本次数据分析作业的核心在于,把长度为8192的时域信号,通过机器学习或者深度学习的方法,实现三分类功能。
这里的核心问题在于:如何把一维的数据,进行3分类。
self.dnn = nn.Sequential(nn.Linear(8192, 2048),nn.BatchNorm1d(2048),nn.Dropout(0.8),nn.ReLU(),nn.Linear(2048, 1024),nn.BatchNorm1d(1024),nn.Dropout(0.7),nn.ReLU(),nn.Linear(1024, 256),nn.BatchNorm1d(256),nn.Dropout(0.6),nn.ReLU(),nn.Linear(256, 128),nn.BatchNorm1d(128),nn.ReLU(),nn.Linear(128, 3))
这是老师给出的DNN网络模型,核心思想是通过全连接层构建简单的神经网络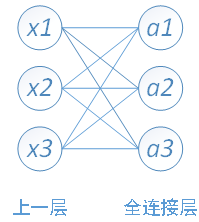
通过对5个全连接层,把8192个输入神经元,映射到3个神经元的输出上,网络深度较深。同时训练效果不好,测试出来只有68%的准确率。我个人猜测可能是,全连接层处理这种复杂的非线性问题效果不一定会好。并且通过多次的BatchNormalization可能会破坏了数据的结构。
我们采用的是一个新的网络架构
class Dnn(nn.Module):def __init__(self):super().__init__()self.dnn = nn.Sequential(nn.Conv1d(1,8,33,1),nn.MaxPool1d(4),nn.Conv1d(8,16,33,1),nn.MaxPool1d(4),nn.Conv1d(16,32,31,1),nn.MaxPool1d(4),nn.Conv1d(32,64,19,1),nn.MaxPool1d(4),nn.Flatten(),nn.Linear(1600,512),nn.Linear(512,128),nn.Linear(128,3))def forward(self, x):out = self.dnn(x)return out
我们采用了conv1d的1维卷积方法来对数据进行处理。为了配合conv1d的数据结构,我们需要对输入的数据集进行预处理,把训练集的tensor维度+1
class MyDataset(Dataset):def __init__(self, x, y):super().__init__()self.x = torch.FloatTensor(x).unsqueeze(1)self.y = torch.LongTensor(y)def __getitem__(self, idx):return self.x[idx], self.y[idx]def __len__(self):return len(self.y)
这里可以通过torch.unsqueeze(1)来实现。增加的1维,为特征维度。
在训练时,我们采用了
