https://blog.csdn.net/smartempire/article/details/21406005
https://blog.csdn.net/smartempire/article/details/22938315
背景:
自上世纪70年代以来,人脸识别已成为计算机视觉和生物识别技术研究的热点之一。基于手工特征的传统方法和传统的机器学习技术最近已经被用非常大的数据集训练的深度神经网络所取代。本文综述了当前流行的人脸识别方法,包括传统的(基于几何的、整体的、基于特征的和混合的)和深度学习方法。
人脸识别介绍:
1.实验目的
(依据需求制定至少三条,包括实验完成目标和学生培养目标)
1.
2.实验原理(尽可能详细)
2.1 问题背景描述
人脸识别是指能够在图像或视频中识别或验证主体身份的技术。自从70年代第一个人脸识别算法被提出以来,人脸识别的准确性得到了提高,如今人脸识别往往比传统上被认为更健壮的其他生物识别方式(如指纹或虹膜识别[3])更受青睐。使人脸识别比其他生物识别方式更具吸引力的差异因素之一是其非侵入性。例如,指纹识别需要用户将手指放入传感器,虹膜识别需要用户明显靠近摄像头,扬声器识别需要用户大声说话。相比之下,现代的人脸识别系统只要求用户在摄像头的视野范围内(前提是他们与摄像头的距离在合理范围内)。这使得人脸识别成为用户最友好的生物识别方式。这也意味着人脸识别的潜在应用范围更广,因为它可以部署在用户不希望与系统合作的环境中,比如监控系统。人脸识别的其他常见应用包括访问控制、欺诈检测、身份验证和社交媒体。
由于人脸图像在现实世界中的高变异性(这些类型的人脸图像通常被称为野外人脸),在不受约束的环境中部署时,人脸识别是最具挑战性的生物识别方式之一。这些变化包括头部姿势、衰老、遮挡、光照条件和面部表情。
人脸识别技术已经发生了重大转变多年来。 传统方法依赖于手工制作的特征, 比如边缘和纹理描述符,结合机器学习技术,比如主成分分析, 线性判别分析或支持向量机。
对于在无约束环境中遇到的不同变化来说,工程特性的困难使研究人员专注于每一种变化类型的专门方法,例如年龄不变方法,姿态不变方法,光照不变方法,等。近年来,传统的人脸识别方法逐渐被基于卷积神经网络(cnn)的深度学习方法所取代。深度学习方法的主要优点是,它们可以用非常大的数据集进行训练,学习出代表数据的最佳特征。网络上的“公开数据集”的可用性使得我们能够收集包含真实世界变化的数据。使用这些数据集训练的基于cnn的人脸识别方法已经取得了非常高的精度,因为它们能够学习在训练过程中使用的人脸图像中存在的真实世界变化的健壮特征。
此外,计算机视觉深度学习方法的普及也加速了人脸识别的研究,cnn被用于解决许多其他的计算机视觉任务,如目标检测与识别、分割、光学字符识别、面部表情分析、年龄估计等。

人脸识别系统通常由以下部分组成:
1)人脸检测。人脸检测器查找人脸在图像中的位置,并(如果有的话)返回每个人脸的边界框的坐标。图3a对此进行了说明
2)人脸对齐。人脸对齐的目标是使用一组位于图像中固定位置的参考点,以相同的方式对人脸图像进行缩放和裁剪。这个过程通常需要使用地标探测器找到一组面部地标,在简单的2D对齐情况下,找到适合参考点的最佳仿射变换。图3b和3c显示了使用同一组参考点对齐的两张人脸图像。更复杂的3D对齐算法(例如:[16])也可以实现面部正面化,即改变面部的姿势到正面。
3) 人脸表征。在人脸表示阶段,将人脸图像的像素值转换为一个紧凑的、具有鉴别性的特征向量,也称为模板。理想情况下,同一主题的所有面孔应该映射到相似的特征向量。
4)人脸匹配。在人脸匹配构建模块中,将两个模板进行比较,产生一个相似度得分,表明它们属于同一主题的可能性。
人脸表征可以说是人脸识别系统中最重要的组成部分。
2.2 算法原理及分析(可添加适当的公式推理,必须确保准确无误)
3.实验内容
3.1 实验环境搭建
本次实验采用的是pycharm的python编辑平台,本次实验采用的包主要是sklearn的机器学习包和matplotlib数据显示包。
# import导入实验所用到的包import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import GridSearchCVfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import PCAfrom sklearn.svm import SVC
3.2 数据导入(包括预处理等,需给出具体实例和操作流程)
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]# Split into a training set and a test set using a stratified k fold# split into a training and testing set# 特征提取X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
lfw_people = fetch_lfw_people(min_faces_per_person=70,resize=0.4)
从fetch_lfw_people中加载人脸数据集。这里有关fetch_lfw_people的使用可以参考https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_lfw_people.html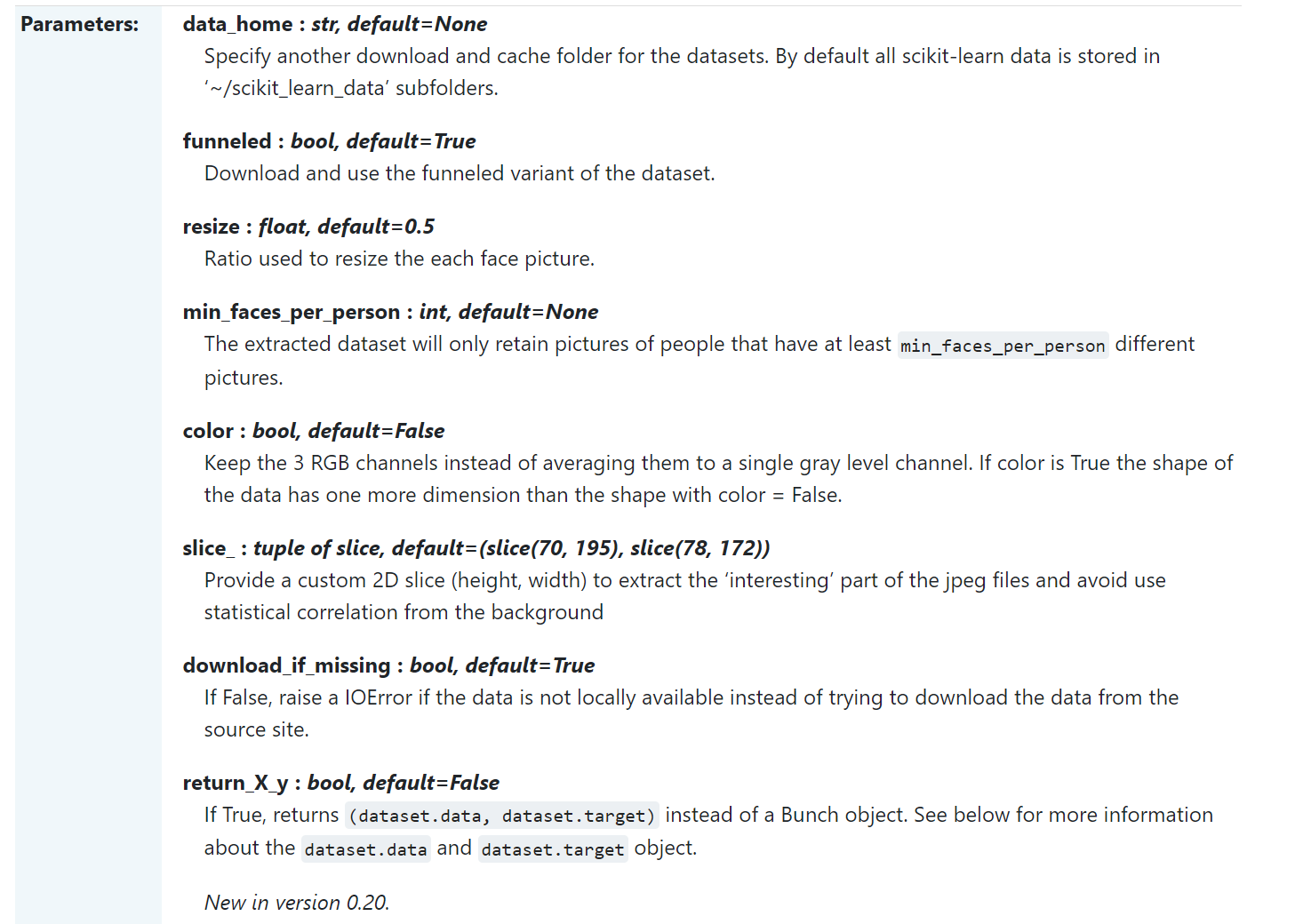
其中,min_faces_per_person参数代表的意思是,提取多少张不同的人脸照片。
resize代表缩放大小。
