https://blog.csdn.net/qq_41140449/article/details/123325471
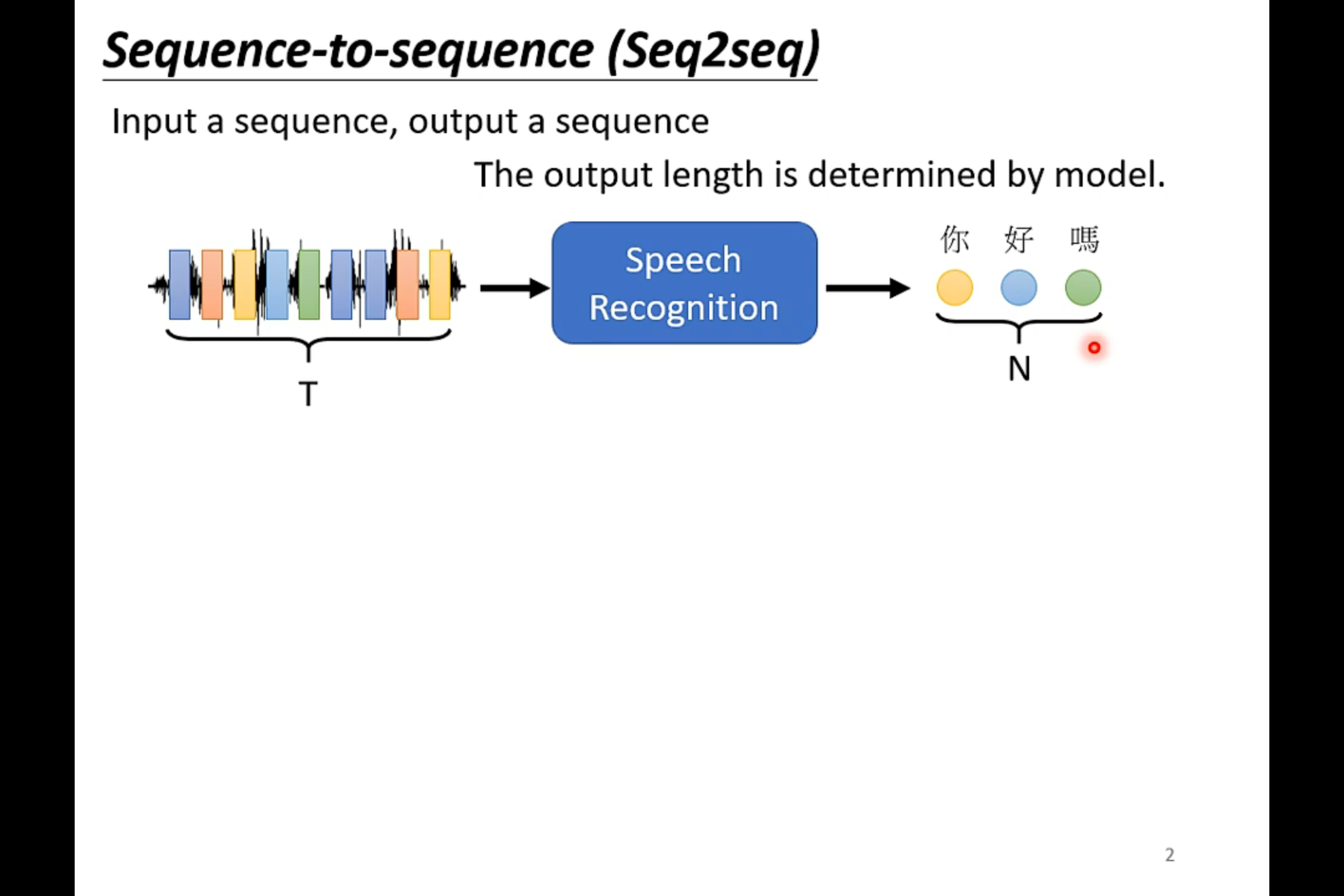
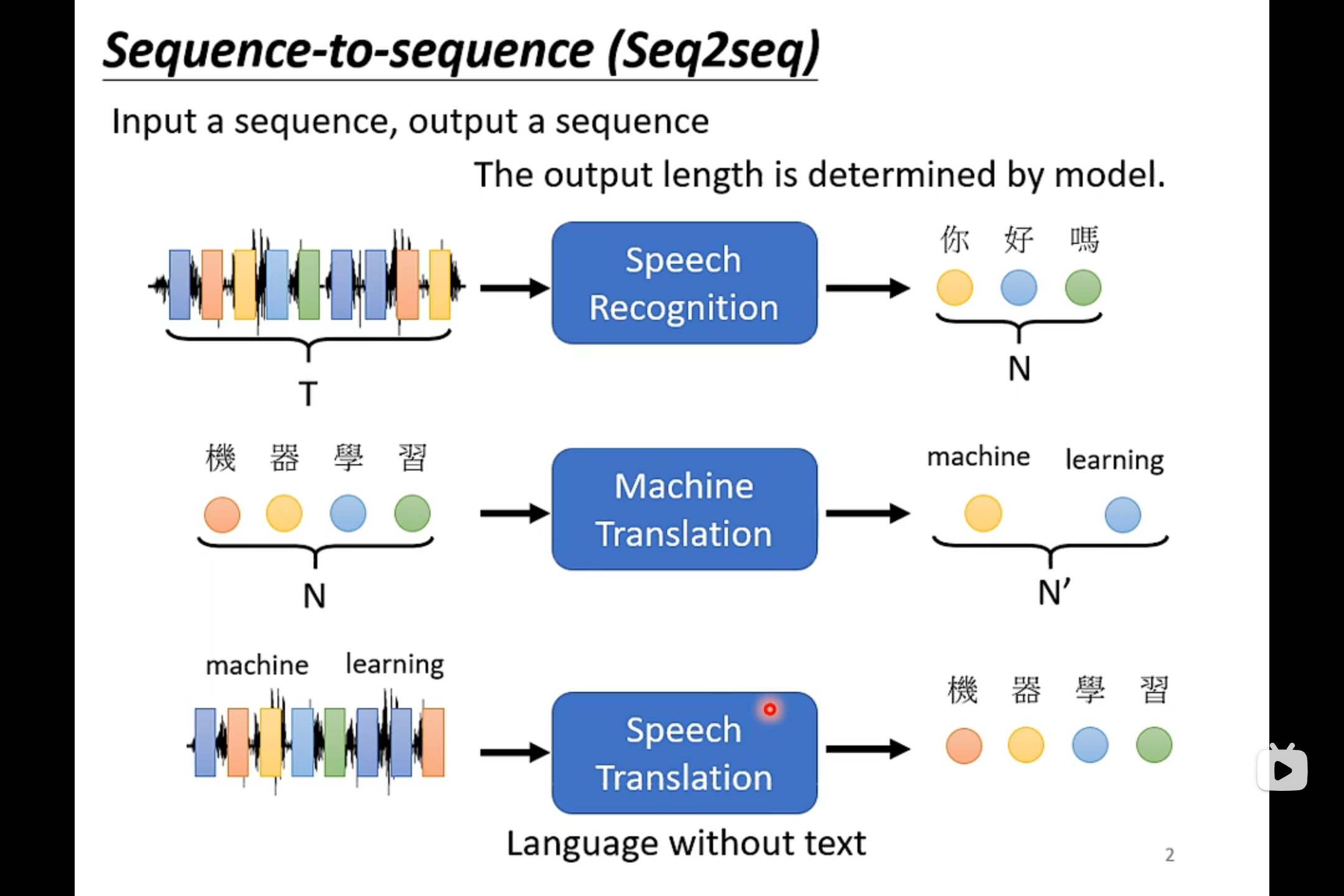