model = Dnn().to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.AdamW(model.parameters(), lr=0.001)scheduler=torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[60,100,150],gamma=0.5)
变学习率的训练方法,在60,100,150epochs的时候,放慢1倍的学习率,这样可以避免梯度爆炸和梯度消失的问题。同时也会避免出现学习率过大从而无法收敛的问题。
关于核心网络的解释:
class Dnn(nn.Module):def __init__(self):super().__init__()self.dnn = nn.Sequential(nn.Conv1d(1,8,33,1), #把1维的输入变成8维的输出nn.MaxPool1d(4),nn.Conv1d(8,16,33,1),#把8维的输入变成64维的输出nn.MaxPool1d(4),nn.Conv1d(16,32,31,1),nn.MaxPool1d(4),nn.Conv1d(32,64,19,1),nn.MaxPool1d(4),nn.Flatten(),nn.Linear(1600,512),nn.Linear(512,128),nn.Linear(128,3))def forward(self, x):out = self.dnn(x)return out
conv1d是1维卷积,采用卷积可以获取更大的感受野,这里设置kernel_size=33。之后的MaxPool1d(4)是池化层,目的是增大卷积的感受野,让模型可以更好的关注输入数据的上下文信息。
通过conv1d把输入数据的特征维度不断放大,最后再缩小,经过多个卷积层的处理,以提高模型的非线性拟合能力。
之后的Flatten是要把tensor压缩到1维,方便之后的全连接层运算。
经过计算后可以得出,此时输入全连接层的数据长度为1600。

模型训练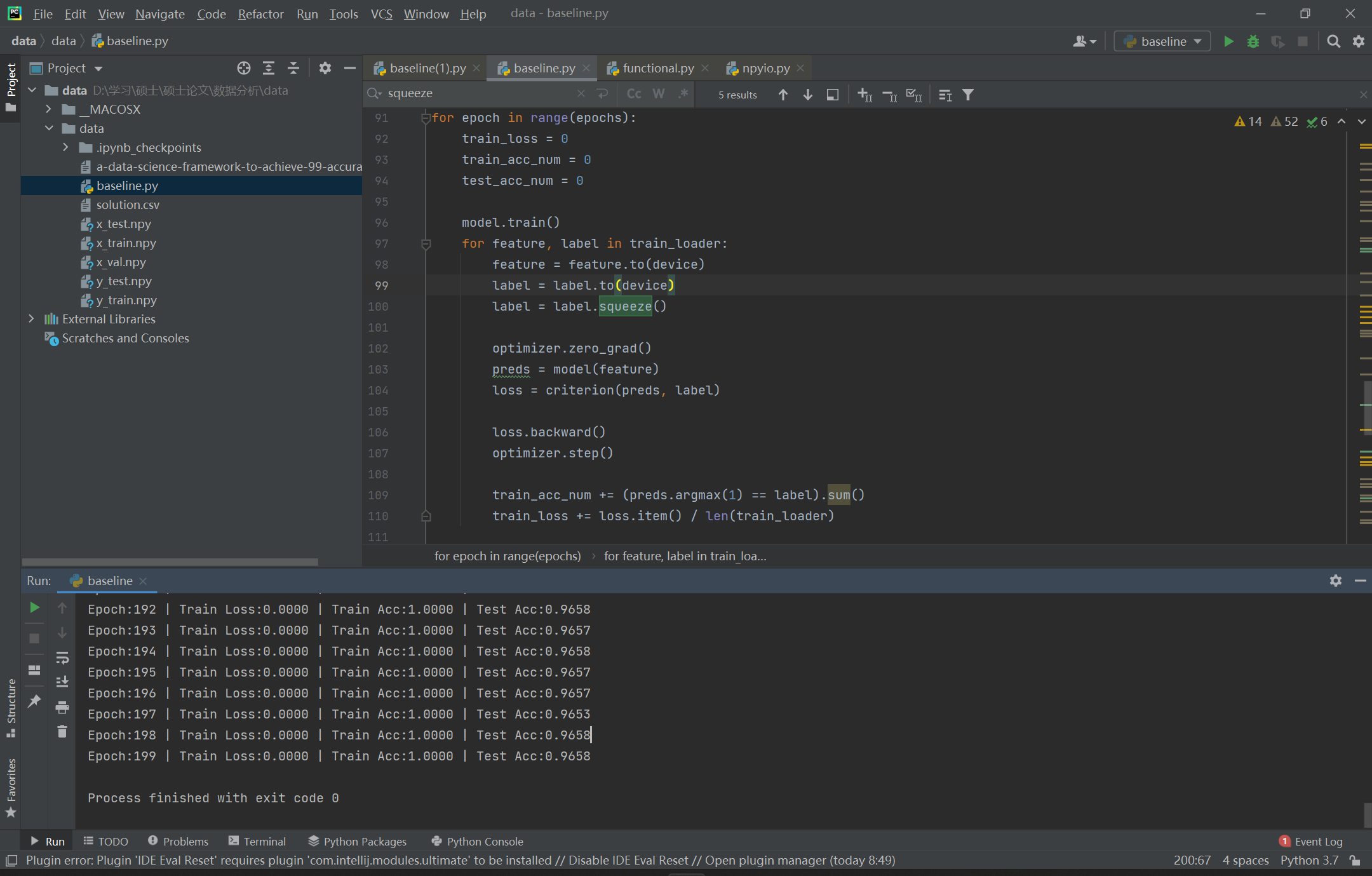
可以从图中看出,经过200个epoch的训练,训练精度达到了100%,测试精度达到了96%
1.数据读取
我们使用pytorch(深度学习工具包)对数据进行学习和训练的时候,首先我们需要数据,这里为了匹配pytorch的代码结构,我们需要把数据打包成数据集的格式。
# 第一步:数据读取data_path = 'D:\学习\硕士\硕士论文\数据分析\data\data' # 存放数据的路径## 读取训练集x_train = np.load(data_path + '/x_train.npy')y_train = np.load(data_path + '/y_train.npy')## 读取测试集x_test = np.load(data_path + '/x_test.npy')y_test = np.load(data_path + '/y_test.npy')## 读取待提交数据x_val = np.load(data_path + '/x_val.npy')
这里的 x_train.npy y_train.npy都是数据文件。
