概览
MYSQL中SQL的执行流程
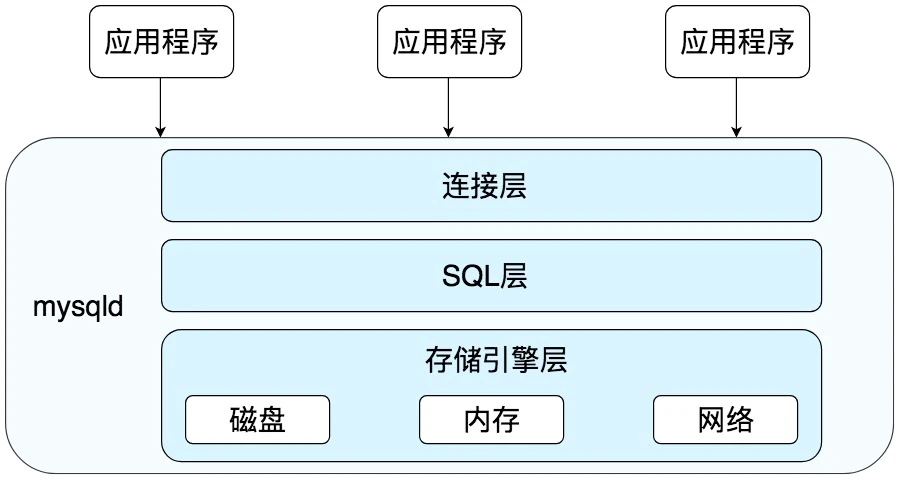
- 连接层: 客户端与服务器端建立连接, 客户端发送SQL到服务器端
- SQL层: 对SQL语句进行查询处理
- 存储引擎层: 与数据库文件打交道, 负责数据的存储和读取
SQL层结构: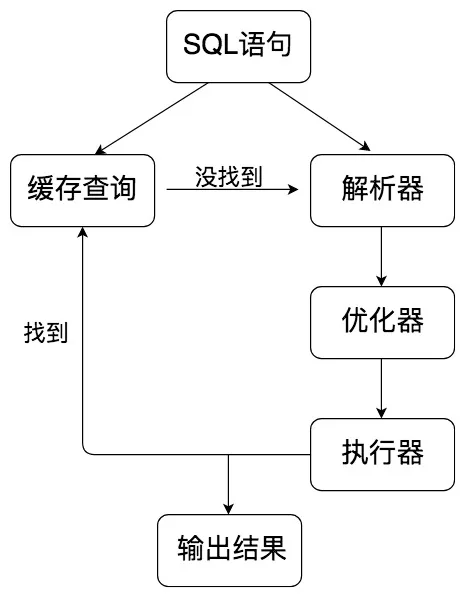
- 查询缓存(MYSQL8.0后抛弃了)
- 解析器: 语法分析, 语义分析
- 优化器: 确定SQL语句的执行路径
- 执行器: 执行之前判断用户权限, 若具备就执行SQL并返回结果
分析SQL执行
-- 打开profiling以收集sql语句执行时所使用的资源情况, 1代表开启set profiling=1;select @@profiling;-- 测试sqlselect * from oa_user WHERE user_name='test';-- 获取执行列表show profiles;-- 查看某个特定的执行详情, 在Navicat中执行完后可以直接点剖析查看show profile for query 94;

count(*)与count(1)
1、一般情况下:COUNT() = COUNT(1) > COUNT(字段)
所以尽量使用COUNT(),当然如果你要统计的是就是某个字段的非空数据行数,那另当别论。毕竟执行效率比较的前提是要结果一样才行。
2、如果要统计COUNT(),尽量在数据表上建立二级索引,系统会自动采用key_len小的二级索引进行扫描,这样当我们使用SELECT COUNT()的时候效率就会提升,有时候提升几倍甚至更高都是有可能的。
事务
ACID, 原子性是基础, 隔离性是手段, 一致性是约束条件, 持久性是最终目的.
一致性指的是写入数据库的任何数据都需满足我们事先定义的约束规则(七种常见约束, 主键, 外键, not null, unique, default, check).
比如说,在数据表中我们将姓名字段设置为唯一性约束,这时当事务进行提交或者事务发生回滚的时候,如果数据表中的姓名非唯一,就破坏了事务的一致性要求。

若有收获,就点个赞吧
0 人点赞
