- Abstract——
- Introduction
- Problem Setting And Terminology
- 3 Supervised Super-Resolution
- 3.1 Super-resolution Frameworks
- 3.1.1 Pre-upsampling Super-resolution
- 3.1.2 Post-upsampling Super-Resolution(没懂)
- 3.1.3 Progressive Upsampling Super-Resolution
- 3.1.4 Iterative Up-and-down Sampling Super-resolution
- 3.2 Upsampling Methods
- 3.3 Network Desigin
- 3.4 Learning Strategies
- 3.5 Other Improvements
- 3.6 State-of-the-art Super-resolution Models
Abstract——
This article aims to provide a comprehensive survey on recent advances of image super-resolution using deep learning approaches. In general, we can roughly group the existing studies of SR techniques into three major categories: supervised SR, unsupervised SR, and domain-specific SR.In addition, we also cover some other important issues, such as publicly available benchmark datasets and performance evaluation metrics.
超分主要有三个领域:有监督超分、无监督超分、特定领域超分
本文探讨的第二个主要话题:公开可用的基准数据集、性能评估指标
Introduction
In general, this problem is very challenging and inherently ill-posed since there are always multiple HR images corresponding to a single LR image.In literature, a variety of classical SR methods have been proposed, including prediction-based methods , edge-based methods , statistical methods , patch-based methods and sparse representation methods etc.
In general, the family of SR algorithms using deep learning techniques differ from each other in the following major aspects: different types of network architectures , different types of loss functions , different types of learning principles and strategies etc.
不同SR算法,主要区别在于:
1、不同的网络结构
2、不同的损失函数
3、不同的学习策略
Unlike the existing surveys, this survey takes a unique deep learning based perspective to review
the recent advances of SR techniques in a systematic and comprehensive manner.
本文将采取深度学习视角,系统全面的介绍了超分技术的进展。
The main contributions of this survey are three-fold:
1)
We give a comprehensive review of image super resolution techniques based on deep learning, including problem settings, benchmark datasets, performance metrics, a family of SR methods with deep learning, domain-specifific SR applications, etc.
2)
We provide a systematic overview of recent advances of deep learning based SR techniques in a
hierarchical and structural manner, and summarize the advantages and limitations of each component
for an effective SR solution.
3)
We discuss the challenges and open issues, and identify the new trends and future directions to
provide an insightful guidance for the community.
1、包括问题设置、基准数据集、性能指标、基于深度学习的图像超分辨率方法、特定领域的图像超分辨率应用等。
2、采用分层和结构化的方式,并总结了各个组件的优点和局限性,寻找有效的SR解决方案
In the following sections, we will cover various aspects of recent advances in image super-resolution with deep learning.
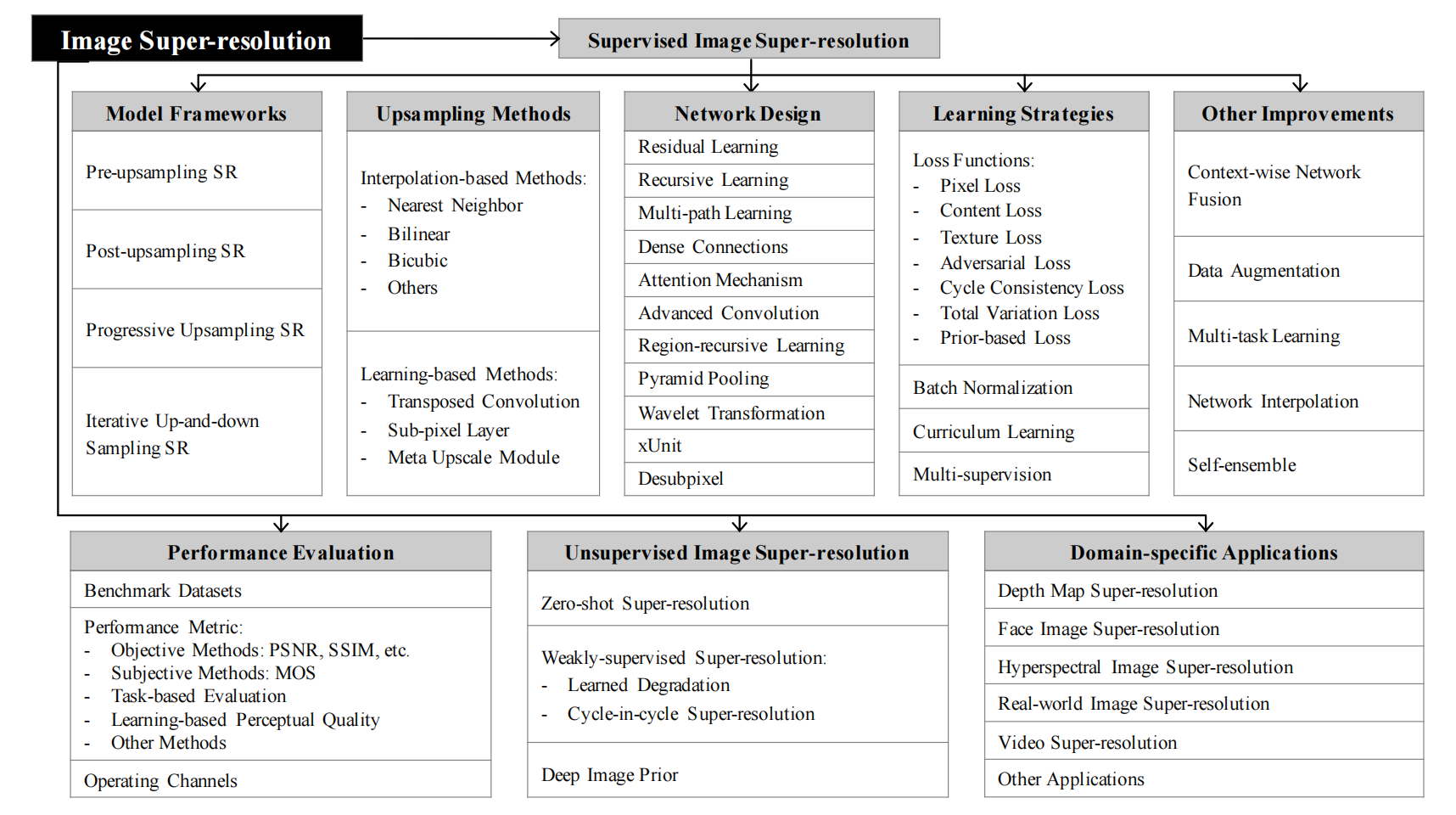
Fig. 1 shows the taxonomy of image SR to be covered in this survey in a hierarchically-structured way.
