From SRCNN to VDSR——the performance improvement of different structure.
Zudong Weng,2110436241,School of Electronic Information
Abstract
In the process of image acquisition, due to the environment, equipment, transmission, post-processing and other reasons, there are often different types and different degrees of degradation. Image enhancement algorithm mainly realizes adaptive quality recovery for degraded images, which is the main low-level computer vision task and plays an important role in digital camera, automatic driving and other important fields. This paper aims to introduce the basic process of super-resolution training by neural network, and make a comparative study of neural networks with different models and structures, and analyze the influence of the change of network structure on the performance of super-resolution of neural network. The differences among SRCNN, VDSR are analyzed.
1.INTRODUCTION
Image super-resolution (SR) is an important category of image processing technology in computer vision and image processing. It has a wide range of practical applications, such as medical imaging, surveillance and security, etc. In addition to improving image perception quality, it also helps improve other computer vision tasks In general, this problem is very challenging and ill-posed in nature, as there are always multiple HR images for one LR image.
Image super-resolution aims to recover a corresponding high resolution image from a low resolution image. Generally speaking, a low resolution image is the output of a high resolution image after a degraded model
where  denotes a degradation mapping function,
denotes a degradation mapping function, indicates the corresponding high resolution,
indicates the corresponding high resolution,  Is the parameter of the degenerate process.The research goal of the researchers is to recover an approximate image based on
Is the parameter of the degenerate process.The research goal of the researchers is to recover an approximate image based on  from
from  , which can be expressed by the following formula:
, which can be expressed by the following formula: 
Where  is the super-resolution model and
is the super-resolution model and  is the parameter of the model.
is the parameter of the model.
In most cases, the process of degradation is unknown, although the process of degradation is unknown and can be influenced by various factors (e.g., compression artifacts, anisotropic degradation, sensor noise, and speckle noise). Therefore, in the research, we generally take downsampling as the degradation model.
1.1 SUPERVISED SUPER-RESOLUTION
Now, researchers with deep learning super-resolution model is put forward these models focus on supervision of SR, which use the LR image and the corresponding HR training Although the difference between these models is very big, but they are essentially some combination of a set of components, such as network design model framework on sampling method and learning strategy From this perspective, the researchers combined these components to construct an integrated SR model for specific purposes. The upsampling of images as a partition can be divided into a pre-upsampling hyperpartition model and a post-upsampling hyperpartition model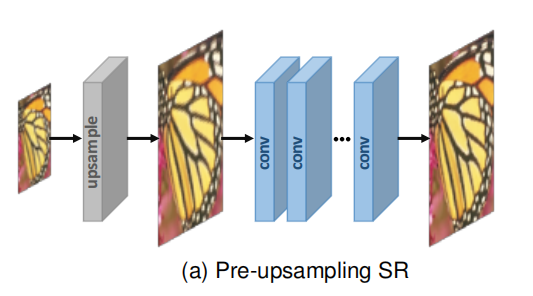
1.2 PRE-UPSAMPLING SR
Since the mapping from low-dimensional space to high-dimensional space is difficult to learn directly, it is a simple solution to obtain higher resolution images using traditional upsampling algorithm and then refine them using deep neural network. Therefore, Dong et al Firstly, pre-upsampling SR framework is adopted (as shown in Figure A), and SRCNN is proposed to learn end-to-end mapping from interpolated LR images to HR images. Specifically, traditional methods (such as bicubic interpolation) are used to upsample LR images to coarse HR images of desired size Since the most difficult up-sampling operation is completed,CNNs only needs to refine the rough image, greatly reducing the learning difficulty.
