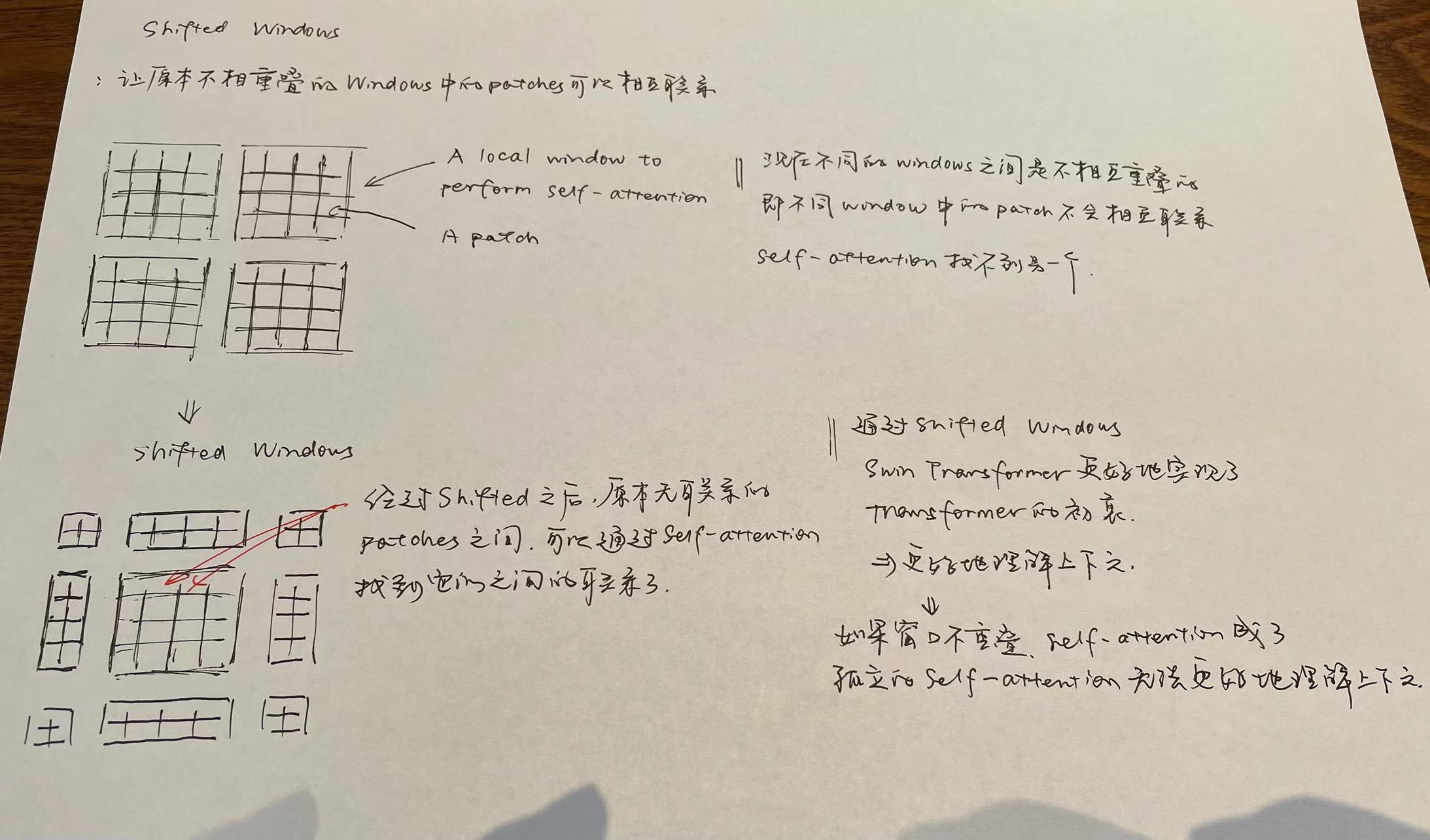
在Swin Transformer这篇文章中,作者提出了Shift Windows这个概念, Swin Transformer的目的是,让Vision Transformer像卷积一样也能分成几个blocks做层级式的特征提取,做到一个特征多尺度的概念。 在目前的CV领域的比赛中,Swin Transformer基本思已经实现霸榜,最好的几个模型都用到了Swin Transformer
transformer中token的解释:我理解的是token是transformer模型中最小的处理单位。 在NLP领域中,token就是每一个单词,在CN领域中,token就是每一个patch序列 这些都是处理的最小单位。 transformer中,做自注意力是在token中进行计算的。 就是说之前的attention大多使用在seq2seq任务中,例如在机器翻译中,attention作用在源句子token(token就指的是单词或词语)和目标句子token之间,但是transformer的self-attention作用在源句子的token之间。在Swin Transformer中,Multi Self-attention就是在Windows中进行的,一个Windows由很多patches组成。
Abstract
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision.(Swin Transformer可以作为计算机视觉中的通用的骨干网络) Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities(Transformer从NLP领域迁移到CV领域有一个很重要的问题就是,尺度问题,同一个语义可能对应着不同大小的像素区域) and the high resolution of pixels in images compared to words in text. (High Resolution对应着向量,序列的长度会变得很长)To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows.
The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at https://github.
com/microsoft/Swin-Transformer.
我认为Swin Transformer主要创新点在于Shifted Windows这样一个机制,通过Shifted Windows,把原图片切割成了许多小的windows,并且只在windows内做自注意力机制。由于图像转化为向量之后会变成一个很长的序列,直接进行自注意力机制计算,会导致计算量非常的大。Shifted Windows很好地解决了这个问题。切割之后Windows和Windows是不重叠的,这样的话无法观察到不同Windows之间的patches是如何联系的,所以对Windows进行Shift。这里应用了图像的先验知识,图像中相近的地方信息的关联度比较大。由于只Shifted 1/2 Patch_size,大大减少了计算量。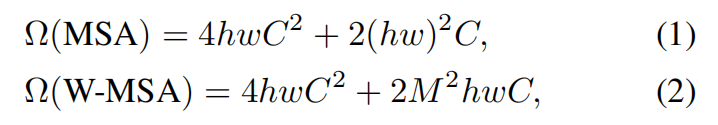
1.Introduction
Modeling in computer vision has long been dominated by convolutional neural networks (CNNs). Beginning with AlexNet [39] and its revolutionary performance on the ImageNet image classification challenge, CNN architectures have evolved to become increasingly powerful through greater scale [30, 76], more extensive connections [34], and more sophisticated forms of convolution [70, 18, 84]. With
CNNs serving as backbone networks for a variety of vision tasks, these architectural advances have led to performance improvements that have broadly lifted the entire field.