Section 2 gives the problem defifinition and reviews the mainstream datasets and evaluation metrics. Section 3 analyzes main components of supervised SR modularly.
Section 4 gives a brief introduction to unsupervised SR methods.
Section 5 introduces some popular domain-specifific SR applications, and Section 6 discusses future directions and open issues.
Fig.1以层次结构的方式显示本调查中所涉及的图像超分辨率的分类.
第2部分给出了问题定义并回顾了主流数据集和评估指标。
第3部分对监督超分辨率的主要组成部分进行了模块分析。
第4部分简要介绍了无监督超分辨方法。
第5部分介绍了一些流行的特定领域的SR应用。
第6部分讨论未来的方向和开放的问题
Problem Setting And Terminology
2.1 Problem Definitions
Image super-resolution aims at recovering the corresponding HR images from the LR images. Generally, the LR image Ix _is modeled as the output of the following degradation:

(1)
where _D _denotes a degradation mapping function, _Iy _is the corresponding HR image and δ is the parameters of the degradation process (e.g., the scaling factor or noise). Generally, the degradation process (i.e., _D _and δ) is unknown and only LR images are provided. In this case, also known as blind SR, researchers are required to recover an HR approximation _Iˆy _of the ground truth HR image _Iy _from
_the LR image Ix, following:
(2)
where F _is the super-resolution model and θ denotes the parameters of _F.
Although the degradation process is unknown and can be affected by various factors (e.g., compression artifacts, anisotropic degradations, sensor noise and speckle noise),researchers are trying to model the degradation mapping. Most works directly model the degradation as a single downsampling operation, as follows:

where ↓s _is a downsampling operation with the scaling factor _s
↓s _is a downsampling operation with the scaling factor _s
虽然有很多degration的方法,但是用的最多的就是下采样。
As a matter of fact, most datasets for generic SR are built based on this pattern, and the most commonly used downsampling operation is bicubic interpolation with anti-aliasing. However, there are other works [39] modelling the degradation as a combination of several operations:
where Iy ⊗ κ _represents the convolution between a blur kernel κ and the HR image _Iy, and nς _is some additive white Gaussian noise with standard deviation ς_. Compared to the naive defifinition of Eq. 3, the combinative degradation pattern of Eq. 4 is closer to real-world cases and has been shown to be more benefificial for SR [39].
但是直接用下采样并不能很好的拟合现实生活中的情况,所以我们用模糊核对原图像进行卷积,然后再下采样,再加入高斯白噪声。
To this end, the objective of SR is as follows:
where L(Iˆy, Iy) represents the loss function between the generated HR image Iˆy _and the ground truth image _Iy, Φ(θ) is the regularization term and _λ _is the tradeoff parameter. Although the most popular loss function for SR is pixel-wise mean squared error (i.e., pixel loss), more powerful models tend to use a combination of multiple loss functions, which will be covered in Sec. 3.4.1.
这里都是笼统地介绍参数的训练,具体用什么损失函数并没有说,L1还是L2正规化也没有说,具体使用的时候再看具体的情况。
2.2 Datasets for Super-resolution
Today there are a variety of datasets available for image super-resolution, which greatly differ in image amounts, quality, resolution, and diversity, etc.Some of them provide LR-HR image pairs, while others only provide HR images, in which case the LR images are typically obtained by _imresize _function with default settings in MATLAB (i.e., bicubic interpolation with anti-aliasing).
In Table 1 we list a number of image datasets commonly used by the SR community,and specifically indicate their amounts of HR images, average resolution, average numbers of pixels, image formats,
and category keywords.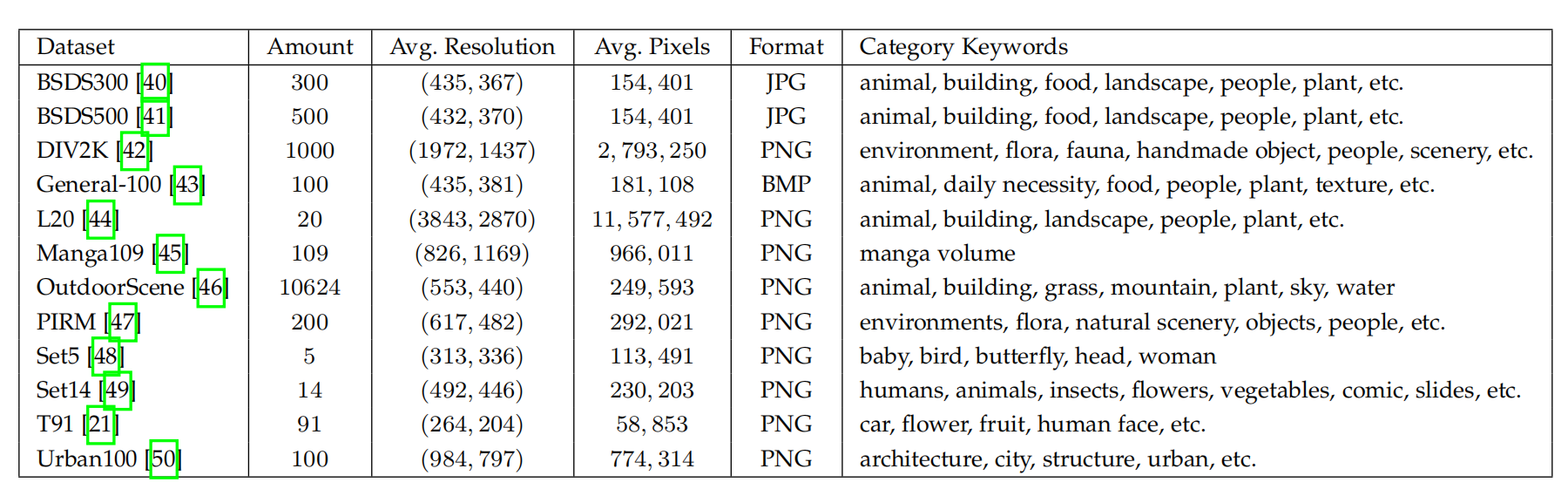
具体的Datasets如何使用,还得参考代码。
2.3 Image Quality Assessment
Image quality refers to visual attributes of images and focuses on the perceptual assessments of viewers. In general, image quality assessment (IQA) methods include subjective methods based on humans’ perception (i.e., how realistic the image looks) and objective computational methods.
