1.不同模型的比较
如何定量的评估两个模型之间的差异,这是一件比较困难的事情。
我们用交叉熵,就可以比较不同模型之间的差异。
对不同的模型都用熵来进行量化。
如果两个模型不是同一种模型,这样的话,就没有办法公度了。
把公度问题解决的最好的,是我们熟悉的货币体系。
不论是什么东西,在什么样的价值体系内,我们只要把它放到货币体系内,它就可以变成一串数字,衡量出来。
人脑里面是一个概率模型,神经网络里面也是一个概率模型,所以我们可以用熵来作为概率模型的公度。
2.定义符
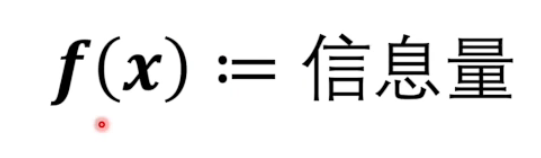
这个符号代表了,后面的式子对前面的式子进行定义。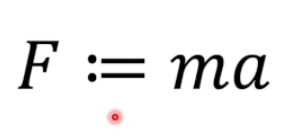
这是牛顿对力的定义,牛顿可以这么写也可以不这么写。这是定义。
力不是恰恰等于,质量乘以加速度,而是,力是由质量和加速度定义出来的。