n_samples, h, w = lfw_people.images.shape
进入debug模式我们可以看出,
lfw_people是一个对象的类,其中images对象中有,shape字典,里面含有三个键值对。分别代表了图片的样本个数,长,宽。
X = lfw_people.data
这一步的操作是为了从lfw_people数据集中读取输入数据。
n_features = X.shape[1]
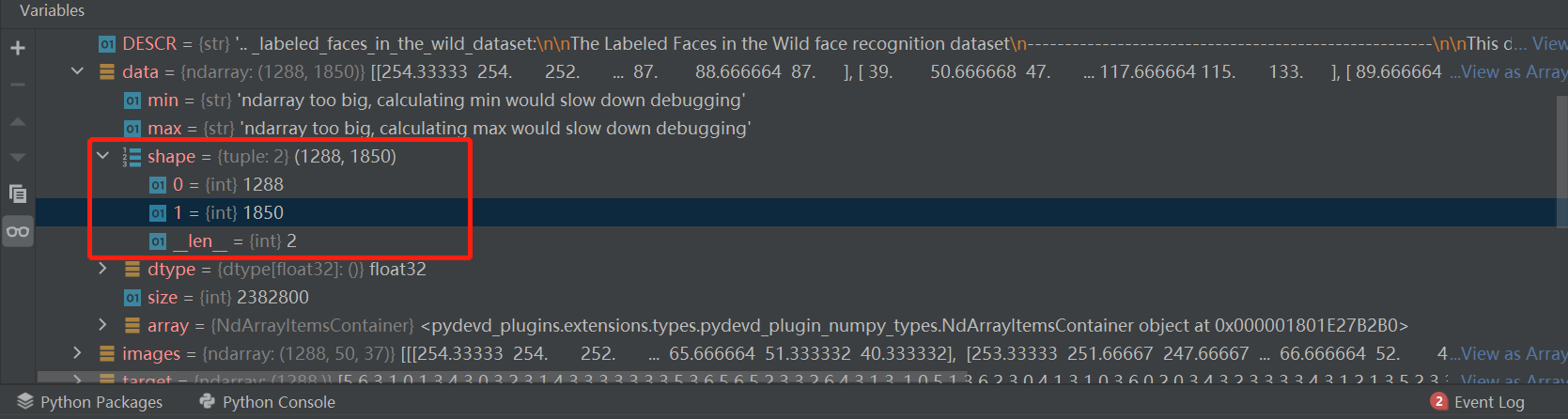
这里的1288是之前的lfw_people.images.shape里面的1288,说明一共有1288个样本。
这里的1850是,lfw_people.images.shape里面的h,w的乘积,代表了一张图片的二维矩阵平铺后的序列。
y = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]
这里y = lfw_people.target是为了获取标签。target_names = lfw_people.target_names即为标签的名字。

这里可以看出,y所对应的数值,和target_names对应的标签名。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
这一步的作用是为了划分训练集和测试集。
3.3 实施算法
特征脸方法原理介绍:
Eigenface
Eigenfaces就是特征脸的意思,是一种从主成分分析(Principal Component Analysis,PCA)中导出的人脸识别和描述技术。特征脸方法的主要思路就是将输入的人脸图像看作一个个矩阵,通过在人脸空间中一组正交向量,并选择最重要的正交向量,作为“主成分”来描述原来的人脸空间。
3.3.1 算法流程
——特征脸训练与识别原理图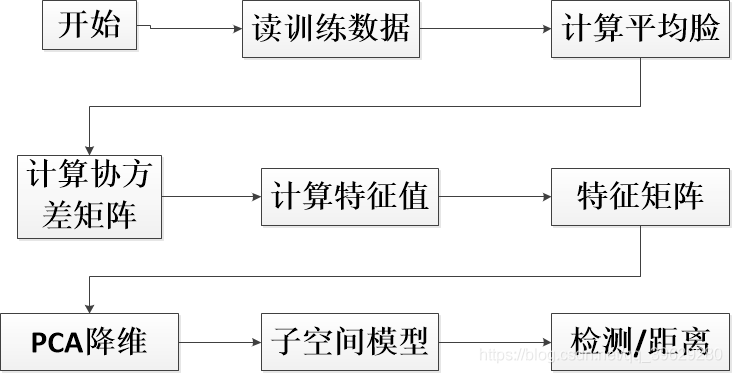
在很多应用中需要对大量数据进行分析计算并寻找其内在的规律,但是数据量巨大造成了问题分析的复杂性,因此我们需要一些合理的方法来减少分析的数据和变量同时尽量不破坏数据之间的关联性。于是这就有了主成分分析方法,PCA作用:
- 数据降维。减少变量个数;确保变量独立;提供一个合理的框架解释。
- 去除噪声,发现数据背后的固有模式。
——PCA的主要过程:
- 特征中心化:将每一维的数据(矩阵A)都减去该维的均值,使得变换后(矩阵B)每一维均值为0;
- 计算变换后矩阵B的协方差矩阵C;
- 计算协方差矩阵C的特征值和特征向量;
- 选取大的特征值对应的特征向量作为”主成分”,并构成新的数据集
——特征脸方法
特征脸方法就是将PCA方法应用到人脸识别中,将人脸图像看成是原始数据集,使用PCA方法对其进行处理和降维,得到“主成分”——即特征脸,然后每个人脸都可以用特征脸的组合进行表示。这种方法的核心思路是认为同一类事物必然存在相同特性(主成分),通过将同一目标(人脸图像)的特性寻在出来,就可以用来区分不同的事物了。人脸识别嘛,就是一个分类的问题,将不同的人脸区分开来。
特征脸方法的实现步骤:
获取包含M张人脸图像的集合T。假设这里使用15张图片来作为人脸训练图像,每张图片的尺寸是100150,所以这里M=15。我们把导入的图像拉平,本来,100150的矩阵,拉平就是一个150001的矩阵,然后M张放在一个大矩阵下,该矩阵为1500015。
计算平均图像A,并获得偏差矩阵B,为15000*15平均图像也就是把每一行的15个元素平均计算,这样最后的平均图像就是一个我们所谓的大众脸。然后每张人脸都减去这个平均图像,最后得到:
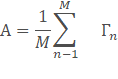
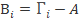
3.求得的方差矩阵。并计算的特征值和特征向量。这就是标准的PCA算法流程。很大的问题就是协方差矩阵的维度会大到无法计算,下面的方法可以解决:
设K是预处理图像的矩阵,每一列对应一个减去均值图像之后的图像。则协方差矩阵为S=K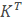
,并且对S的特征值分解 :
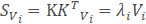
然而KKT是一个非常大的矩阵。因此,如果转而使用如下的特征值分解: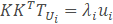
等式两边同时乘以K得到: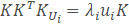
这就意味着,如果Ui是KKT的一个特征向量,则Vi=TUi是S的一个特征向量,反正到最后我们得KKT的一个特征向量,再用K与之相乘就是协方差矩阵的特征向量μ。而此时求得特征向量是1500015的矩阵,每一行(150001)如果变成图像大小矩阵(100*150)的话,都可以看做是一个新人脸,被称为特征脸。
4.主成分分析。在求得的特征向量和特征值中,越大的特征值对于我们区分越重要,也就是主成分,只需要那些大的特征值对应的特征向量,而那些十分小甚至为0的特征值来说,对应的特征向量几乎没有意义。在这里通过一个阈值selecthr来控制,当排序后的特征值的一部分相加大于该阈值,选择这部分特征值对应的特征向量,此时剩下的矩阵15000*M,M根据情况而变。这样不仅减少计算量,而且保留了主成分,减少了噪声的干扰。
5.人脸识别。此时导入一个新的人脸,使用上面主成分分析后得到的特征向量μ,来求得一个每一个特征向量对于导入人脸的权重向量Ω
‘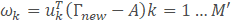