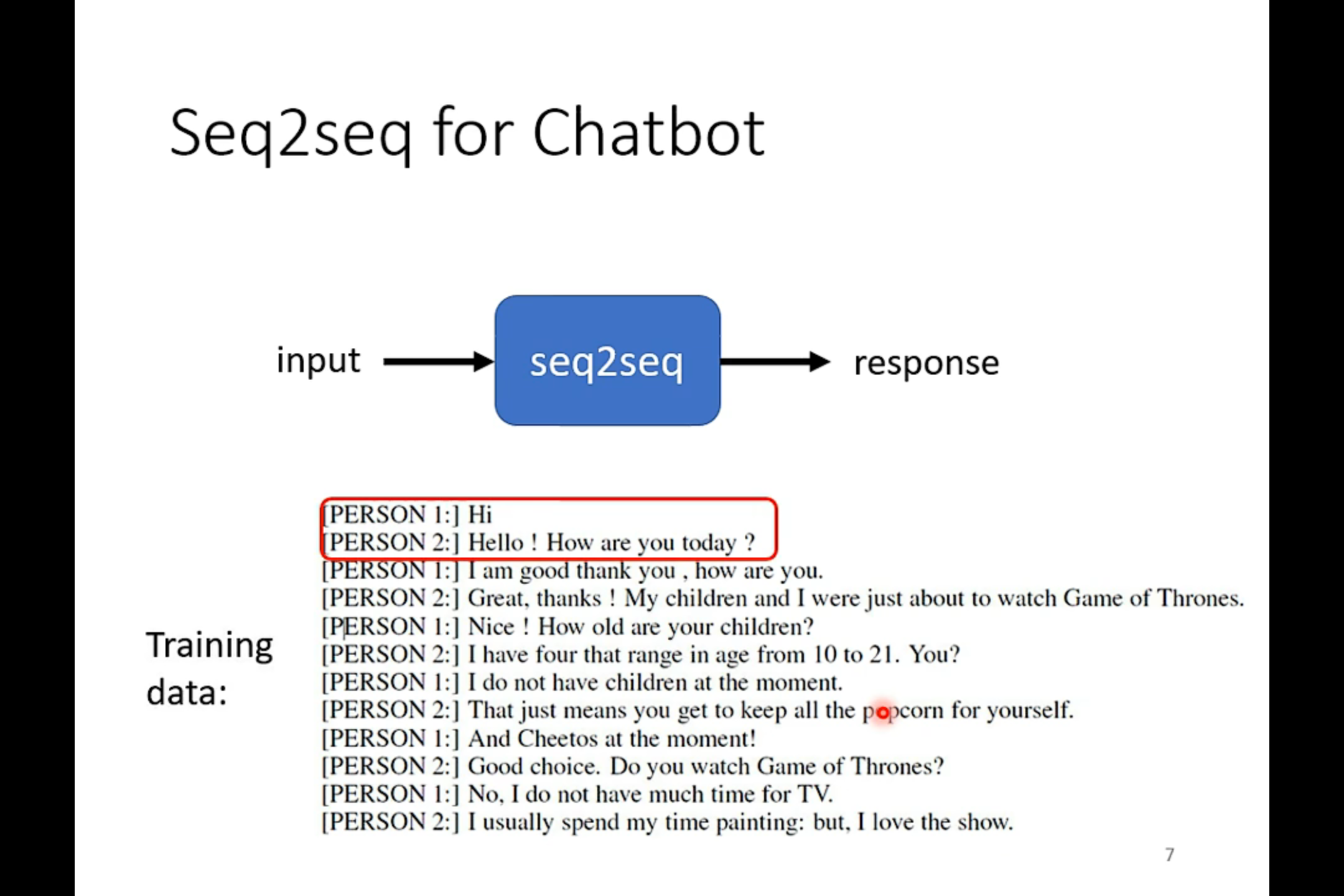
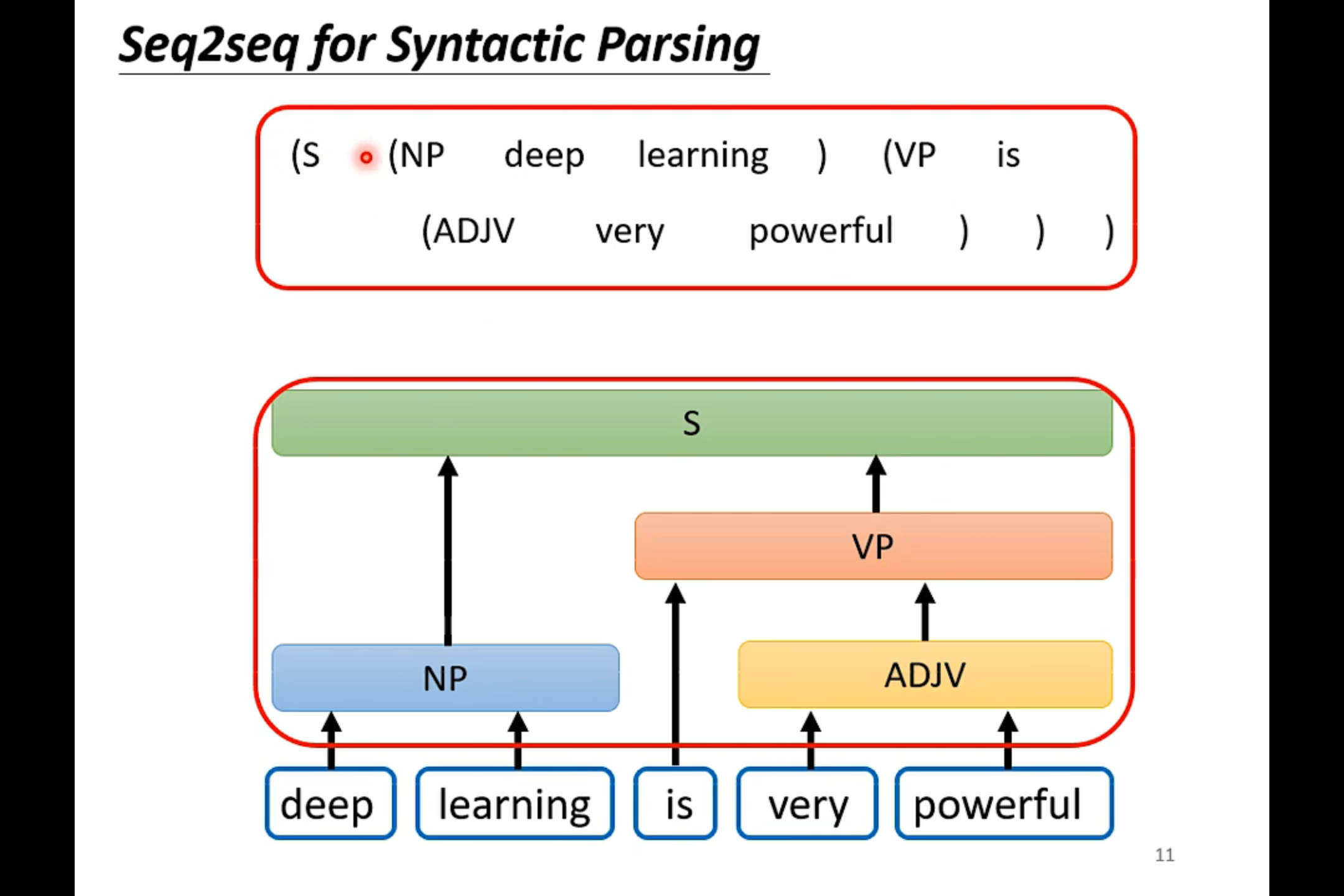
在文字上的sequence to sequence的应用

