不理解的词目:spatially varying convolution windows是指什么 https://blog.csdn.net/Wenyuanbo/article/details/121264131
Abstract
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low quality images (_e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of
_three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by up to 0.14∼0.45dB, while the total number of parameters can be reduced by up to 67%.
图像复原是一个low-level的计算机视觉任务,把低质量的图像恢复成高质量的图像。在图像恢复领域,之前的state-of-the-art方法一直都是基于卷积神经网络的。随着Transformer框架从NLP领域出圈,Vision Transformer之后,Transformer也开始应用于图像处理领域,并且取得了impressive的成绩在high-level领域。SwinIR这篇文章把专门用于图像领域的Transformer骨干框架SwinTransformer应用到了low-level领域——Image Restoration.
图像复原的主要任务是根据低质量图像还原高质量图像。文章提出了一种基于swin Transformer的模型来对图像进行复原,该模型主要包含三个部分:1,浅层特征提取、2,深层特征提取和 3,高质量图像重建。该模型具有更少的参数和更优的性能。更少的参数和更优的性能也是本篇论文的
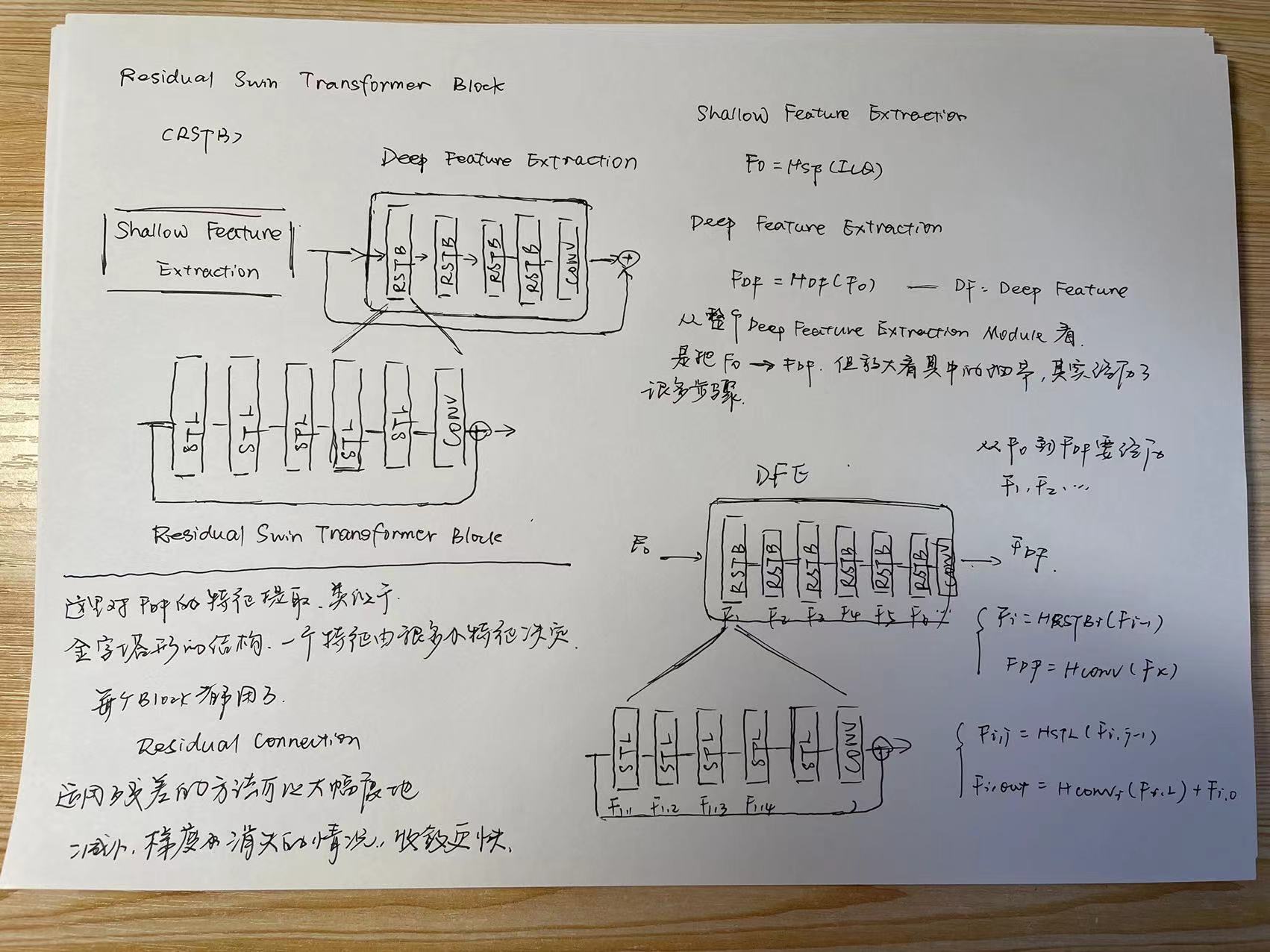
本框架的结构中,深沉特征提取是重点,由Residual Swin Transformer Blocks组成,每个RSTB模块又由Swin Transformer Layers和Residual Connection组成。
1.Introduction
Most CNN-based methods focus on elaborate architecture designs such as residual learning [43, 51] and dense connections [97, 81]. Although the performance is significantly improved compared with traditional model-based methods, they generally suffer from two basic problems that stem from the basic convolution layer.First, the interactions between images and convolution kernels are content-independent.
Using the same convolutional kernel to restore different image regions may not be the best choice.
Second, under the principle of local processing, convolution is not effective for long-range dependency modelling(这是什么东西).
之前都是用CNN以及CNN的优化结构做图像恢复,但是这样的话,会有无法避免CNN带来的两个基本问题。 1.图像和卷积核之间没有联系,用同样的卷积核恢复不同的图像区域可能不是最佳的选择。 2.在局部处理的原则下,卷积对长依赖建模并不有效。 提出CNN的劣势之处,说明本文肯定是要优化CNN的这些毛病。 【不太理解什么叫,1和长依赖建模】
