Kafka副本
- 每个主题下有若干个分区, 每个分区下有若干个副本.
副本本质是一个只能追加写的提交日志
副本作用:
- 提供数据冗余, 提供高可用性
提供高伸缩性, 横向拓展, 提高吞吐量, 实际由于追随者副本不可读, 未能实现改善数据局部性, 允许将数据放入与用户地理位置相近的点, 从而降低延时, 同上未能实现
副本采用的是基于领导者的角色机制, 追随者不对外提供服务, 唯一的任务是从领导者异步拉取消息, 并写入自身的提交日志
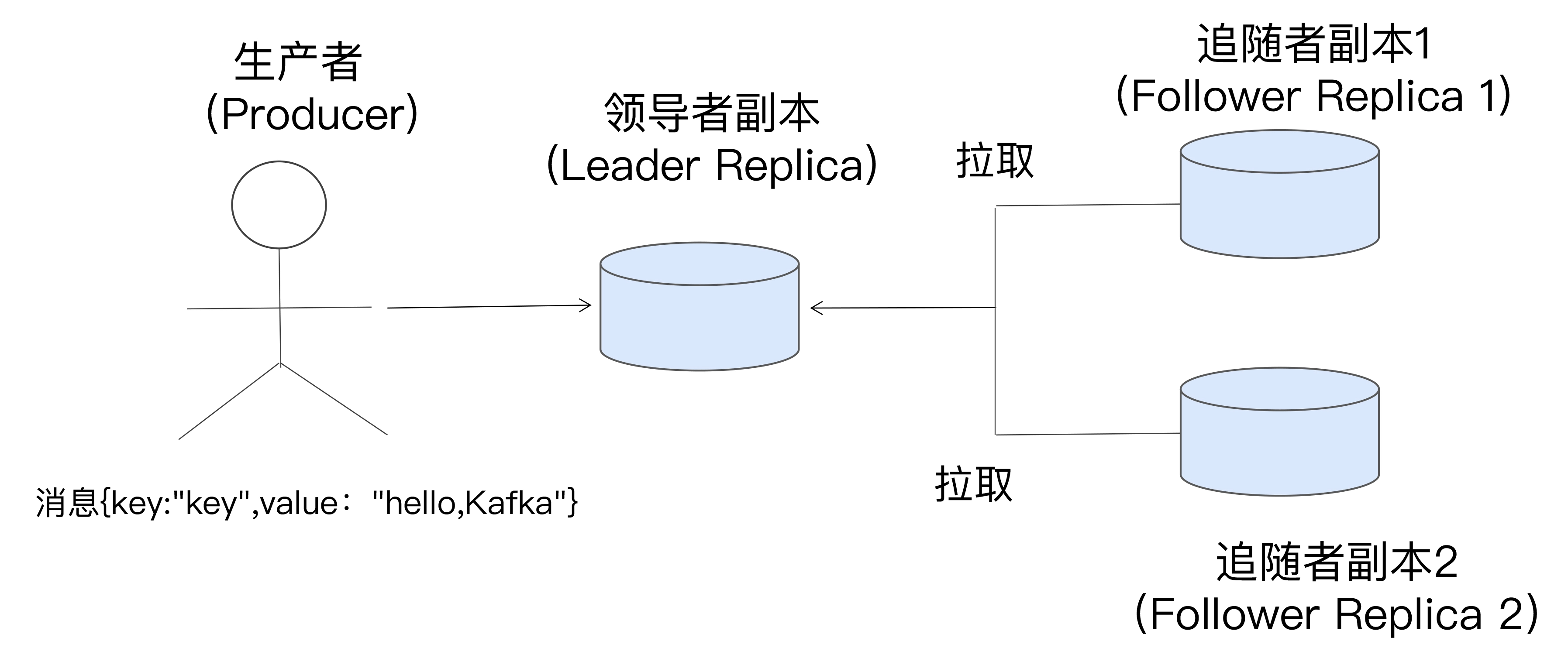
In-sync Replicas(ISR)
ISR 副本集合, ISR 中的副本都是与 Leader 同步的副本,相反,不在 ISR 中的追随者副本就被认为是与 Leader 不同步的, 称为非同步副本。ISR必然包括 Leader 副本.
Kafka 判断 Follower 是否与 Leader 同步的标准是 Broker 端参数replica.lag.time.max.ms 参数值, 默认值为10s, 表示Follower 副本能够落后 Leader 副本的最长时间间隔, ISR是一个根据此标准动态调整的集合
在Kafka中, 选择非同步副本的过程称为Unclean 领导者选举。Broker 端参数 unclean.leader.election.enable 控制是否允许 Unclean 领导者选举。开启提升了高可用性, 但可能造成数据丢失, 建议禁止.