On the other hand, the evolution of network architectures in natural language processing (NLP) has taken a different path, where the prevalent architecture today is instead the Transformer [64]. Designed for sequence modeling and transduction tasks, the Transformer is notable for its use of attention to model long-range dependencies in the data. Its tremendous success in the language domain has led researchers to investigate its adaptation to computer vision, where it has recently demonstrated promising results on certain tasks, specifically image classification [20] and joint vision-language modeling [47].
Transformer在NLP是主导地位,Transformer在NLP取得了优良的成绩,作者也想把transformer用到CV领域上。这里我不太理解patch_size这个概念,比如说patch_size=4是下采样四倍,是长和宽都除以四。那为什么第一个16x是16倍下采样呢,不是长宽都除以4吗。
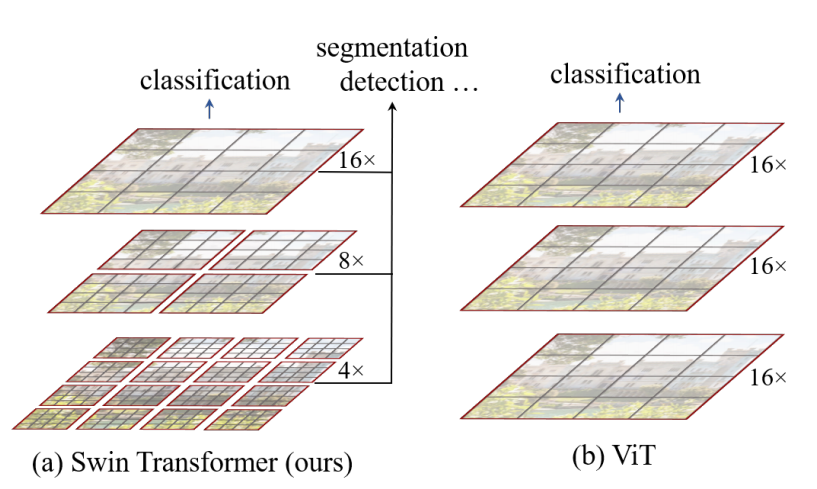
Figure 1. (a) The proposed Swin Transformer builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classifification and dense recognition tasks.
(b) In contrast, previous vision Transformers [20] produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.
这个图中,我们可以看出,ViT——Vision Transformer,ViT把图片打成了patch,16x 16这样的一个形式, 这里的16x意味着一个16倍的下采样,在ViT中的每一个patch,每一个token代表的尺寸都差不多,因为每一层都是16倍的下采样率,这样的话,对于多尺寸的特征的分辨能力就会差一些。 在ViT中处理的一直都是16倍下采样率之后的特征,ViT就不适合处理这种预测密集型任务。 ViT的self-attention始终是在整图上进行的,ViT是一个全局建模,所以ViT的计算复杂度是跟图像的尺寸的平方成正比的。 为了减少序列长度,Swin Transformer采用了,在小窗口内算自注意力。Swin Transformer利用了,卷积神经网络中的Locality 的Introductive bias利用了局部性的先验知识,就是说同一个物体的不同部位,或者说语义相近的不同物体,大概率会出现在相连的地方。所以,即使在一个小范围的地方做自注意力,也差不多是够用的。 在图像处理领域对于全局去做自注意力机制,是有点浪费计算资源的。 在Swin Transformer中,利用了patch-merging的方法,让计算机可以捕获到更大视野范围内的问题,让Swin Transformer可以更好的实现多尺度特征的提取。
In this paper, we seek to expand the applicability of Transformer such that it can serve as a general-purpose backbone for computer vision, as it does for NLP and as CNNs do in vision. (作者希望把transformer扩展成为一个新的骨干网络在CV领域。)We observe that significant challenges in transferring its high performance in the language domain to the visual domain can be explained by differences between the two modalities. One of these differences involves scale. Unlike the word tokens that serve as the basic elements of processing in language Transformers, visual elements can vary substantially in scale, a problem that receives attention in tasks such as object detection [42, 53, 54]. In existing Transformer-based models [64, 20], tokens are all of a fixed scale, a property unsuitable for these vision applications. Another difference is the much higher resolution of pixels in images compared to words in passages of text. There exist many vision tasks such as semantic segmentation that require dense prediction at the pixel level, and this would be intractable for Transformer on high-resolution images, as the computational complexity of its self-attention is quadratic to image size. To overcome these issues, we propose a general purpose Transformer backbone, called Swin Transformer, which constructs hierarchical feature maps and has linear computational complexity to image size. As illustrated in Figure 1(a), Swin Transformer constructs a hierarchical representation by starting from small-sized patches (outlined in gray) and gradually merging neighboring patches in deeper Transformer layers. With these hierarchical feature maps, the Swin Transformer model can conveniently leverage advanced techniques for dense prediction such as feature pyramid networks (FPN) [42] or U-Net [51]. The linear computational complexity is achieved by computing self-attention locally within non-overlapping windows that partition an image (outlined in red). The number of patches in each window is fixed, and thus the complexity becomes linear to image size. These merits make Swin Transformer suitable as a general-purpose backbone for various vision tasks, in contrast to previous Transformer based architectures [20] which produce feature maps of a single resolution and have quadratic complexity.
A key design element of Swin Transformer is its _shift _of the window partition between consecutive self-attention layers, as illustrated in Figure 2. The shifted windows bridge the windows of the preceding layer, providing connections among them that signifificantly enhance modeling power (see Table 4). This strategy is also effificient in regards to real-world latency: all _query _patches within a window share the same _key _set1 , which facilitates memory access in hardware. In contrast, earlier _sliding window _based self-attention approaches [33, 50] suffer from low latency on general hardware due to different _key _sets for different _query _pixels2 . Our experiments show that the proposed _shifted window _approach has much lower latency than the _sliding window _method, yet is similar in modeling power (see Tables 5 and 6). The shifted window approach also proves benefificial for all-MLP architectures [61].
第四段主要是介绍Swin Transformer提出的Shifted Windows这个概念。通过Shifted Windows,Swin可以更好地注意到图片的上下文,更好地发挥transformer的初衷。
The proposed Swin Transformer achieves strong performance on the recognition tasks of image classifification, object detection and semantic segmentation. It outperforms the ViT / DeiT [20, 63] and ResNe(X)t models [30, 70] significantly with similar latency on the three tasks. Its 58.7 box AP and 51.1 mask AP on the COCO test-dev set surpass the previous state-of-the-art results by +2.7 box AP (Copy-paste [26] without external data) and +2.6 mask AP (DetectoRS [46]). On ADE20K semantic segmentation, it obtains 53.5 mIoU on the val set, an improvement of +3.2 mIoU over the previous state-of-the-art (SETR [81]). It also achieves a top-1 accuracy of 87.3% on ImageNet-1K image
classifification.