As an alternative to CNN, transformer designs a self-attention mechanism to capture global interactions between contexts and has shown promising performance in seveal vision problems.[6, 74, 19, 56].
相比于CNN,transformer的注意力机制就能很好的捕获全局和上下文之间的联系。
However, vision Transformers for image restoration usually divide the input image into patches with fixed size and process each patch independently.Such a strategy inevitably gives rise to two drawbacks.
本文是使用了swin transformer来做Image Restoration,所以这里介绍了transformer可以很好的捕获全局和上下文之间的联系,但是同时也引出了transformer不足之处。
First, border pixels cannot utilize neighbouring pixels that are out of the patch for image restoration. Second, the restored image may introduce border artifacts around each patch.
首先,边界像素不能利用相邻的像素进行图像恢复。 第二,恢复后的图像可能会在每个patch周围引入边界伪影。
Recently , Swin Transformer has shown great promise as it integrates the advantages of both CNN and Transformer.On the one hand, it has the advantage of CNN to process image with large size due to the local attention mechanism.On the other hand, it has the advantage of Transformer to model long-range dependency with the shifted window scheme.
Swin Transformer结合了CNN和Transformer的优点。 由于CNN的局部注意力机制,它可以处理大范围的图像【是因为Swin Transformer的patch merging操作吗】 由于Transformer的优点,它可以对长范围依赖进行建模(这是啥?)
In this paper,we propose an image restoration model, namely SwinIR, based on Swin Transformer.More specifically, SwinIR consists of three modules : shallow feature extraction , deep feature extraction and high-quality image reconstruction modules.
SwinIR由三个模块组成, shallow feature extraction 浅层特征提取 deep feature extaction 深层特征提取 high quality image reconstruction modules 高质量图片重建模块
Shallow feature extraction module uses a convolution layer to extract shallow feature,which is directly transmitted to the reconstruction module so as to preserve low-frequency information.