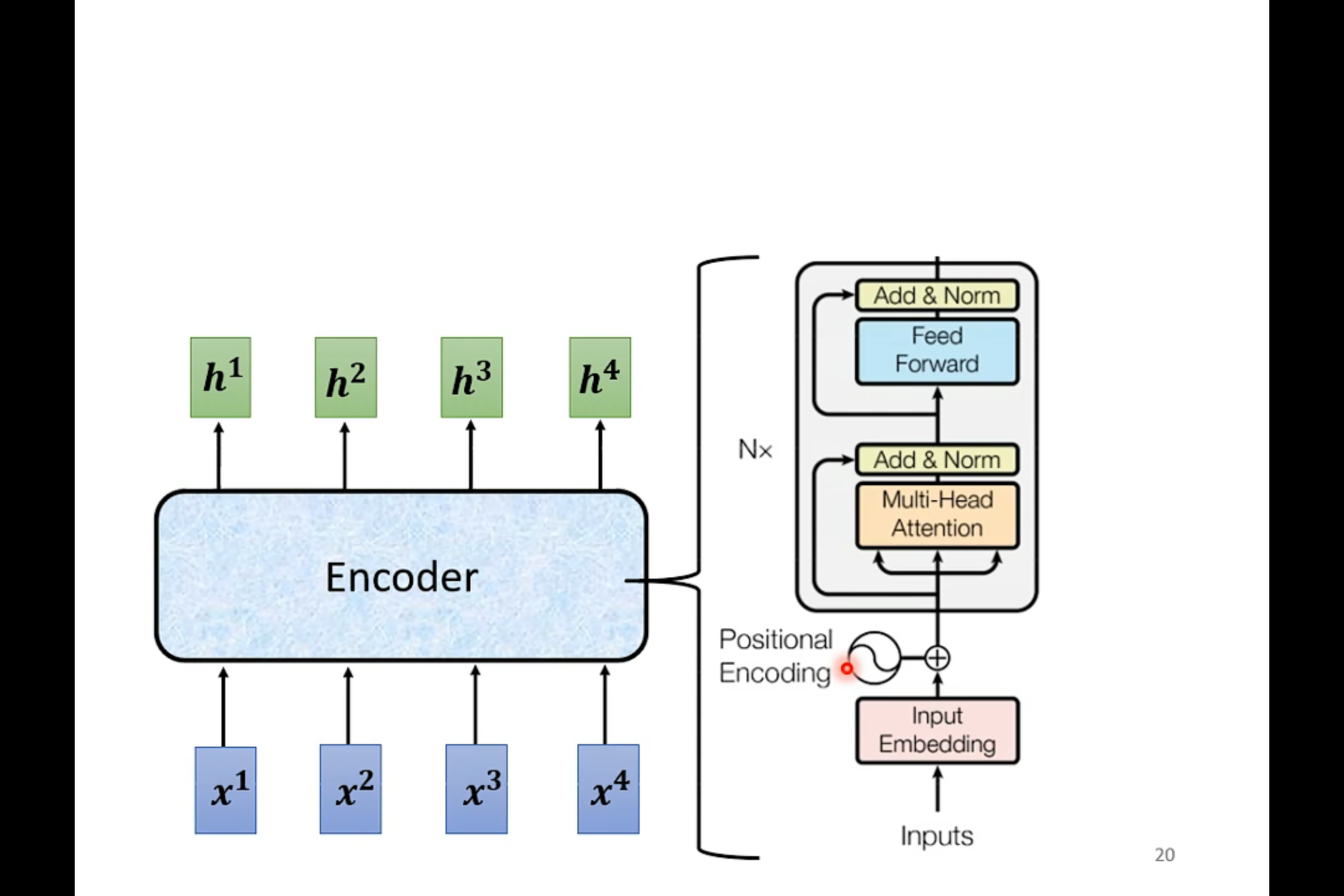
Encoder


Encoder用的就是Self-attention
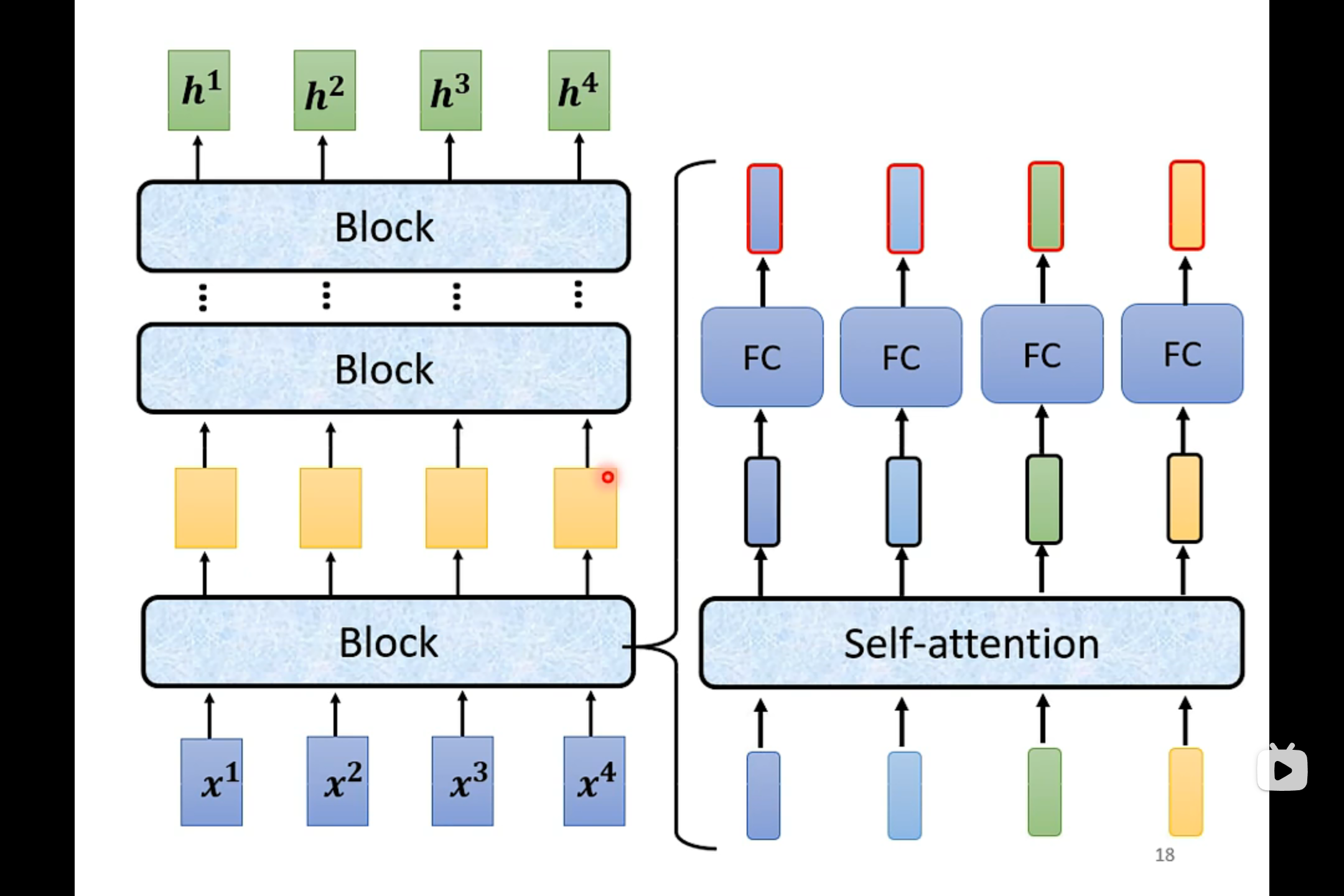