np.load()是先把数据文件,通过numpy来进行读取,之后再通过pytorch把numpy的格式转化为匹配pytorch代码结构的数据格式。一般是tensor的张量格式。
class MyDataset(Dataset):def __init__(self, x, y):super().__init__()# 转化成tensor格式self.x = torch.FloatTensor(x).unsqueeze(1)self.y = torch.LongTensor(y)def __getitem__(self, idx):# 获取数据集的元素return self.x[idx], self.y[idx]def __len__(self):# 获取数据集的长度return len(self.y)
这里的数据集
train_dataset = MyDataset(x_train, y_train)test_dataset = MyDataset(x_test, y_test)
的作用就是把数据转化为tensor的数据结构。通过重写数据集的类来实现。
在pytorch中,数据是以tensor来处理的,tensor可以理解为[1,2,3,4]这种多维的矩阵。比如说4维的tensor就是[1,2,3,4]每个格子里面都可以存放数字信息。
self.x = torch.FloatTensor(x).unsqueeze(1)
是因为,我们需要把输入的Float的numpy格式转化为Tensor格式。这里的unsqueeze(1)的目的是,扩充tensor的维度。额外置放一个维度用来填充输入序列的特征维度。
1.2 读取训练集和测试集
机器学习的任务就是通过对训练集的训练,来求得相应的参数模型,最后用训练得到的模型来预测测试集的结果。
简单的理解:训练集是模拟题 训练出来的模型是我们总结归纳的结论,测试集就是考试。
我们训练的东西是网路的参数。可以画一个简单的全连接网络来理解什么是训练好的模型。
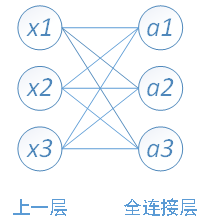
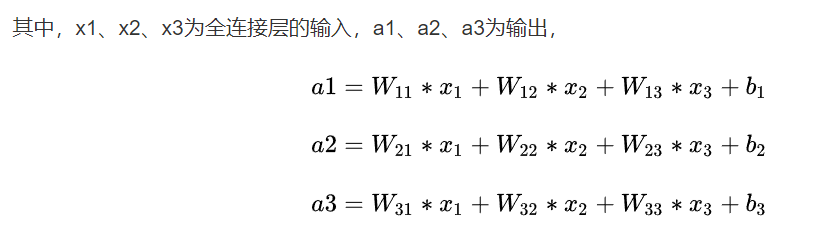
训练的就是其中的W11,W12,W13 b1……这些参数。最后预测的模型其实也就是一个函数,我们需要知道函数的系数是什么。
我们一般会把训练的结果保存下来,之后使用网络模型的时候可以直接读取权重参数。
数据预处理
数据预处理,主要就是使输入的数据的分布更适合接下来的处理过程。
一般有标准化,归一化,最大最小值法。
第一步:数据读取
# 第一步:数据读取data_path = 'D:\学习\硕士\硕士论文\数据分析\data\data' # 存放数据的路径
读取训练集
## 读取训练集x_train = np.load(data_path + '/x_train.npy')y_train = np.load(data_path + '/y_train.npy')
读取测试集
## 读取测试集x_test = np.load(data_path + '/x_test.npy')y_test = np.load(data_path + '/y_test.npy')
读取待提交数据
