CNN,RNN,GAN,Transformer,
3. Convolutional Neural Networks for Super-Resolution
3.1 Formulation
1) Patch extraction and representation:
此操作从低分辨率图像Y中提取(重叠)色块,并将每个色块表示为高维向量。 这些向量包括一组特征图,其数量等于向量的维数。
2) Non-linear mapping:
此操作将每个高维向量非线性映射到另一个高维向量。 从概念上讲,每个映射向量都是高分辨率补丁的表示。 这些向量包含另一组特征图。
3) Reconstruction:
此操作将上述高分辨率的逐块表示形式进行汇总,以生成最终的高分辨率图像。 预期该图像类似于ground truth X。
n1和n2取决于filter的个数,feature maps就是特征图,1x1的卷积参数量比较少,可以很好的实现通道的简化,用1x1的卷积进行降维。通过逐步降维渐渐回到3维的图片。强回归
SRCNN是基于Sparse-Coding Methods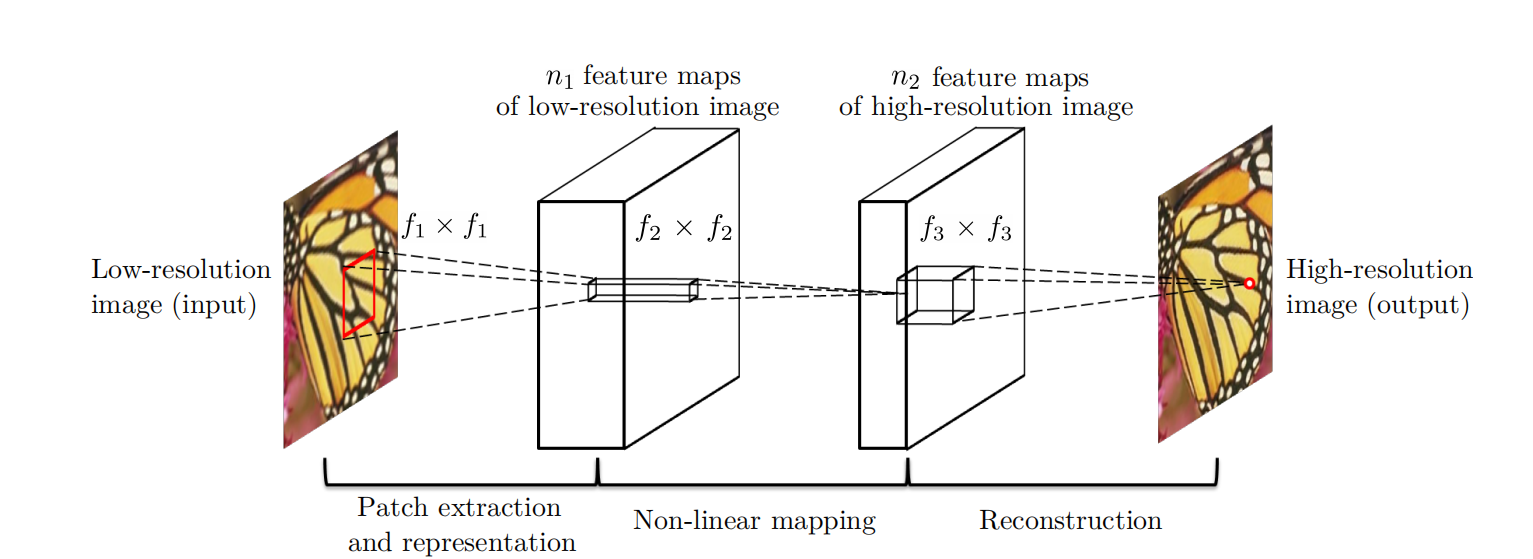
3.1.1 Patch extraction and representation
图像恢复中的一种流行策略(例如[1])是密集提取补丁,然后用一组预先训练好的基(例如PCA,DCT,Haar等)来表示它们。这等同于用一组滤波器对图像进行卷积,每个滤波器对应一个基。 在我们的表述中,我们将这些基的优化纳入网络的优化之中。 形式上,我们的第一层表示为操作F1: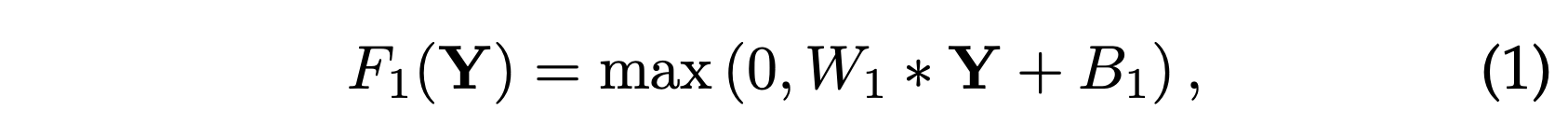
其中W1和B1分别代表滤波器和偏置,“*”代表卷积运算。在此,W1对应于支撑c×f1×f1的n1个过滤器,其中c是输入图像中通道的数量,f1是过滤器的空间大小。直观地,W1在图像上应用n1个卷积,每个卷积的核尺寸为c×f1×f1。输出由n1个特征图组成。B1是n1维向量,其每个元素都与一个过滤器关联。 我们在过滤器响应上应用线性校正单位(ReLU,max(0,x)) [33] (注:ReLU可以等效地视为第二个运算(非线性映射)的一部分,而第一个运算(补丁提取和表示)变成纯线性卷积。)。
W1是很多个滤波器的集合,W1Y + B1的意思是,
无数个w1Y+b的组合。就是第一层的输出是n1个feature maps的集合。最后再用ReLU函数激活。
3.1.2 Non-linear Mapping
第一层为每个面片提取n1维特征。 在第二个操作中,我们将这些n1维向量中的每一个映射到n2维向量中。 这等效于应用n2个具有微小空间支持1×1的滤波器。
(什么是trivial spatial support ?,这里的1x1滤波器的作用是什么?)
