数据集划分
from sklearn.model_selection import train_test_split
我们在训练的时候,一般只向文件输入一个train.csv
这时候我们需要把数据集划分成,训练集和测试集
from sklearn.model_selection import train_test_splitx_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
这里的x和y为特征值和目标值,我们需要把x和y分别拆成,训练集的目标值和特征值还有,测试集的目标值和特征值。
转换器与预估器
Transformer
转化器一般用于数据预处理。我们对输入的训练数据/测试数据做的预处理,都是用
fit_transform()
其中的fit和transform又是区分开来的
def knn_iris():# 获取数据集iris = load_iris()# 数据集分割x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25)# 特征工程transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)
我们可以看到在上面的例子中,我们对x_train和x_test使用了不同的操作,两个不同的操作之后,得到了最后的结果。
现在的问题在于:fit和transform分别执行了什么操作。
我们使用的是StandardScaler()函数进行特征工程。

transform的操作执行的功能是,计算出mean和 的值
的值
fit的操作是把计算出来的参数,代入到数据中去。
Question:——我们为什么要对x_train进行fit_transform而对x_test进行fit呢?
因为,x_train是我们的训练集,而x_test是我们的测试集,我们测试集的数据,应该是用来校准是否满足模型的,所以我们应该用训练集训练出来的参数去作为测试集fit的参数。
Estimator
estimator.fit和estimator.predict是最重要的两个方法。
我们用estimator来对模型进行训练。
estimator = KNeighborsClassifier(n_neighbors = 3)estimator.fit(x_train,y_train)y_predict = estimator.predict(x_test)print("y_predict",y_predict)
我们先利用算法模型实例化一个estimator
然后再通过数据来训练estimator,这里我们需要输入训练集的数据,即x_train,y_train
之后,我们要输出预测集的数据。
计算模型的准确率
y_predict = estimator.predict(x_test)print("y_predict:\n",y_predict)print("直接对比真实值和预测值")score = estimator.score(x_test,y_test)print("准确率为:",score)
x和y分别为,特征值和目标值。
模型设计与调优
模型设计与调优,核心思路在于:
很多模型在使用的时候,需要设计参数,现在问题在于,我们不知道如何设计最好的参数,最优的参数值。
1.1 交叉验证
交叉验证是什么意思呢?
我们现在有一个训练集,我们还需要对训练集进行划分,划分成测试集和训练集。
交叉验证,CrossVerified就是我们通过不同的分割方式,把训练集和测试集分割成不同的模块,现在我们对不同模块的进行训练,看看那个效果最好。这个就叫做交叉验证
1.2 超参网格搜索GridSearch
超参网格搜索的意思:就是
比如说我们使用KNN算法的时候,算法内部的n_neighbors可以有不同的取值,并且根据不同的取值会得出不同的结果。现在我们可以利用GridSearch方法对不同的参数值进行遍历,进而输出最好的那一个。
这是一种模型自动调优的方法。
我们利用超参数网格搜索+交叉验证,就可以计算出最优的模型。
所以也叫做GridSearchCV
transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# KNN算法预估器estimator = KNeighborClassfier(n_neighbors = 3)# 如果我们不使用网格搜索和交叉验证,我们就应该先把参数设计好。
transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# KNN算法预估器estimator = KNeighborClassfier()# GridSearchCVpara_dict = {"n_neighbors":[1,3,5,7,9,11]}estimator = GridSearchCV(estimator,param_grid=param_dict,cv=10)
GridSearchCV的几个参数
1、最佳参数 :bestparams
2、最佳结果 :bestscore
3、最佳估计器:bestestimator
4、交叉验证结果:cv_results
# 最佳参数estimator.best_params# 最佳结果estimator.best_score_# 最佳估计器estimator.best_estimator_# 交叉验证结果estimator.cv_results
标准化
StandardScaler
from sklearn.preprocessing import StandardScaler
为什么要对数据进行数据预处理?
1.1 介绍
在运用机器学习模型之前,我们要先对机器进行模型训练,也就是标准化,归一化,正常化,正规化
因为,很简单,我们要对数据进行归类运算。如果我们要进行归类运算,我们就需要计算数据距离这种概念。
所以我们要用标准化来统一度量衡