力更像是牛顿的发明。
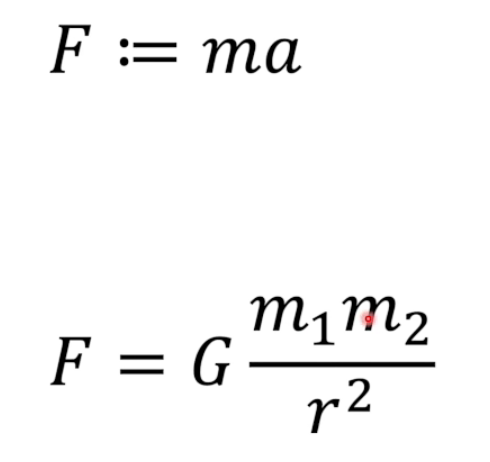
力是发明的,万有引力是发明的。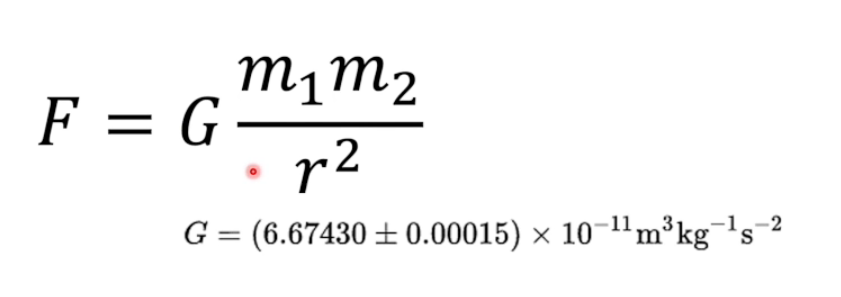
我们可以发现,F=ma是非常巧合相等的,但是万有引力的系数确是非常复杂的。这是因为牛顿把力定义为质量乘以加速度。为了整个力学体系能够自洽,牛顿只能去配凑万有引力的系数。