图像质量评估分为,主观和客观的评价标准。
The former is more in line with our need but often time-consuming and expensive, thus the latter is currently the mainstream.
我们还是喜欢用机器进行图像质量评估。
In addition, the objective IQA methods are further divided into three types [58]:
1.full-reference methods performing assessment using reference images,
2.reduced-reference methods based on comparisons of extracted features,
3.and no-reference methods (i.e., blind IQA) without any reference images.
Next we’ll introduce several most commonly used IQA methods covering both subjective methods and objective methods.
2.3.1 Peak Signal-to-Noise Ratio
Peak signal-to-noise ratio (PSNR) is one of the most popular reconstruction quality measurement of lossy transformation.(有损变换重构)
For image super-resolution, PSNR is defined via the maximum pixel value (denoted as L) and the mean squared error (MSE) between images.
(PSNR是通过最大像素值和图像之间的均方误差来定义的。)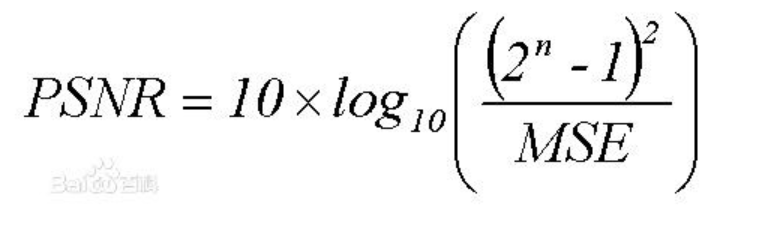
如果均方误差越小,就说明PSNR越大。即图片效果越好。
where _L _equals to 255 in general cases using 8-bit representations. Since the PSNR is only related to the pixel-level MSE, only caring about the differences between corresponding pixels instead of visual perception, it often leads to poor performance in representing the reconstruction quality in
real scenes, where we’re usually more concerned with human perceptions. However, due to the necessity to compare with literature works and the lack of completely accurate perceptual metrics, PSNR is still currently the most widely used evaluation criteria for SR models.
这里说的意思是,PSNR的取值跟像素级有关,一般来说是8级像素。在真实场景种PSNR有可能表现的不是特别好,但是现在也没啥更好的替代方法,所以还是很经常用PSNR做指标。
2.3.2 Stuctural Similarity
Considering that the human visual system (HVS) is highly adapted to extract image structures [59], the structural similarity index (SSIM) [58] is proposed for measuring the structural similarity between images, based on independent comparisons in terms of luminance, contrast, and structures.
由于人的视觉系统可以很好的提取图像的结构,SSIM结构相似度指标,也可以用来测量两张图片之间的相似度,我们可以从亮度、对比度、结构相似度来判断两张图片的相似程度。

现在的情况是,我们知道有这两种方法就好了,真正用的时候我们都是调用API的
psnr = skimage.measure.compare_psnr(im1,im2,255)ssim = skimage.measure.compare_ssim(im1,im2,255)
2.3.3 Mean Opinion Score
Mean opinion score (MOS) testing is a commonly used subjective IQA method, where human raters are asked to assign perceptual quality scores to tested images. Typically, the scores are from 1 (bad) to 5 (good). And the fifinal MOS is calculated as the arithmetic mean over all ratings.
这个就是请志愿者对图片进行主观打分,一共有1到5分,最后取平均值。
2.3.4 Learning-based Perceptual Quality
In order to better assess the image perceptual quality while reducing manual intervention, researchers try to assess the perceptual quality by learning on large datasets.
利用神经网络来学习其他图片的评分标准。
Specififically, Ma et al. [66] and Talebi et al. [67] propose no-reference Ma and NIMA, respectively, which are learned from visual perceptual scores and directly predict the quality scores without ground-truth images. In contrast, Kim et al. [68] propose DeepQA, which predicts visual similarity of images by training on triplets of distorted images, objective error maps, and subjective scores. And Zhang et al. [69] collect a large scale perceptual similarity dataset, evaluate the perceptual image patch similarity (LPIPS) according to the difference in deep features by trained deep networks, and show that the deep features learned by CNNs model perceptual similarity much better than measures without CNNs.
通过CNN学习之后的感知相似度会更好。
Although these methods exhibit better performance on capturing human visual perception, what kind of perceptual quality we need (e.g., more realistic images, or consistent identity to the original image) remains a question to be explored, thus the objective IQA methods (e.g., PSNR, SSIM) are still the mainstreams currently.
现在业内也无法很好的明确,对人类视觉体验效果更好和从数值上的相似度,哪个更加重要,所以大多数的时候,我们还是使用PSNR和SSIM
2.5 Super-resolution Challenges
In this section, we will brieflfly introduce two most popular challenges for image SR, NTIRE and PIRM .