1.3 POST-UPSAMPLING SR
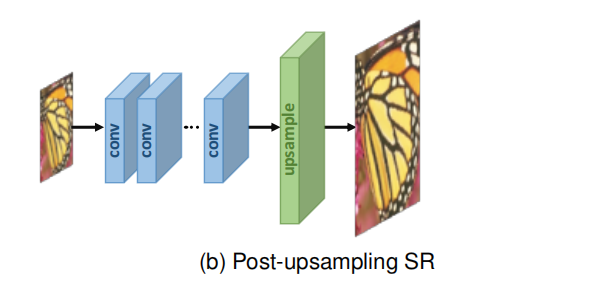
In order to improve computational efficiency and make full use of deep learning technology to automatically improve resolution, the researchers propose to integrate end-to-end learnable layers at the end of the model, replacing predefined up-sampling and performing most of the computation in low-dimensional space In the pioneering work of this framework, namely SR after upsampling, as shown in Figure (b),LR input images were fed into deep CNN without increasing resolution, and an end-to-end learnable upsampling layer was applied at the end of the network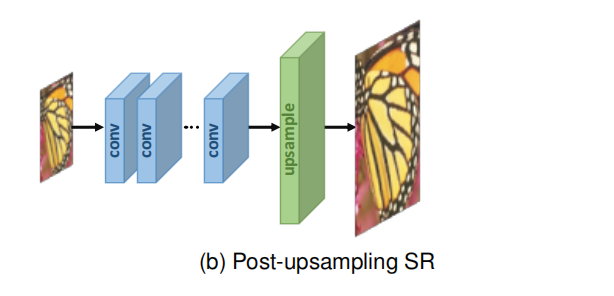
1.4 UPSAMPLING METHODS
In the current superpartition network model architecture, the common upsampling method is mostly based on interpolation upsampling method. Image interpolation, also known as image scaling, refers to adjusting the size of a digital image, which is widely used in image-related applications. Traditional interpolation methods include nearest neighbor interpolation, bilinear interpolation and biccubic interpolation, Sinc and Lanczos resampling, and so on. Because these methods are easy to interpret and implement, some of them are still widely used in CNN-based SR models.
Nearest neighbor interpolation
Nearest neighbor interpolation is a simple and intuitive algorithm. It selects the nearest pixel value for each position to interpolate, regardless of any other pixels. As a result, this method is very fast, but usually produces low-quality blocky results.
Bilinear interpolation
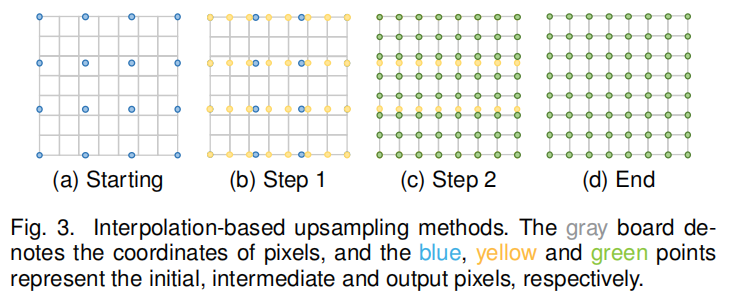
Bilinear interpolation (BLI) first performs linear interpolation on one axis of the image, and then on the other axis, as shown in FIG. 3. Because it produces a quadratic interpolation with a 2 × 2 receiver domain, it shows better performance than nearest neighbor interpolation while maintaining relatively fast speed.
Bicubic interpolation
Similarly, bicubic interpolation (BCI) performs cubic interpolation on both axes, as shown in Figure 3. Compared to BLI, BCI needs to allow for 4 × 4 pixels, resulting in smoother artifacts, but lower speeds. In fact, BCI with anti-aliasing is currently the mainstream SR data set construction method (i.e. HR image degradation to LR image), and is also widely used in pre-sampling SR framework.
2. MODEL ANALYSIS
2.1 SRCNN
A deep learning method for single image super-resolution is proposed. SRCNN directly learns end-to-end mapping between low/high resolution images. This mapping is represented as a deep convolutional neural network (CNN) that outputs high resolution images with low resolution images as input.
(Figure 2-1 SRCNN network structure)
SRCNN consists of three convolutional layers. We can divide the network structure of SRCNN into three main parts.
1. Extraction and representation of Patch. 2. Nonlinear mapping. 3. The refactoring.
The first layer uses a 9x9 convolution kernel, the second layer uses a 5x5 convolution kernel, and the third layer also uses a 5x5 convolution kernel.
2.2 VDSR
VDSR proposes a high precision single image super resolution (SR) method. VDSR uses a very deep convolutional network, inspired by VGG-NET for ImageNet classification. The authors found that increasing the depth of the network significantly improved accuracy. The final model of VDSR uses 20 convolution layers. Context information of large image area can be efficiently utilized by cascading small filters in deep network structure. However, for very deep networks, convergence rate becomes a key problem in the training process. VDSR proposes a simple and effective training program.
(Figure 2-3 VDSR network structure)
VDSR uses the same network structure except for the first and last layers, with 64 filters and each is 3x3x64.