此解释仅对1×1过滤器有效。 但是很容易推广到较大的过滤器,例如3×3或5×5。 在这种情况下,非线性映射不在输入图像的补丁上; 相反,它位于特征图的3×3或5×5“补丁”上。 第二层的操作是: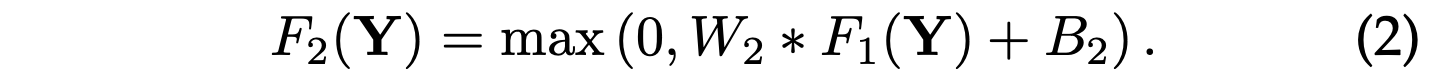
这里W2包含大小为n1×f2×f2的n2个过滤器,而B2是n2维的。 输出的n2维向量中的每个向量在概念上都是将用于重建的高分辨率色块的表示。
可以添加更多的卷积层以增加非线性(卷积操作是线性的,这里应该是指加了激活函数的卷积层)。 但这会增加模型的复杂度(一层的n2×f2×f2×n2参数),因此需要更多的训练时间。 我们将在4.3.3节中介绍其他非线性映射层,以探索更深的结构。
(这里不太理解,为什么non-linear mapping之后,反而feature maps少了呢,特征少了,不应该越高级的特征越多吗?
为什么layer 2输出的就是high-resolution呢?
3.1.3 Reconstruction
在传统方法中,通常将预测的重叠高分辨率色块取平均值,以产生最终的完整图像。 平均可以视为一组特征图上的预定义滤波器(其中每个位置都是高分辨率色标的“平化”矢量形式)。 因此,我们定义了一个卷积层以产生最终的高分辨率图像:
(patch与vector有什么联系?)
(overlapping哪里来的?In the traditional methods,the predicted overlapping high-resolution patches)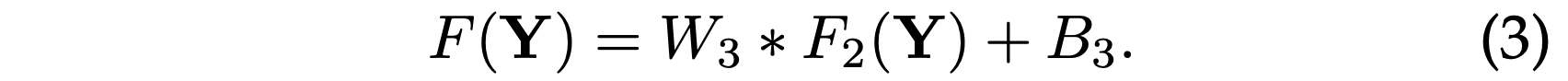
这里W3对应于大小为n2×f3×f3的c个滤波器,而B3是c维向量。
如果高分辨率图像块的表示位于图像域中(即,我们可以简单地对每个表示进行形状调整以形成图像块),我们希望滤波器的作用类似于平均滤波器(就是将多个高分辨率图像块的重叠部分的值取平均值作为该部分的最终结果); 如果高分辨率色块的表示是在其他一些域中(例如,一些基的系数),则我们期望W3的行为类似于首先将系数投影到图像域上然后取平均值(就是将多个高分辨率图像块的重叠部分的值取加权平均值作为该部分的最终结果)。 无论哪种方式,W3都是一组线性滤波器。