请求处理过程
- Apache Kafka 自己定义了一组请求协议,用于实现各种各样的交互操作。比如常见的 PRODUCE 请求是用于生产消息的,FETCH 请求是用于消费消息的,METADATA 请求是用于请求 Kafka 集群元数据信息的。
- 所有的请求都是通过 TCP 网络以 Socket 的方式进行通讯的。
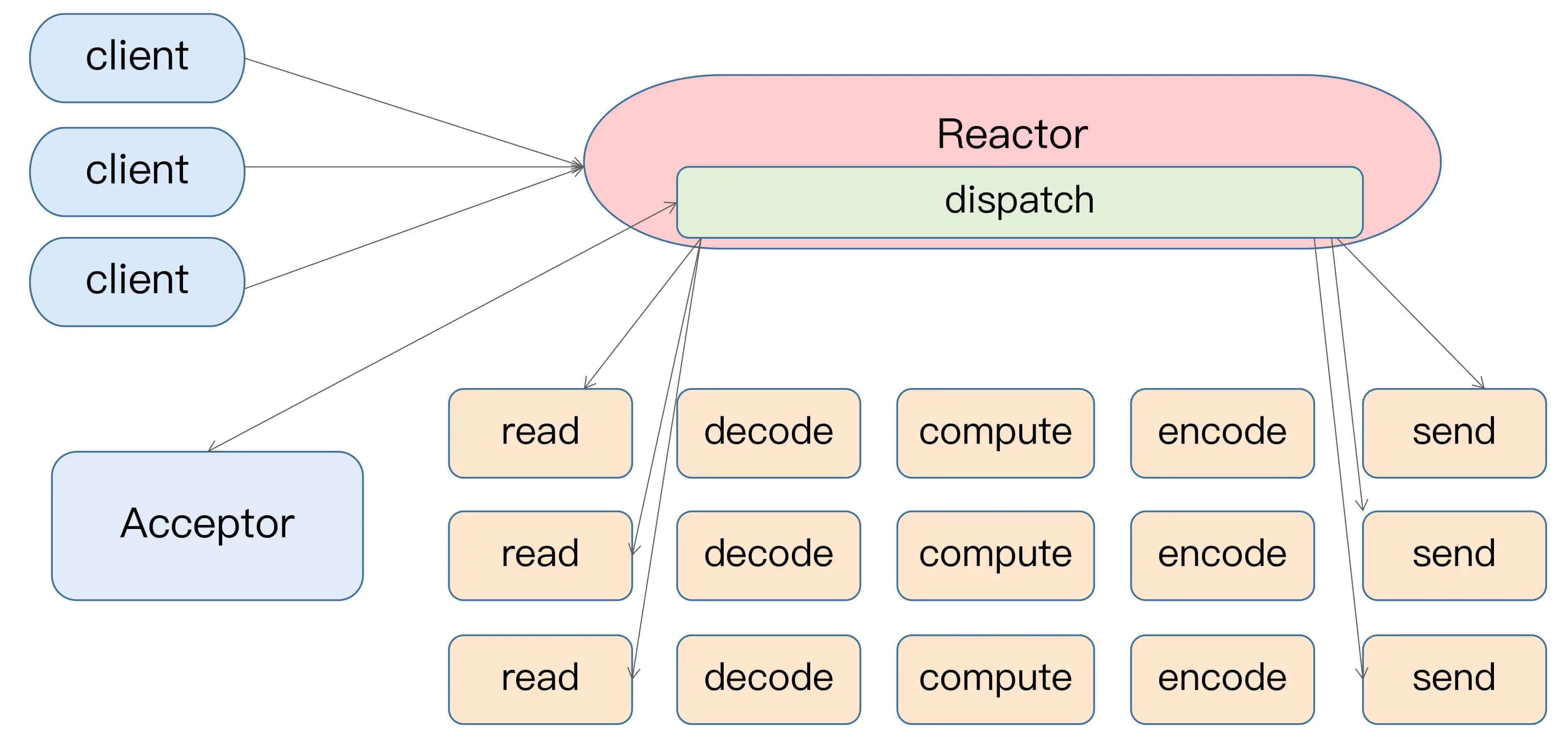
Kafka 使用的是 Reactor 模式来处理请求
Reactor 模式的架构如下图所示:
- 多个客户端会发送请求给到 Reactor。Reactor 有个请求分发线程 Dispatcher,也就是图中的 Acceptor,它会将不同的请求下发到多个工作线程中处理。