It is our belief that a unified architecture across computer vision and natural language processing could benefit both fields, since it would facilitate joint modeling of visual and textual signals and the modeling knowledge from both domains can be more deeply shared. We hope that Swin Transformer’s strong performance on various vision problems can drive this belief deeper in the community and encourage unifified modeling of vision and language signals.
作者坚信,在CV和NLP中存在一个大一统的框架。 作者是利用Swin Transformer在视觉领域的先验信息,才让Swin Transformer在CV领域取得了出色的成果,但ViT在大一统这一块领域做的会更好,因为ViT可以什么都不加,就应用到CV领域上。
2.Related Work
3.Method
3.1 Overall Architecture
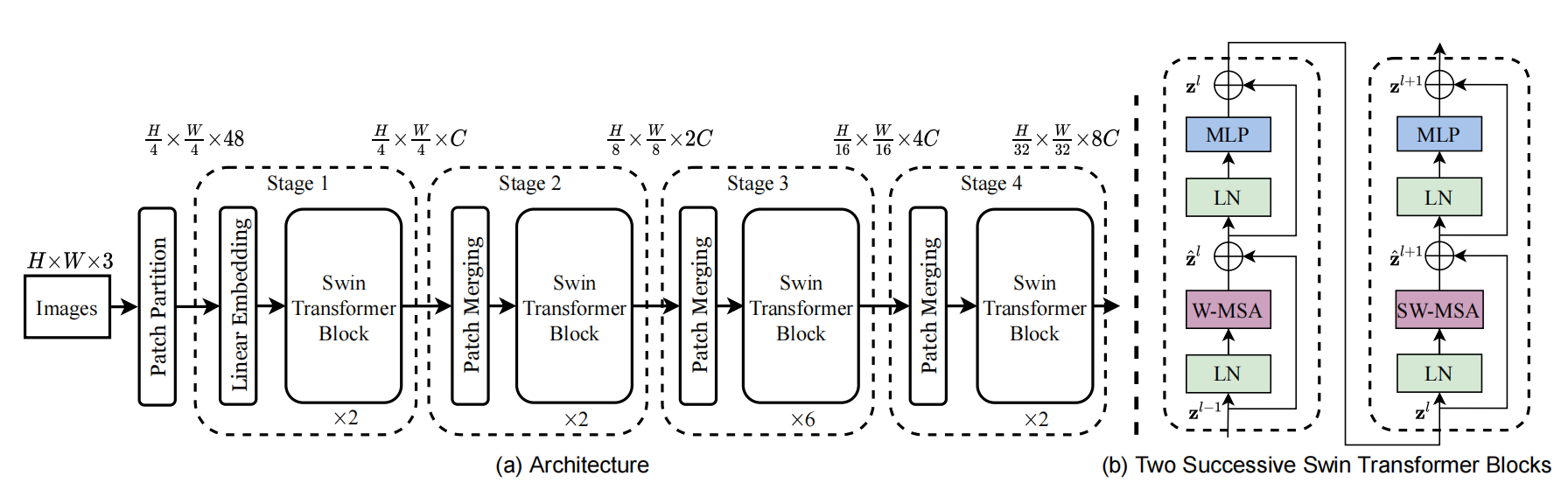
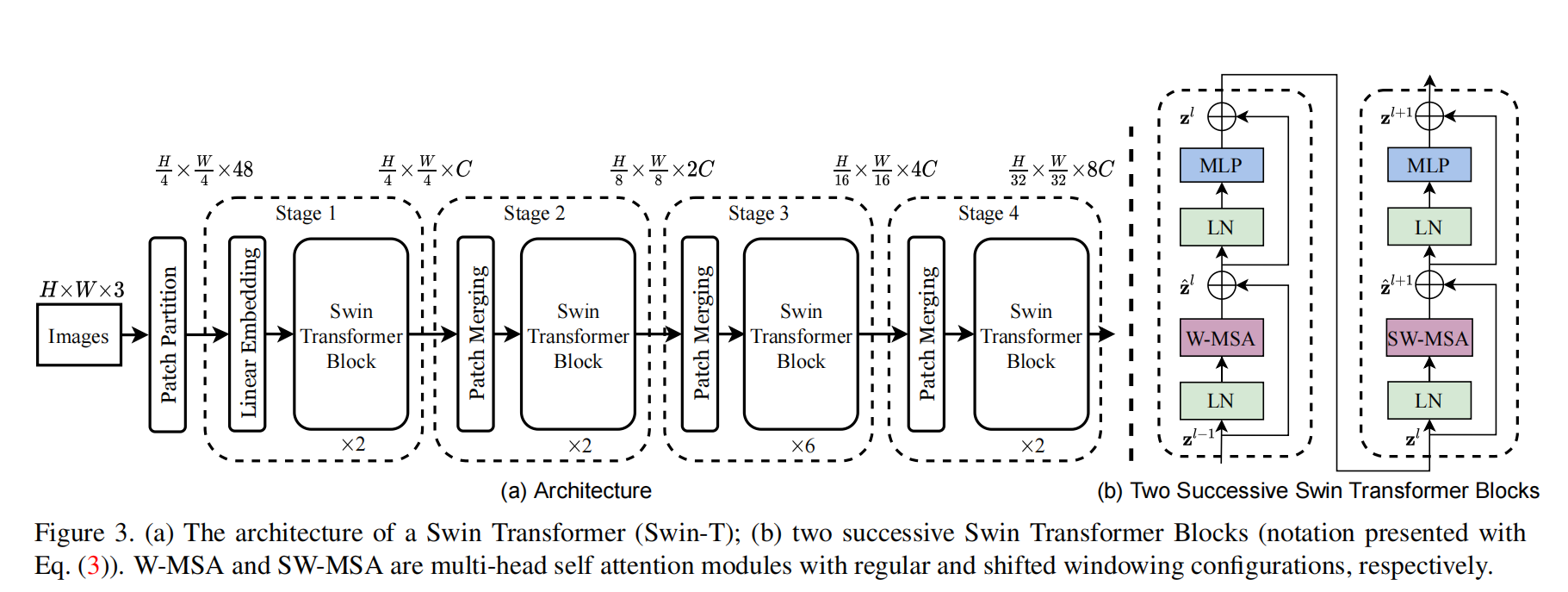
Figure 3. (a) The architecture of a Swin Transformer (Swin-T); (b) two successive Swin Transformer Blocks (notation presented with Eq. (3)). W-MSA and SW-MSA are multi-head self attention modules with regular and shifted windowing confifigurations, respectively
这里的架构主要分为Stage 1和 Stage 2两个大的模块
Stage 1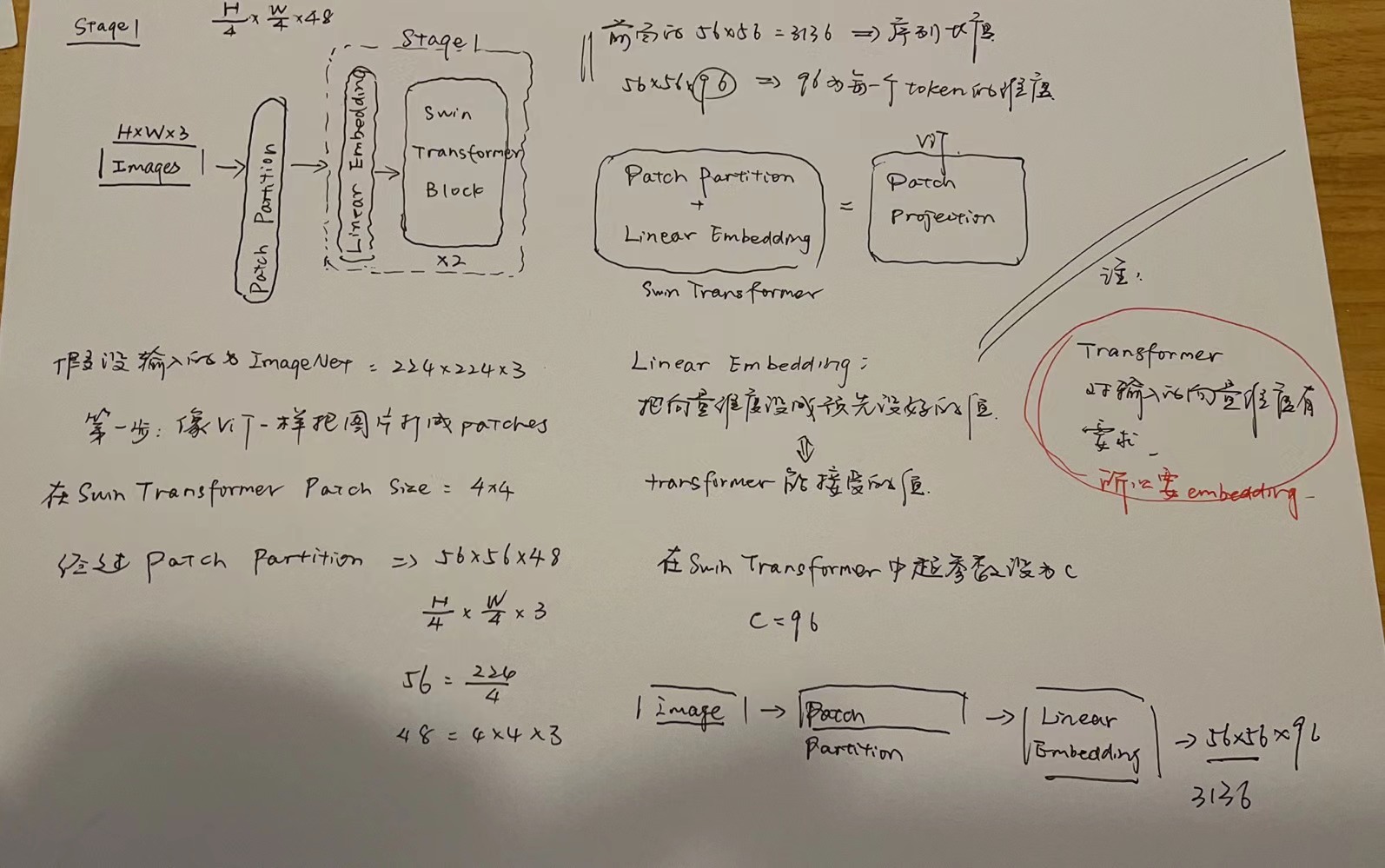
Stage 2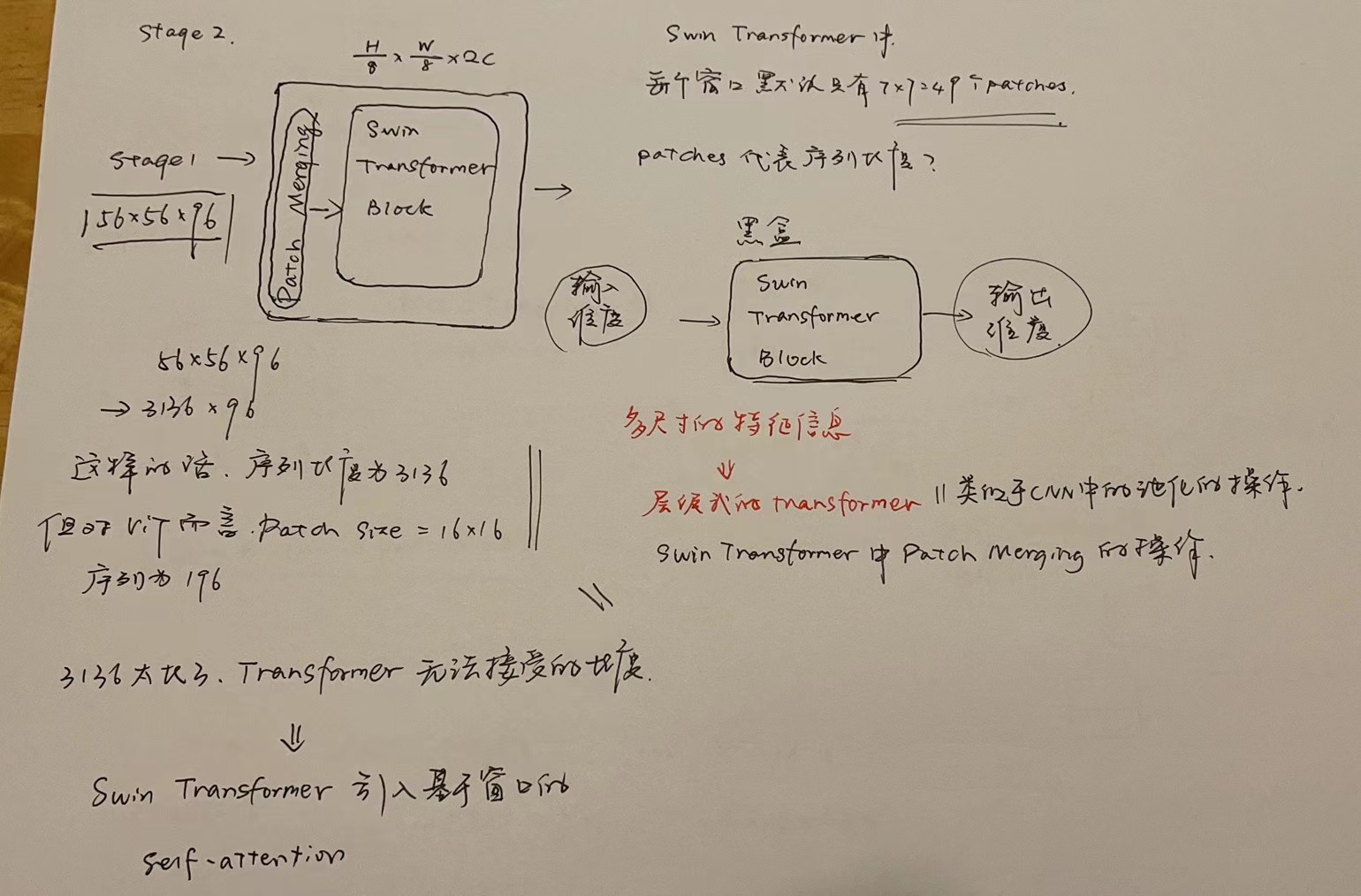

这里的patch merging的核心目的在于增加,观察野,这里是2倍下采样,所以是长和宽都变为原来的1/2。所以,2x2=4,把原来的图像切割成4份。在每个区域内再切4份,这样就会起到类似于池化的功能,相当于在每个区域内都取4个特征。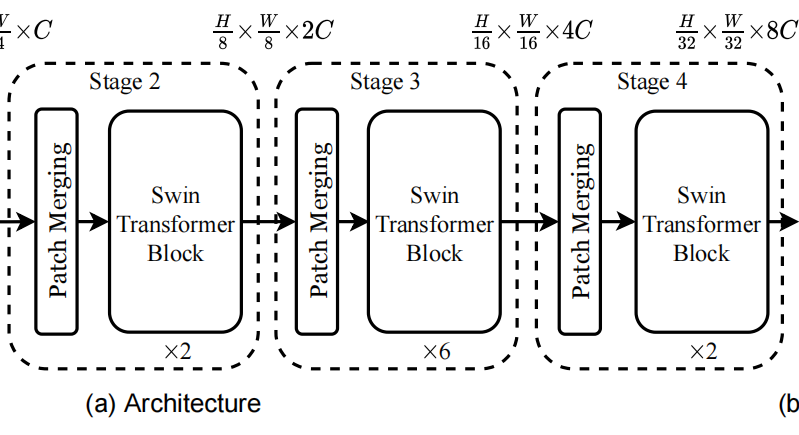
An overview of the Swin Transformer architecture is presented in Figure 3, which illustrates the tiny version (Swin-T). It first splits an input RGB image into non-overlapping patches by a patch splitting module, like ViT. Each patch is treated as a “token” and its feature is set as a concatenation of the raw