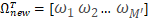
这里的A就是第二步求得的平均图像,特征向量其实就是训练集合的图像与均值图像在该方向上的偏差,通过未知人脸在特征向量的投影,我们就可以知道未知人脸与平均图像在不同方向上的差距。此时我们用上面第2步求得的偏差矩阵的每一行做这样的处理,每一行会得到一个权重向量。利用求得Ω和Ωk的欧式距离来判断未知人脸与第K张训练人脸之间的差距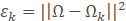
3.3.2 算法实例
3.3.2.1 基础实验实例(当前实验涉及子实验的相关原理实践)
# import导入实验所用到的包import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import GridSearchCVfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import PCAfrom sklearn.svm import SVC# 下载人脸数据lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]# Split into a training set and a test set using a stratified k fold# split into a training and testing set# 特征提取X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled# dataset): unsupervised feature extraction / dimensionality reductionn_components = 150pca = PCA(n_components=n_components, svd_solver='randomized',whiten=True).fit(X_train)eigenfaces = pca.components_.reshape((n_components, h, w))X_train_pca = pca.transform(X_train)X_test_pca = pca.transform(X_test)# Train a SVM classification model# 建立SVM分类模型param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)clf = clf.fit(X_train_pca, y_train)print("Best estimator found by grid search:")print(clf.best_estimator_)# Quantitative evaluation of the model quality on the test set# 模型评估y_pred = clf.predict(X_test_pca)print(classification_report(y_test, y_pred, target_names=target_names))print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
其中有关PCA的部分如下:
参考网址https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html?highlight=pca#sklearn.decomposition.PCA
n_components = 150pca = PCA(n_components=n_components, svd_solver='randomized',whiten=True).fit(X_train)eigenfaces = pca.components_.reshape((n_components, h, w))X_train_pca = pca.transform(X_train)X_test_pca = pca.transform(X_test)
其中PCA的参数ncomponents 为降维后的参数。其中svd_solver参数为设置矩阵分解的方法,其中使用的是randomized方法。
PCA.fit(X_train)的目的是,使用PCA方法来对X_train进行预处理,获取之后降维所需要的一些参数。
pca = PCA.fit(X_train)只是为了获取,之后降维需要使用的函数,X_train_pca = pca.transfrom(X_train)才是把,X_train数据转化为降维之后的X_train_pca。
其中pca.components的目的是为了获取降维后的数据。
SVC(kernel=’rbf’, classweight=’balanced’)的目的是使用SVC方法来实现SVM算法。
对图像做主成分分析生成很多特征脸,我们可以认为每一张图像都是由特征脸叠加而成的,特征脸是根据图像进行主成分分析得到的,可以理解为每个人脸的一些特征,将这些特征叠加起来就可以得到一张清晰的人脸。通过主成分分析,我们可以抽取每一张图像的特征脸
X_train_pca=pca.transform(X_train)
X_test_pca=pca.transform(X_test)
然后把图像根据特征脸做转化提取里面的特征。
param_grid={‘C’:[1e3,5e3,1e4,5e4,1e5],
‘gamma’:[0.0001,0.0005,0.001,0.005,0.01,0.1],}
设置SVM里的必要参数,C是惩罚系数,gamma是学习值,即允许的间隔值
