOrders());// 等待,计数器-1barrier.await();}});T2.start();}
总结:
CountDownLatch 主要用来解决一个线程等待多个线程的场景,可以类比旅游团团长要等待所有的游客到齐才能去下一个景点;而 CyclicBarrier 是一组线程之间互相等待,更像是几个驴友之间不离不弃。
除此之外 CountDownLatch 的计数器是不能循环利用的,也就是说一旦计数器减到 0,再有线程调用 await(),该线程会直接通过。但 CyclicBarrier 的计数器是可以循环利用的,而且具备自动重置的功能,一旦计数器减到 0 会自动重置到你设置的初始值。除此之外,CyclicBarrier 还可以设置回调函数,可以说是功能丰富。
并发容器:都有哪些“坑”需要我们填?
如何将非线程安全的容器变成线程安全的容器?
只要把非线程安全的容器封装在对象内部,然后控制好访问路径就可以了。
代码示例
SafeArrayList<T>{//封装ArrayListList<T> c = new ArrayList<>();//控制访问路径synchronizedT get(int idx){return c.get(idx);}synchronizedvoid add(int idx, T t) {c.add(idx, t);}synchronizedboolean addIfNotExist(T t){if(!c.contains(t)) {c.add(t);return true;}return false;}}
Java SDK在Collections 这个类中还提供了一套完备的包装类
List list = Collections.synchronizedList(new ArrayList());Set set = Collections.synchronizedSet(new HashSet());Map map = Collections.synchronizedMap(new HashMap());
组合操作需要注意竞态条件问题
例如上面提到的 addIfNotExist() 方法就包含组合操作。组合操作往往隐藏着竞态条件问题,即便每个操作都能保证原子性,也并不能保证组合操作的原子性
用迭代器遍历容器
示例代码(存在并发问题,这些组合的操作不具备原子性。)