pixel RGB values. In our implementation, we use a patch size of 4 × _4 and thus the feature dimension of each patch is 4 × 4 × 3 = 48. A linear embedding layer is applied on this raw-valued feature to project it to an arbitrary dimension (denoted as _C).
Several Transformer blocks with modifified self-attention computation (Swin Transformer blocks) are applied on these patch tokens. The Transformer blocks maintain the number of tokens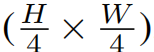 , and together with the linear embedding are referred to as “Stage 1”.
, and together with the linear embedding are referred to as “Stage 1”.
To produce a hierarchical representation, the number of tokens is reduced by patch merging layers as the network gets deeper. The fifirst patch merging layer concatenates the features of each group of 2 ×
2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features. This reduces the number of tokens by a multiple of 2×_2 = 4 (2× downsampling of resolution), and the output dimension is set to 2_C. Swin Transformer blocks are applied afterwards for feature transformation, with the resolution kept at 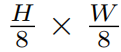 . This fifirst block of patch merging and feature transformation is denoted as “Stage 2”. The procedure is repeated twice, as “Stage 3” and “Stage 4”, with output resolutions of
. This fifirst block of patch merging and feature transformation is denoted as “Stage 2”. The procedure is repeated twice, as “Stage 3” and “Stage 4”, with output resolutions of 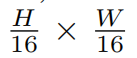 and