clf=GridSearchCV(SVC(kernel=‘rbf’,class_weight=‘balanced’),param_grid)
通过网格搜索的方式,调整SVC(SVM分类器),C和gamam的组合有5*6=30个,那么我们现在希望找到一个最好的参数组合,使得SVM表示最好,所以网格搜索就是一个一个实验30个组合得到的参数运行程序,观察哪一种组合的表现是最好的,从而得到最优的超参数。
clf=clf.fit(X_train_pca,y_train)
得到最优超参数后训练我们的模型,将训练集得到的特征和与之对应的标签放进模型中训练,此时模型就可以找到一个对于这部分训练数据来说最优的超平面clf.best_estimator。
找到之后我们用得到的最优超平面去预测测试集的特征
y_pred=clf.predict(X_test_pca)
print(classification_report(y_test, y_pred, target_names=target_names))
为显示模型的评价指标,分别有精准率(Precision)、召回率(Recall)、F1(调和平均)三种指标,结果为: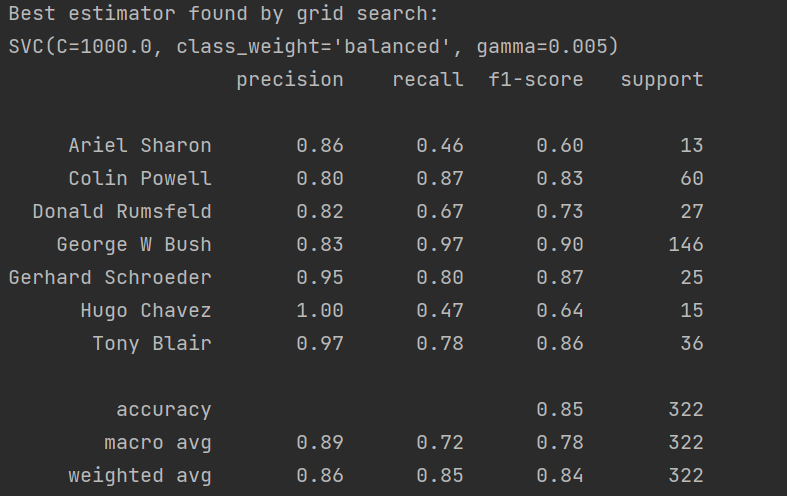
其中关于classification_report函数的详细介绍可以参考附加内容。以及sklearn的参考文档:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html?highlight=classification#sklearn.metrics.classification_report
其中我们可以从F1指标中看出对George W Bush的总体预测评价是最高的。
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
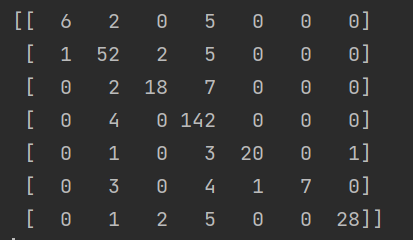
利用confusion_matrix()函数输出confusion_matrix对模型结果进行一个观察。利用confusion_matrix()方法,我们可以清晰地计算出模型的精确值和召回值。竖着来看,是预测的结果,横着来看是真实的结果。我们可以从混淆矩阵中轻易的计算出精确值和召回值的数值。具体的参考附加的4.6。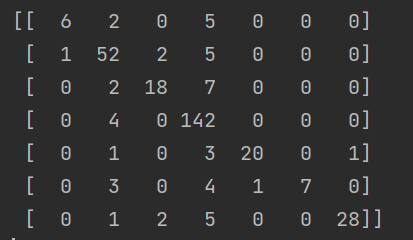
预测结果可视化
# 预测结果可视化def plot_gallery(images, titles, h, w, n_row=3, n_col=4):"""Helper function to plot a gallery of portraits"""plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)plt.title(titles[i], size=12)plt.xticks(())plt.yticks(())
其中可视化用的Python包为matplotlib.pyplot
官方文档:https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.html
# 导入绘图所需要的python包import matplotlib.pyplot as plt
使用plt.figure绘制画框,之后再使用plt.subplots_adjust添加图片区域。之后通过for循环展示图片。

3.3.3 实验结果分析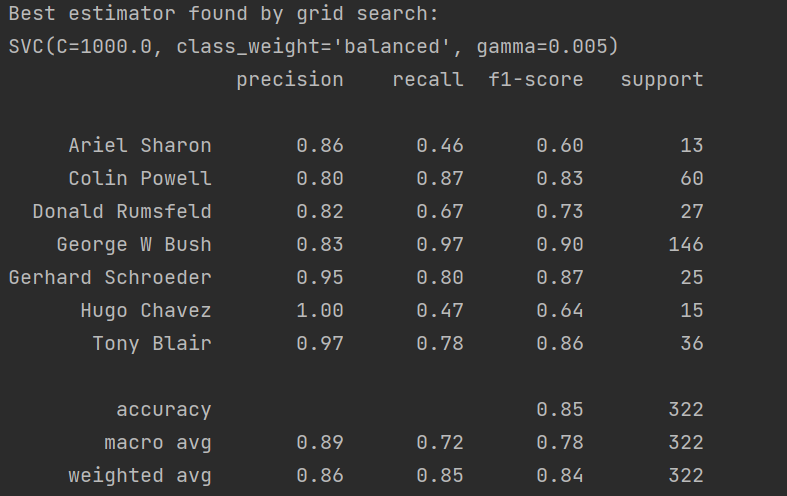


3.3.3.1 定量实验分析
4.附加
4.1 关于LFW人脸数据集
简介
LFW (Labeled Faces in the Wild) 人脸数据库是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要用来研究非受限情况下的人脸识别问题。LFW 数据库主要是从互联网上搜集图像,而不是实验室,一共含有13000 多张人脸图像,每张图像都被标识出对应的人的名字,其中有1680 人对应不只一张图像,即大约1680个人包含两个以上的人脸。
LFW (Labled Faces in the Wild)人脸数据集是目前人脸识别的常用测试集,其中提供的人脸图片均来源于生活中的自然场景,因此识别难度会增大,尤其由于多姿态、光照、表情、年龄、遮挡等因素影响导致即使同一人的照片差别也很大。并且有些照片中可能不止一个人脸出现,对这些多人脸图像仅选择中心坐标的人脸作为目标,其他区域的视为背景干扰。LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。
LFW数据集主要测试人脸识别的准确率,该数据库从中随机选择了6000对人脸组成了人脸辨识图片对,其中3000对属于同一个人2张人脸照片,3000对属于不同的人每人1张人脸照片。测试过程LFW给出一对照片,询问测试中的系统两张照片是不是同一个人,系统给出“是”或“否”的答案。通过6000对人脸测试结果的系统答案与真实答案的比值可以得到人脸识别准确率。
这个集合被广泛应用于评价 face verification算法的性能。意义
可以看出,在LFW 数据库中人脸的光照条件、姿态多种多样,有的人脸还存在部分遮挡的情况,因此识别难度较大。现在, LFW 数据库性能测评已经成为人脸识别算法性能的一个重要指标。
关于人脸数据集的sklearn文档:
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_lfw_people.html
4.2 关于PCA算法的详解
1,概述
1.1,什么是维度?
