NIPS-2012-imagenet-classification-with-deep-convolutional-neural-networks-Paper.pdf
AlexNet是经典的论文,但是我们要从现在的角度看,看看AlexNet当时对技术的选择,是否还是对的。 当时有很多技术细节从现在的角度来看是不必要的,而且是有点过度的enginering的。
Introduction
论文的第一段通常是在讲一个故事,我们在做什么方向的研究,什么的方向,然后为什么这个方向很重要。
Current approaches to object recognition make essential use of machine learning methods. To improve their performance, we can collect larger datasets, learn more powerful models, and use better techniques for preventing overfifitting.
过拟合在深度学习中是一个派别,通常是使用正则化来避免过拟合,但是在之后的研究中发现,是否使用正则化并不是最关键的因素,最关键的因素在于我们的模型是如何设计的。
To learn about thousands of objects from millions of images, we need a model with a large learning
capacity. However, the immense complexity of the object recognition task means that this problem cannot be specifified even by a dataset as large as ImageNet, so our model should also have lots
of prior knowledge to compensate for all the data we don’t have. Convolutional neural networks
(CNNs) constitute one such class of models [16, 11, 13, 18, 15, 22, 26]. Their capacity can be controlled by varying their depth and breadth, and they also make strong and mostly correct assumptions
about the nature of images (namely, stationarity of statistics and locality of pixel dependencies).
Thus, compared to standard feedforward neural networks with similarly-sized layers, CNNs have
much fewer connections and parameters and so they are easier to train, while their theoretically-best
performance is likely to be only slightly worse.
Despite the attractive qualities of CNNs, and despite the relative effificiency of their local architecture,
they have still been prohibitively expensive to apply in large scale to high-resolution images. Luckily, current GPUs, paired with a highly-optimized implementation of 2D convolution, are powerful
enough to facilitate the training of interestingly-large CNNs, and recent datasets such as ImageNet
contain enough labeled examples to train such models without severe overfifitting.
The specifific contributions of this paper are as follows: we trained one of the largest convolutional
neural networks to date on the subsets of ImageNet used in the ILSVRC-2010 and ILSVRC-2012
competitions [2] and achieved by far the best results ever reported on these datasets. We wrote a
highly-optimized GPU implementation of 2D convolution and all the other operations inherent in
training convolutional neural networks, which we make available publicly1 . Our network contains
a number of new and unusual features which improve its performance and reduce its training time,
which are detailed in Section 3. The size of our network made overfifitting a signifificant problem, even
with 1.2 million labeled training examples, so we used several effective techniques for preventing
overfifitting, which are described in Section 4. Our fifinal network contains fifive convolutional and
three fully-connected layers, and this depth seems to be important: we found that removing any
convolutional layer (each of which contains no more than 1% of the model’s parameters) resulted in
inferior performance.
作者最大的贡献就是提出了一个效果很好的模型,比以前的都好。但是使用GPU训练的。因为训练量很大。第三章和第四章讲作者的创新点。
The Dataset
ImageNet is a dataset of over 15 million labeled high-resolution images belonging to roughly 22,000
categories. The images were collected from the web and labeled by human labelers using Amazon’s Mechanical Turk crowd-sourcing tool. Starting in 2010, as part of the Pascal Visual Object
Challenge, an annual competition called the ImageNet Large-Scale Visual Recognition Challenge
(ILSVRC) has been held. ILSVRC uses a subset of ImageNet with roughly 1000 images in each of
1000 categories. In all, there are roughly 1.2 million training images, 50,000 validation images, and
150,000 testing images.
ILSVRC-2010 is the only version of ILSVRC for which the test set labels are available, so this is
the version on which we performed most of our experiments. Since we also entered our model in
the ILSVRC-2012 competition, in Section 6 we report our results on this version of the dataset as
well, for which test set labels are unavailable. On ImageNet, it is customary to report two error rates:
top-1 and top-5, where the top-5 error rate is the fraction of test images for which the correct label
is not among the fifive labels considered most probable by the model.
ImageNet consists of variable-resolution images, while our system requires a constant input dimensionality. Therefore, we down-sampled the images to a fifixed resolution of 256 × _256. Given a
rectangular image, we fifirst rescaled the image such that the shorter side was of length 256, and then
cropped out the central 256×_256 patch from the resulting image. We did not pre-process the images
in any other way, except for subtracting the mean activity over the training set from each pixel. So
we trained our network on the (centered) raw RGB values of the pixels.