and  , respectively. These stages jointly produce a hierarchical representation,with the same feature map resolutions as those of typical
, respectively. These stages jointly produce a hierarchical representation,with the same feature map resolutions as those of typical
convolutional networks, e.g., VGG [52] and ResNet [30]. As a result, the proposed architecture can conveniently replace the backbone networks in existing methods for various vision tasks.
3.2 Shifted Windows based Self-Attention
The standard Transformer architecture [64] and its adaptation for image classifification [20] both conduct global self-attention, where the relationships between a token and all other tokens are computed. The global computation leads to quadratic complexity with respect to the number of tokens,
making it unsuitable for many vision problems requiring an immense set of tokens for dense prediction or to represent a high-resolution image.
Self-attention in non-overlapped windows
For effificient modeling, we propose to compute self-attention within local windows. The windows are arranged to evenly partition the image in a non-overlapping manner. Supposing each window contains M × M _patches, the computational complexity of a global MSA module and a window based one on an image of _h × w _patches are3: 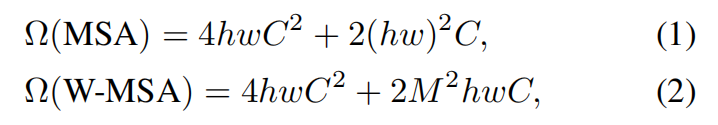
where the former is quadratic to patch number _hw, and the latter is linear when M _is fifixed (set to 7 by default). Global self-attention computation is generally unaffordable for a large _hw, while the window based self-attention is scalable.