List list = Collections.synchronizedList(new ArrayList());Iterator i = list.iterator();while (i.hasNext())foo(i.next());
修正:
List list = Collections.synchronizedList(new ArrayList());synchronized (list) {Iterator i = list.iterator();while (i.hasNext())foo(i.next());}
并发容器及其注意事项
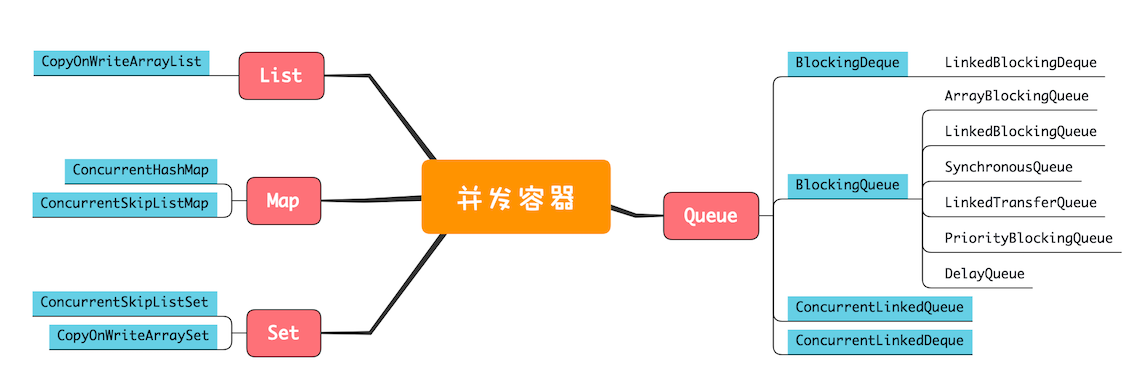
List
List 里面只有一个实现类就是 CopyOnWriteArrayList。CopyOnWrite,顾名思义就是写的时候会将共享变量新复制一份出来,这样做的好处是读操作完全无锁。
实现原理:
CopyOnWriteArrayList 内部维护了一个数组,成员变量 array 就指向这个内部数组,所有的读操作都是基于 array 进行的,如下图所示,迭代器 Iterator 遍历的就是 array 数组。如果在遍历 array 的同时,还有一个写操作,CopyOnWriteArrayList 会将 array 复制一份,然后在新复制处理的数组上执行增加元素的操作,执行完之后再将 array 指向这个新的数组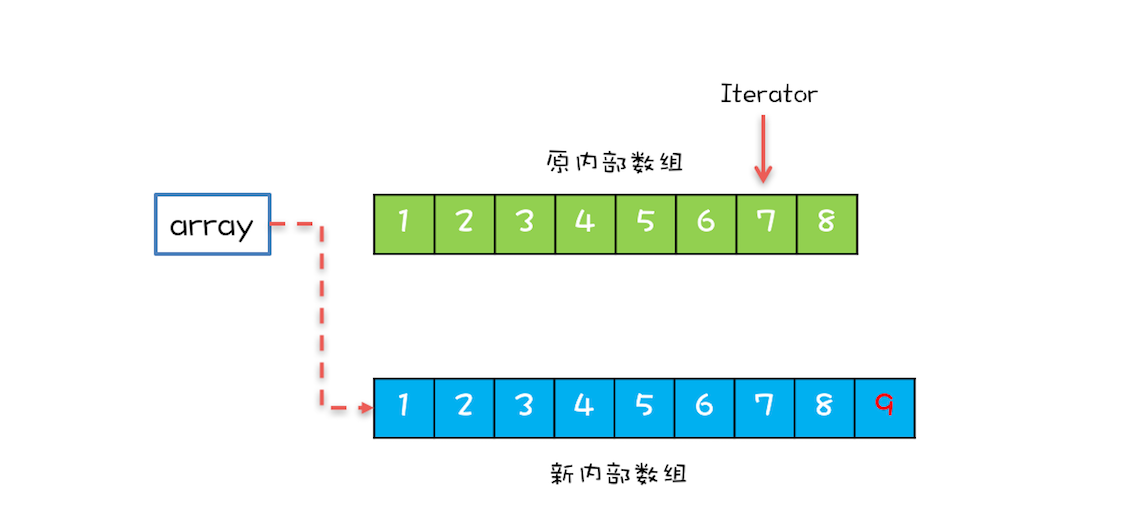
注意:
- CopyOnWriteArrayList 仅适用于写操作非常少的场景,而且能够容忍读写的短暂不一致。例如上面的例子中,写入的新元素并不能立刻被遍历到。
- CopyOnWriteArrayList 迭代器是只读的,不支持增删改。因为迭代器遍历的仅仅是一个快照,而对快照进行增删改是没有意义的
Map
ConcurrentHashMap 和 ConcurrentSkipListMap,它们从应用的角度来看,主要区别在于 ConcurrentHashMap 的 key 是无序的,而 ConcurrentSkipListMap 的 key 是有序的。
需要注意的是key和value的非空情况。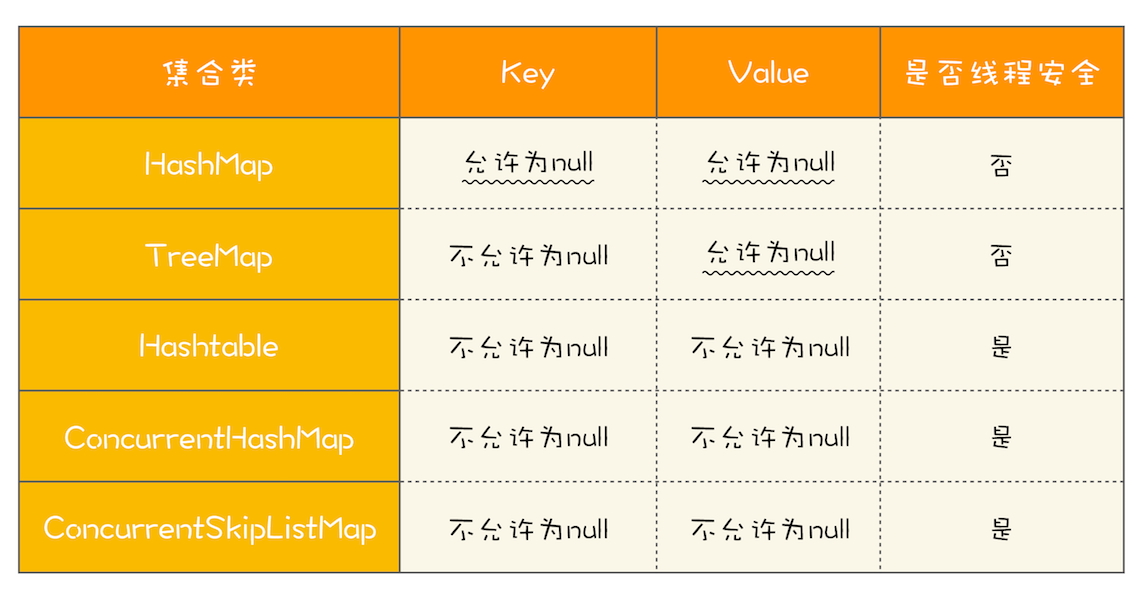
Set
CopyOnWriteArraySet 和 ConcurrentSkipListSet,使用场景可以参考前面讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap,它们的原理都是一样的