The main convolution part of VDSR refers to the design idea of VGG-NET. VGGNet uses 33 convolution kernel and 22 pooled kernel to improve performance through deepening network structure. The increase in the number of network layers does not result in an explosion in the number of parameters, because the number of parameters is concentrated in the last three fully connected layers. Meanwhile, the series of two 33 convolution layers is equivalent to a 55 convolution layer, and the series of three 33 convolution layers is equivalent to a 77 convolution layer, that is, the size of the receptive field of three 33 convolution layers is equivalent to a 77 convolution layer. However, the number of three 33 convolutional layers is only about half of that of 77. Meanwhile, the former can have three nonlinear operations while the latter only has one, which makes the former better able to learn features.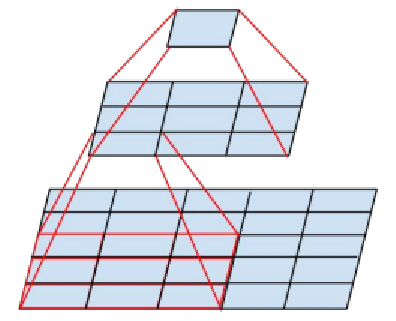
(Figure 2-4 VGG-NET diagram)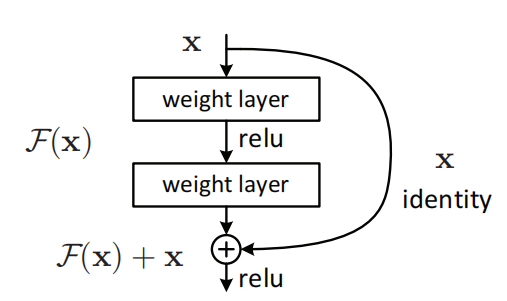
(Figure 2-6 Schematic diagram of residual structure)
The first layer of the VDSR is used to process the input of the image, and the last layer of the VDSR is used to achieve the reconstruction of the image containing a single filter of 3x3X64 structure. The network takes an interpolated low-resolution image (to the desired size) as input and predicts image details. VDSR preprocessing the input image is the same as SRCNN.
2.3 The IMPROVEMENT OF VDSR OVER SRCNN
Although SRCNN has successfully introduced deep learning technology into super-resolution (SR) problems, we find its limitations in three aspects: first, it depends on the context of small image areas; Second, training convergence is too slow; Third, the network only works on a single scale.
Due to the shallow network depth of SRCNN, the sensibility field of THE convolution of SRCNN is small and cannot capture the image context information of a large area, resulting in unsatisfactory effect of SRCNN in hyperfractional recovery. SRCNN does not use residual network structure, so it cannot adopt a large learning rate during training, resulting in low learning efficiency.
VDSR puts forward some new methods to solve these problems
1. Deeper networks use larger receptive fields to obtain image context information. The author uses the deep convolutional network based on VGG-NET. The use of smaller convolutional kernel and deeper network can increase the nonlinear capability of the network and ultimately improve the performance of the network.
2. The network adopts residual-learning CNN and uses a very high learning rate to improve the speed of Convergence. Using large learning rate, it is easy to meet the problems of vanishing gradient and exploding gradient. Here, residual learning and adjustable gradient clipping technology are used to suppress the generation of gradient problem.
3. A single neural network can perform image super-resolution reconstruction based on different Scale factors
After VDSR adopts the method of residual learning, the learning rate is improved so that the time of network training is greatly reduced, and the deeper network structure also improves the test accuracy of the network.
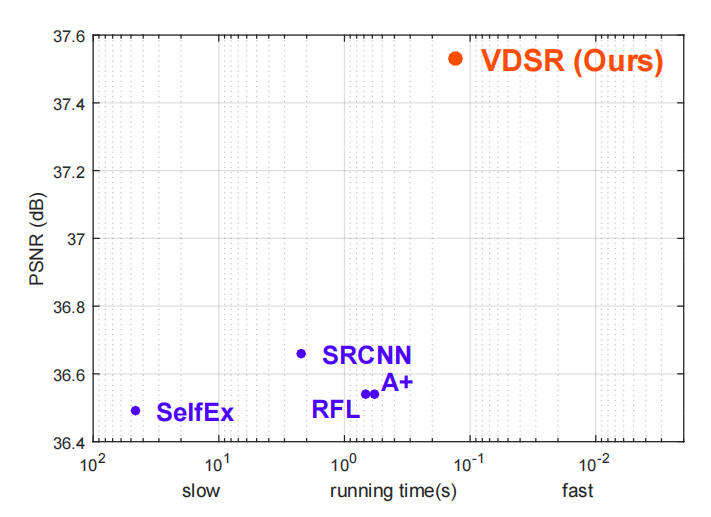
(Figure 2-9 VDSR improvement over SRCNN)
3. EXPERIMENT
3.1 DATA PRE-PROCESSING
The data preprocessing modules of SRCNN and VDSR are the same. SRCNN and VDSR both belong to the pre-sampling super-resolution. Firstly, the image is up-sampled by the traditional bicubic interpolation algorithm, and then the up-sampled image is input into the neural network for an end-to-end training.