在transformer中加入了Residual的设计

这里的self-attention加入了residual connection和layer norm
经过residual connection和layer norm之后的输出才进入到Full Collection里面。


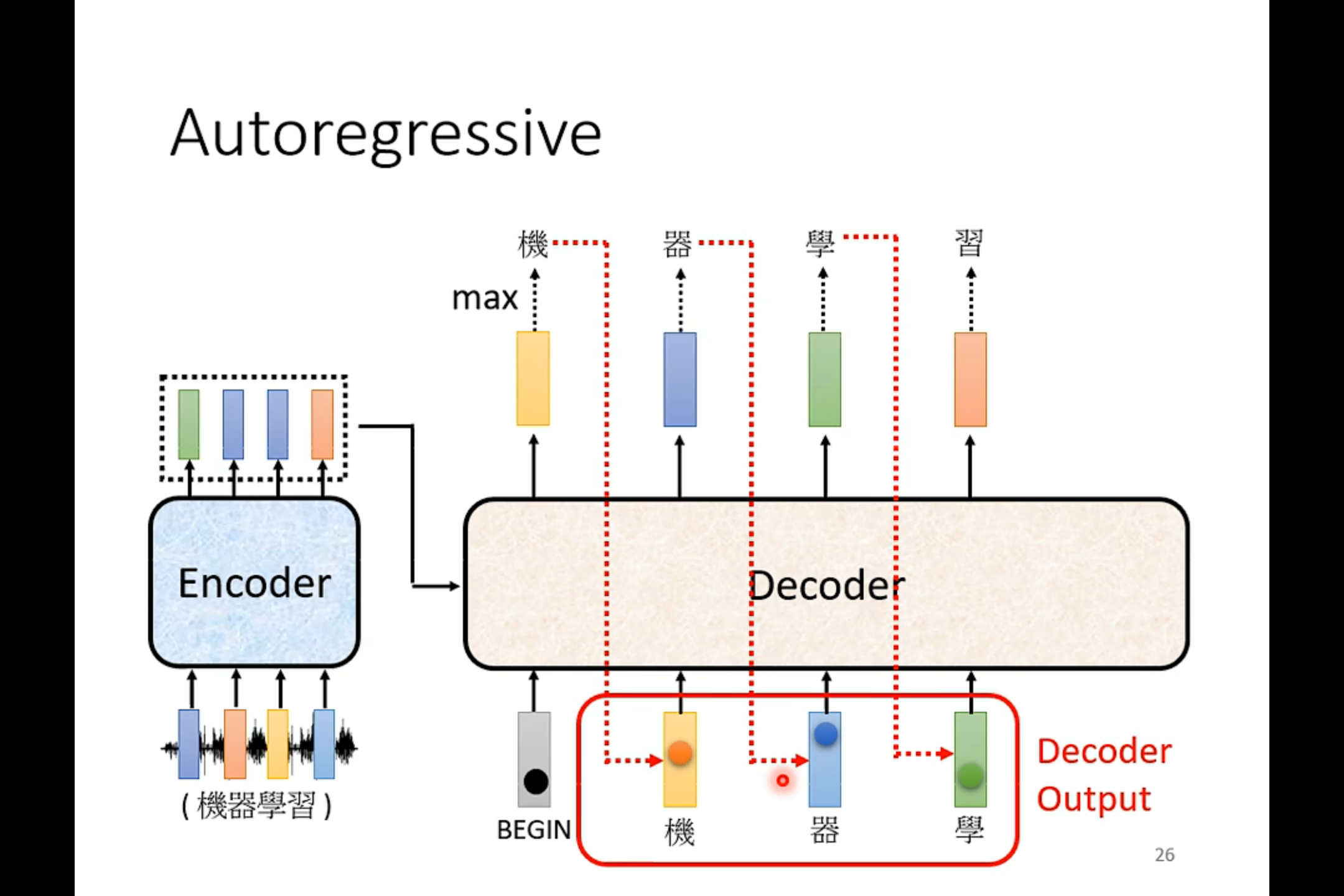
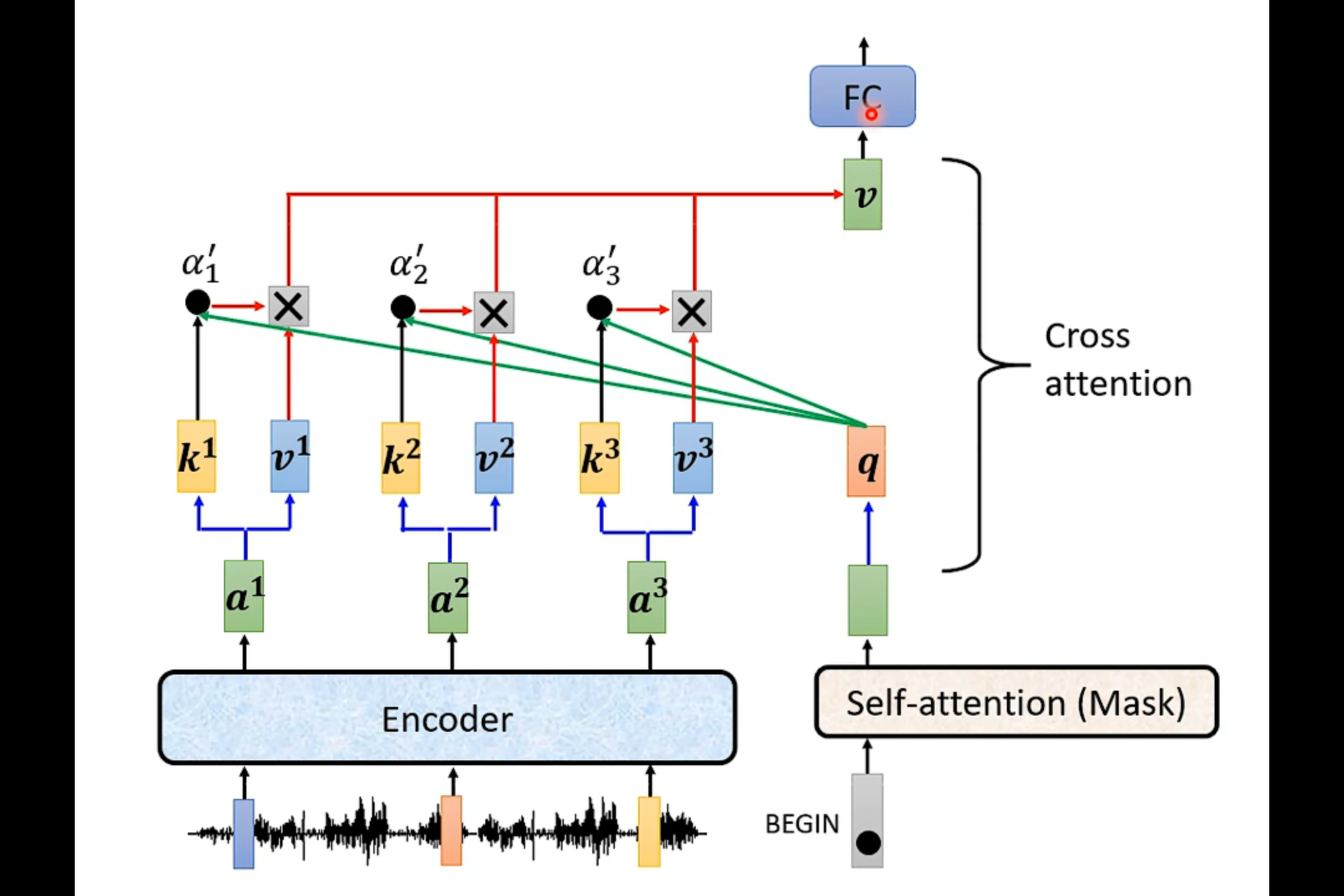
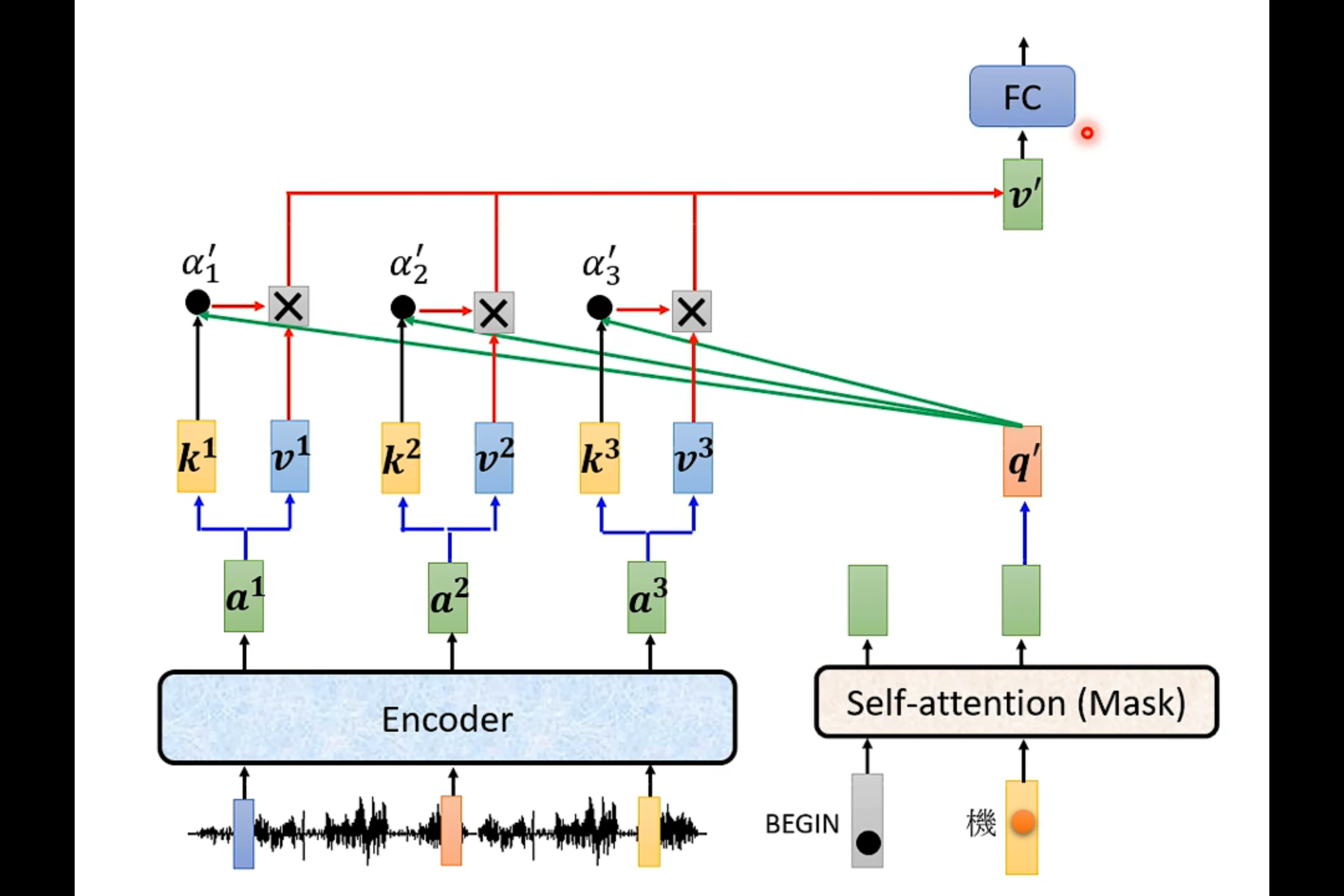
