https://blog.csdn.net/ch07013224/article/details/80324312
Accurate Image Super-Resolution Using Very Deep Convolutional Networks
https://arxiv.org/abs/1511.04587
We find increasing our network depth shows a signifificant improvement in accuracy.
SRCNN存在3点局限性:
1.依赖较小的图像区域的上下文信息
2.网络训练收敛速度慢
3.网络只能解决单一尺度的图像超分辨率
While SRCNN successfully introduced a deep learning technique into the super-resolution (SR) problem, we find its limitations in three aspects: fifirst, it relies on the context of small image regions; second, training converges too slowly; third, the network only works for a single scale.
因为这里的SRCNN就是简单的3层卷积层,没有采用resnet的方法进行训练,不能采用较大的学习率进行训练。
VDSR提出新的方法来解决这些局限性:
1.更深的网络使用更大的感受野来获取图像上下文信息——关于为什么更深的网络可以提高图像的感受野
2.网络进行残差学习(residual-learning CNN),并且使用极高的学习率,提高收敛(Convergence)速度。采用大学习率,容易遇到梯度消失和梯度爆炸(vanishing/exploding gradients)的问题,这里使用残差学习和可调梯度裁剪技术(adjustable gradient clipping)来抑制梯度问题的产生。
3.一个单一神经网络可以针对不同尺度(Scale Factor)进行图像超分辨率重构
虽然非常深的模型可以提高性能,但现在需要更多的参数来定义一个网络。通常,为每个比例因子创建一个网络。考虑到经常使用分数尺度因子,我们需要一种经济的方法来存储和检索网络。因此,该文还训练了一个多尺度的模型。使用这种方法,参数在所有预定义的尺度因子中共享。训练一个多尺度的模型是很简单的。针对多个特定尺度的训练数据集被组合成一个大数据集。
正如在VDSR论文中作者提到,输入的低分辨率图像和输出的高分辨率图像在很大程度上是相似的,也就是指低分辨率图像携带的低频信息与高分辨率图像的低频信息相近,训练时带上这部分会多花费大量的时间,实际上我们只需要学习高分辨率图像和低分辨率图像之间的高频部分残差即可。残差网络结构的思想特别适合用来解决超分辨率问题,可以说影响了之后的深度学习超分辨率方法。VDSR是最直接明显的学习残差的结构。

但是这里,我从代码中没看出来,代码怎么实现残差学习的……代码都没有做差这个操作。
VDSR于2016年于Jiwon Kim等人所提出。作者主要使用了一种基于VGG-Net的深度卷积网络[使用更小以及更深的卷积核,可以增加模型的拟合能力及非线性],训练时只学习残差,最终得到了极高的学习率(比SRCNN高104倍),并且在图片质量表现上也有很大优势。
作者认为,增加网络的深度会显著提高性能。
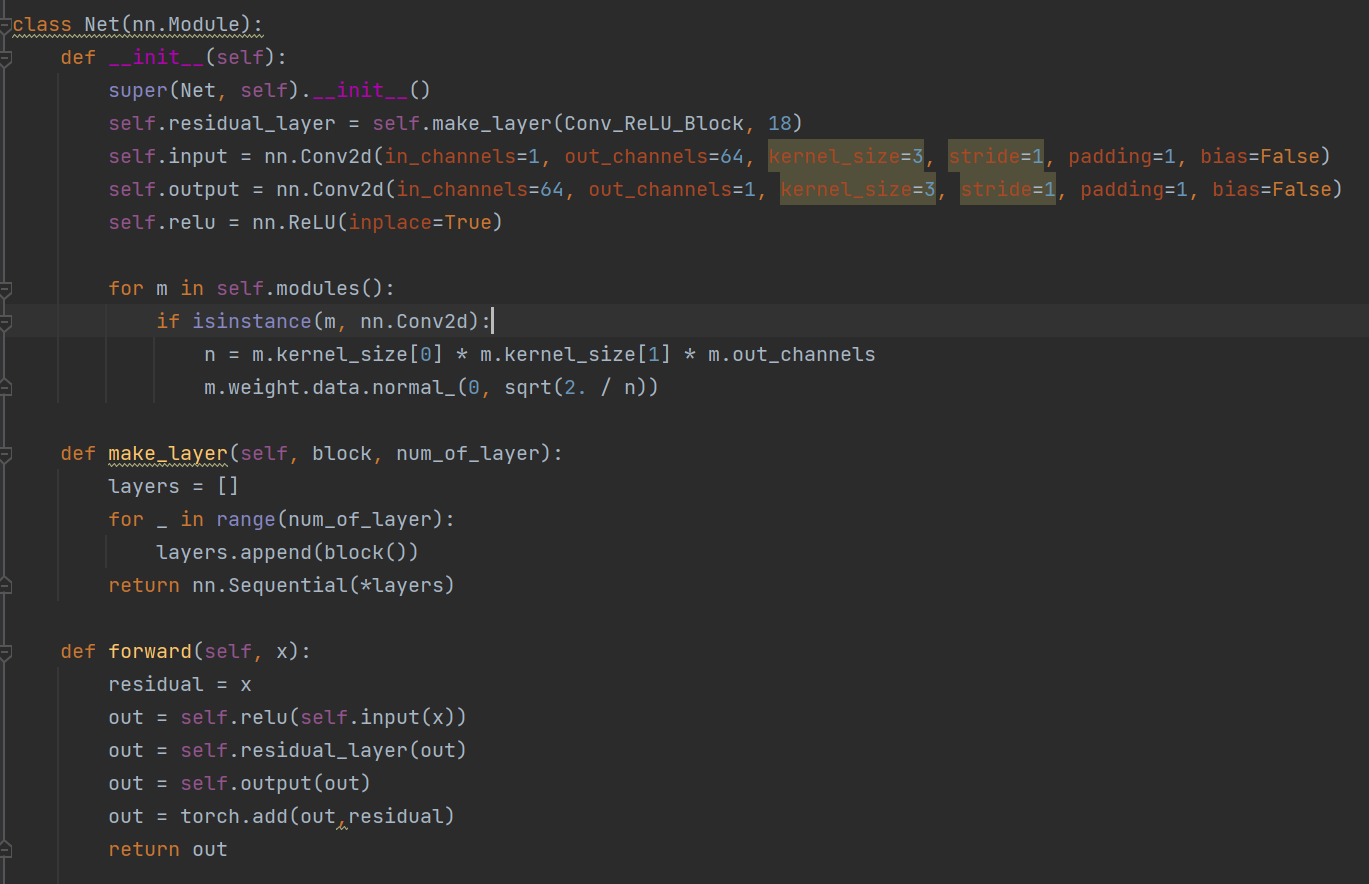
网络模型共有20层,第一层对输入图像进行操作,最后一层用于图像重建。除了第一层和最后一层外,其他卷积层为同一类型:3 × 3 × 64 3×3×64 。
网络将插值后的低分辨率图像(到所需大小)作为输入,再将这个图像与网络学到的残差相加得到最终的网络的输出。
激活函数:ReLU
损失函数:MSE


若有收获,就点个赞吧
0 人点赞