- Acceptor 线程只是用于请求分发,不涉及具体的逻辑处理,非常得轻量级,因此有很高的吞吐量表现。而这些工作线程可以根据实际业务处理需要任意增减,从而动态调节系统负载能力。
请求获取分发
Kafka的Reactor架构示例
- SocketServer 组件,类似于 Reactor 模式中的 Dispatcher,它也有对应的 Acceptor 线程和一个工作线程池
- Kafka 提供了 Broker 端参数 num.network.threads,用于调整该网络线程池的线程数。其默认值是 3,表示每台 Broker 启动时会创建 3 个网络线程,专门处理客户端发送的请求。
- Acceptor 线程采用轮询的方式将入站请求公平地发到所有网络线程中
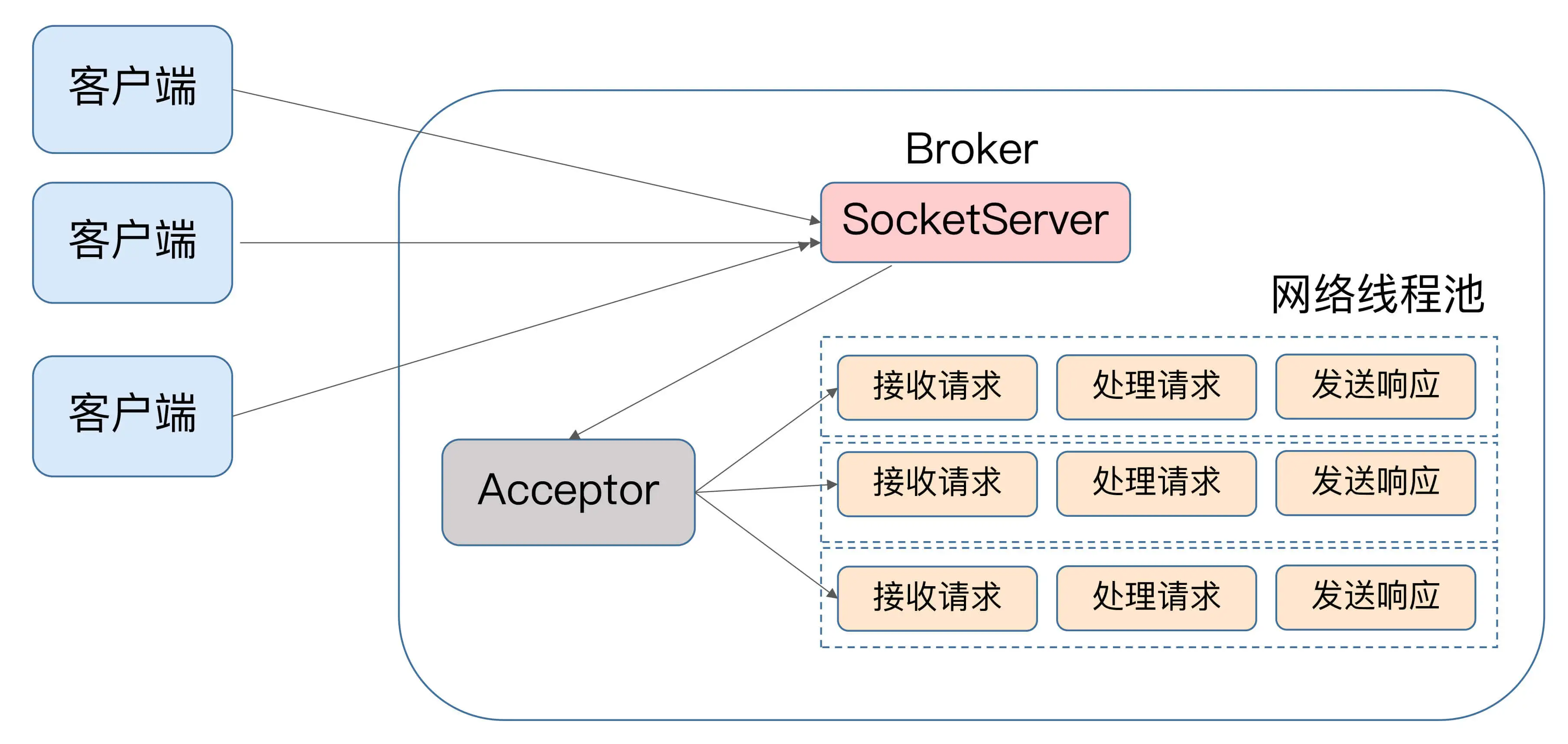
请求处理