有趣的是,尽管以上三个操作是出于不同的直觉,但它们都可指向相同的形式:卷积层。 我们将三个操作放在一起,形成一个卷积神经网络(图2)。 在该模型中,所有过滤权重和偏差都将得到优化。 尽管整体结构简洁,但我们的SRCNN模型还是通过借鉴超分辨率的重大进展而积累的广泛经验而精心开发的[49],[50]。 我们将在下一部分中详细说明这种关系。
3.2 Relationship to Sparse-Coding-Based Methods
——这里只是在比较Sparse-Coding和SRCNN的区别。
高分辨率的图像主要和低分辨率的差异就是在频域上,细节的东西就是高频的信息。
不同的滤波器可能处理的频率不同。
我们表明,基于稀疏编码的SR方法[49],[50]可以看作是卷积神经网络。 如图3所示。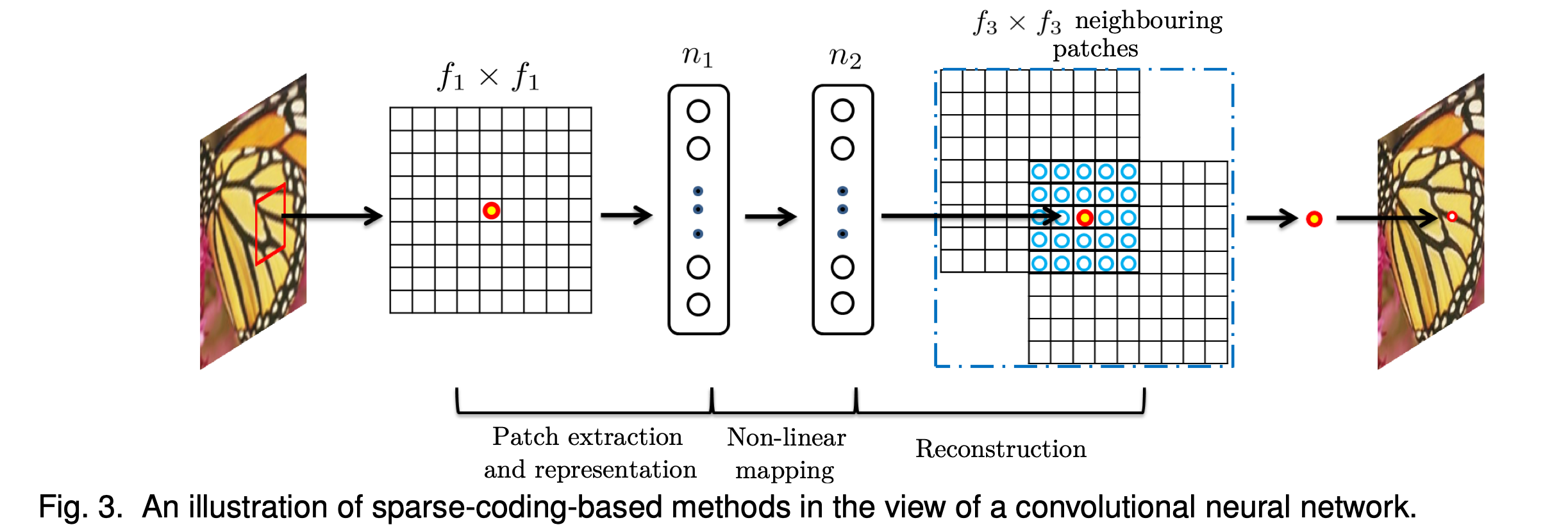
在基于稀疏编码的方法中,让我们考虑从输入图像中提取f1×f1的低分辨率图像块。 然后,像Feature-Sign [29]这样的稀疏编码求解器将首先将补丁投影到(低分辨率)字典上。 如果字典大小为n1(也就是用n1个和图像块相同大小的字典块加权求和来表示图像块),则等效于在输入图像上应用n1个f1×f1的线性滤波器进行卷积(平均减法也是线性运算,因此可以吸收)。如图3的左图所示。
然后,稀疏编码求解器将迭代处理n1个系数。 该求解器的输出为n2个系数(高分辨字典的系数),对于稀疏编码,通常为n2 = n1(为什么?高维的基应该比低维的基数量多呀,系数怎么相等?)。 这n2个系数代表了高分辨率图像块。 从这个意义上讲,稀疏编码求解器的行为类似于非线性映射算法的特殊情况,其空间支持(spatial support,可以理解为卷积核大小)为1×1。 参见图3的中间部分。但是,稀疏编码求解器不是前馈的,即它是一种迭代算法。 相反,我们的非线性算法是完全前馈的,可以有效地计算出来。 如果我们将f2设置为1,则我们的非线性算子可以视为像素级的全连接层。 值得注意的是,SRCNN中的“稀疏编码求解器”指的是前两层,而不仅仅是第二层或激活函数(ReLU)。 因此,通过学习过程也可以很好地优化SRCNN中的非线性运算。
是否可以理解为,我们添加卷积层的目的只是为了增加神经网络的非线性?
3.3 Training
用最小均方误差作为损失函数
我理解的就是,本文就是用卷积核来提取特征,最后用类似于基加系数的方式恢复原图像。
增加多层卷积层的目的是为了增加神经网络的非线性,以至于可以拟合的更好。

若有收获,就点个赞吧
0 人点赞