NTIRE Challenge.
The New Trends in Image Restoration and Enhancement (NTIRE) challenge is in conjunction with CVPR and includes multiple tasks like SR, denoising and colorization.
图像恢复和图像增强的新趋势。包括多项任务,如SR、去噪和着色。
For image SR, the NTIRE challenge is built on the DIV2K [42] dataset and consists of bicubic
downscaling tracks and blind tracks with realistic unknown degradation. These tracks differs in degradations and scaling factors, and aim to promote the SR research under both ideal conditions and real-world adverse situations.
通过DIV2K数据集,数据集里面有bicubic downscaling 和一些盲degradation,目的是为了让SR在理想和真实的情况中更好的工作。
PIRM Challenge.
The Perceptual Image Restoration and Manipulation (PIRM) challenges are in conjunction with
ECCV and also includes multiple tasks.
感知图像恢复与与操作(PIRM)挑战相结合ECCV还包括多个任务。
3 Supervised Super-Resolution
These models focus on supervised SR, i.e., trained with both LR images and corresponding HR images.
有监督SR是指,同时给LR和HR来训练。
Although the differences between these models are very large, they are essentially some combinations of a set of components such as model frameworks, upsampling methods, network design, and
learning strategies.
模型框架、上采样方法、网络设计
具体的集成SR方案,就是对这些组件进行排列组合
3.1 Super-resolution Frameworks
现存的SR框架可以分为四类:
pre-upsampling SR, post-upsampling SR,
progressive upsampling SR and iterative up-and-down sampling SR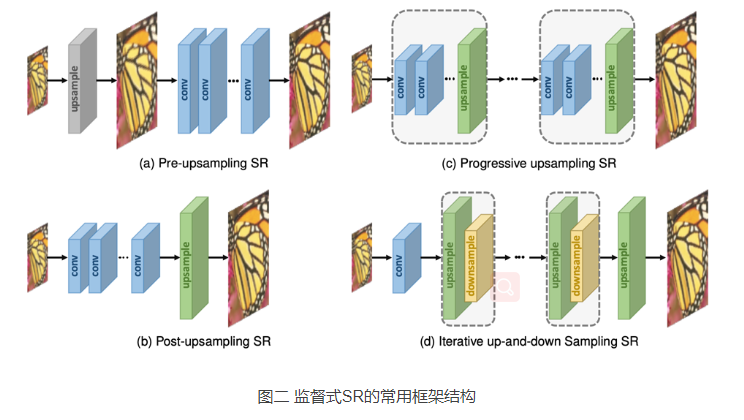
3.1.1 Pre-upsampling Super-resolution
On account of the diffificulty of directly learning the mapping from low-dimensional space to high-dimensional space, utilizing traditional upsampling algorithms to obtain higher resolution images and then refifining them using deep neural networks is a straightforward solution.
方法:利用传统的上采样算法获得更高分辨率的图像,然后使用深度神经网络对其进行细化
Thus Dong et al. [22], [23] fifirstly adopt the pre-upsampling SR framework (as Fig. 2a shows) and propose SRCNN to learn an end-to-end mapping from interpolated LR images to HR images.
Specififically, the LR images are upsampled to coarse HR images with the desired size using traditional methods (e.g., bicubic interpolation), then deep CNNs are applied on these images for reconstructing high-quality details.)
先用传统的bicubic interpolation进行上采样,再用CNN进行细化。
方法:利用传统的上采样算法获得更高分辨率的图像,然后使用深度神经网络对其进行细化
优点:①较困难的上采样任务是通过预定义的传统算法完成的,深度cnn只需要对粗图像进行细化,大大降低了学习难度
②这些模型可以以任意大小和缩放因子的插值图像作为输入并给出与单尺度SR模型性能相当的精确结果
缺点:预先定义的上采样方法通常会引入一些副作用(例如,噪声放大和模糊),而且由于大多数操作是在高维空间中执行的,时间和空间成本比其他框架要高得多
3.1.2 Post-upsampling Super-Resolution(没懂)
目的:为了解决Pre-upsampling SR计算效率问题,充分利用深度学习(DL)技术自动提高图像分辨率
方法:在取代先上采样操作,在低维空间进行mapping操作,然后在最后放置一个端到端可学习的上采样层
优点:计算量大的非线性卷积特征提取过程只发生在低维空间中,并且分辨率只有在网络的最末端才会增加。使得计算复杂度和空间复杂度大大降低,同时训练速度和推理速度也大大提高。
缺点:一方面,上采样操作只有一步,大大增加了大尺度因子的学习难度,
另一方面,每个尺度因子都需要一个单独的SR模型,无法满足多尺度SR的需要
Question:先用神经网络在训练什么?
3.1.3 Progressive Upsampling Super-Resolution
目的:解决后上采样的缺点
方法:该框架下的模型基于串联的cnn,逐步重构出更高分辨率的图像。即:在每一阶段,图像上采样到一个更高的分辨率,并由cnn进行细化
优点:通过将困难task分解为简单task,该框架下的模型不仅极大地降低了学习难度,获得了更好的性能,特别是在large factors的情况下,而且在不引入过多的空间和时间代价的情况下解决了多尺度的超分辨率问题。
缺点:多阶段模型设计复杂,训练难度大,需要更多的设计结构设计指导和更高级的训练策略。
3.1.4 Iterative Up-and-down Sampling Super-resolution
目的:为了更好地捕捉LR-HR图像对的相互依赖性
方法:一种称为back-projection的迭代过程被纳入到SR中用来缩小LR-HR之间的关系。迭代的使用这种过程来进行微调,也就是先计算重建的错误,然后用它来调节HR图像的亮度。这种思想被用来构建了DBPN(deep back-projection networks),结合着上-下采样层,可以交替的在上采样层和下采样层之间互相连通,最终使用中间的HR图像的特征图的串联得到最后的结果。
优点:可以获得LR-HR图像之间深层次的关系,并以此获得更好的重建结果
缺点:对back-projection的设计标准并不明确,结构很复杂,需要手动设计。有很大的探索与改进空间
3.2 Upsampling Methods
上采样:在应用在计算机视觉的深度学习领域,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(e.g.:图像的语义分割),这个采用扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。
3.2.1 Interpolation-based Upsampling
图像插值,又称图像缩放,指的是调整数字图像的大小,几乎被所有与图像相关的应用程序所使用。传统的插值方法有最近邻插值、双线性和双三次插值、Sinc和Lanczos重采样等
Nearest-neighbor Interpolation.