我们先来解释一下维度的概念。
对于数组和Series来说,维度就是功能shape返回的结果,shape中返回了几个数字,就是几维。索引以外的数据,不分行列的叫一维(此时shape返回唯一的维度上的数据个数),有行列之分叫二维(shape返回行x列),也称为表。一张表最多二维,复数的表构成了更高的维度。当一个数组中存在2张3行4列的表时,shape返回的是(更高维,行,列)。当数组中存在2组2张3行4列的表时,数据就是4维,shape返回(2,2,3,4)。
数组中的每一张表,都可以是一个特征矩阵或一个DataFrame,这些结构永远只有一张表,所以一定有行列,其中行是样本,列是特征。针对每一张表,维度指的是样本的数量或特征的数量,一般无特别说明,指的都是特征的数量。除了索引之外,一个特征是一维,两个特征是二维,n个特征是n维。
对图像来说,维度就是图像中特征向量的数量。特征向量可以理解为是坐标轴,一个特征向量定义一条直线,是一维,两个相互垂直的特征向量定义一个平面,即一个直角坐标系,就是二维,三个相互垂直的特征向量定义一个空间,即一个立体直角坐标系,就是三维。三个以上的特征向量相互垂直,定义人眼无法看见,也无法想象的高维空间。
降维算法中的”降维“,指的是降低特征矩阵中特征的数量。降维的目的是为了让算法运算更快,效果更好,但其实还有另一种需求:数据可视化。从上面的图我们其实可以看得出,图像和特征矩阵的维度是可以相互对应的,即一个特征对应一个特征向量,对应一条坐标轴。所以,三维及以下的特征矩阵,是可以被可视化的,这可以帮助我们很快地理解数据的分布,而三维以上特征矩阵的则不能被可视化,数据的性质也就比较难理解。
1.2,sklearn中的降维算法
sklearn中降维算法都被包括在模块decomposition中,这个模块本质是一个矩阵分解模块。在过去的十年中,如果要讨论算法进步的先锋,矩阵分解可以说是独树一帜。矩阵分解可以用在降维,深度学习,聚类分析,数据预处理,低纬度特征学习,推荐系统,大数据分析等领域。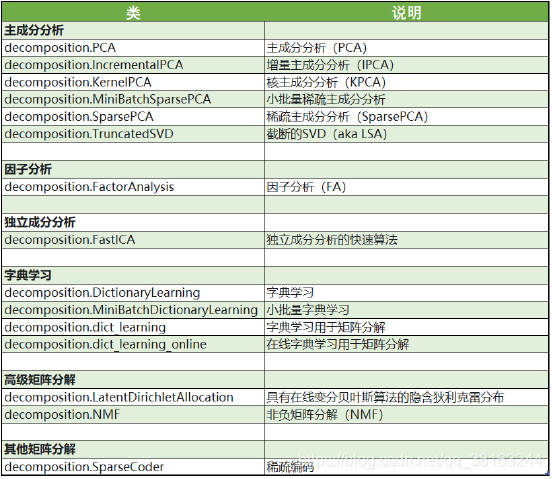
2,PCA与SVD
在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
我们提到过一种重要的特征选择方法:方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。主成分分析(Principal components analysis,简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。一般我们提到降维最容易想到的算法就是PCA。
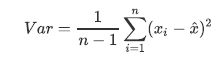
Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值, 代表这一列样本的均值。
代表这一列样本的均值。
2.1 降维究竟是怎样实现的?
class sklearn.decomposition.PCA (n_components=None, copy=True,whiten=False,svd_solver=’auto’,tol=0.0,iterated_power=’auto’,random_state=None)
PCA作为矩阵分解算法的核心算法,其实没有太多参数,但不幸的是每个参数的意义和运用都很难,因为几乎每个参数都涉及到高深的数学原理。为了参数的运用和意义变得明朗,我们来看一组简单的二维数据的降维。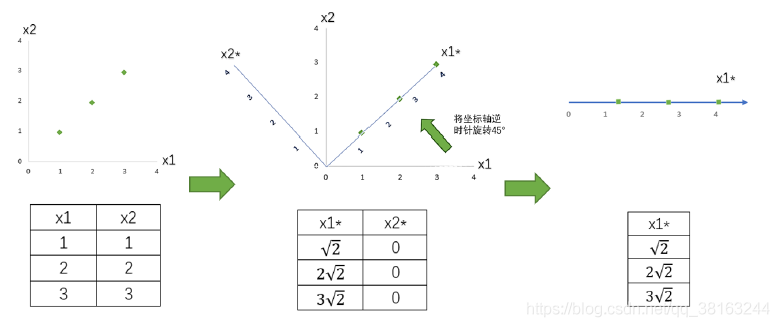
我们现在有一组简单的数据,有特征x1和x2,三个样本数据的坐标点分别为(1,1),(2,2),(3,3)。我们可以让x1和x2分别作为两个特征向量,很轻松地用一个二维平面来描述这组数据。这组数据现在每个特征的均值都为2,方差则等于: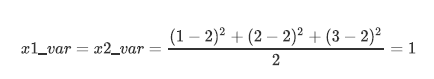
每个特征的数据一模一样,因此方差也都为1,数据的方差总和是2。
现在我们的目标是:只用一个特征向量来描述这组数据,即将二维数据降为一维数据,并且尽可能地保留信息量,即让数据的总方差尽量靠近2。于是,我们将原本的直角坐标系逆时针旋转45°,形成了新的特征向量x1和x2组成的新平面,在这个新平面中,三个样本数据的坐标点可以表示为。可以注意到,x2上的数值此时都变成了0,因此x2明显不带有任何有效信息了(此时x2的方差也为0了)。此时,x1特征上的数据均值是,而方差则可表示成: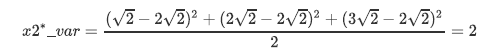
x2上的数据均值为0,方差也为0。此时,我们根据信息含量的排序,取信息含量最大的一个特征,因为我们想要的是一维数据。所以我们可以将x2删除,同时也删除图中的x2特征向量,剩下的x1就代表了曾经需要两个特征来代表的三个样本点。通过旋转原有特征向量组成的坐标轴来找到新特征向量和新坐标平面,我们将三个样本点的信息压缩到了一条直线上,实现了二维变一维,并且尽量保留原始数据的信息。一个成功的降维,就实现了。
通过以上的降维,我们经历了一下步骤:

在步骤3当中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。降维时,它会通过一系列数学的神秘操作(比如说,产生协方差矩阵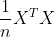 )将特征矩阵X分解为以下三个矩阵,其中
)将特征矩阵X分解为以下三个矩阵,其中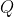 和
和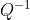 是辅助的矩阵,Σ是一个对角矩阵(即除了对角线上有值,其他位置都是0的矩阵),其对角线上的元素就是方差。降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音。
是辅助的矩阵,Σ是一个对角矩阵(即除了对角线上有值,其他位置都是0的矩阵),其对角线上的元素就是方差。降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音。
而SVD使用奇异值分解来找出空间V,其中Σ也是一个对角矩阵,不过它对角线上的元素是奇异值,这也是SVD中用来衡量特征上的信息量的指标。U和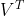 分别是左奇异矩阵和右奇异矩阵,也都是辅助矩阵。
分别是左奇异矩阵和右奇异矩阵,也都是辅助矩阵。
在数学原理中,无论是PCA和SVD都需要遍历所有的特征和样本来计算信息量指标。并且在矩阵分解的过程之中,会产生比原来的特征矩阵更大的矩阵,比如原数据的结构是(m,n),在矩阵分解中为了找出最佳新特征空间V,可能需要产生(n,n),(m,m)大小的矩阵,还需要产生协方差矩阵去计算更多的信息。而现在无论是Python还是R,或者其他的任何语言,在大型矩阵运算上都不是特别擅长,无论代码如何简化,我们不可避免地要等待计算机去完成这个非常庞大的数学计算过程。因此,降维算法的计算量很大,运行比较缓慢,但无论如何,它们的功能无可替代,它们依然是机器学习领域的宠儿。
PCA和特征选择技术都是特征工程的一部分,它们有什么不同?