当网络线程拿到请求后,它不是自己处理,而是将请求放入到一个共享请求队列中。Broker 端还有个 IO 线程池,负责从该队列中取出请求,执行真正的处理。如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
IO 线程池处中的线程才是执行请求逻辑的线程。Broker 端参数 num.io.threads 控制了这个线程池中的线程数。目前该参数默认值是 8,表示每台 Broker 启动后自动创建 8 个 IO 线程处理请求。你可以根据实际硬件条件设置此线程池的个数。
请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属的。这么设计的原因就在于,Dispatcher 只是用于请求分发而不负责响应回传,因此只能让每个网络线程自己发送 Response 给客户端,所以这些 Response 也就没必要放在一个公共的地方。
Purgatory 的组件,这是 Kafka 中著名的“炼狱”组件。它是用来缓存延时请求(Delayed Request)的。所谓延时请求,就是那些一时未满足条件不能立刻处理的请求。比如设置了 acks=all 的 PRODUCE 请求,一旦设置了 acks=all,那么该请求就必须等待 ISR 中所有副本都接收了消息后才能返回,此时处理该请求的 IO 线程就必须等待其他 Broker 的写入结果。当请求不能立刻处理时,它就会暂存在 Purgatory 中。稍后一旦满足了完成条件,IO 线程会继续处理该请求,并将 Response 放入对应网络线程的响应队列中。
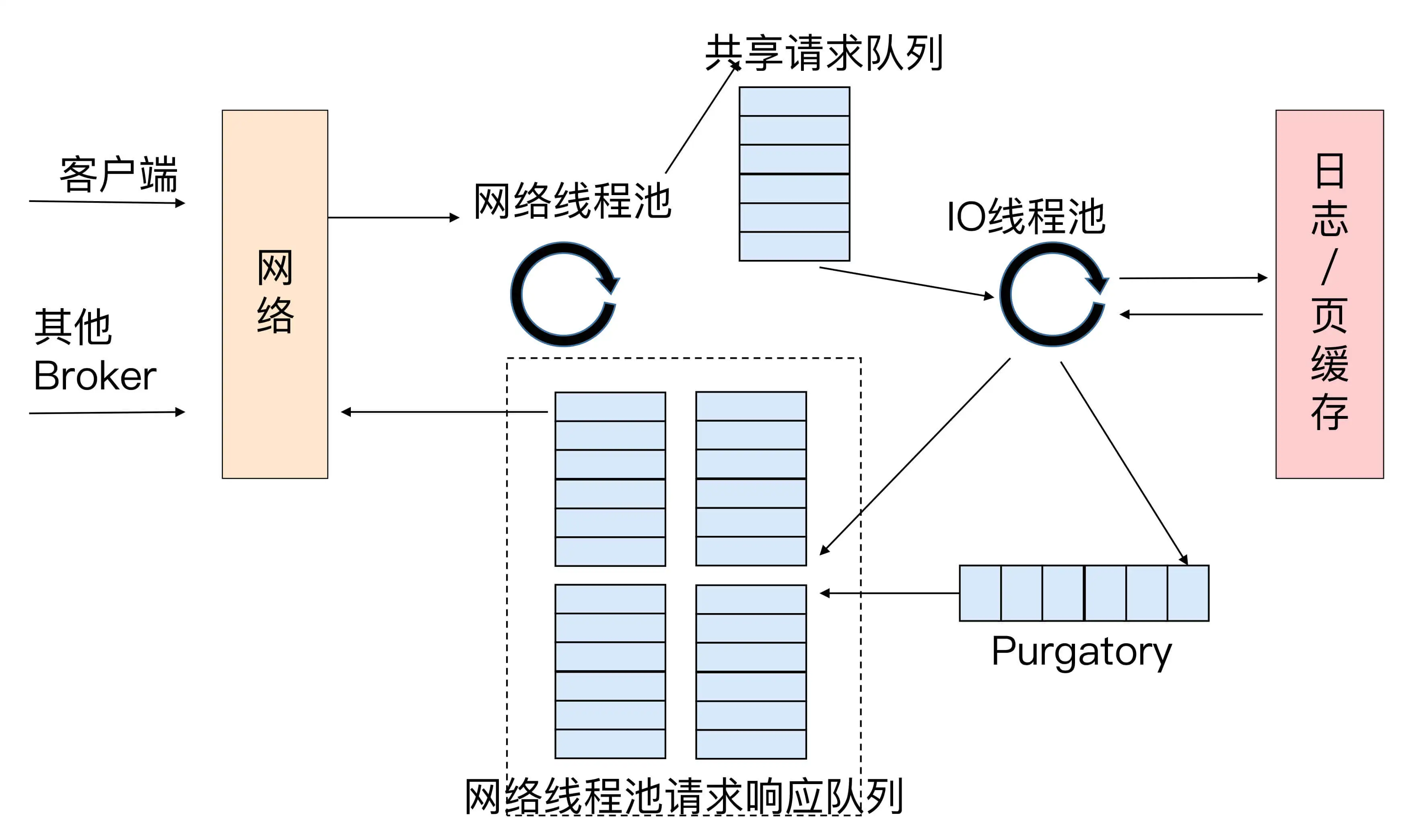