它为每个要插值的位置选择最近的像素值,而不考虑其他像素。因此,这种方法速度很快,但通常会产生块状的结果,质量很差
Bilinear Interpolation.
双线性插值首先在图像的一个轴上执行线性插值,然后再在另一个轴上执行同样操作。两步插值过程如图3所示。虽然每一步采样值和采样位置都是线性的,但得到的接受场大小为2×2的二次插值,在保持较快速度的同时比最近邻插值的性能要好得多。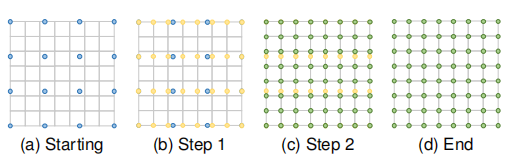
Bicubic Interpolation.
和双线性插值很像,在两个维度上进行三次插值,涉及x了 4×4 的区域,效果更加平滑,但是速度慢点,这种方法也广泛用于构建SR数据集(也就是从HR到LR的生产)以及应用于先上采样SR框架
总的来说,基于插值的上采样方法只是根据图像本身的内容来提高图像的分辨率,而不会带来更多的信息。相反,它们经常在SR模型中引入一些副作用,如计算复杂度、噪声放大、结果模糊等。
3.2.2 Learning-based Upsampling
为了克服基于插值的方法的缺点,以端到端方式学习上采样操作,在超分辨率域中引入了转置卷积层(transposed convolution layer )和亚像素层(sub-pixel layer)。
Transposed Convolution Layer.
转置卷积是一种特殊的正向卷积,先按照一定的比例通过补  来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
图4展示了如何使用 3×3 的卷积核来获得两倍的上采样。新增的像素点设置为0,然后利用一个 3×3 的卷积核(padding=1,stride=1)来执行卷积操作。首先对原图扩大两倍通过这样的操作,将输入特征图的上采样扩大2倍,此时接受视野最大为2x2,
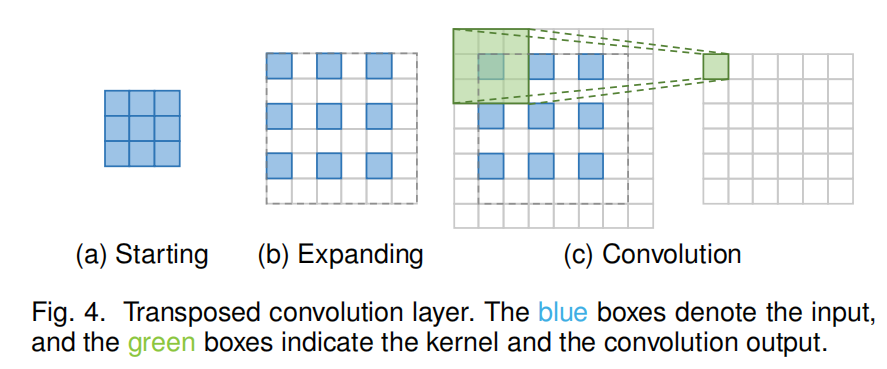
Sub-pixel Layer.
亚像素卷积的原理如图所示,首先对输入图像做卷积处理,生成sxs个特征图(s为上采样因子),然后对sxs个特征图做reshape操作,得到目标图像。(reshape方法如图)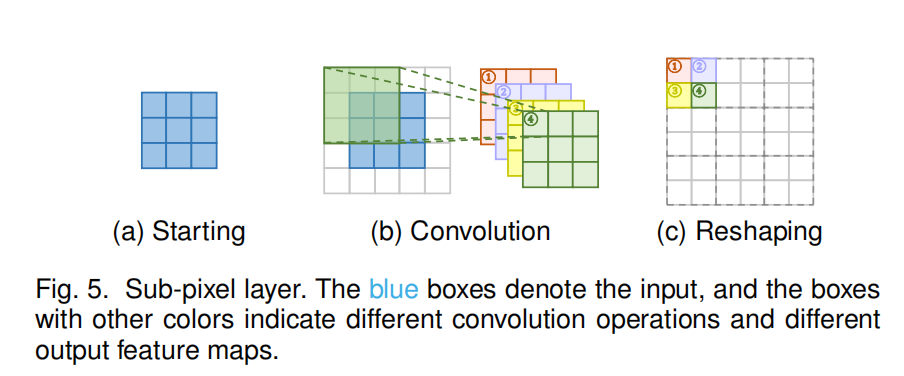
3.3 Network Desigin
In this section, we decompose these networks to essential principles or strategies for network
design, introduce them and analyze the advantages and limitations one by one.
3.3.1 Residual Learning
分为全局残差学习和局部残差学习两种。
Global Residual Learning.
由于图像SR是一种图像到图像的转换任务,其中输入图像与目标图像高度相关,因此我们可以只学习它们之间的残差,这就是全局残差学习。在这种情况下,可以避免学习从一个完整图像到另一个图像的复杂变换,而只需要学习一个残差图来恢复丢失的高频细节。由于大部分区域的残差接近于零,模型的复杂度和学习难度大大降低。
Local Residual Learning.