在ImageNet的分类中,2010年之前的比赛,ILSVRC之前是提供测试集的,但是2012之后的比赛就只有最后的比赛结果了。在这篇文章中作者用了不知道什么方法,raw RGB values of the pixel,其实这是现在很流行的一种端到端的方法,在之前特征是需要大家自己去提取的,但是现在的神经网络自己会提取特征。
The Architecture
The architecture of our network is summarized in Figure 2. It contains eight learned layers —
fifive convolutional and three fully-connected. Below, we describe some of the novel or unusual
features of our network’s architecture. Sections 3.1-3.4 are sorted according to our estimation of
their importance, with the most important fifirst.
3.1 ReLU Nonlinearity
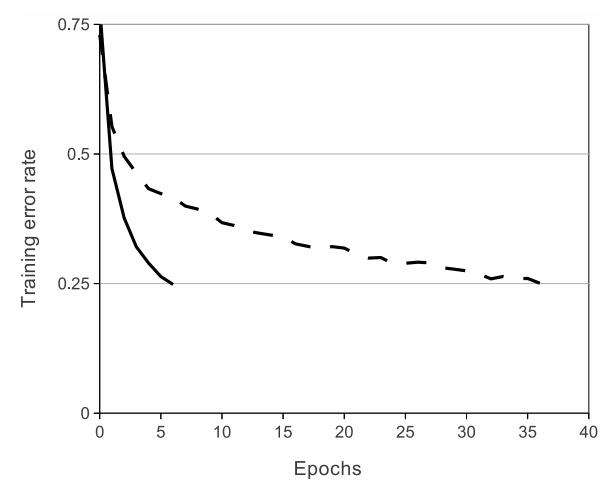
用ReLU的时候,训练的速度会更快。但是现在来看其实用ReLU并不会快特别多,但是为什么还是那么多人用ReLU呢,纯粹是因为ReLU的原理很简单。
3.2 Training on Multiple GPUs
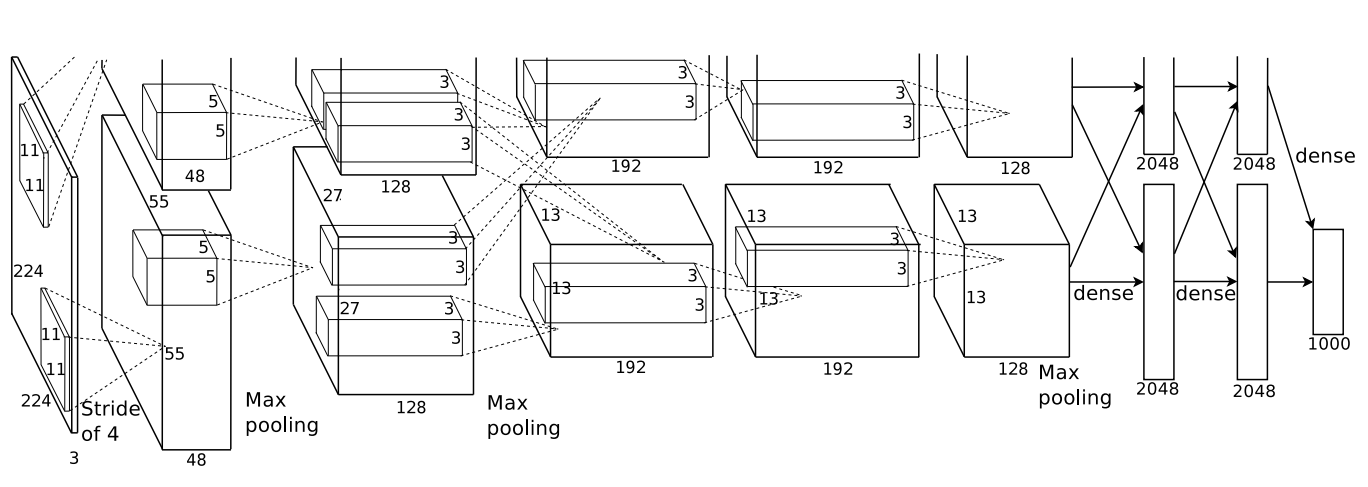
这里的意思是通过卷积,来加深每一层的深度,最后通过全连接层,输出一个4096维度的向量,这个4096的向量再经过线性分类器。这里的4096维向量就很好的表达了语义相关的问题。
如果两张图片的4096向量十分相近,其实很有可能hi是相同的相片。
4. Reducing Overfitting
Our neural network architecture has 60 million parameters. Although the 1000 classes of ILSVRC
make each training example impose 10 bits of constraint on the mapping from image to label, this
turns out to be insuffificient to learn so many parameters without considerable overfifitting. Below, we
describe the two primary ways in which we combat overfifitting.
4.1 Data Augumentation

若有收获,就点个赞吧
0 人点赞