浅层特征提取模块采用卷积层提取浅层特征,浅层特征直接传递给重构模块,保留低频信息。
这里采用卷积层,来提取特征,浅层特征就是细节不够多的,一个图片的框架一样的特征,大多数低频信息。
Deep feature extraction module is mainly composed of residual Swin Transformer blocks,each of which utilizes several Swin Transformer layers for local attention and cross-window interaction.
深度特征提取模块主要由残差的Swin Transformer模块组成,每个模块利用几个Swin Transformer层进行局部注意力和跨窗口交互。
In addition, we add a convolution layer at the end of the block for feature enhancement and use a residual connection to provide a shortcut for feature aggregation. Finally, both shallow and deep features are fused in the reconstruction module for high-quality image reconstruction.
我们在块的末尾增加了一个卷积层用于特征增强,并利用一个残差连接为特征聚合提供了一条捷径。 最后,在重建模块中融合浅层和深层特征,实现高质量的图像重建。
Compared with prevalent CNN-based image restoration models, Transformer-based SwinIR has serval benefits:
(1)content-based interactions between image content and attention weights, which can be interpreted as spatially varying convolution.
(2)long-range dependency modelling are enabled by the shifted window mechanism.
(3)better performance with less parameters.
1.图像内容与注意力权重之间基于内容的交互,可以解释为空间变化的卷积。 2.通过移动窗口机制,可以建立长期依赖关系模型。 3.用更少的参数获得更好的性能。

可以看到SwinIR在用了更少的参数的情况下,反而取得了最优的PSNR效果
Introduction主要介绍了SwinIR的模型架构
1.浅层特征提取,通过卷积层直接提取浅层特征,浅层特征直接传递给重构模块,保留低频信息
2.深层特征提取,由Residual Swin Transformer Blocks组成,并且RSTB模块又由SwinTransformerLayer组成。
3.图像重构模块
2.Related Work
2.1 Image Restoration
Compared to traditional image restoration methods [28, 72, 73, 62, 32] which are generally model-based, learning based methods, especially CNN-based methods, have become more popular due to their impressive performance. They often learn mappings between low-quality and high quality images from large-scale paired datasets. Since pioneering work SRCNN [18] (for image SR), DnCNN [90]
(for image denoising) and ARCNN [17] (for JPEG compression artifact reduction), a flflurry of CNN-based models have been proposed to improve model representation ability by using more elaborate neural network architecture designs, such as residual block [40, 7, 88], dense block [81, 97, 98] and others [10, 42, 93, 78, 77, 79, 50, 48, 49, 92, 70, 36, 83, 30, 11, 16, 96, 64, 38, 26, 41, 25]. Some of them have exploited the attention mechanism inside the CNN framework, such as channel attention [95, 15, 63], non-local attention [52, 61] and adaptive patch aggregation [100].
传统的图像恢复方法,都是采用从low-quality到high-quality图像的映射。 在CNN的基础上做Image Restoration,现在都是通过使用更加精细的神经网络结构,比如说residual block dense block 但有一些也引入了注意力机制,比如说,channel attention,non-local attention,adaptive patch aggregation
2.2 Vision Transformer
Recently, natural language processing model Transformer has gained much popularity in the computer vision community.When used in vision problems such as image classification, object detection, segmentation and crowd counting, it learns to attend to important image regions by exploring the global interactions between different regions(Transformer最早是用在NLP上的,但是我不知道如何使用它来进行图像处理,重点在于Transformer的注意力机制,可以观察到不同区域之间的关联。exploring the global interactions between different regions.).Due to its impressive performance, Transformer has also been introduced for image restoration [9, 5, 82]. Chen et al. [9] proposed a backbone model IPT for various restoration problems based on the standard Transformer.However, IPT relies on large number of
parameters (over 115.5M parameters), large-scale datasets over 1.1M images) and multi-task learning for good performance.(虽然Transformer在图像处理上效果不错,但是它的训练参数和训练集太大了)
Cao et al. [5] proposed VSR-Transformer that uses the self-attention mechanism for better feature fusion in video SR, but image features are still extracted from CNN(这个image features由CNN提取会有什么问题吗?). Besides, both IPT and VSR-Transformer are patch-wise attention, which may be improper for image restoration. In addition, a concurrent work [82] proposed a U-shaped architecture based on the Swin Transformer [56].