特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,我们依然知道这个特征在原数据的哪个位置,代表着原数据上的什么含义。
而PCA,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。以PCA为代表的降维算法因此是特征创造(feature creation,或feature construction)的一种。
可以想见,PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。
2.2,重要参数n_components
n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数。如果我们希望可视化一组数据来观察数据分布,我们往往将数据降到三维以下,很多时候是二维,即n_components的取值为2。
2.3,PCA中的SVD
2.3.1,pca中的svd
svdsolver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,PCA和SVD涉及了大量的矩阵计算,两者都是运算量很大的模型,但其实,SVD有一种惊人的数学性质,即是它可以跳过数学神秘的宇宙,不计算协方差矩阵,直接找出一个新特征向量组成的n维空间,而这个n维空间就是奇异值分解后的右矩阵(所以一开始在讲解降维过程时,我们说”生成新特征向量组成的空间V”,并非巧合,而是特指奇异值分解中的矩阵)。
右奇异矩阵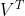 有着如下性质:
有着如下性质: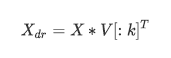
k就是n_components,是我们降维后希望得到的维度。若X为(m,n)的特征矩阵, 就是结构为(n,n)的矩阵,取这个矩阵的前k行(进行切片),即将V转换为结构为(k,n)的矩阵。而与原特征矩阵X相乘,即可得到降维后的特征矩阵 。这是说,奇异值分解可以不计算协方差矩阵等等结构复杂计算冗长的矩阵,就直接求出新特征空间和降维后的特征矩阵。
。这是说,奇异值分解可以不计算协方差矩阵等等结构复杂计算冗长的矩阵,就直接求出新特征空间和降维后的特征矩阵。
简而言之,SVD在矩阵分解中的过程比PCA简单快速,虽然两个算法都走一样的分解流程,但SVD可以作弊耍赖直接算出V。但是遗憾的是,SVD的信息量衡量指标比较复杂,要理解”奇异值“远不如理解”方差“来得容易,因此,sklearn将降维流程拆成了两部分:一部分是计算特征空间V,由奇异值分解完成,另一部分是映射数据和求解新特征矩阵,由主成分分析完成,实现了用SVD的性质减少计算量,却让信息量的评估指标是方差,具体流程如下图:

讲到这里,相信大家就能够理解,为什么PCA的类里会包含控制SVD分解器的参数了。通过SVD和PCA的合作,sklearn实现了一种计算更快更简单,但效果却很好的“合作降维“。
重要参数svd_solver 与 random_state
参数svd_solver是在降维过程中,用来控制矩阵分解的一些细节的参数。有四种模式可选:”auto”, “full”, “arpack”,”randomized”,默认”auto”。
而参数random_state在参数svd_solver的值为”arpack” or “randomized”的时候生效,可以控制这两种SVD模式中的随机模式。通常我们就选用”auto“,不必对这个参数纠结太多。
4.3 关于GridSearchCV详解
1、GridSearchCV简介
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。k折交叉验证将所有数据集分成k份,不重复地每次取其中一份做测试集,用其余k-1份做训练集训练模型,之后计算该模型在测试集上的得分,将k次的得分取平均得到最后的得分。
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,他要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得到结果。
网格搜索可能是最简单,应用最广泛的超参数搜索算法,他通过查找搜索范围内的所有的点来确定最优值。如果采用较大的搜索范围及较小的步长,网格搜索很大概率找到全局最优值。然而这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候。因此在实际应用过程中,网格搜索法一般会先使用较广的搜索范围和较大的步长,来找到全局最优值可能的位置;然后再缩小搜索范围和步长,来寻找更精确的最优值。这种操作方案可以降低所需的时间和计算量,但由于目标函数一般是非凸的,所以很可能会错过全局最优值。
2、GridSearchCV属性说明
(1) cvresults : dict of numpy (masked) ndarrays
具有键作为列标题和值作为列的dict,可以导入到DataFrame中。注意,“params”键用于存储所有参数候选项的参数设置列表。
(2) bestestimator : estimator
通过搜索选择的估计器,即在左侧数据上给出最高分数(或指定的最小损失)的估计器,估计器括号里包括选中的参数。如果refit = False,则不可用。
(3)bestscore :float bestestimator的最高分数
(4)best_parmas : dict 在保存数据上给出最佳结果的参数设置
(5)bestindex : int 对应于最佳候选参数设置的索引(cvresults数组)
search.cvresults [‘params’] [search.bestindex]中的dict给出了最佳模型的参数设置,给出了最高的平均分数(search.bestscore)
3、进行预测的常用方法和属性
- grid.fit(X) :运行网格搜索
- gridscores :给出不同参数情况下的评价结果
- predict(X) : 使用找到的最佳参数在估计器上调用预测。
- bestparams :描述了已取得最佳结果的参数的组合
- bestscore :提供优化过程期间观察到的最好的评分
- cvresults :具体用法模型不同参数下交叉验证的结果
4.4 关于SVM算法详解
概念讲解
1.什么是支持向量机?
支持向量机(support vector machines,SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。除此之外,SVM算法还包括核函数,核函数可以使它成为非线性分类器。在了解SVM算法之前,我们要先认识一下线性分类器。
线性分类器:假设在一个二维线性可分的数据集中,我们要找到一个超平面把两组数据分开,已知的方法有我们已经学过的线性回归和逻辑回归,这条直线可以有很多种,如下图的H1、H2、H3哪一条直线的效果最好呢,也就是说哪条直线可以使两类的空间大小相隔最大呢?