同样的,我们也可以定义万有引力,然后去找到一个惯性系数。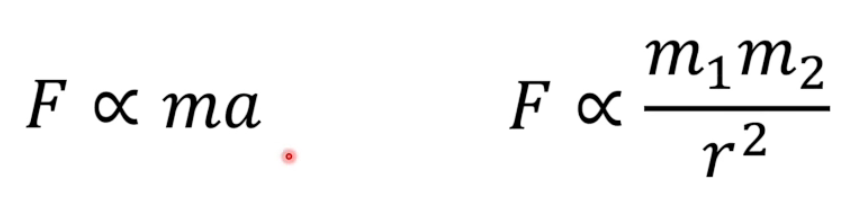
我们知道是有正相关的关系,就看力学体系是以哪个力为基础了。
怎么定义无所谓,关键是要体系能够自洽。
3.信息量
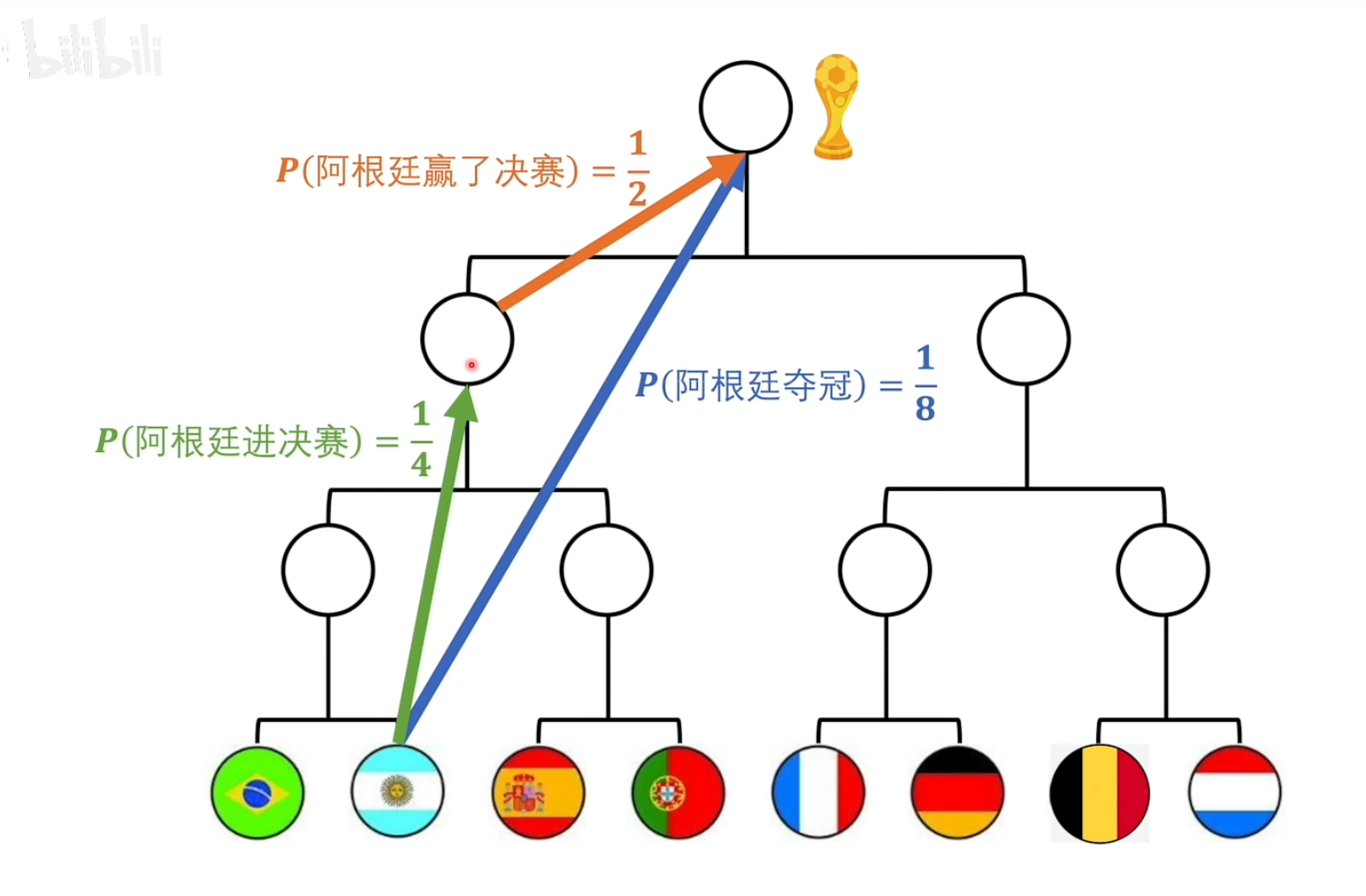
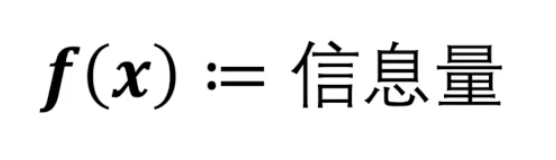