Shifted Windows之后的计算复杂度:
核心就是把本来要在全局进行的自注意力计算,分散到各个小区域再相加,让原本会进行相互计算的区域,不再联系。这里可能是利用了一些图像的先验知识,减少了运算量。
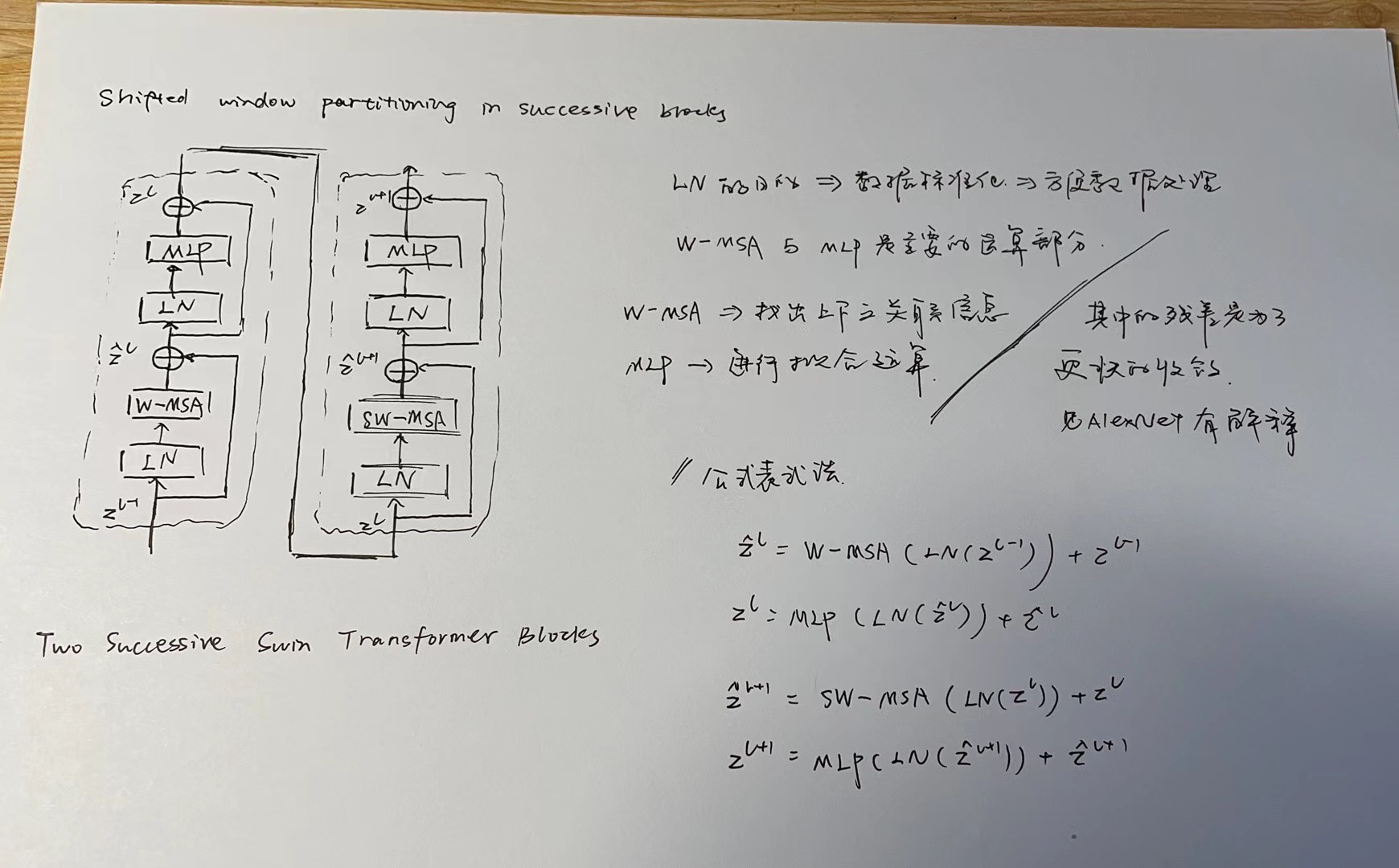
Shifted window partitioning in successive blocks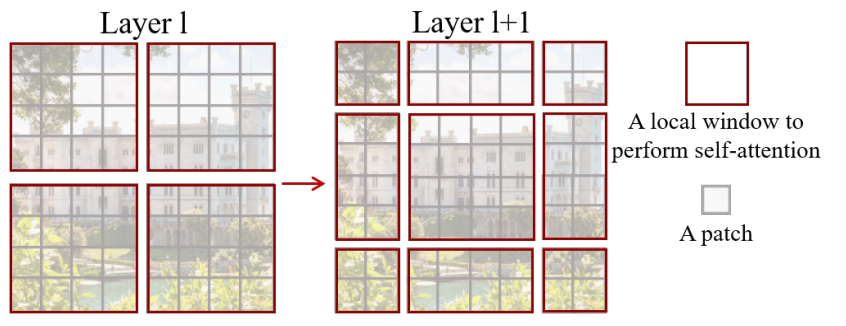
The window-based self-attention module lacks connections across windows, which limits its modeling power. To introduce cross-window connections while maintaining the efficient computation of non-overlapping windows, we propose a shifted window partitioning approach which alternates between two partitioning configurations in consecutive Swin Transformer blocks.(这里移动窗口的目的就是让本来不重叠的部分产生联系) As illustrated in Figure 2, the first module uses a regular window partitioning strategy which starts from the top-left pixel, and the 8 × _8 feature map is evenly partitioned into 2 × 2 windows of size 4 × 4 (_M = 4). Then, the next module adopts a windowing confifiguration that is shifted from that of the preceding layer, by displacing the windows by 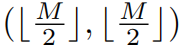 pixels from the regularly partitioned windows. With the shifted window partitioning approach, consecutive Swin Transformer blocks are computed as
pixels from the regularly partitioned windows. With the shifted window partitioning approach, consecutive Swin Transformer blocks are computed as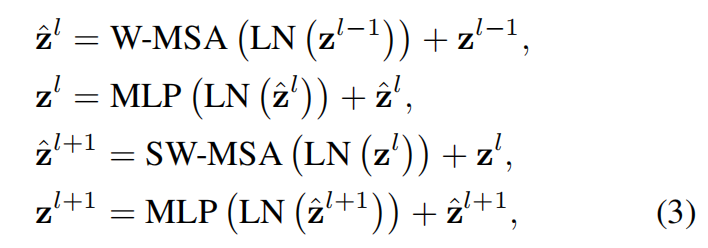
where 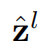 _and
_and 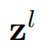 denote the output features of the (S)WMSA module and the MLP module for block _l, respectively;W-MSA and SW-MSA denote window based multi-head self-attention using regular and shifted window partitioning configurations, respectively. The shifted window partitioning approach introduces connections between neighboring non-overlapping windows in the previous layer and is found to be effective in image classification, object detection, and semantic segmentation, as shown in Table 4.
denote the output features of the (S)WMSA module and the MLP module for block _l, respectively;W-MSA and SW-MSA denote window based multi-head self-attention using regular and shifted window partitioning configurations, respectively. The shifted window partitioning approach introduces connections between neighboring non-overlapping windows in the previous layer and is found to be effective in image classification, object detection, and semantic segmentation, as shown in Table 4.
