Abstract
受VGG-net的启发,增加网络深度能显著提高准确度,本文设计了非常深的卷积网络。
在深度网络结构中多次叠加过滤器,可以有效利用大图像区域上的上下文信息。
但是在非常深的网络结构中,训练过程中收敛的速度会变慢,
因此本文方法仅学习残差,并使用梯度裁剪(gradient clipping)提高学习率,从而加快收敛速度。
1.Introduction
SRCNN成功地将深度学习技术引入了超分辨率(SR)问题,但在三个方面存在局限性:
1.它依赖于图像区域的上下文信息;
2.训练收敛太慢;
3.网络仅适用于单个规模(single scale)。
本文作者提出的方法可以有效解决这些问题。
上下文Context:利用分布在大范围图像区域的上下文信息。
较小图像块包含的信息不足以恢复图像细节,本文中非常深的网络使用了考虑大范围图像上下文信息的感知域。
收敛Convergence 残差学习的卷积神经网络和极高的学习率。
由于LR图像和HR图像在很大程度上共享相同的信息,
因此对HR和LR图像之间的差异即残差信息进行显式建模(explicitly modelling)是有效的。
本文使用残差学习和梯度裁剪,提出了适用于输入和输出密切相关的网络结构,
比例因子Scale Factor 提出了一个单模型的超分辨率方法。
训练和存储许多与比例有关的模型以应对所有可能的缩放比例是不切实际的。
本文提出使用单个卷积网络足以实现不同尺度因子超分辨率。
贡献Contribution
本文提出了一种基于非常深的卷积网络的高精度SR方法。
如果使用小的学习率,那么非常深的网络收敛太慢。
通过提高学习速度来提高收敛速度会导致梯度爆炸,但通过残差学习和梯度裁剪可以解决这一问题。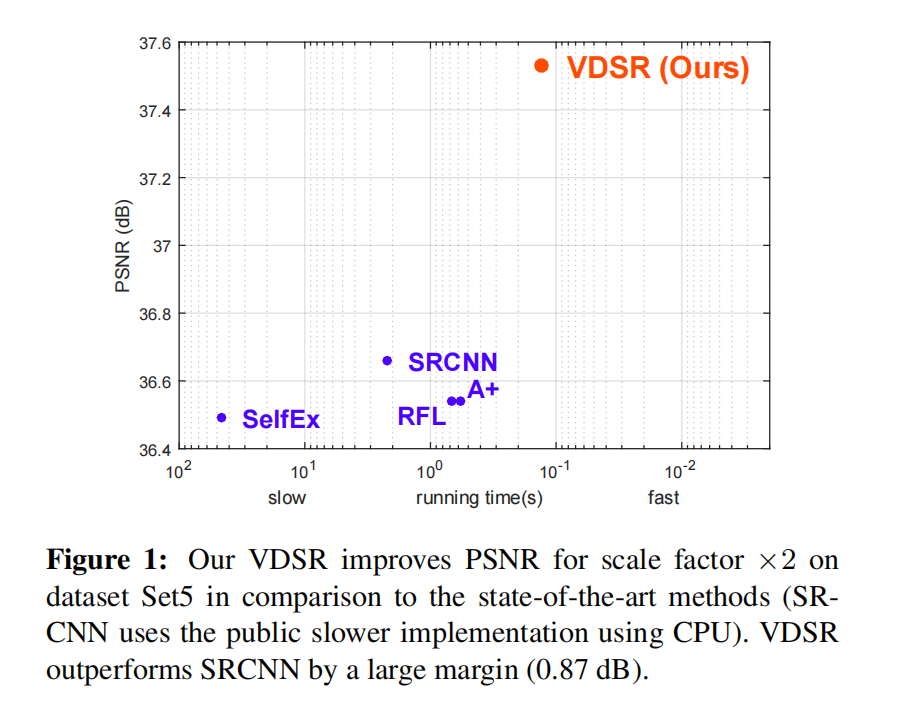
本篇论文我需要搞懂四个问题: 1.Context如何发挥

若有收获,就点个赞吧
0 人点赞