类似于ResNet中的残差学习,shortcut连接可以用于缓解网络深度不断增加所带来的模型退化问题,降低了训练难度,被广泛应用在超分任务中。
3.3.2 Recursive Learning
为了在不引入过多参数的情况下学习到更高级的特征,递归学习(即以递归方式多次应用相同模块)被应用到超分任务中,如图所示。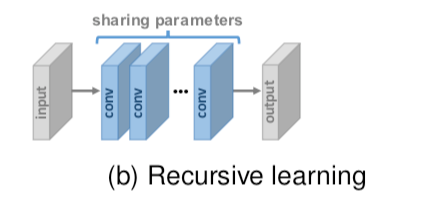
一般来说,递归学习确实可以在不引入过多参数的情况下学习更精细的特征,但仍然无法避免较高的计算成本。它固有地带来了梯度问题的消失或爆炸问题,因此一些技术,如残差学习和多重监督经常与递归学习相结合,以缓解这些问题。
e.g. DRCN、MemNet、CARN、DSRN
3.3.3 Multi-path Learning
多路径学习是指通过多条路径传递特征,每条路径执行不同的操作,将它们的操作结果融合以提供更好的建模能力。具体来说,它可以分为全局、局部和特定规模的多路径学习。
Global Multi-path Learning.
是指利用多条路径来提取图像不同方面的特征,这些路径在传播过程中可以相互交叉,从而大大提高学习能力。(e.g. LapSRN、DSRN)
Local Multi-path Learning.
模块结构如下图所示,在该模块中,采用核尺寸为3×3和5×5的两个卷积层同时提取特征,然后将输出串接并再次进行相同的运算,最后再进行1×1的卷积运算。通过这种局部多路径学习,SR模型可以更好地从多尺度中提取图像特征,进一步提高性能。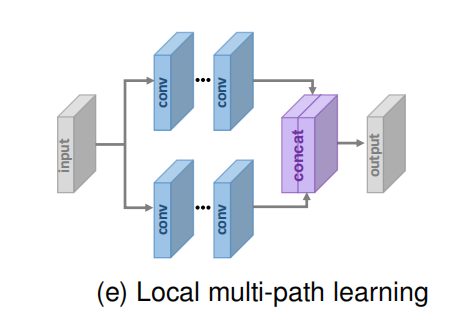
CVPR2020中的CSNLN便是应用了局部多路径学习,将三个通道的信息整合。包括原始的输入(下)、尺度内非局部注意力(中)、跨尺度非局部注意力(上)。
CSNLN: Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
https://ieeexplore.ieee.org/document/9157565
Scale-specifific Multi-path Learning.
考虑到不同尺度的SR模型需要经过相似的特征提取,Lim等人提出了尺度特定的多路径学习方法来实现单网络的多尺度重建。具体地说,它们共享模型的主要组件(即用于特征提取的网络层),并分别在网络的开始和结束处附加特定比例的预处理结构和上采样结构(如图所示)。在训练期间,仅启用和更新与选定比例相对应的模块。这样,所提出的MDSR通过共享不同尺度下的大部分参数,大大减小了模型的规模,并表现出与单尺度模型相当的性能。CARN和ProSR也采用了类似的特定尺度的多路径学习。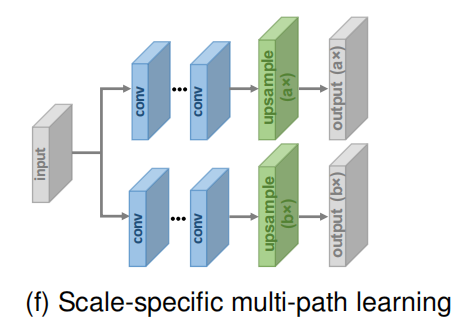
3.3.4 Dense Connections
自从Huang等人提出基于稠密块的DenseNet以来,稠密连接在视觉任务中的应用越来越广泛。对于稠密块体中的每一层,将所有前一层的特征图作为输入,并将其自身的特征图作为输入传递到所有后续层。稠密连接不仅有助于减轻梯度消失、增强信号传播和鼓励特征重用,而且还通过采用小增长率(即密集块中的信道数)和在连接所有输入特征映射后压缩通道数来显著减小模型尺寸。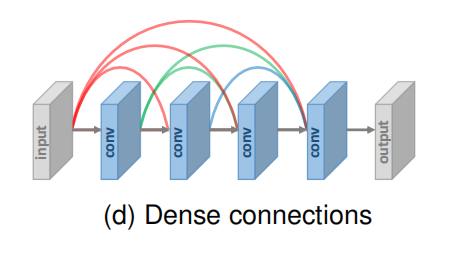