Transformer之前是用在NLP领域的,Transformer核心的地方就是在于可以利用attention machanism找到输入之间的联系。现在通过Transformer来观察不同区域之间的联系,也可以把Transformer用于计算机视觉领域。Transformer在Image Restoration上效果挺好,但是目前的Transformer参数太大。IPT和VSR-Transformer都不太适用于图像恢复。Swin Transformer会比较好适配于Image Restoration
相关工作的话,主要是介绍了
1.在引入Transformer之前,大家都是用CNN来做Image Restoration,通过不断地优化CNN的网络结构来实现。比如说residual connection和dense connection
2.Vision Transformer首先把transformer引入了CV领域,但ViT的结构会导致计算量比较大,使用比较有局限性。但留给了后人遐想的空间。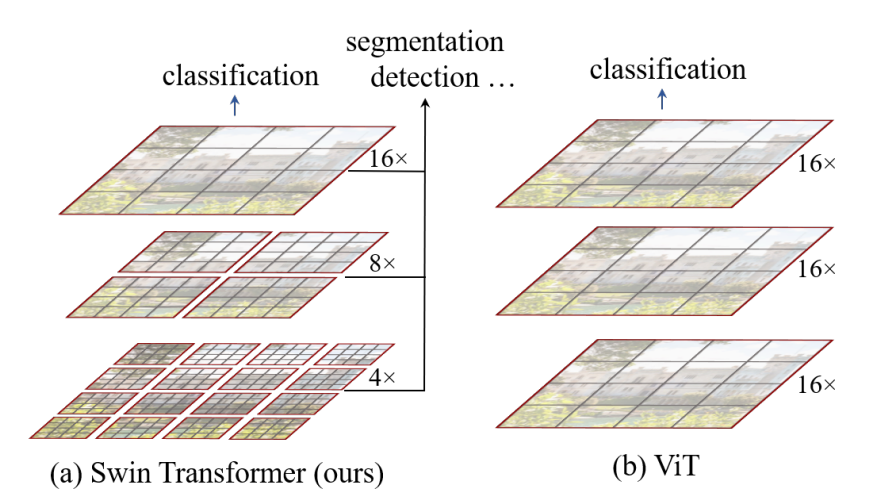
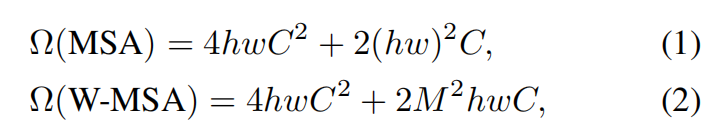
3. Method
3.1 Network Architecture
SwinIR consists of three modules: shallow feature extraction, deep feature extraction and high-quality(HQ) image reconstruction modules.We employ the same feature extraction modules for all restoration tasks, but use different reconstruction modules for different tasks.(这里的模块是指什么?)
Shallow and deep feature extraction.
Given a low-quality (LQ) input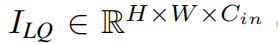 (H, W _and _Cin _are the image height, width and input channel number, respectively), we use a 3 × _3 convolutional layer
(H, W _and _Cin _are the image height, width and input channel number, respectively), we use a 3 × _3 convolutional layer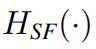 to extract shallow feature
to extract shallow feature 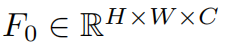 as
as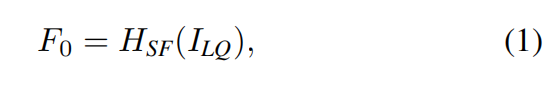
where _C _is the feature channel number. The convolution layer is good at early visual processing, leading to more stable optimization and better results [86]. It also provides a simple way to map the input image space to a higher dimensional feature space.