标准化和归一化有什么区别呢?
归一化是有缺陷的,当我们在考虑运算的时候,我们肯定要考虑异常值。我们需要用一些鲁棒性较强的数据来进行分析。
当我们使用归一化的时候,我们的最终输出结果与最大值和最小值有关。所以,如果异常值是最大值或最小值,就会很影响归一化的结果。

我们可以看到,对数据进行标准化,我们用到的是统计相关的数据,当我们利用统计数据进行标准化的时候,我们其实是对数据整体进行一个考量,而非只是选取某个特定的值作为优化的标准。
——标准化也是满足统计模型的,如何满足,即通过变换使原来的样本,变成了标准正态分布样本。
同时在这里我们也可以发现一个问题,那就是:
抗干扰能力和计算量是一对矛盾的变量
如果我们希望数据有更强的抗干扰能力,我们就不能对数据的计算提出过多的要求。
1.2 为什么要对数据进行无量纲化
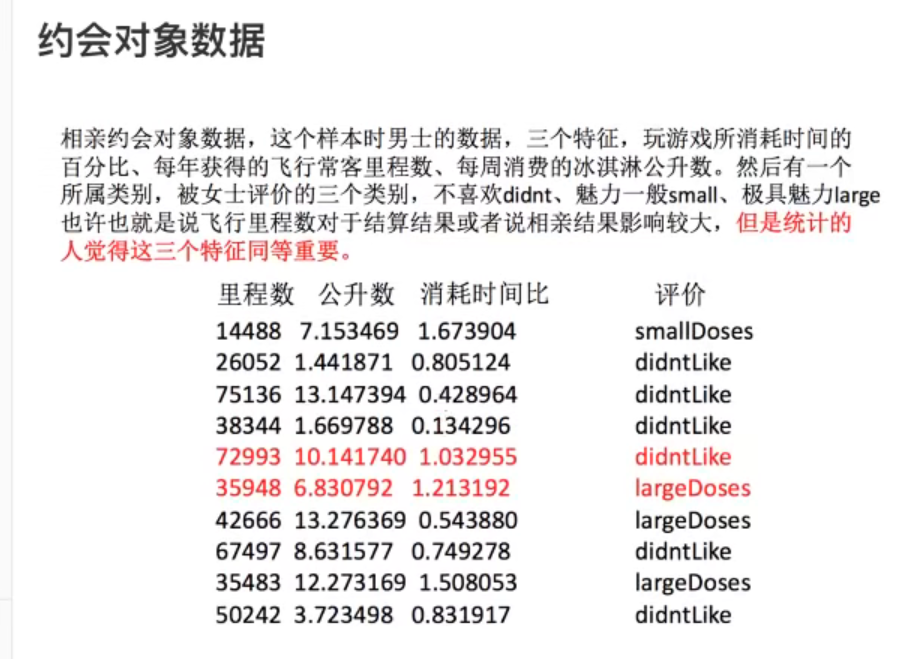
使用无量纲化,目标就是为了使各个字段的权重相同。
这样更方便使用跟距离有关的算法。比如说聚类算法
K近邻算法(KNN)——KNeighboursClassifier
1.1 介绍

通过判断某个样本与最近N个已知样本的距离,来确定当前样本的分类。
1.2 原理

在这里KNN算法运用到了,距离的概念,即样本空间中,两个样本之间的距离。
如果我们要使用KNN算法,我们就不得不引入,无量纲化的操作。
曼哈顿距离:绝对值距离
闵可夫斯基距离:范数
朴素贝叶斯算法
朴素的意思就是,特征和特征之间相互独立。
因为我们的数据量不够的话,就无法从数据中找到是否相互独立的关系。
应用场景:文本分类
单词作为特征
拉普拉斯平滑系数

若有收获,就点个赞吧
0 人点赞