As the input data, length and width are different, and may not be an integer multiple of the superpartition coefficient. So we also need to preprocess the input image first.
The input image can be exactly in accordance with the superpartition coefficient of the corresponding downsampling operation.
For image preprocessing, down-sampling of input high-resolution images is required first to obtain corresponding low-resolution images. However, since the neural network is an end-to-end learning process, up-sampling amplification of low-resolution images after down-sampling is also required. So that the size of the image input into the neural network is the same as the size of the high-resolution image we want to get.
3.2 Deeper gets Better
In SR tasks, the VGG-NET structure can be used to infer the contextual information of high-frequency components corresponding to each other. A larger receptive field means that the network can use more background to predict image details. As SR is an ill-posed problem, collect and analyze more neighboring points can get more clues. For example, if there are some image patterns that are completely contained in the receptive field, then this pattern may be recognized and used for super-resolution of the image.
In addition, very deep networks can take advantage of high nonlinearity. Using 19 modified linear units, VDSR networks can model very complex functions with an appropriate number of channels (neurons).
We have now experimentally shown that very deep networks significantly improve SR performance. We train and test networks with depths ranging from 5 to 20 (counting only weighted layers, not including nonlinear layers). In Figure 3-1, we show the results. In most cases, performance increases with depth. As depth increases, performance improves rapidly.
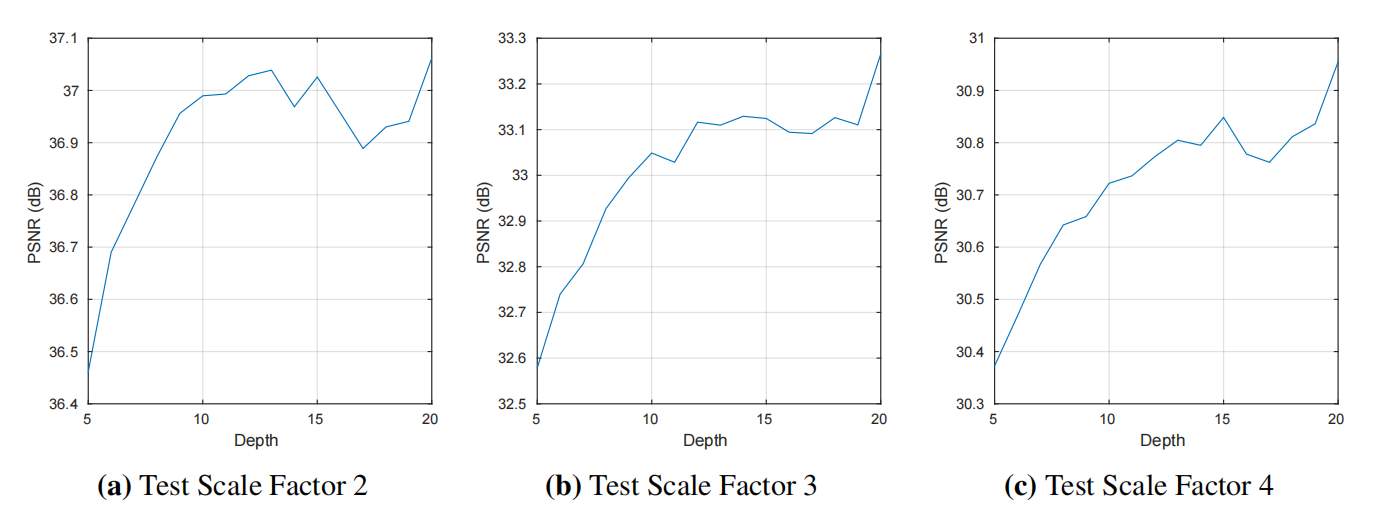
(Figure 3-1 Depth vs Performance)
3.3 HIGH LEARNING RATE OF DEEP NETWORK