SwinIR的浅层特征提取,使用了HSF这样一个卷积层来提取。F0为浅层特征。
Then, we extract deep feature 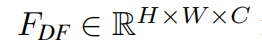 from F_0 as
from F_0 as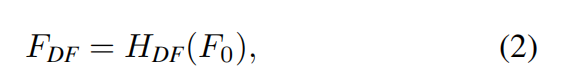
where 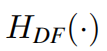 is the deep feature extraction module and it contains _K _residual Swin Transformer blocks (RSTB) and a 3 × 3 convolutional layer. More specififically, intermediate features _F_1, F2, . . . , FK and the output deep feature
is the deep feature extraction module and it contains _K _residual Swin Transformer blocks (RSTB) and a 3 × 3 convolutional layer. More specififically, intermediate features _F_1, F2, . . . , FK and the output deep feature 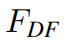 are extracted block by block as
are extracted block by block as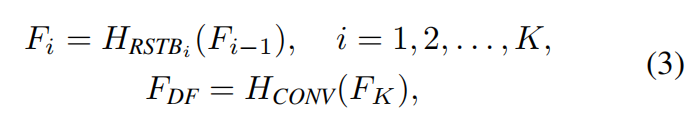
where _HRSTBi (·) denotes the i-th RSTB and 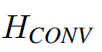 _ _is the last convolutional layer.Using a convolutional layer at the end of feature extraction can bring the inductive bias of the convolution operation into the Transformer-based network, and lay a better foundation for the later aggregation of shallow and deep features.
_ _is the last convolutional layer.Using a convolutional layer at the end of feature extraction can bring the inductive bias of the convolution operation into the Transformer-based network, and lay a better foundation for the later aggregation of shallow and deep features.
深层特征提取以黑盒的角度看的化,就是浅层特征F0,输入到Deep Feature Extraction这样一个Module之后输出FDF的深层特征。 Deep Feature Extraction里面的结构主要是由RSTB和STL组成的。

Image reconstruction
Taking image SR as an example, we reconstruct the high-quality image 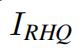 _ _by aggregating
_ _by aggregating
shallow and deep features as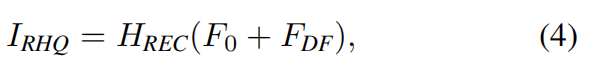
where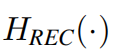 is the function of the reconstruction module(这里的reconstruction module如何理解?). Shallow feature mainly contain low-frequencies, while deep feature focus on recovering lost high-frequencies.With a long skip connection, SwinIR can transmit the low frequency information directly to the reconstruction module, which can help deep feature extraction module focus on high-frequency information and stabilize training(什么是stabilize training). For the implementation of reconstruction module, we use the sub-pixel convolution layer(什么是亚像素层) [68] to upsample the feature.
is the function of the reconstruction module(这里的reconstruction module如何理解?). Shallow feature mainly contain low-frequencies, while deep feature focus on recovering lost high-frequencies.With a long skip connection, SwinIR can transmit the low frequency information directly to the reconstruction module, which can help deep feature extraction module focus on high-frequency information and stabilize training(什么是stabilize training). For the implementation of reconstruction module, we use the sub-pixel convolution layer(什么是亚像素层) [68] to upsample the feature.
上面的公式,
是专门给超分使用的,超分领域的问题才需要用到,Lost high-frequencies。这里用了一个skip connection直接把低频和高频信号加起来,实现超分。
For tasks that do not need upsampling, such as image denoising and JPEG compression artifact reduction, a single convolution layer is used for reconstruction. Besides, we use residual learning to reconstruct the residual between the LQ and the HQ image instead of the HQ image. This is
formulated as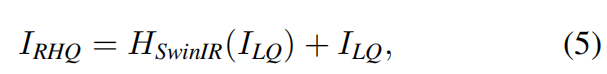
where 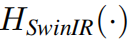 denotes the function of SwinIR.
denotes the function of SwinIR.
对于不需要上采样的任务,我们采用残差连接来重建。这里用LQ和HQ之间的残差来代替HQ 上一个需要上采样的任务是,对F0和FDF进行long skip connection,这里是直接Low-Quality,不一样的。
Loss function.