Decoder
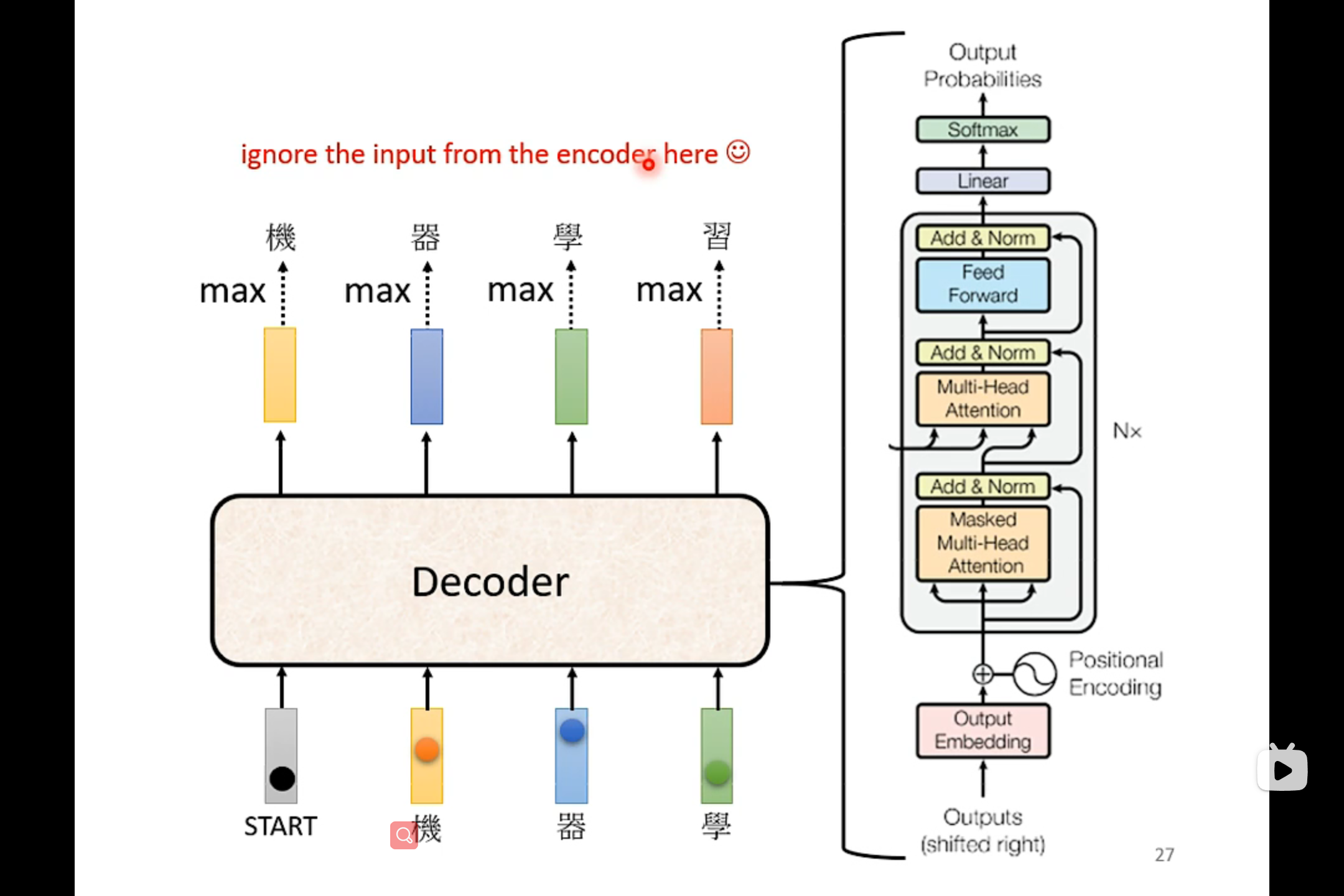
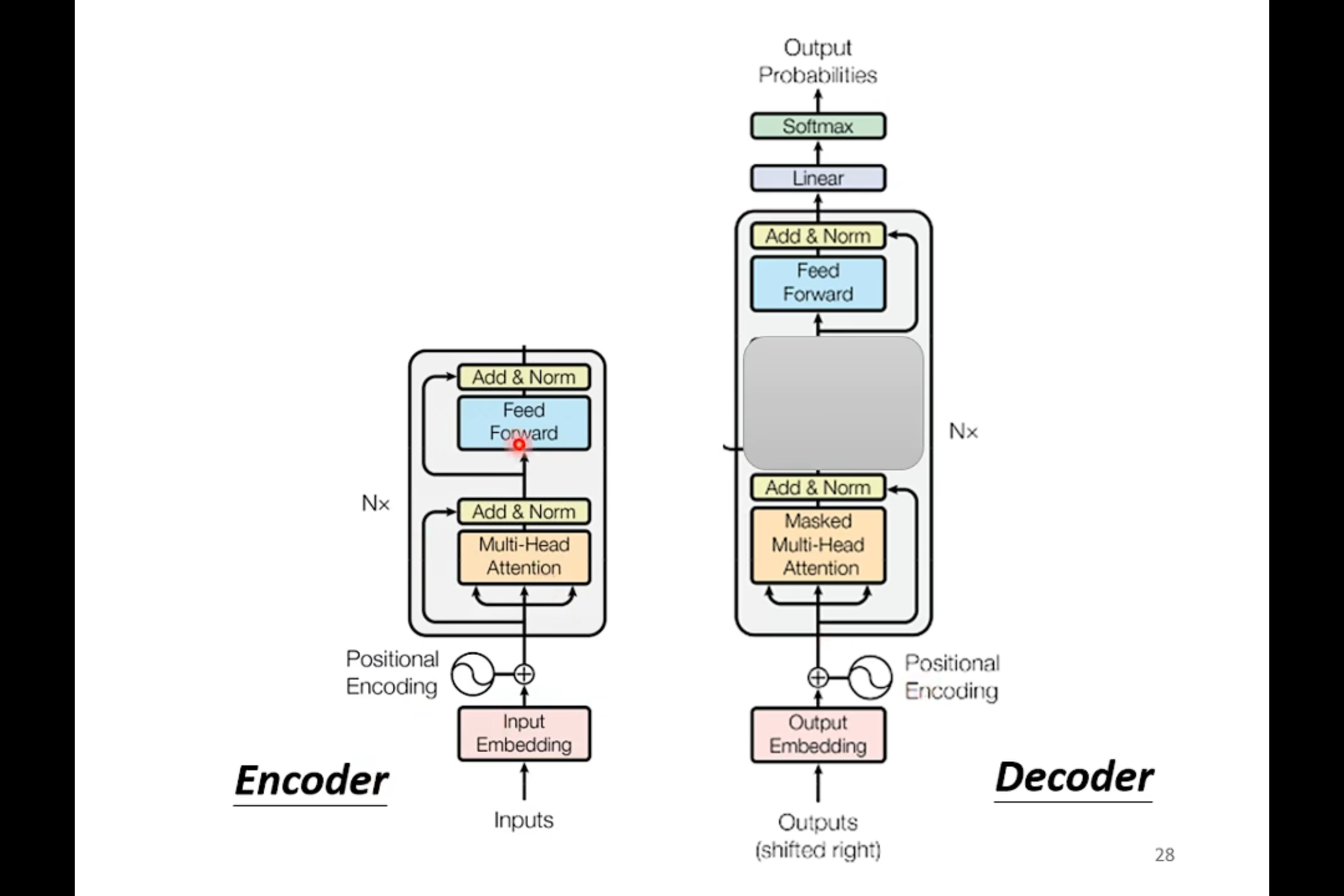
如果把decoder中间的那一块遮起来,我们会发现encoder和decoder并没有太大的区别。
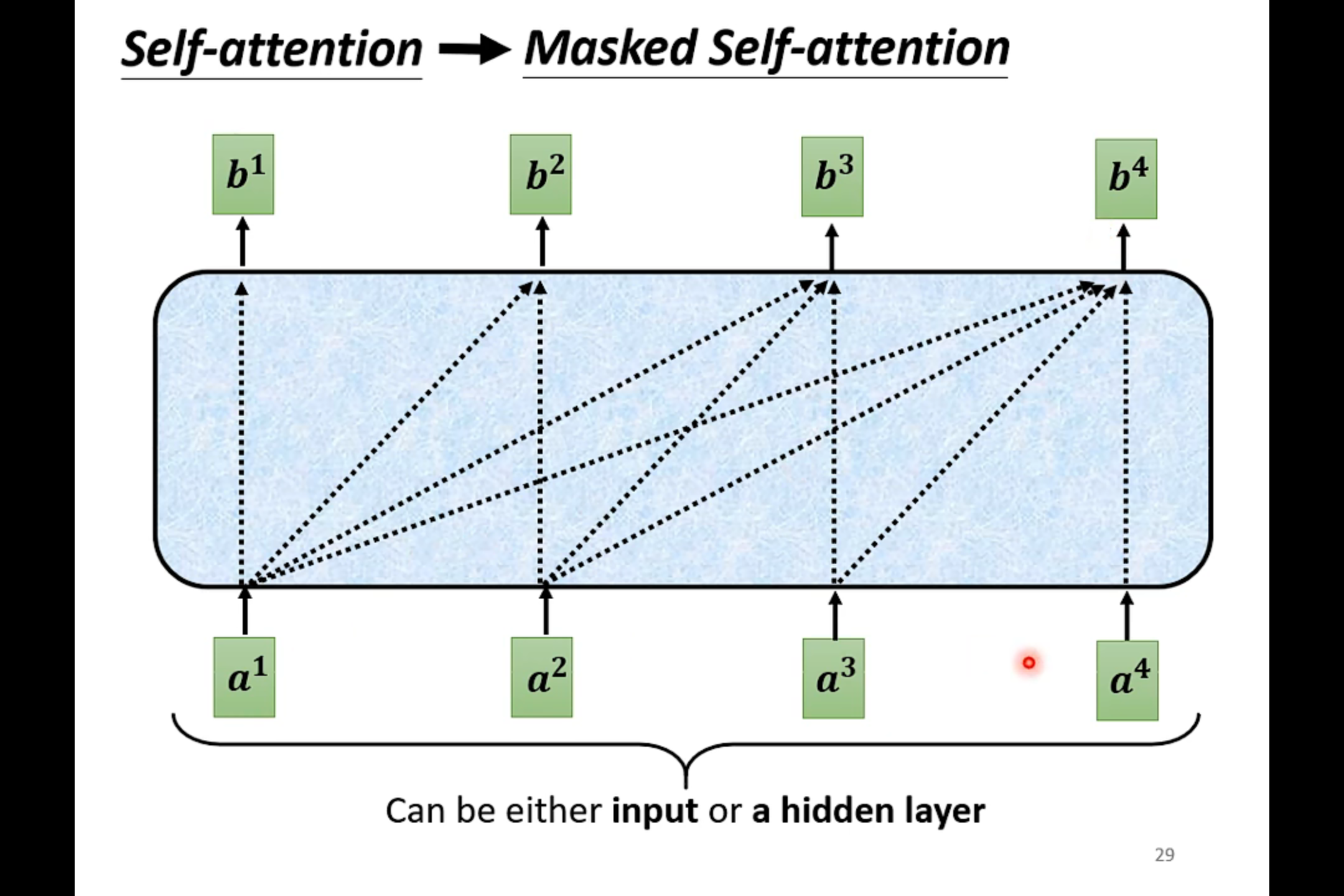
Masked Self-attention——产生b1的时候,只需要考虑a1
产生b2的时候只需要考虑a1和a2