## 读取待提交数据x_val = np.load(data_path + '/x_val.npy')
第二步:数据预处理
数据预处理采用的是Min-Max处理方法,避免数据出现过大的偏离,通过Min-Max方法来减少数据的方差。
def process(data):'''这里采用minmax数据处理方式'''data = data / np.expand_dims(np.max(np.abs(data), 1), axis=1)return datax_train = process(x_train)x_test = process(x_test)# 注意:提交的时候,一定要对验证集做同样的数据预处理x_val = process(x_val)
在处理时,我们要对所有的数据进行处理,所以要统一进行process,对所有的输入数据都进行process。此处的process是我们自己定义的数据预处理函数
第三步:数据封装
class MyDataset(Dataset):def __init__(self, x, y):super().__init__()self.x = torch.FloatTensor(x).unsqueeze(1)self.y = torch.LongTensor(y)def __getitem__(self, idx):return self.x[idx], self.y[idx]def __len__(self):return len(self.y)train_dataset = MyDataset(x_train, y_train)test_dataset = MyDataset(x_test, y_test)
self.x = torch.FloatTensor(x).unsqueeze(1)
是因为,我们需要把输入的Float的numpy格式转化为Tensor格式。这里的unsqueeze(1)的目的是,扩充tensor的维度。额外置放一个维度用来填充输入序列的特征维度。
再封装成dataloader
## 再封装成dataloadertrain_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
第四步:搭建模型
class Dnn(nn.Module):def __init__(self):super().__init__()self.dnn = nn.Sequential(nn.Conv1d(1,8,33,1),nn.MaxPool1d(4),nn.Conv1d(8,16,33,1),nn.MaxPool1d(4),nn.Conv1d(16,32,31,1),nn.MaxPool1d(4),nn.Conv1d(32,64,19,1),nn.MaxPool1d(4),nn.Flatten(),nn.Linear(1600,512),nn.Linear(512,128),nn.Linear(128,3))def forward(self, x):out = self.dnn(x)return out
conv1d是1维卷积,采用卷积可以获取更大的感受野,这里设置kernel_size=33。之后的MaxPool1d(4)是池化层,目的是增大卷积的感受野,让模型可以更好的关注输入数据的上下文信息。