Windows经过Shift操作之后,从4个Windows变成了9个Windows。现在的问题是,Shift之后窗口的尺寸各不相同。我们如何调整9个Windows的大小,让其的尺寸和原来的4x4相同呢?相同之后有个好处,就是可以把相同的尺寸的Windows压成一个Batch统一计算。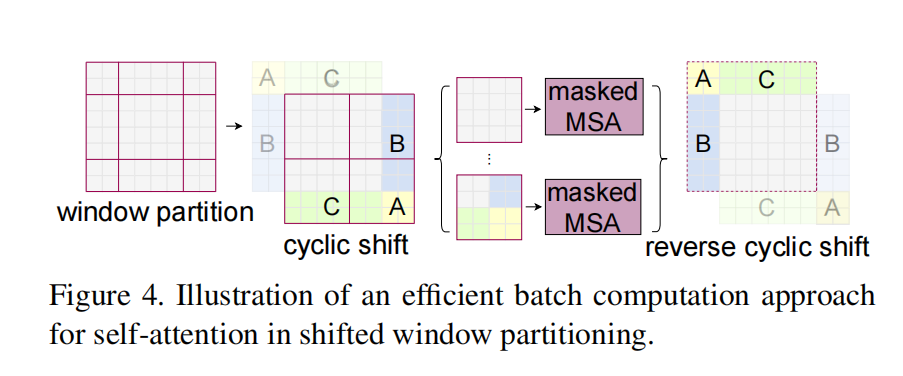
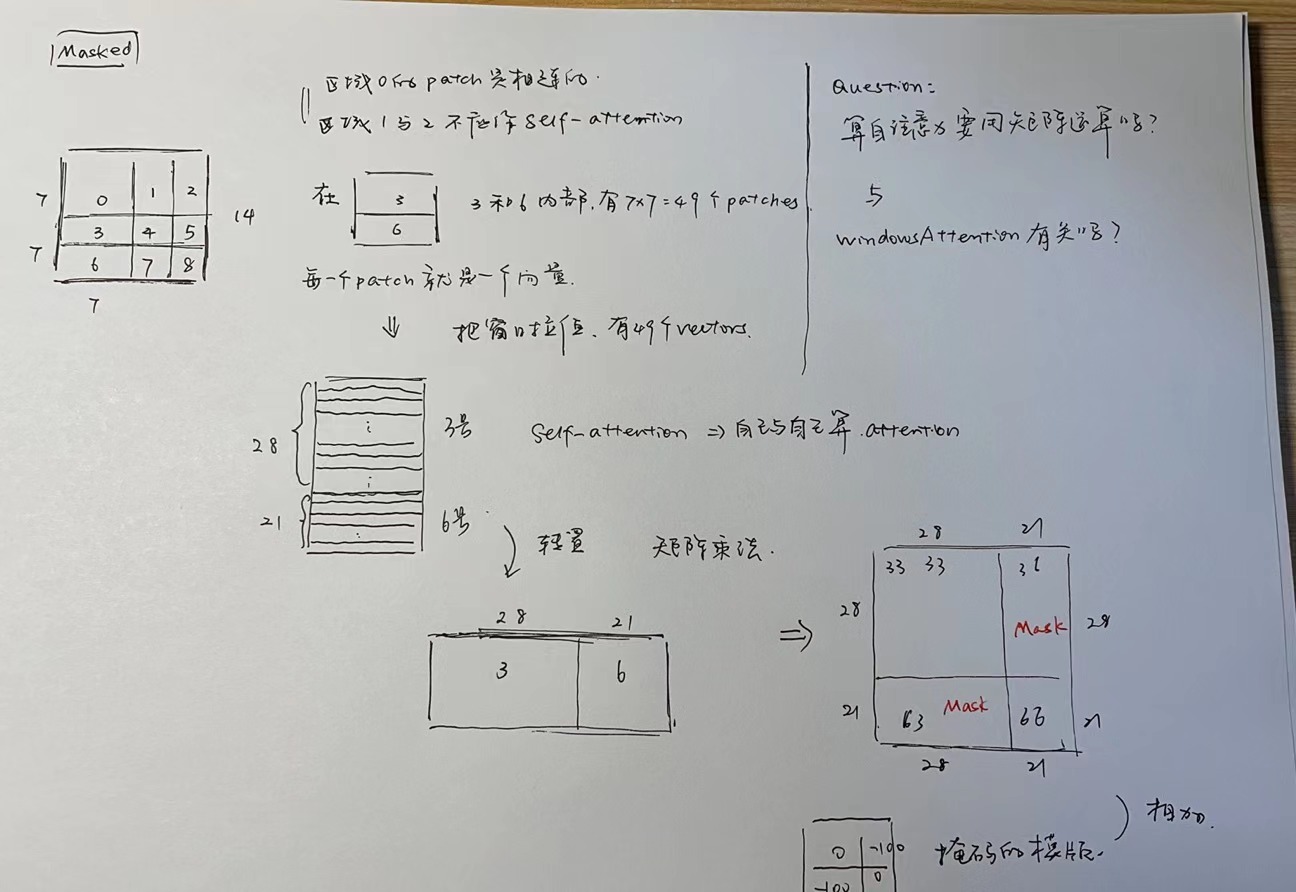
我发现用这种shifted windows有个好处,因为用shifted windows这种方法可以让不同的windows之间产生联系,但又不至于联系到太远的地方。 、

Eifficient batch computation for shifted configuration
An issue with shifted window partitioning is that it will result in more windows, from  _to
_to 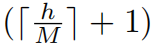 ×
× 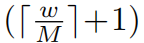 in the shifted confifiguration, and some of the windows will be smaller than _M × M_4 . A naive solution is to pad the smaller windows to a size of _M × M _and mask out the padded values when computing attention. When the number of windows in regular partitioning is small, e.g. 2 × 2, the increased computation with this naive solution is considerable (2 × 2 → 3 × _3, which is 2.25 times greater). Here, we propose a _more effificient batch computation approach _by cyclic-shifting toward the top-left direction, as illustrated in Figure 4. After this shift, a batched window may be composed of several sub-windows that are not adjacent in the feature map, so a masking mechanism is employed to limit self-attention computation to within each sub-window. With the cyclic-shift, the number of batched windows remains the same as that of regular window partitioning, and thus is also effificient. The low latency of this approach is shown in Table 5.
in the shifted confifiguration, and some of the windows will be smaller than _M × M_4 . A naive solution is to pad the smaller windows to a size of _M × M _and mask out the padded values when computing attention. When the number of windows in regular partitioning is small, e.g. 2 × 2, the increased computation with this naive solution is considerable (2 × 2 → 3 × _3, which is 2.25 times greater). Here, we propose a _more effificient batch computation approach _by cyclic-shifting toward the top-left direction, as illustrated in Figure 4. After this shift, a batched window may be composed of several sub-windows that are not adjacent in the feature map, so a masking mechanism is employed to limit self-attention computation to within each sub-window. With the cyclic-shift, the number of batched windows remains the same as that of regular window partitioning, and thus is also effificient. The low latency of this approach is shown in Table 5.