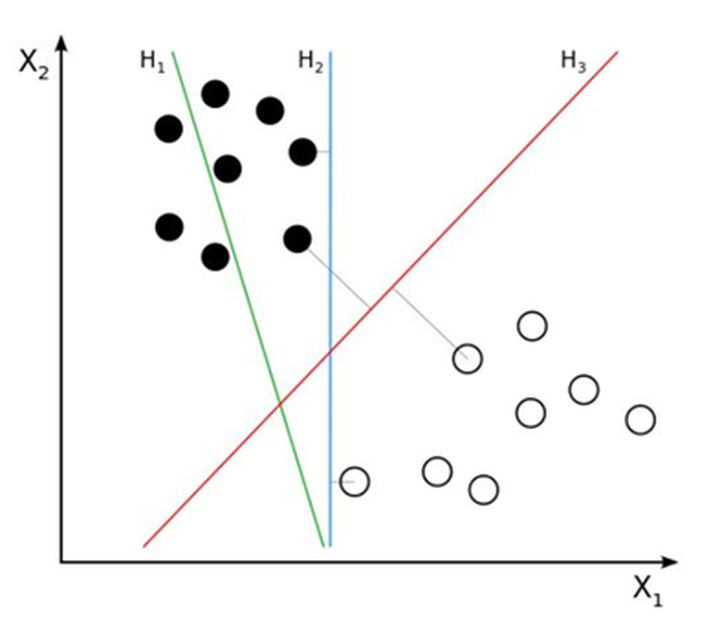
我们凭直观感受应该觉得答案是H3。首先H1不能把类别分开,这个分类器肯定是不行的;H2可以,但分割线与最近的数据点只有很小的间隔,如果测试数据有一些噪声的话可能就会被H2错误分类(即对噪声敏感、泛化能力弱)。H3以较大间隔将它们分开,这样就能容忍测试数据的一些噪声而正确分类,是一个泛化能力不错的分类器。因此我们把这个划分数据的决策边界就叫做超平面。离这个超平面最近的点就是”支持向量”,点到超平面的距离叫做间隔,支持向量机的意思就是使超平面和支持向量之间的间隔尽可能的大,这样才可以使两类样本准确地分开。 <br />[<br />](https://blog.csdn.net/weixin_43332715/article/details/120864251)<br />2.支持向量机的种类:<br />a) 线性可分SVM:当数据线性可分的时候,通过硬间隔最大化可以学习得到一个线性分类器,即硬间隔SVM,如上图的H3<br />b) 近似线性SVM:当训练数据不能线性可分但是可以近似线性可分时,通过软间隔(soft margin)最大化也可以学习到一个线性分类器,即软间隔SVM<br />c) 非线性SVM:<br />当训练数据线性不可分时,通过使用核技巧(kernel trick)和软间隔最大化,可以学习到一个非线性SVM。<br />[<br />](https://blog.csdn.net/weixin_43332715/article/details/120864251)<br /> 3.超平面与间隔:<br />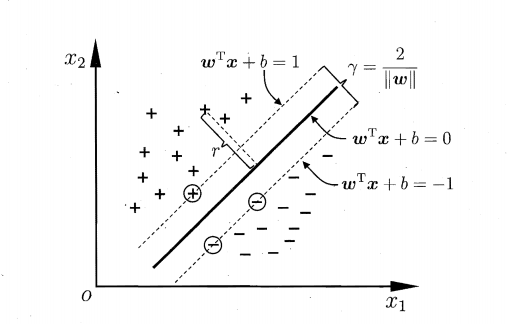<br /> 我们从图上可以看到,这条中间的实线代表的超平面离直线两边的数据的间隔最大,对训练集的数据的噪声有最大的包容力。<br /><br /> 对一个分类问题,我们假设,<br />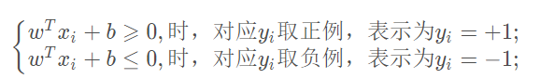<br /> 我们知道,所谓的支持向量,就是使得上式等号成立,即最靠近两条虚边界线的向量。为什么像上面的式子那么假设呢?其实是为了方便计算。 <br />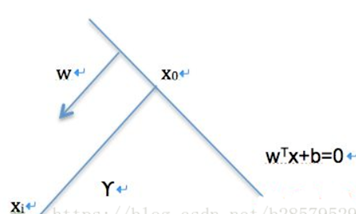<br />
4.算法实战:
sklearn中对于支持向量机提供了很多模型:LinearSVC, LinearSVR, NuSVC, NuSVR, SVC, SVR
SVC
用于分类,用libsvm实现,参数如下:
- C : 惩罚项,默认为1.0,C越大容错空间越小;C越小,容错空间越大
- kernel : 核函数的类型,可选参数为:
- “linear” : 线性核函数
- “poly” : 多项式核函数
- “rbf” : 高斯核函数
- “sigmod” : sigmod核函数
- “precomputed” : 核矩阵,表示自己提前计算好核函数矩阵
- degree : 多项式核函数的阶,默认为3,只对多项式核函数生效,其他的自动忽略
- gamma : 核函数系数,可选,float类型,默认为auto。只对’rbf’ ,’poly’ ,’sigmod’有效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features
- coef0 :核函数中的独立项,float类型,可选,默认为0.0。只有对’poly’ 和,’sigmod’核函数有用,是指其中的参数c
- probability : probability:是否启用概率估计,bool类型,可选参数,默认为False,这必须在调用fit()之前启用,并且会fit()方法速度变慢
- tol :svm停止训练的误差精度,float类型,可选参数,默认为1e^-3
- cache_size :内存大小,float,可选,默认200。指定训练所需要的内存,单位MB
- class_weight:类别权重,dict类型或str类型,可选,默认None。给每个类别分别设置不同的惩罚参数C,如果没有,则会给所有类别都给C=1,即前面指出的C。如果给定参数’balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重
- max_iter:最大迭代次数,int类型,默认为-1,不限制
- decision_function_shape :决策函数类型,可选参数’ovo’和’ovr’,默认为’ovr’。’ovo’表示one vs one,’ovr’表示one vs rest。
- random_state :数据洗牌时的种子值,int类型,可选,默认为None
模型训练结束后,可以使用下列参数:
- support_ : array类型,支持向量的索引
- supportvectors: 支持向量的集合
- nsupport : 比如SVC将数据集分成了4类,该属性表示了每一类的支持向量的个数。
- dualcoef : array, shape = [n_class-1, n_SV] 对偶系数,支持向量在决策函数中的系数,在多分类问题中,这个会有所不同。
- coef_ : array,该参数仅在线性核时才有效,指的是每一个属性被分配的权值。
- intercept :array, shape = [n_class * (n_class-1) / 2]决策函数中的常数项bias。和coef共同构成决策函数的参数值(偏置?)