For image SR, we optimize the parameters of SwinIR by minimizing the L_1 pixel loss.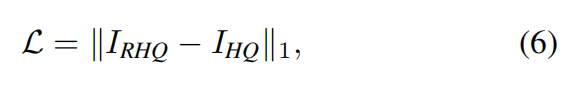
where 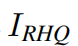 is obtained by taking
is obtained by taking 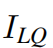 as the input of SwinIR, and
as the input of SwinIR, and 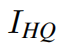 _is the corresponding ground-truth HQ image. For classical and lightweight image SR, we only use the naive L1 pixel loss as same as previous work to show the effiectiveness of the proposed network. For real-world image SR,
_is the corresponding ground-truth HQ image. For classical and lightweight image SR, we only use the naive L1 pixel loss as same as previous work to show the effiectiveness of the proposed network. For real-world image SR,
we use a combination of pixel loss, GAN loss and perceptual loss [81, 89, 80, 27, 39, 81] to improve visual quality.
对于传统的和轻量级的图像超分任务,一般使用L1 pixel loss。对于现在的一些现实的SR任务,我们会使用多种损失函数的结合,比如说GAN loss , perceptual loss
For image denoising and JPEG compression artifact reduction, we use the Charbonnier loss [8] 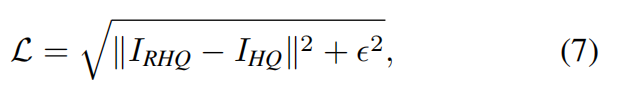
where 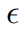 is a constant that is empirically set to
is a constant that is empirically set to  .
.
3.2 Residual Swin Transformer Block【重点】
As shown in Fig. 2(a), the residual Swin Transformer block (RSTB) is a residual block with Swin Transformer layers (STL) and convolutional layers. Given the input feature Fi,_0 of the _i-th RSTB, we fifirst extract intermediate features Fi,_1, Fi,2, . . . , Fi,L by _L _Swin Transformer layers as 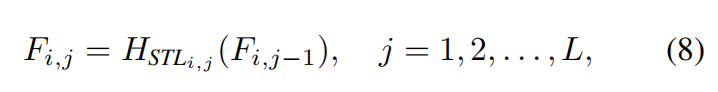
where 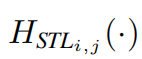 is the _j-th Swin Transformer layer in the i-th RSTB. Then, we add a convolutional layer before the residual connection. The output of RSTB is formulated as
is the _j-th Swin Transformer layer in the i-th RSTB. Then, we add a convolutional layer before the residual connection. The output of RSTB is formulated as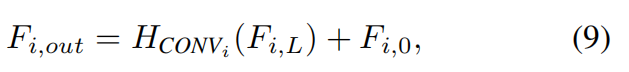
where 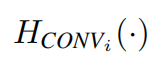 is the convolutional layer in the i-th RSTB.
is the convolutional layer in the i-th RSTB.
上面这个图是SwinIR的工作流程,主要是Deep Feature Extraction的工作流程,主要解释了其中的Residual Swin Transformer Block的工作方法。特征提取类似于金字塔形状的层层提取。都采用残差连接是为了让梯度更快的收敛。用了Residual Connection之后只会更好不会更坏,因为是identity
This design has two benefifits. First, although Transformer can be viewed as a specific instantiation of spatially varying convolution [21, 75],(关于transformer和spatially varying convolution的关系我还不是很理解) convolutional layers with spatially invariant filters can enhance the translational equivariance of SwinIR.(不太理解这里的spatially invariant filter和translational equivariance of SwinIR的具体意思,为什么要计算方差?) Second, the residual connection provides a identity-based connection from different blocks to the reconstruction module, allowing the aggregation of different levels of features.
1虽然Transformer可以被看作是空间变化卷积的具体实例[21,75],但使用空间不变滤波器的共卷积层可以增强SwinIR的平移等方差。[这个不太理解] 2.残差连接提供了从不同块到重构模块的同一连接,允许不同级别的特征聚合。
Swin Transformer layer
Swin Transformer layer (STL) [56] is based on the standard multi-head self-attention(这里需要复习一下multi-head self-attention) of the original Transformer layer [76]. The main differences lie in local attention and the shifted window mechanism.