RDN: Residual Dense Network for Image Super-Resolution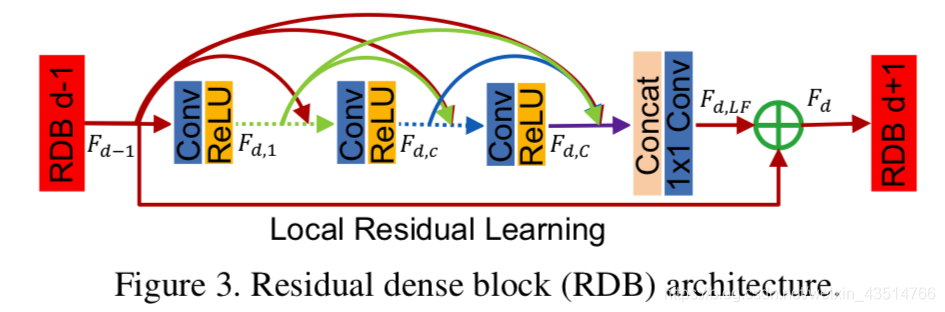
SRDenseNet: Image Super-Resolution Using Dense Skip Connections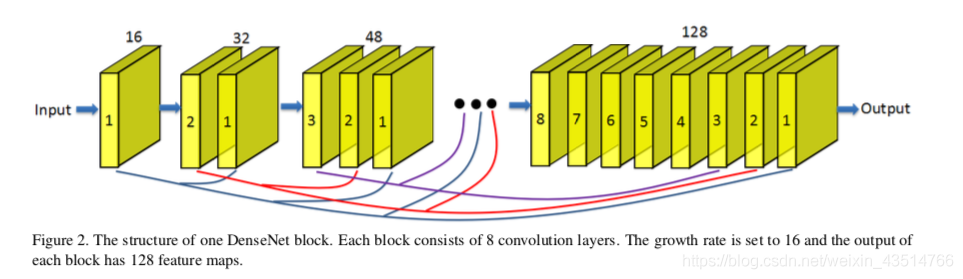
3.3.5 Attention Mechanism
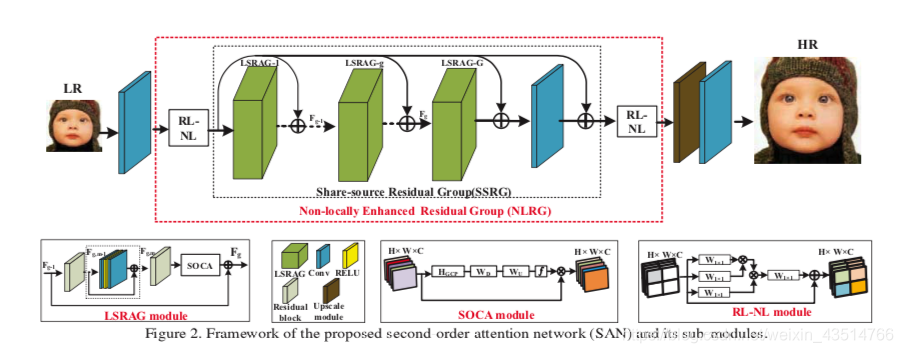
考虑到不同通道之间特征的相互依赖关系,Hu等人提出了SENet,通过考虑通道之间的相互依赖关系来提高网络的学习能力。在该模块中,使用全局平均池化(GAP)将每个输入信道压缩成一个通道描述符(即常数),然后将这些描述符输入到两个密集层中,以产生各通道的权重因子。最近,Zhang等人将通道注意机制应用在超分中,提出了RCAN,显著提高了模型的表达能力。为了更好地探究特征之间的相关性,Dai等人进一步提出二阶通道注意力(SOCA)模块。SOCA通过使用二阶特征统计量代替了全局平均池化,以提取更加精细的特征。
SENet: Squeeze-and-Excitation Networks
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks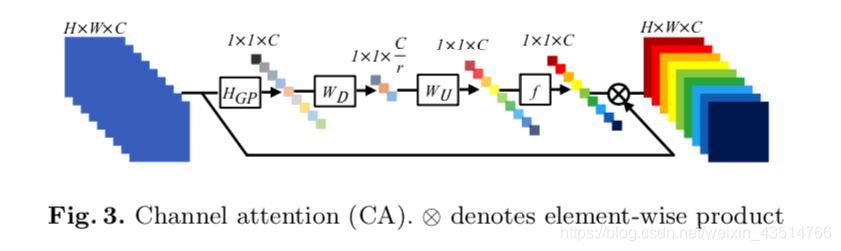
SAN: Second-order Attention Network for Single Image Super-Resolution
CSNLN: Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining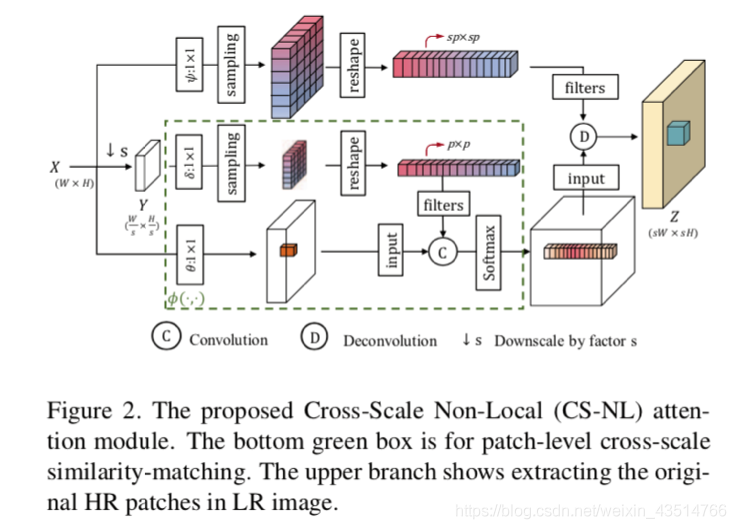
3.4 Learning Strategies
3.4.1 Loss Functions
In the super-resolution fifield, loss functions are used to measure reconstruction error and guide the model optimization.
Pixel Loss.
分为L1损失和L2损失。

在早期,研究者们通常采用L2损失作为模型的损失函数,但后来发现它不能很准确地衡量重建的质量。与L1损失相比,L2损失惩罚较大的error,但对小error的容忍度更高,因此常常导致结果过于平滑。因为PSNR的定义与“对应像素之间的误差”高度相关,最小化像素损失直接使PSNR最大化,像素损失逐渐成为应用最广泛的损失函数。
Content Loss.
衡量不同图像通过预训练的模型后得到的特征图之间的差异,计算图像之间的感知相似性。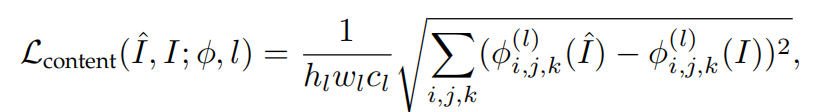
φ是预先训练好的图像分类网络,如VGG、ResNet;l指该网络的第l层。
Texture Loss.
考虑到重建图像应具有与目标图像相同的风格(如颜色、纹理、对比度),将图像纹理视为不同特征通道之间的相关性.