通过conv1d把输入数据的特征维度不断放大,最后再缩小,经过多个卷积层的处理,以提高模型的非线性拟合能力。
之后的Flatten是要把tensor压缩到1维,方便之后的全连接层运算。
经过计算后可以得出,此时输入全连接层的数据长度为1600。

第五步:模型训练
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')epochs = 200model = Dnn().to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.AdamW(model.parameters(), lr=0.001)scheduler=torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[60,100,150],gamma=0.5)for epoch in range(epochs):train_loss = 0train_acc_num = 0test_acc_num = 0model.train()for feature, label in train_loader:feature = feature.to(device)label = label.to(device)# label = label.squeeze()optimizer.zero_grad()preds = model(feature)loss = criterion(preds, label)loss.backward()optimizer.step()train_acc_num += (preds.argmax(1) == label).sum()train_loss += loss.item() / len(train_loader)model.eval()with torch.no_grad():for feature, label in test_loader:feature = feature.to(device)label = label.to(device)# label = label.squeeze()preds = model(feature)test_acc_num += (preds.argmax(1) == label).sum()train_acc = train_acc_num / len(train_loader.dataset)test_acc = test_acc_num / len(test_loader.dataset)print(f'Epoch:{epoch:3} | Train Loss:{train_loss:6.4f} | Train Acc:{train_acc:6.4f} | Test Acc:{test_acc:6.4f}')
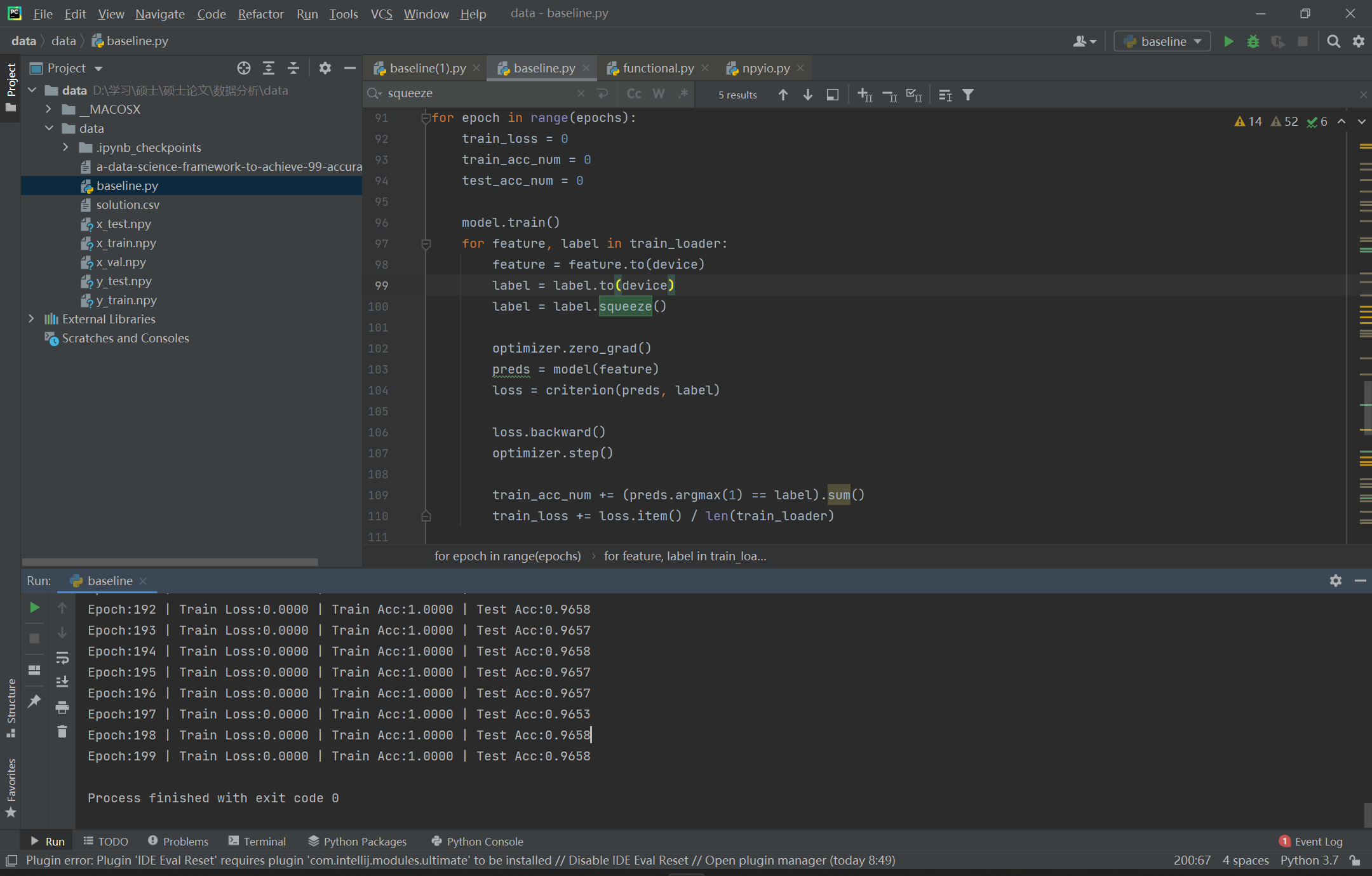
可以从图中看出,经过200个epoch的训练,训练精度达到了100%,测试精度达到了96%
第六步:生成提交数据

若有收获,就点个赞吧
0 人点赞