Training depth models may not converge within realistic time limits. SRCNN performs poorly at more than three layers of weight. While there could be various reasons, one possibility is that they stopped the training process before the network converged, increasing the depth to 20 doesn’t seem practical for SRCNN. Improving learning efficiency is the basic principle of improving training efficiency. But simply setting the learning rate too high can cause a fade/burst. For this reason, we recommend an adjustable gradient clip to maximize speed while suppressing explosion gradients.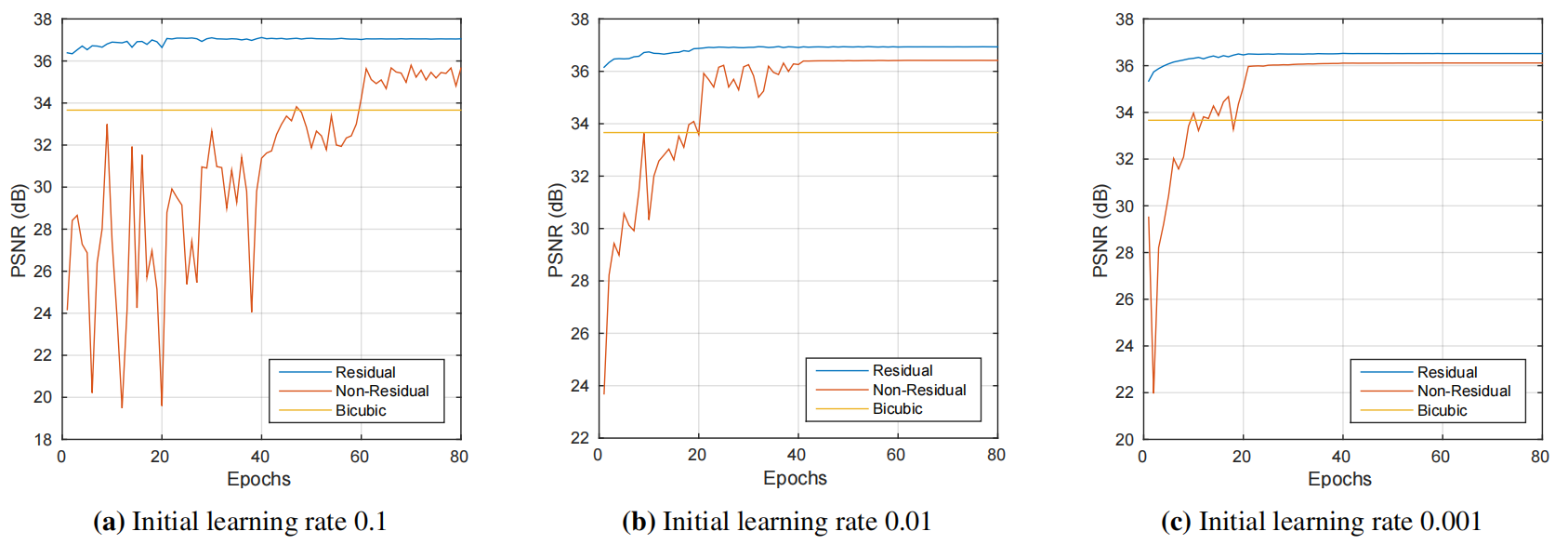
3.4 RESULTS



(Figure 3-2 Ground Truth) (Figure 3-3 SRCNN) (Figure 3-4 VDSR)
The PSNR of SRCNN was 25.93
The PSNR of VDSR was 26.94
4.CONCLUSION
VDSR proposes a super-resolution method using extremely deep networks. Training a very deep network is difficult because of slow convergence. We use residual learning and extremely high learning rates to quickly optimize a very deep network. By using deeper neural networks with smaller convolution kernels, the network can have better nonlinear ability and larger receptive field, thus greatly improving the performance of the network.
REFERENCE
[1] C. Dong, C. C. Loy, K. He and X. Tang, “Image Super-Resolution Using Deep Convolutional Networks,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 295-307, 1 Feb. 2016, doi: 10.1109/TPAMI.2015.2439281.
[2] J. Kim, J. K. Lee and K. M. Lee, “Accurate Image Super-Resolution Using Very Deep Convolutional Networks,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1646-1654, doi: 10.1109/CVPR.2016.182.
[3] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[4] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR, 2015: 448-456.
[5] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011: 315-323.
[6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[7] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.

若有收获,就点个赞吧
0 人点赞