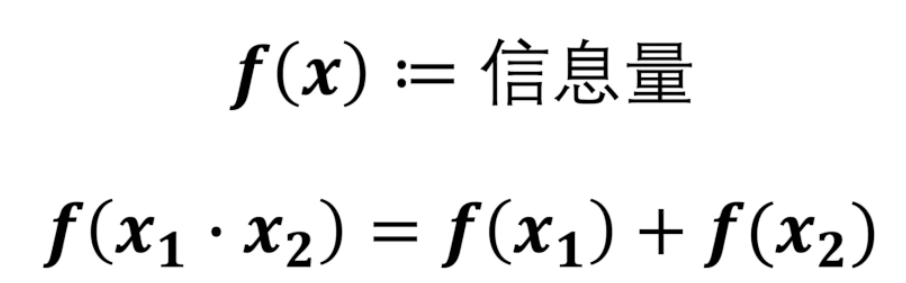
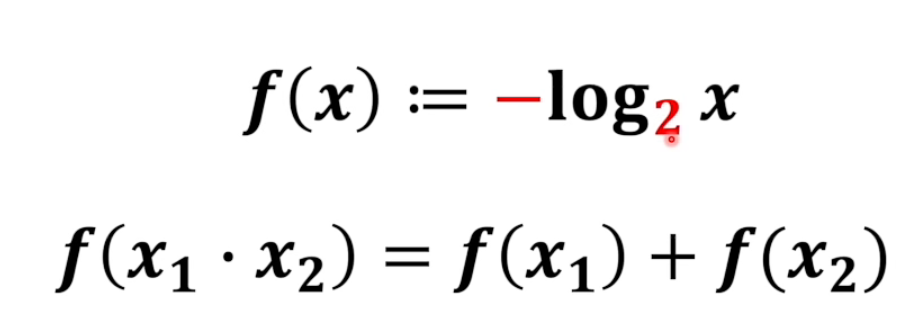
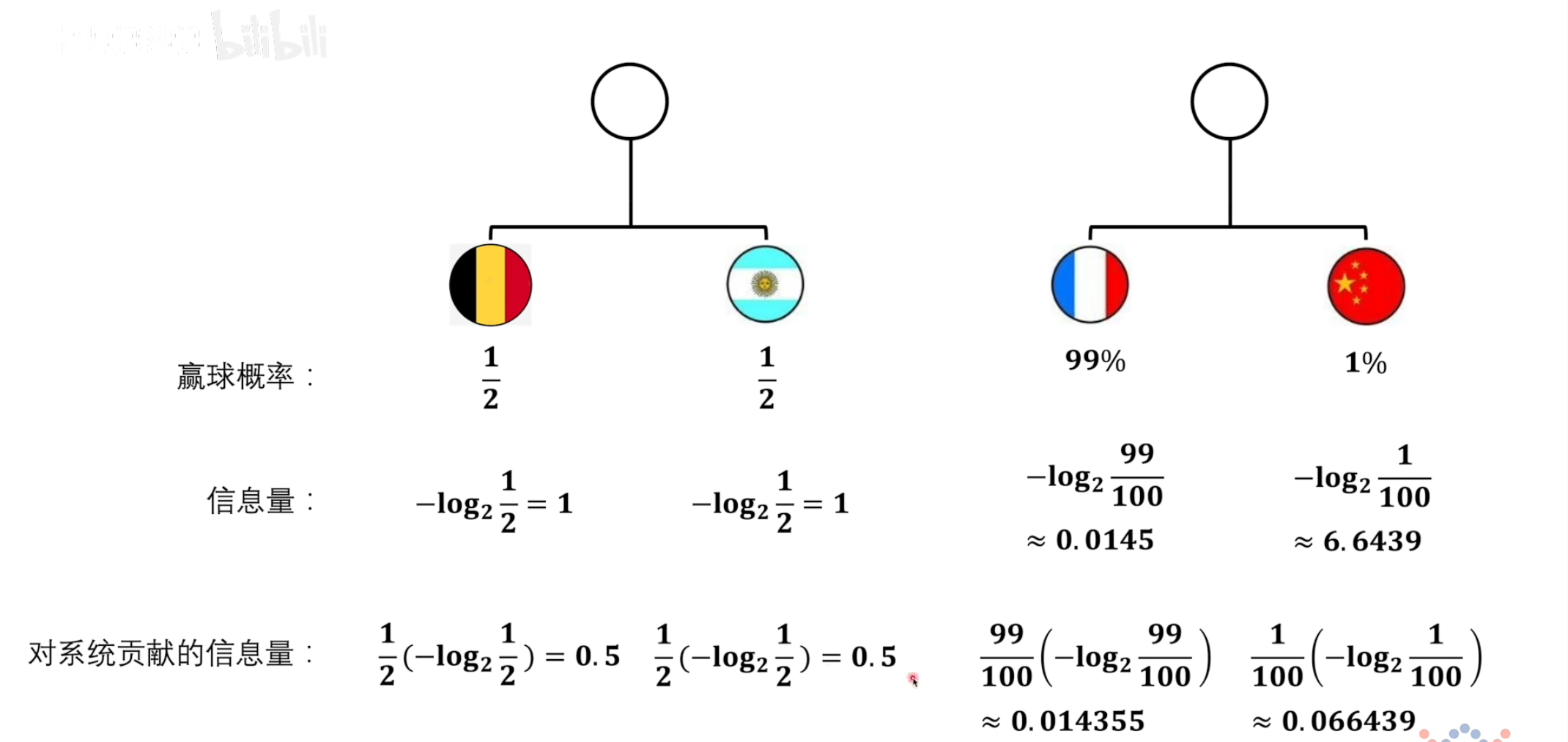
以2为底是相当于抛硬币模型的。
比如说阿根廷夺冠的概率是1/8,就相当于抛3个硬币全部朝上的概率。