Adversarial Loss.
在生成对抗网络中,判别器被用来判断当前输入信号的真伪,生成器则尽可能产生“真”的信号,以骗过判别器。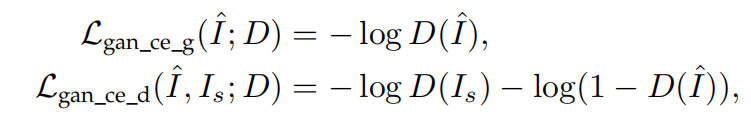
3.4.2 Batch Normalization
为了加速和稳定深部神经网络的训练,Sergey等人提出批量标准化(BN)以减少网络的内部协变量偏移。具体来说,它们对每个小批量执行规范化,并为每个通道训练两个额外的转换参数,以保持表示能力。然而,Lim等人在EDSR中提出BN会丢失每个图像的比例信息,并从网络中去除范围灵活性。此外,由于BN层与前面的卷积层消耗的内存量相同,因此移除BN层后,GPU内存使用量也充分减少。与SRResNet相比,没有批量标准化层的baseline模型在训练期间节省了大约40%的内存使用量。因此,在有限的计算资源下,我们可以建立一个比传统ResNet结构有更好性能的更大的模型。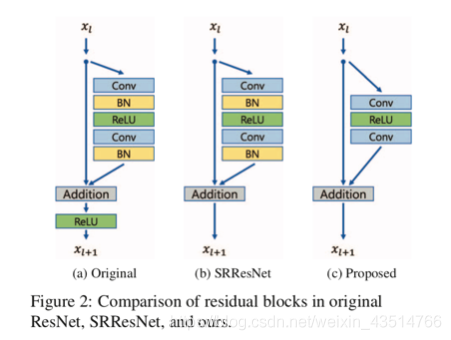
3.5 Other Improvements
3.6 State-of-the-art Super-resolution Models
下表总结了一些有代表性的模型及其关键策略。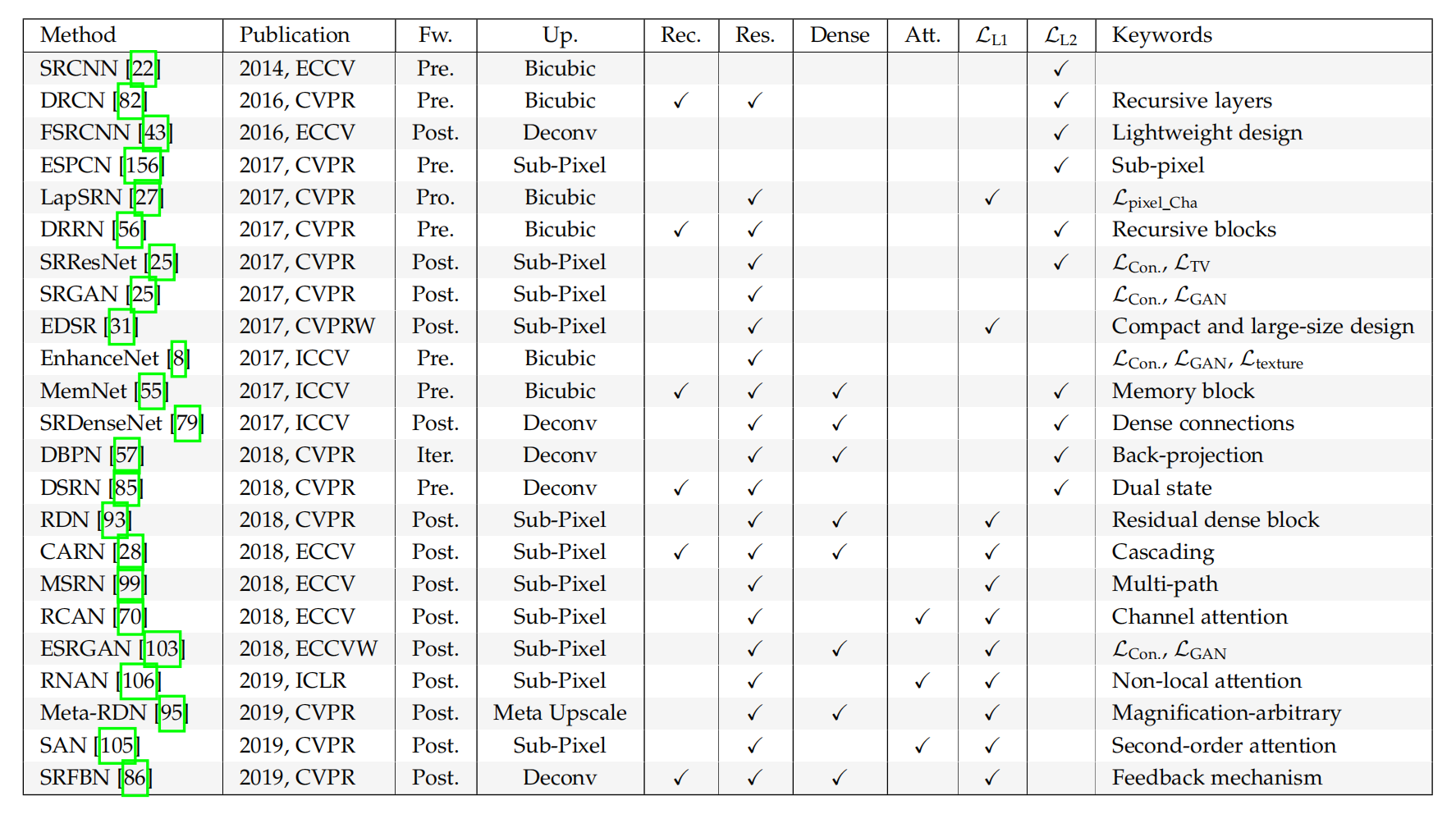

若有收获,就点个赞吧
0 人点赞