主要区别在于地方关注和窗口机制的转移。不太理解,什么叫做窗口机制的转移。 这里的Windows是什么意思呢。
As shown in Fig. 2(b), given an input of size H × W × C, Swin Transformer first reshapes the input to
a 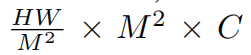 feature by partitioning the input into non-overlapping
feature by partitioning the input into non-overlapping 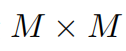 _local windows(这里好像是窗口一定要是正方形?), where
_local windows(这里好像是窗口一定要是正方形?), where 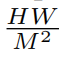 is the total number of windows. Then, it computes the standard self-attention separately for each window (_i.e., local attention). For a local window feature
is the total number of windows. Then, it computes the standard self-attention separately for each window (_i.e., local attention). For a local window feature 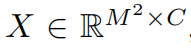 , the query, key _and _value _matrices _Q, K _and _V _are computed as
, the query, key _and _value _matrices _Q, K _and _V _are computed as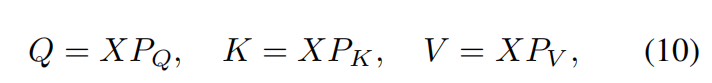
where _PQ, PK _and _PV _are projection matrices that are shared across different windows. Generally, we have _Q, K, V ∈ _R_M_2×d _. The attention matrix is thus computed by the self-attention mechanism in a local window as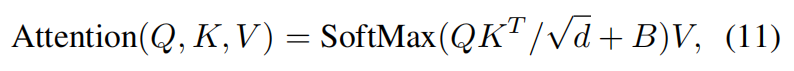
where _B _is the learnable relative positional encoding. In practice, following [76], we perform the attention function for _h _times in parallel and concatenate the results for multi head self-attention (MSA)(注意力机制的用处到底是啥,效果是啥,找到两个地方的关联吗,这里的输出的X是结合上下文的X).
Next, a multi-layer perceptron (MLP) that has two fully connected layers with GELU non-linearity between them is used for further feature transformations. The LayerNorm (LN) layer is added before both MSA and MLP, and the residual connection is employed for both modules. The whole process is formulated as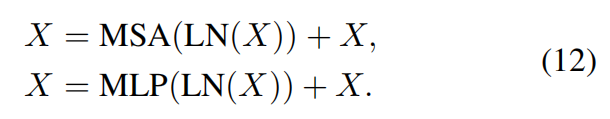
这里的MSA好像是为了把输入之间关联起来,引入Multi Self-Attention,可以关注到输入与上下文之间的多种关系。 MLP,Multi-layer Perceptron 好像是为了,给系统引入非线性。加强拟合能力。 这里的LayerNorm是Transformer常用的一种归一化方法,目的是Norm了以后可以加大learning rate加快训练速度。
However, when the partition(这里的partition指什么) is fixed for different layers, there is no connection across local windows. Therefore, regular and shifted window partitioning are used alternately to enable cross-window connections [56], where shifted window partitioning means shifting the feature by 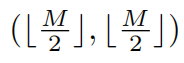 pixels before partitioning.
pixels before partitioning.
(我理解的windows好像是卷积窗口一样的东西,只是给attention用的)
我不太理解,为什么要这样来设计SwinIR的Deep Feature Extraction,RSTB不就是很多个Swin Transformer Block连在一起吗……如果直接用很多个Swin Transformer连在一起和这样设计有什么区别呢?
5. Conclusion
In this paper, we propose a Swin Transformer-based image restoration model SwinIR. The model is composed of three parts: shallow feature extraction, deep feature extraction and HR reconstruction modules. In particular, we use a stack of residual Swin Transformer blocks (RSTB) for deep feature extraction, and each RSTB is composed of Swin Transformer layers, convolution layer and a residual connection. Extensive experiments show that SwinIR achieves state-of-the-art performance on three representative image restoration tasks and six different settings: classic image SR, lightweight image SR, real-world image SR, grayscale image denoising, color image denoising and JPEG compression artifact reduction, which demonstrates the effectiveness and generalizability of the proposed SwinIR.
In the future, we will extend the model to other restoration tasks such as image deblurring and deraining.

若有收获,就点个赞吧
0 人点赞