以2为底的信息量是有单位的,bit。
这里在计算机中也很好理解,计算机中的单位也是bit。
比如说,我们有16位的存储空间需要存储,现在我们存入了xxxx xxxx xxxx xxxx,在我们输入之前,计算机有16个0 1可以取值。所以有2^16种可能性。现在我们输入了一个特定的值,故可能性收缩到1种,所以信息量为16bit。
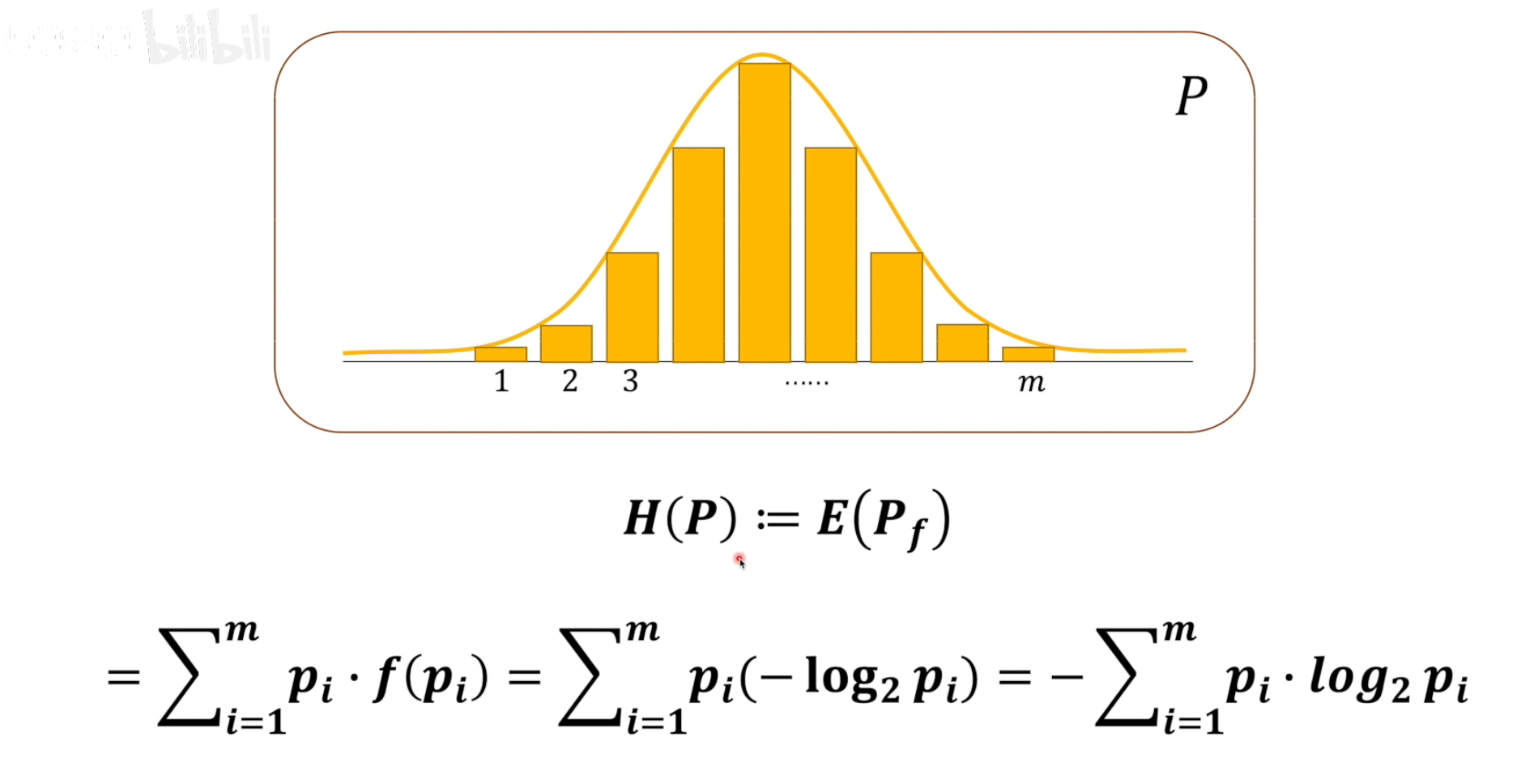