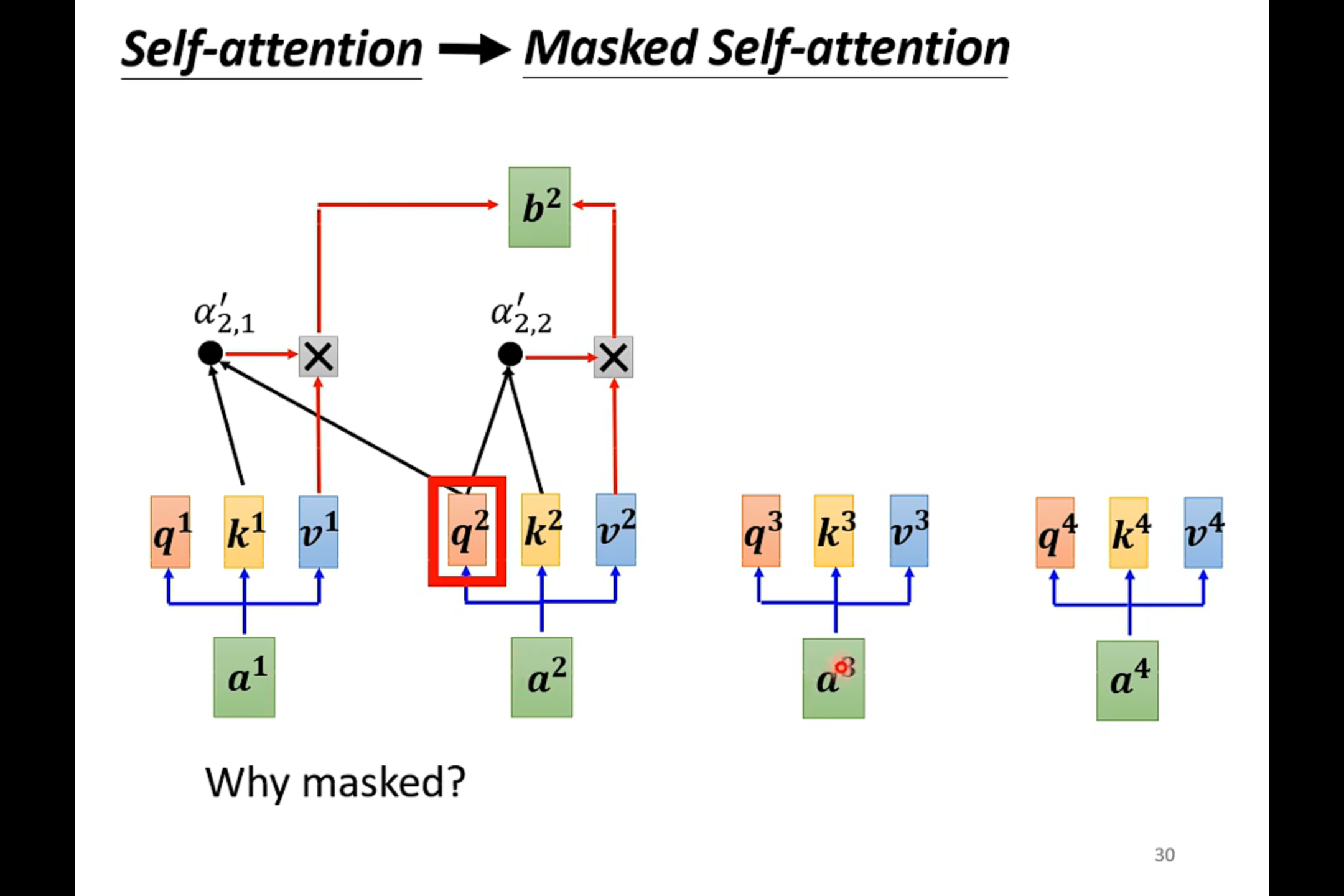
在decoder中,是先有a1 才有a2 然后才有a3

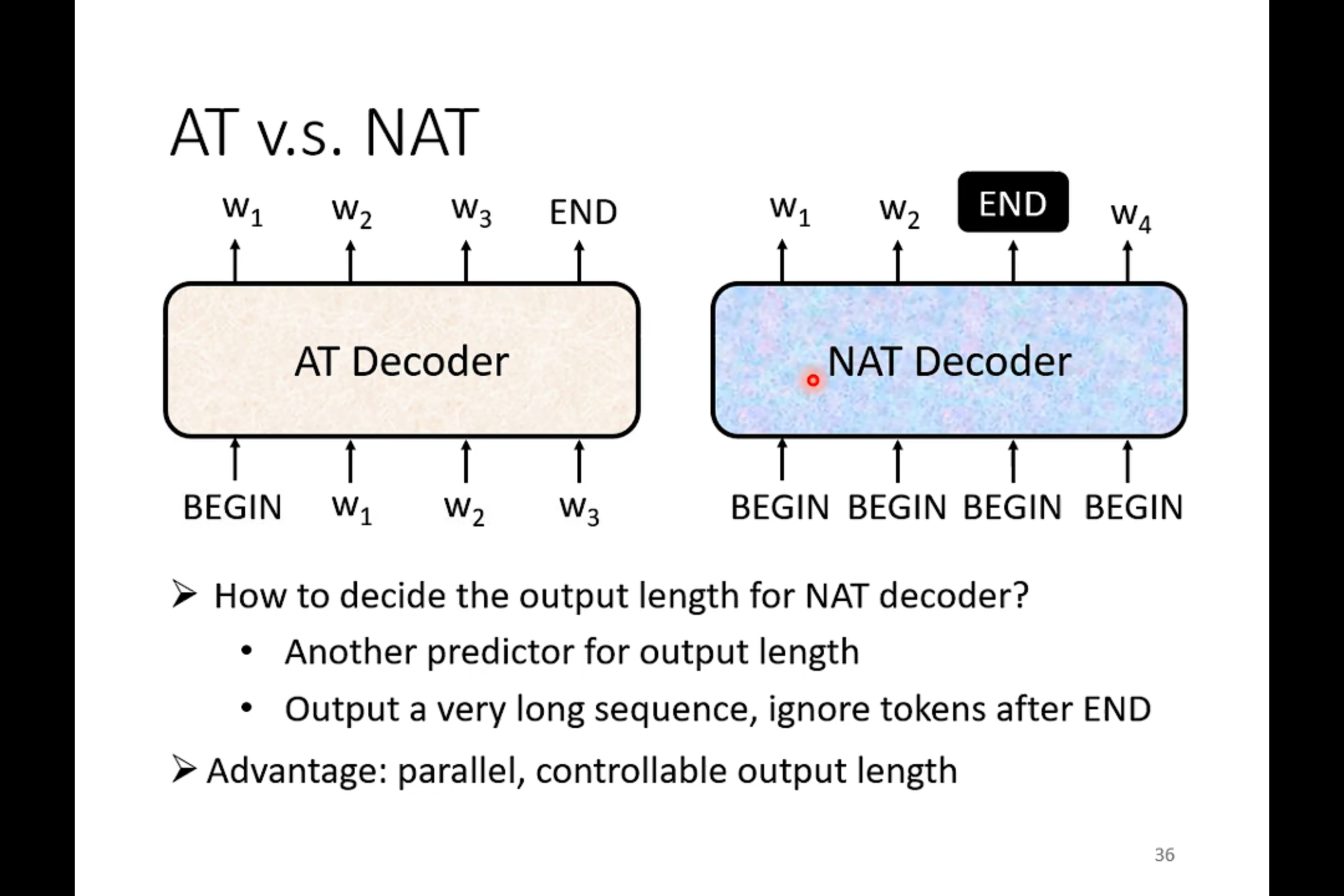

若有收获,就点个赞吧
0 人点赞
