在深度学习网络中,通常需要设计一个模型的损失函数来约束我们的训练过程,如针对分类问题可以使用交叉熵损失,针对回归问题可以使用均方误差损等。
模型的训练并不是漫无目的的,而是朝着最小化损失函数的方向去训练,这时候就会用到梯度下降类的算法。
梯度下降法(gradient descent)是一个一阶最优化算法,通常也称为最速下降法,是通过函数当前点对应梯度的反方向,使用规定步长进行迭代搜索,从而找到一个函数的局部极小值的算法,最好的情况是,我们希望找到全局最小值。
当样本总量特别大的时候,对算法的速度影响非常大,所以就有了随机梯度下降法(stochastic gradient descent,SGD)算法。每次只取一部分样本进行梯度下降
1.梯度下降法——公式推导
https://www.cnblogs.com/pinard/p/5970503.html

2.BGD、SGD、MBGD
2.1批量梯度下降法(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新,这个方法对应于前面3.3.1的线性回归的梯度下降算法,也就是说3.3.1的梯度下降算法就是批量梯度下降法。 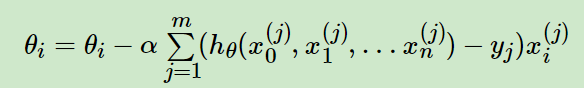
由于我们有m个样本,这里求梯度的时候就用了所有m个样本的梯度数据
2.2 随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是: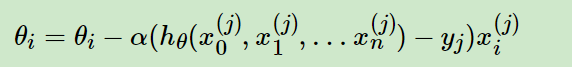
随机梯度下降法,和4.1的批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
那么,有没有一个中庸的办法能够结合两种方法的优点呢?有!这就是4.3的小批量梯度下降法。
2.3 小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样子来迭代,1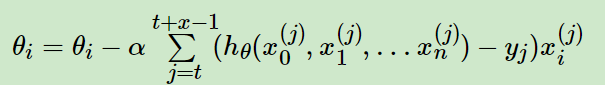

若有收获,就点个赞吧
0 人点赞