控制类请求与数据类型请求分离
在 Kafka 内部,还有很多执行其他操作的请求类型,比如负责更新 Leader 副本、Follower 副本以及 ISR 集合的 LeaderAndIsr 请求,负责勒令副本下线的 StopReplica 请求等。这些请求是控制类的请求。也就是说,它们并不是操作消息数据的,而是用来执行特定的 Kafka 内部动作的。
控制类请求可以直接令数据类请求失效!它的优先级更高. 社区通过完全拷贝上图中的组件, 实现两类请求的分离.也就是说,Kafka Broker 启动后,会在后台分别创建两套网络线程池和 IO 线程池的组合,它们分别处理数据类请求和控制类请求。
Rebalance全流程
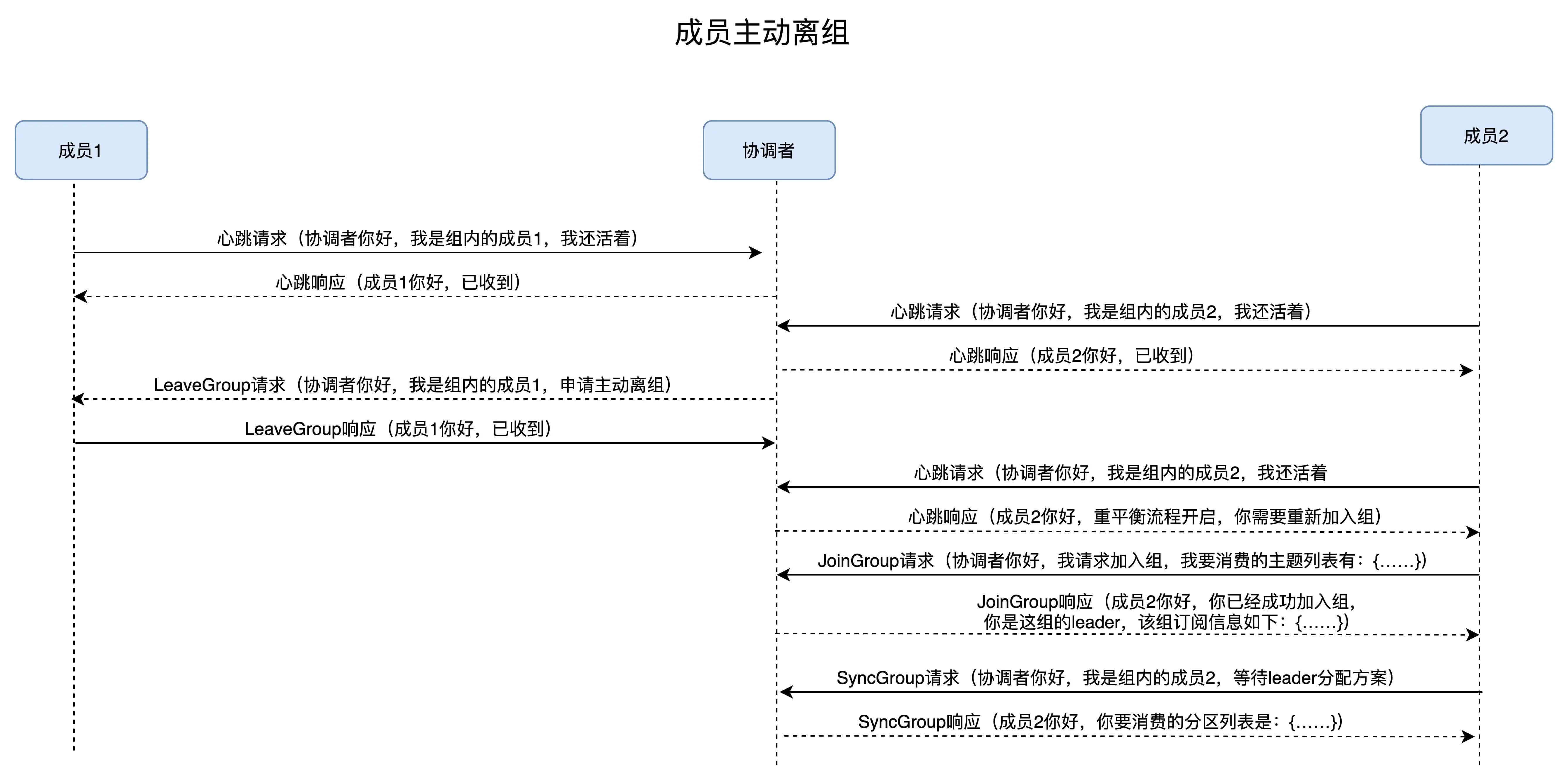
重平衡的 3 个触发条件:
- 组成员数量发生变化
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
重平衡通知
重平衡是通过心跳线程来通知到消费者实例的
- 当协调者决定开启新一轮重平衡后,它会将“REBALANCE_IN_PROGRESS”封装进心跳请求的响应中,发还给消费者实例
- heartbeat.interval.ms, 该参数设置了心跳的间隔时间, 也是重平衡通知的频率, 减小该值, 能让消费者更迅速的感知到重平衡
消费者组状态机
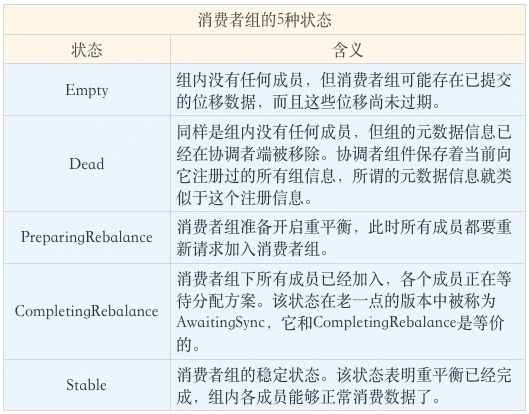
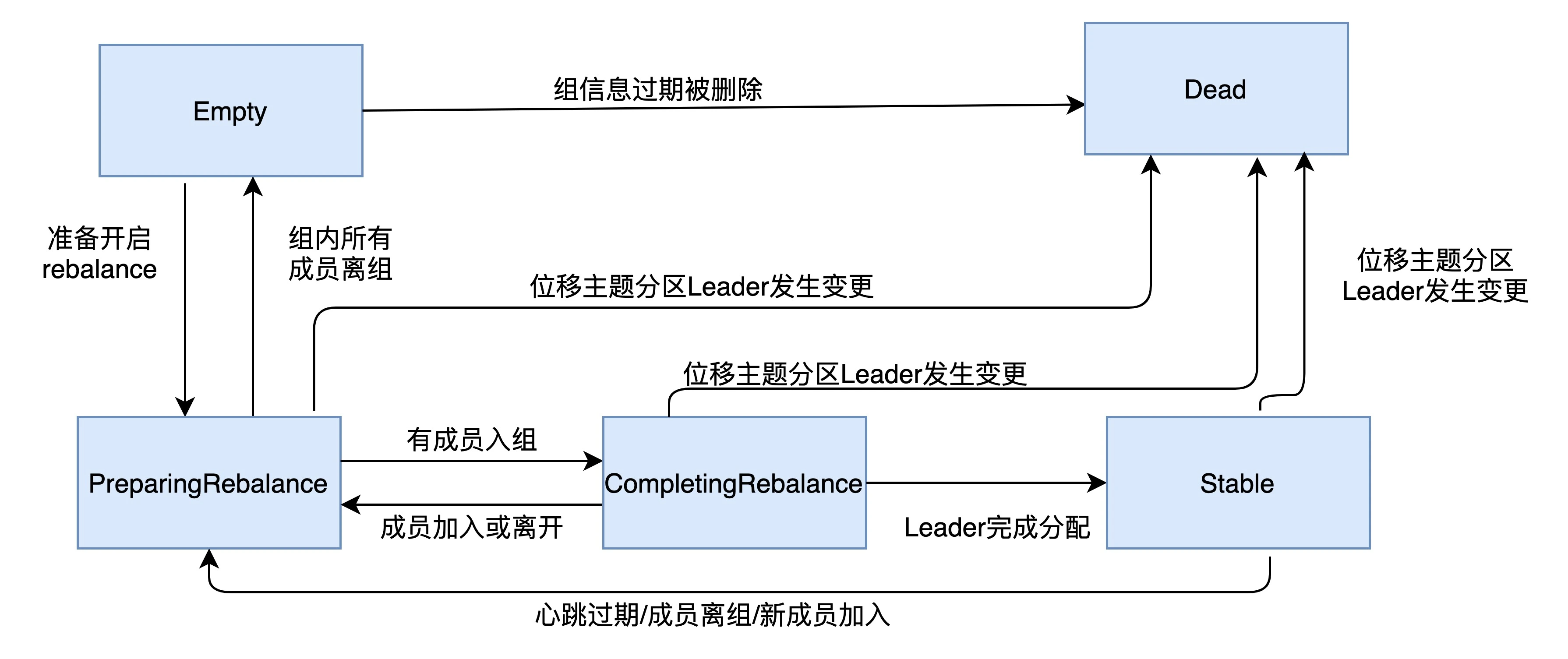
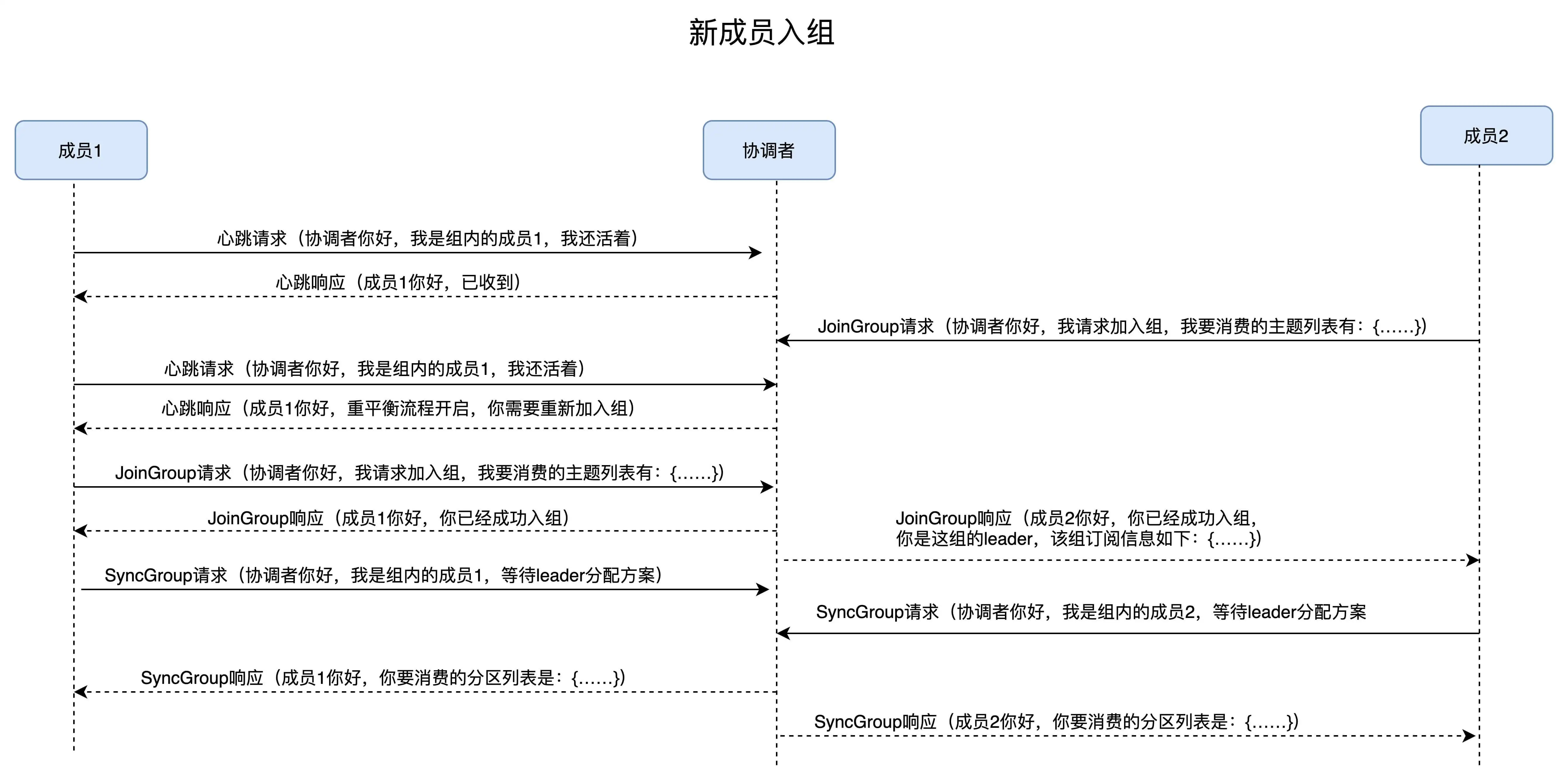
消费端重平衡流程