4.熵
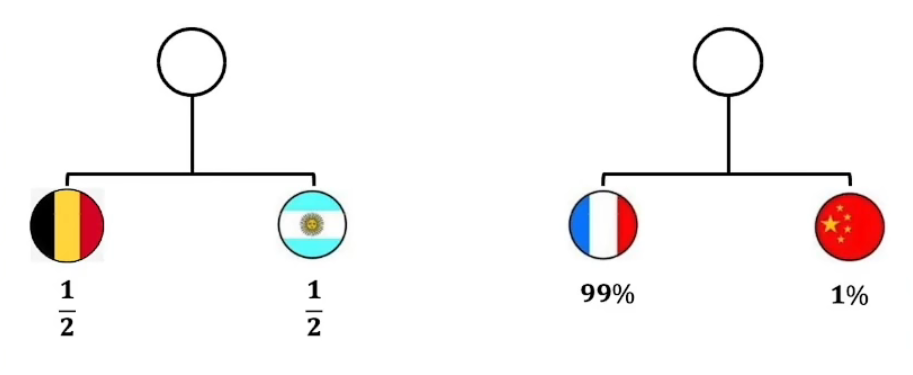
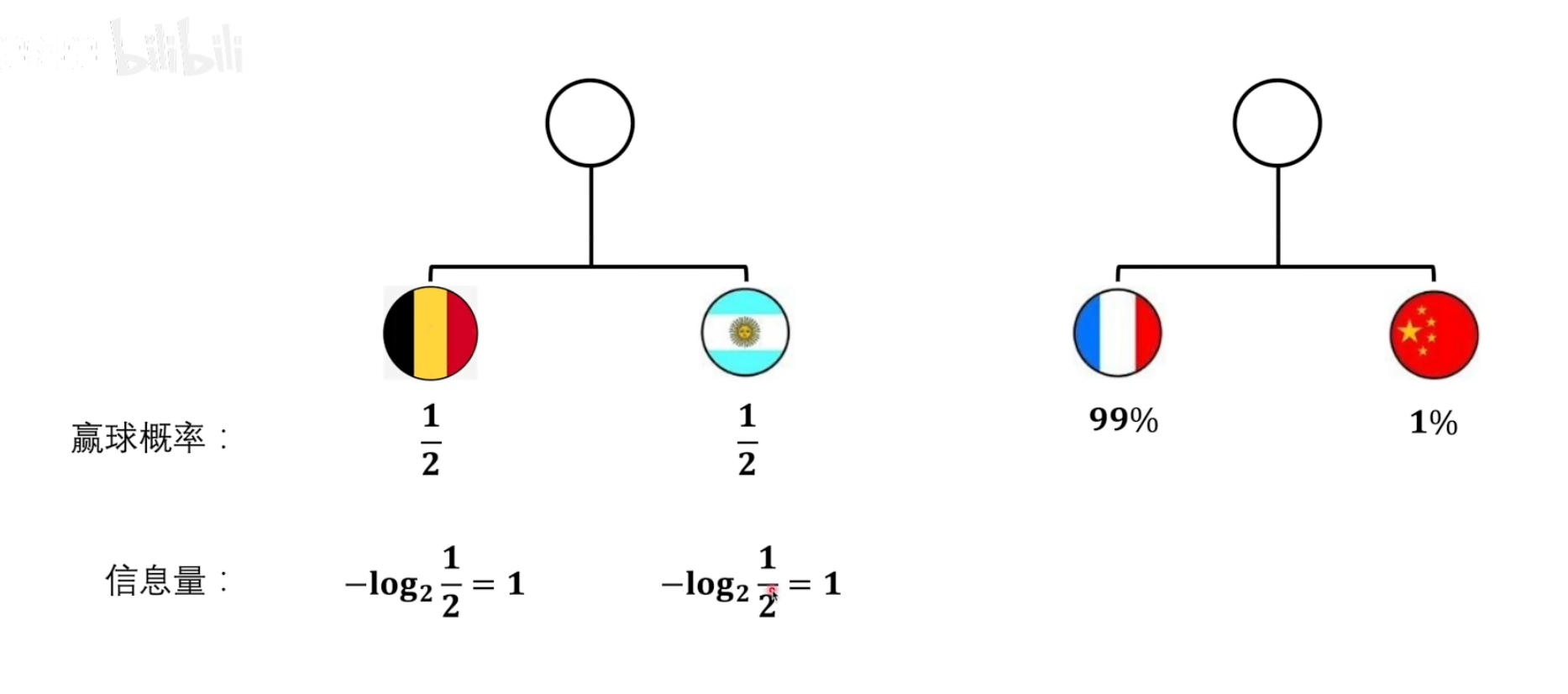
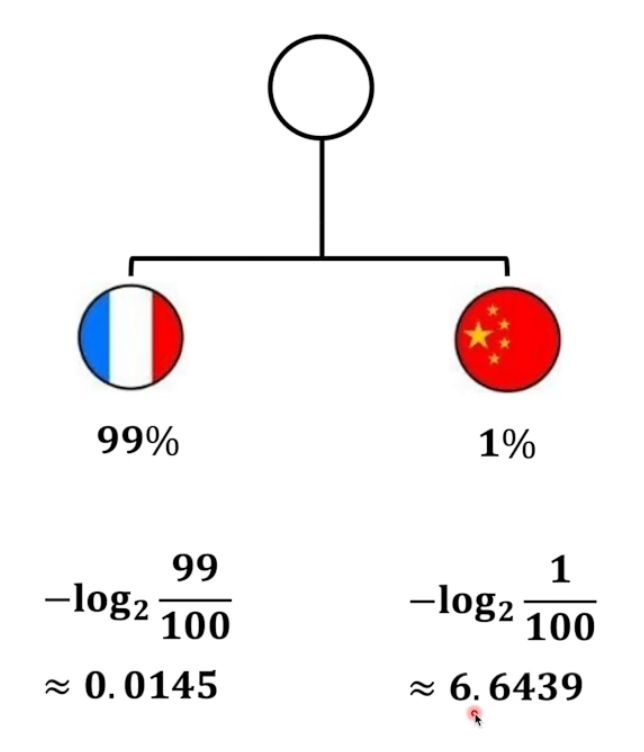
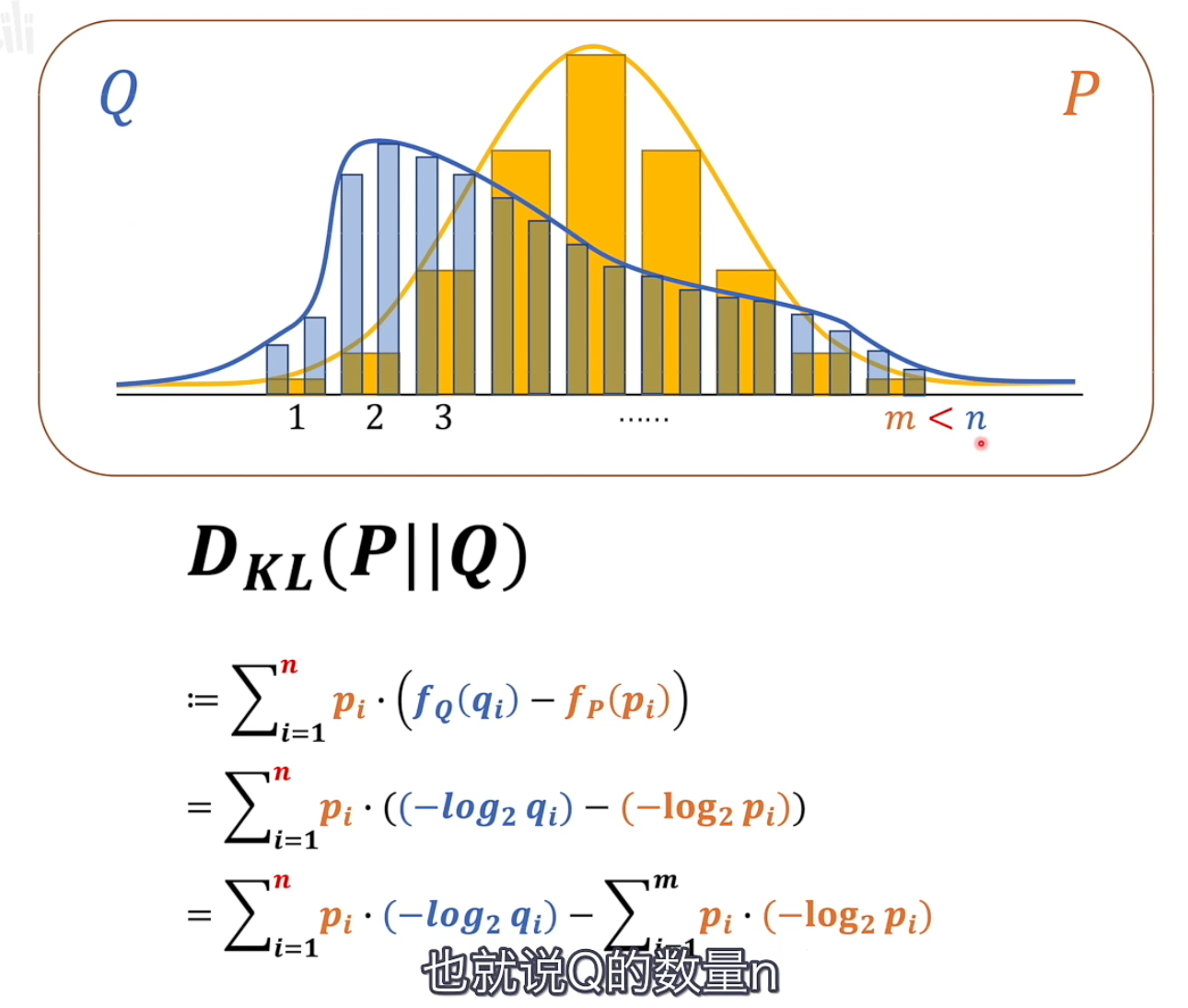
5.相对熵——KL散度


若有收获,就点个赞吧
0 人点赞