Queue
Java 并发包里面 Queue 这类并发容器是最复杂的,你可以从以下两个维度来分类。一个维度是阻塞与非阻塞,所谓阻塞指的是当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。另一个维度是单端与双端,单端指的是只能队尾入队,队首出队;而双端指的是队首队尾皆可入队出队。Java 并发包里阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队列使用 Deque 标识。
这两个维度组合后,可以将 Queue 细分为四大类,分别是:
1.单端阻塞队列:其实现有 ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue。内部一般会持有一个队列,这个队列可以是数组(其实现是 ArrayBlockingQueue)也可以是链表(其实现是 LinkedBlockingQueue);甚至还可以不持有队列(其实现是 SynchronousQueue),此时生产者线程的入队操作必须等待消费者线程的出队操作。而 LinkedTransferQueue 融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好;PriorityBlockingQueue 支持按照优先级出队;DelayQueue 支持延时出队。单端阻塞队列示意图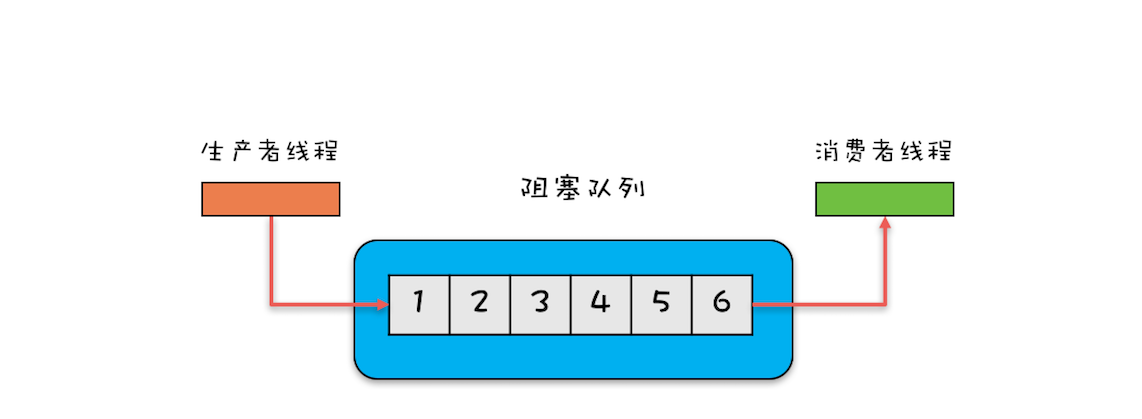
2.双端阻塞队列:其实现是 LinkedBlockingDeque。双端阻塞队列示意图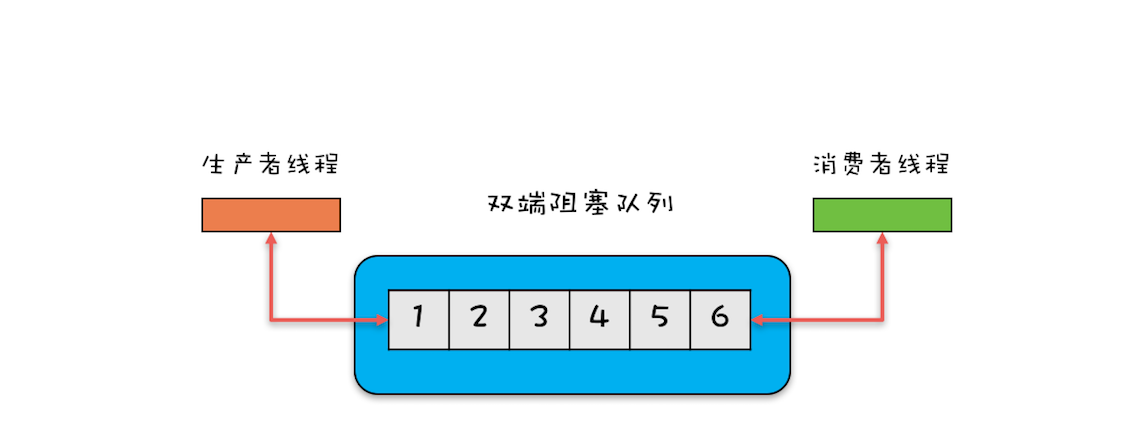
3.单端非阻塞队列:其实现是 ConcurrentLinkedQueue。
4.双端非阻塞队列:其实现是 ConcurrentLinkedDeque。
另外,使用队列时,需要格外注意队列是否支持有界(所谓有界指的是内部的队列是否有容量限制)。实际工作中,一般都不建议使用无界的队列,因为数据量大了之后很容易导致 OOM。上面我们提到的这些 Queue 中,只有 ArrayBlockingQueue 和 LinkedBlockingQueue 是支持有界的,所以在使用其他无界队列时,一定要充分考虑是否存在导致 OOM 的隐患。

若有收获,就点个赞吧
0 人点赞