- 成员加入组时, 向协调者发送JoinGroup请求携带自身订阅的主题, 协调者收集全部成员请求后, 通常选择第一个发JoinGroup的消费者作为领导者消费者
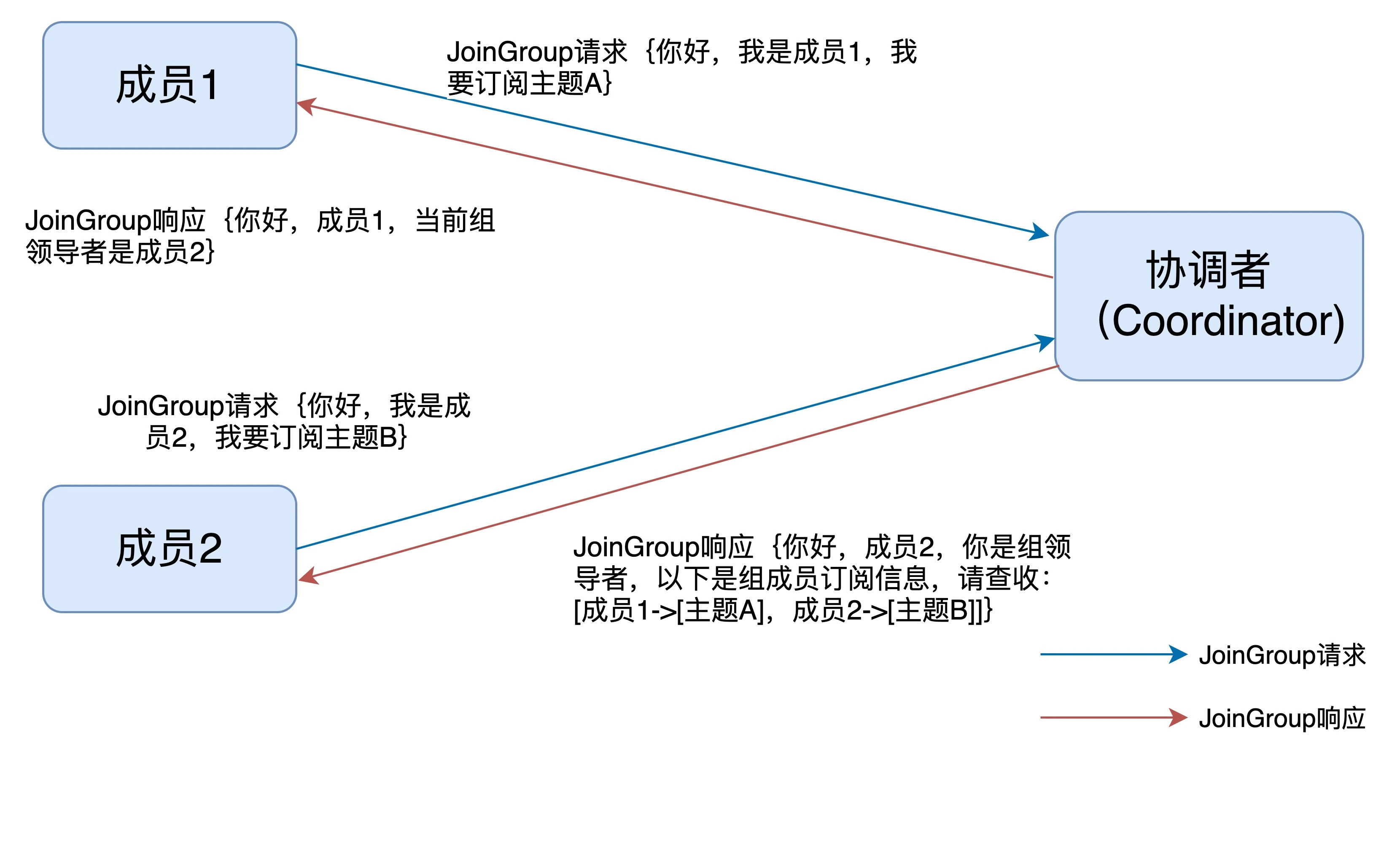
- 领导者消费者根据所有成员的订阅信息制定具体的分区消费分配方案, 然后向协调者发送SyncGroup请求, 协调者再统一以SyncGroup响应方式将方案分发给所有成员
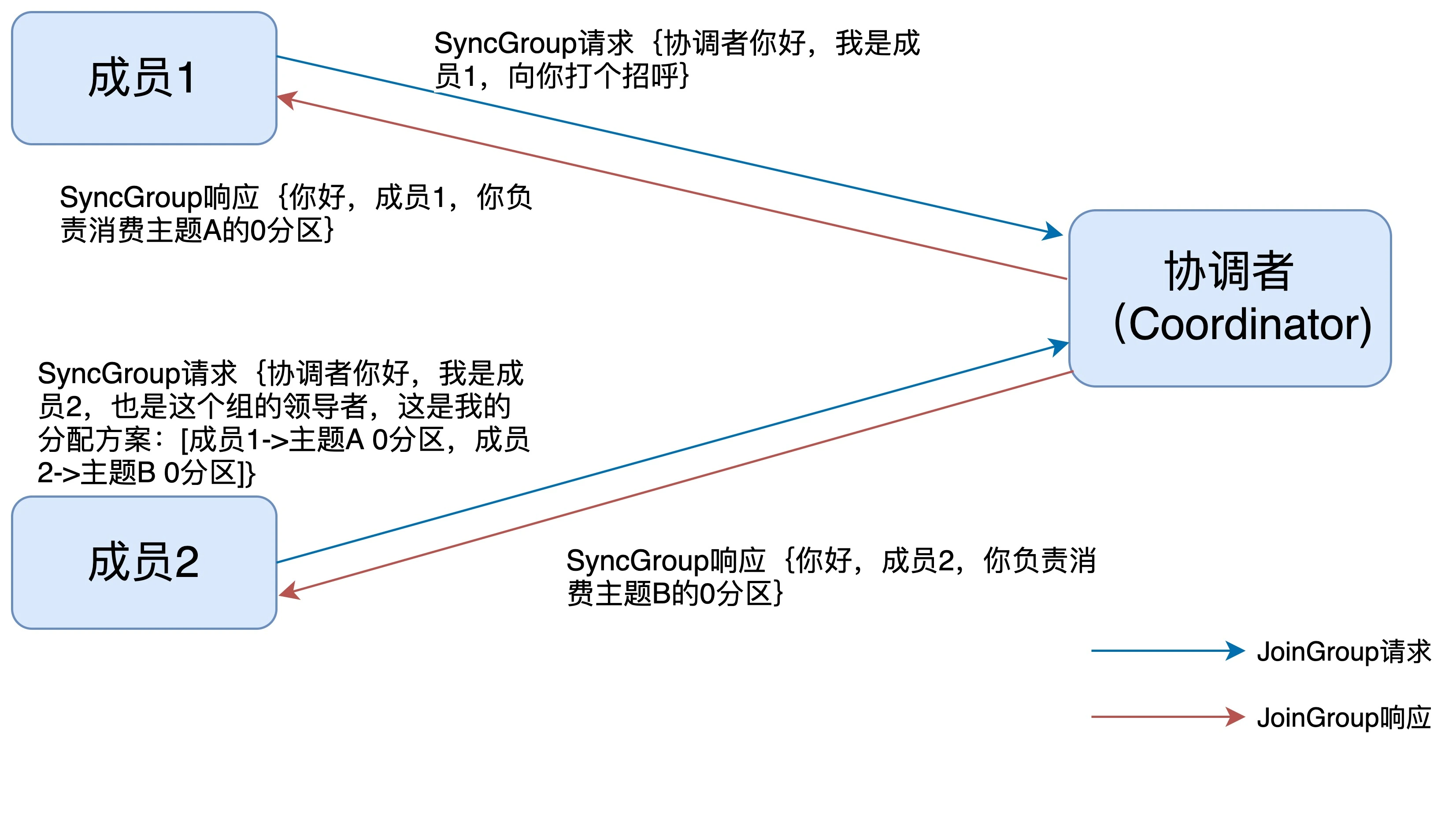
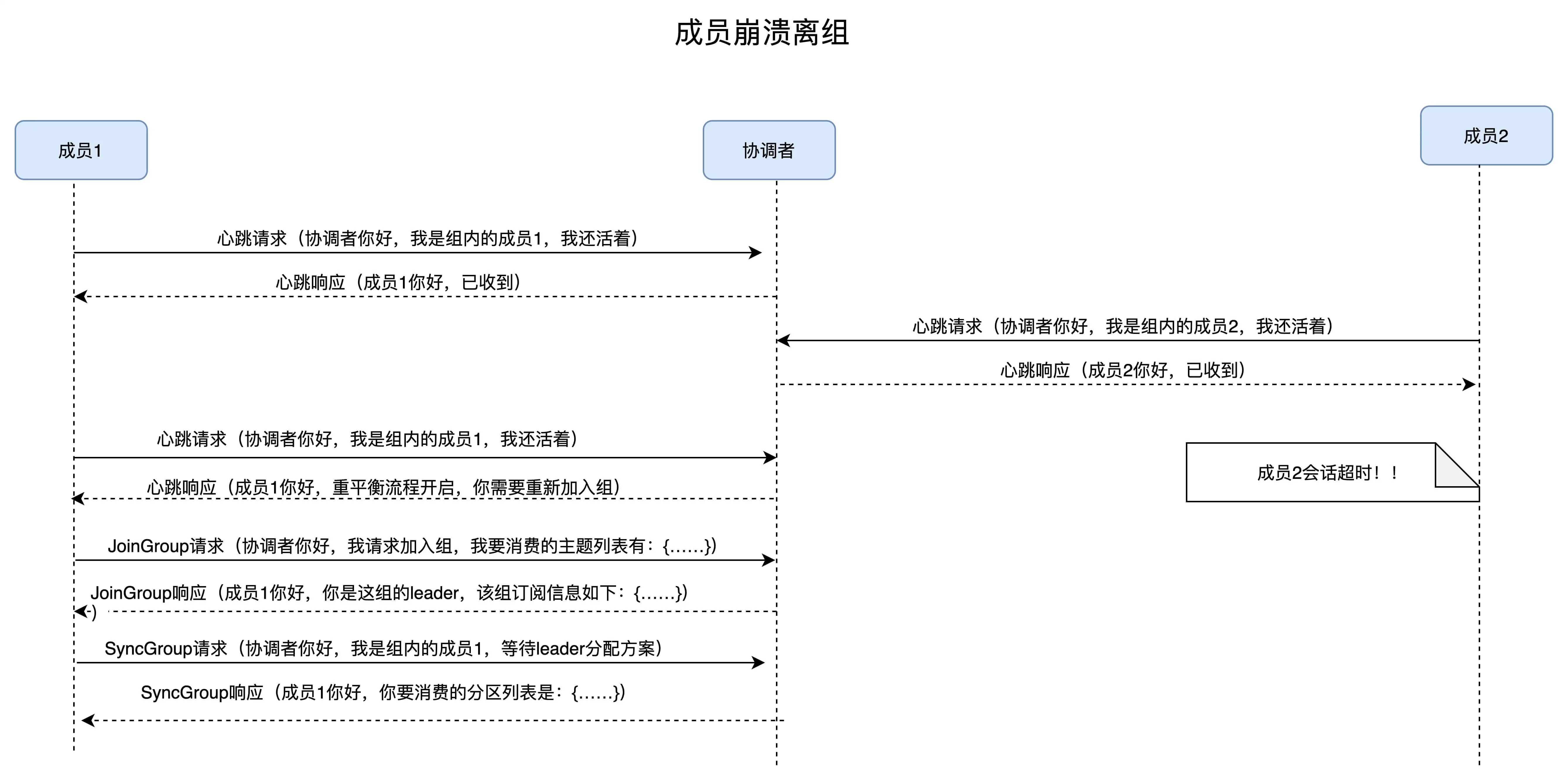
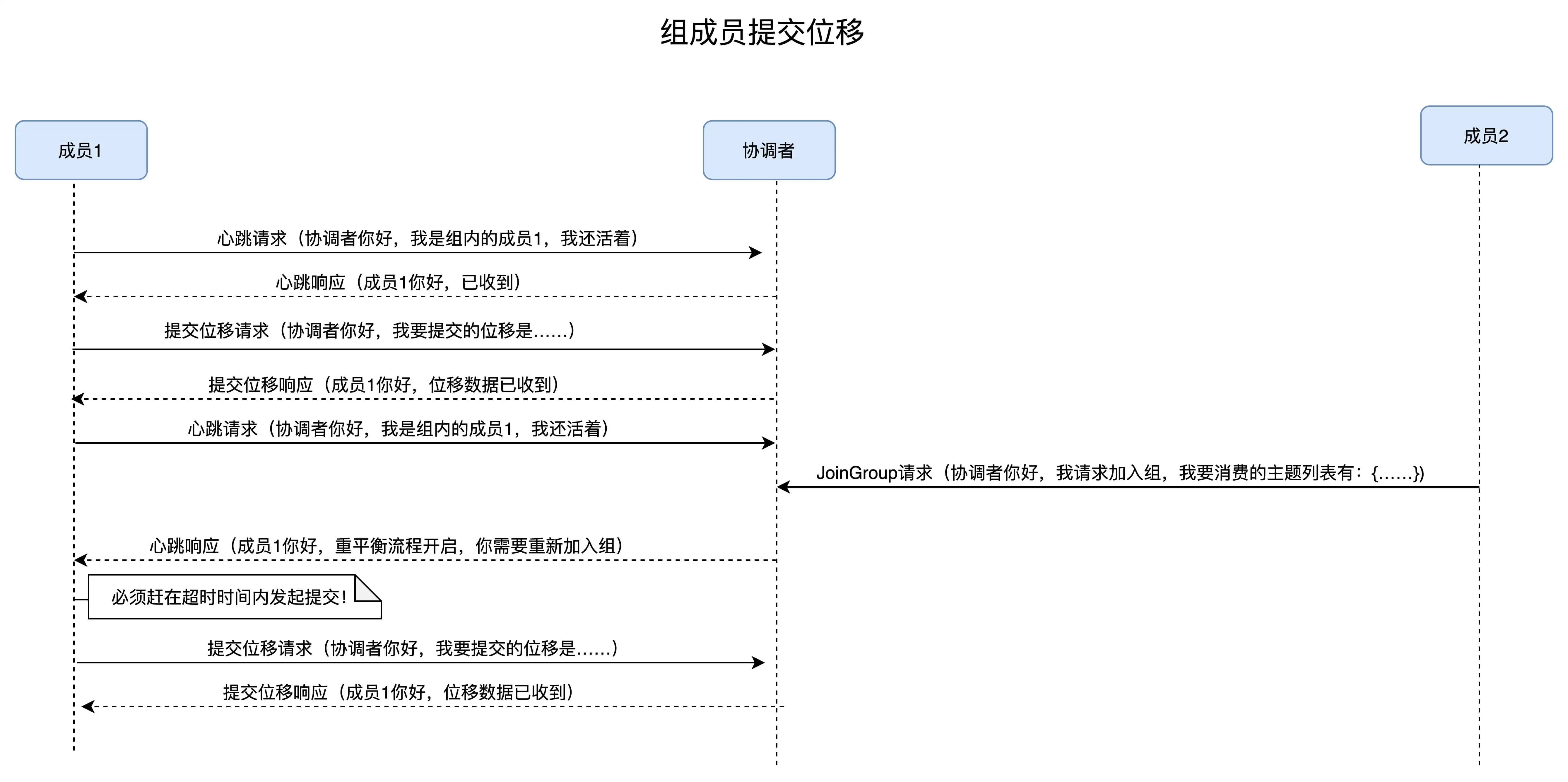
Broker端重平衡场景剖析

若有收获,就点个赞吧
0 人点赞