Relative position bias
In computing self-attention, we follow [49, 1, 32, 33] by including a relative position bias 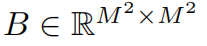 to each head in computing similarity:
to each head in computing similarity: 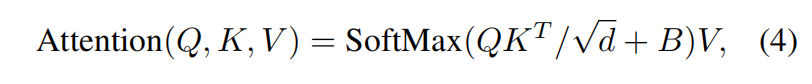
where 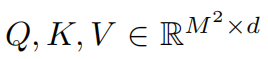 are the query, key _and _value _matrices; _d _is the _query/key _dimension, and _M_2 is the number of patches in a window. Since the relative position along each axis lies in the range [−M + 1, M −_1], we parameterize a smaller-sized bias matrix
are the query, key _and _value _matrices; _d _is the _query/key _dimension, and _M_2 is the number of patches in a window. Since the relative position along each axis lies in the range [−M + 1, M −_1], we parameterize a smaller-sized bias matrix 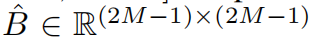 , and values in _B _are taken from
, and values in _B _are taken from 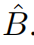
We observe signifificant improvements over counterparts without this bias term or that use absolute position embedding, as shown in Table 4. Further adding absolute position embedding to the input as in [20] drops performance slightly, thus it is not adopted in our implementation. The learnt relative position bias in pre-training can be also used to initialize a model for fifine-tuning with a different window size through bi-cubic interpolation [20, 63].
5.Conclusion
This paper presents Swin Transformer, a new vision Transformer which produces a hierarchical feature representation and has linear computational complexity with respect to input image size.Swin Transformer achieves the state-of-the-art performance on COCO object detection and ADE20K semantic segmentation, signifificantly surpassing previous best methods. We hope that Swin Transformer’s
strong performance on various vision problems will encourage unifified modeling of vision and language signals.
As a key element of Swin Transformer, the _shifted window _based self-attention is shown to be effective and efficient on vision problems, and we look forward to investigating its use in natural language processing as well.
说实话,我不理解为什么用了Swin Transformer,最后的指标就好了。为啥用了Swin Transformer精度就高了。
附录
1.从swin transformer中理解patch_size
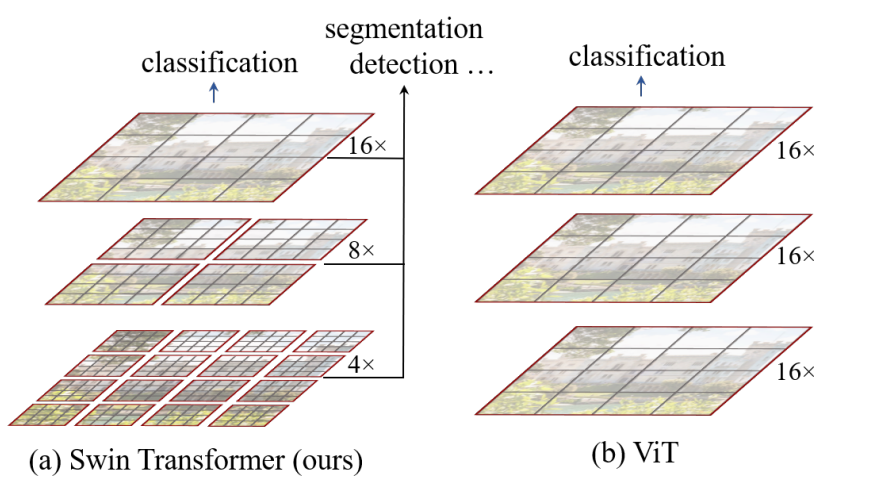
结合这两幅图来看,stage 1中,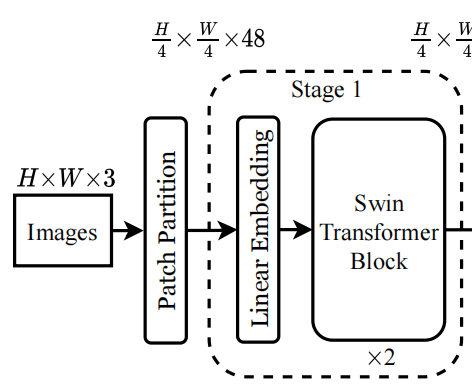 这里的
这里的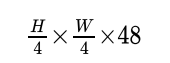 ,是4倍的下采样,即长宽都除以四。把原来的图片切割成16个窗口。对应于
,是4倍的下采样,即长宽都除以四。把原来的图片切割成16个窗口。对应于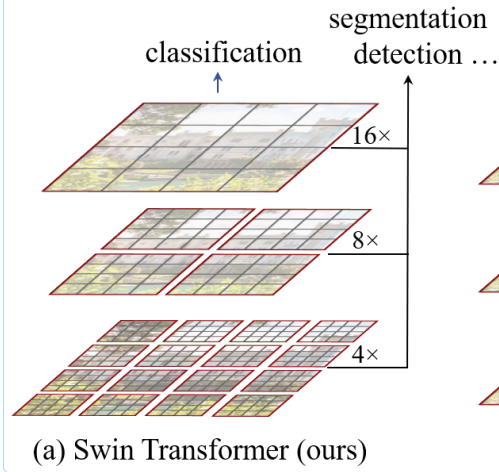 第一层16x,即长和宽都变成原来的1/4
第一层16x,即长和宽都变成原来的1/4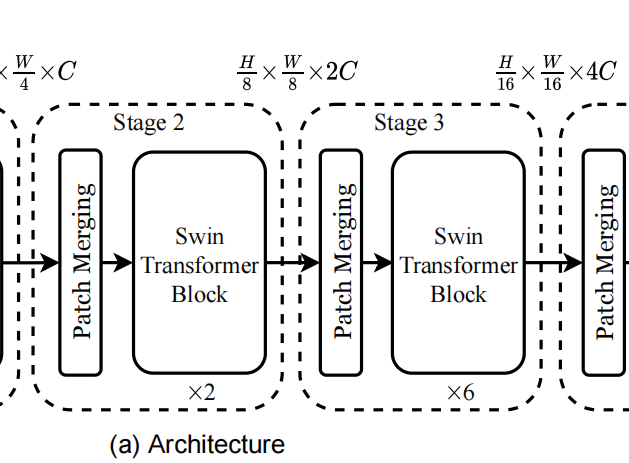
后面的Stage2和Stage 3对应于8x和16x
即把原图像切割成多少个窗口。
2.为什么patch-merging可以让计算机捕获到更大的视野?

若有收获,就点个赞吧
0 人点赞