4.5 关于classfication_report详解
sklearn参考文档:
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html?highlight=classification#sklearn.metrics.classification_report
sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数.
准确率Accuracy
准确率的定义:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
举例:有100封邮件,有85封邮件预测正确,那么准确率即为:85/100=85%。
注:85封邮件预测正确,这个“预测正确”有2种情况:
①是垃圾邮件,预测结果也是垃圾邮件——预测正确。
②是正常邮件(不是垃圾邮件),预测结果也是正常邮件——预测正确。精确率Precision/召回率Recall/F1值
预测问题会有下列4种情况:
TP——将正类预测为正类的数量
FN——将正类预测为负类的数量
FP——将负类预测为正类的数量
TN——将负类预测为负类的数量。
通常,以关注的类作为“正类”,其他类为负类。在垃圾邮件检测中,“垃圾邮件”是正类,则“正常邮件”是负类。则TP/FN/FP/TN的理解如下:
TP——是垃圾邮件(正类),预测结果是垃圾邮件(预测为正类)
FN——是垃圾邮件(正类),预测结果是正常邮件(预测为负类)
FP——是正常邮件(负类),预测结果是垃圾邮件(预测为正类)
TN——是正常邮件(负类),预测结果是正常邮件(预测为负类)
2.1. 精确率(Precision)
精确率(Precision)的定义如下: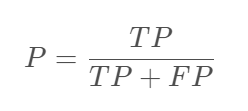
理解:
①TP——是垃圾邮件(正类),预测结果是垃圾邮件(预测为正类)
②FP——是正常邮件(负类),预测结果是垃圾邮件(预测为正类)
③TP+FP——可能是垃圾邮件/也可能是正常邮件,但预测结果都是垃圾邮件。
则精确率(P)的含义就是:你预测结果是垃圾邮件的这些邮件中(TP+FP),有多少个是真正的垃圾邮件(TP)?
2.2. 召回率(Recall)
召回率(Recall)的定义如下: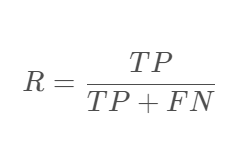
理解:
①TP——是垃圾邮件(正类),预测结果是垃圾邮件(预测为正类)
②FN——是垃圾邮件(正类),预测结果是正常邮件(预测为负类)
③TP+FN——是垃圾邮件,但预测结果可能是垃圾邮件也可能是正常邮件。
则召回率(R)的含义就是:有这么多的垃圾邮件(TP+FN),有多少是你预测对的(TP)?
2.3. F1值(F1 score)
F1值(F1 score)的定义如下: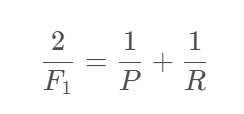
可以看出F1是P和R的调和平均数。
调和平均数具有以下几个主要特点:
①调和平均数易受极端值的影响,且受极小值的影响比受极大值的影响更大。
②只要有一个标志值为0,就不能计算调和平均数。
③当组距数列有开口组时,其组中值即使按相邻组距计算,假定性也很大,这时的调和平均数的代表性很不可靠。
④调和平均数应用的范围较小。在实际中,往往由于缺乏总体单位数的资料而不能直接计算算术平均数,这时需用调和平均法来求得平均数。
4.6 关于confusion_matrix的详解
混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法。
以下有几个概念需要先说明:
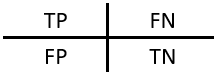
TP(True Positive): 真实为0,预测也为0
FN(False Negative): 真实为0,预测为1
FP(False Positive): 真实为1,预测为0
TN(True Negative): 真实为1,预测也为1
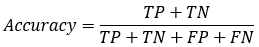 :分类模型总体判断的准确率(包括了所有class的总体准确率)
:分类模型总体判断的准确率(包括了所有class的总体准确率)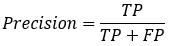 : 预测为0的准确率
: 预测为0的准确率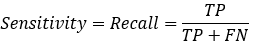 : 真实为0的准确率
: 真实为0的准确率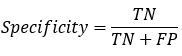 : 真实为1的准确率
: 真实为1的准确率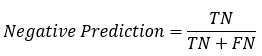 : 预测为1的准确率
: 预测为1的准确率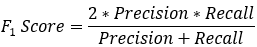 : 对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差
: 对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差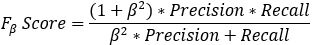 : 另外一个综合Precision和Recall的标准,F1-Score的变形
: 另外一个综合Precision和Recall的标准,F1-Score的变形
举个经典的二分类例子: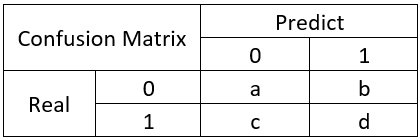
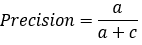 ,
, 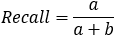 ,
, 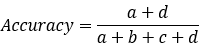
如果是多分类的呢?举一个三分类的例子: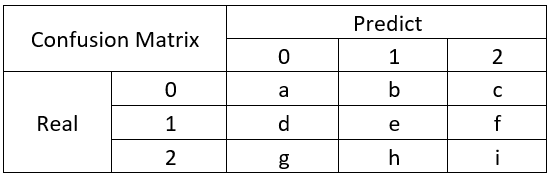
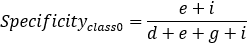 ,
, 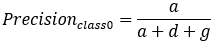 ,
, 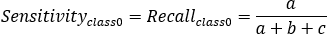
因此我们知道,计算Specificity,Recall,Precision等只是计算某一分类的特性,而Accuracy和F1-Score这些是判断分类模型总体的标准。我们可以根据实际需要,得出不同的效果。
4.7 关于matplotlib.pyplot详解
matplotlib.pyplot为python提供的绘图工具包
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.figure.html
一般我们在引用matplotlib.pyplot的时候,常常会把matplotlib.pyplot缩写为plt
import matplotlib.pyplot as plt
1.plt.figure()
fig = plt.figure()作用就是生成一个图框,但是这个图框还不能用来画图,画图需要在子图(subplot)或者轴域(Axes)中作图,用别人的话说,fig = plt.figure()就是生成了一个画板,在画板fig上使用ax = fig.add_sudplot(a,b,c)就生成了一个子图ax,fig,ax = plt.subplots(a,b)就是即生成了画板fig,又生成了一组子图ax,使用ax[x,y]便选中了一个子图,下面说一下plt.figure(),plt.subplolts(),fig.add_sudplot()函数的参数


若有收获,就点个赞吧
0 人点赞

{kind=link}