Single-image super-resolution
1.SRCNN
https://www.yuque.com/ocfyts/byvevb/pcxt8c
简单的end-to-end的学习和训练
在原文中,作者首先使用双三次插值方法对低分辨率图像进行缩小和放大,得到处理后的低分辨率图像(预处理)。
输入:处理后的低分辨率图像 Y
卷积层1:kernelSize为 9 × 9
卷积层2:kernelSize为 1 × 1
卷积层3:kernelSize为 5 × 5
输出:高分辨率图像
作者对于这三层卷积层的解释:
特征块提取和表示:此操作从低分辨率图像 Y 中提取(重叠)特征块,并将每个特征块表示为一个高维向量。这些向量包括一组特征图,其数量等于向量的维数。
非线性映射:该操作将每个高维向量非线性映射到另一个高维向量。每个映射向量在概念上都是高分辨率特征块的表示。这些向量同样包括另一组特征图。
重建:该操作聚合上述高分辨率patch-wise(介于像素级别和图像级别的区域)表示,生成最终的高分辨率图像。
激活函数:ReLU。
损失函数:MSE(均方误差)。原因可获得高PSNR。
PSNR:一种广泛使用的用于定量评估图像恢复质量的指标。
SRCNN存在3点局限性:
1.依赖较小的图像区域的上下文信息
2.网络训练收敛速度慢
3.网络只能解决单一尺度的图像超分辨率 因为这里的SRCNN就是简单的3层卷积层,没有采用resnet的方法进行训练,不能采用较大的
2.VDSR
https://blog.csdn.net/ch07013224/article/details/80324312
Accurate Image Super-Resolution Using Very Deep Convolutional Networks
https://arxiv.org/abs/1511.04587
We find increasing our network depth shows a significant improvement in accuracy.
SRCNN存在3点局限性:
1.依赖较小的图像区域的上下文信息
2.网络训练收敛速度慢
3.网络只能解决单一尺度的图像超分辨率
While SRCNN successfully introduced a deep learning technique into the super-resolution (SR) problem, we find its limitations in three aspects: fifirst, it relies on the context of small image regions; second, training converges too slowly; third, the network only works for a single scale.
因为这里的SRCNN就是简单的3层卷积层,没有采用resnet的方法进行训练,不能采用较大的学习率进行训练。
VDSR提出新的方法来解决这些局限性:
1.更深的网络使用更大的感受野来获取图像上下文信息——关于为什么更深的网络可以提高图像的感受野
2.网络进行残差学习(residual-learning CNN),并且使用极高的学习率,提高收敛(Convergence)速度。采用大学习率,容易遇到梯度消失和梯度爆炸(vanishing/exploding gradients)的问题,这里使用残差学习和可调梯度裁剪技术(adjustable gradient clipping)来抑制梯度问题的产生。
3.一个单一神经网络可以针对不同尺度(Scale Factor)进行图像超分辨率重构
虽然非常深的模型可以提高性能,但现在需要更多的参数来定义一个网络。通常,为每个比例因子创建一个网络。考虑到经常使用分数尺度因子,我们需要一种经济的方法来存储和检索网络。因此,该文还训练了一个多尺度的模型。使用这种方法,参数在所有预定义的尺度因子中共享。训练一个多尺度的模型是很简单的。针对多个特定尺度的训练数据集被组合成一个大数据集。
正如在VDSR论文中作者提到,输入的低分辨率图像和输出的高分辨率图像在很大程度上是相似的,也就是指低分辨率图像携带的低频信息与高分辨率图像的低频信息相近,训练时带上这部分会多花费大量的时间,实际上我们只需要学习高分辨率图像和低分辨率图像之间的高频部分残差即可。残差网络结构的思想特别适合用来解决超分辨率问题,可以说影响了之后的深度学习超分辨率方法。VDSR是最直接明显的学习残差的结构。

但是这里,我从代码中没看出来,代码怎么实现残差学习的……代码都没有做差这个操作。
VDSR于2016年于Jiwon Kim等人所提出。作者主要使用了一种基于VGG-Net的深度卷积网络[使用更小以及更深的卷积核,可以增加模型的拟合能力及非线性],训练时只学习残差,最终得到了极高的学习率(比SRCNN高104倍),并且在图片质量表现上也有很大优势。
作者认为,增加网络的深度会显著提高性能。
网络模型共有20层,第一层对输入图像进行操作,最后一层用于图像重建。除了第一层和最后一层外,其他卷积层为同一类型:3 × 3 × 64 。
网络将插值后的低分辨率图像(到所需大小)作为输入,再将这个图像与网络学到的残差相加得到最终的网络的输出。
3.SRResNet和SRGAN
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
https://arxiv.org/abs/1609.04802
SRGAN
在这篇文章中,将生成对抗网络(Generative Adversarial Network, GAN)用在了解决超分辨率问题上。文章提到,训练网络时用均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是恢复出来的图像通常会丢失高频细节,使人不能有好的视觉感受。SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。感知损失是利用卷积神经网络提取出的特征,通过比较生成图片经过卷积神经网络后的特征和目标图片经过卷积神经网络后的特征的差别,使生成图片和目标图片在语义和风格上更相似。
SRResNet:就是只用生成器,损失函数是MSE loss或者VGG loss。
SRGAN:用了生成器和判别器,损失函数用了perceptual loss,adversarial loss。
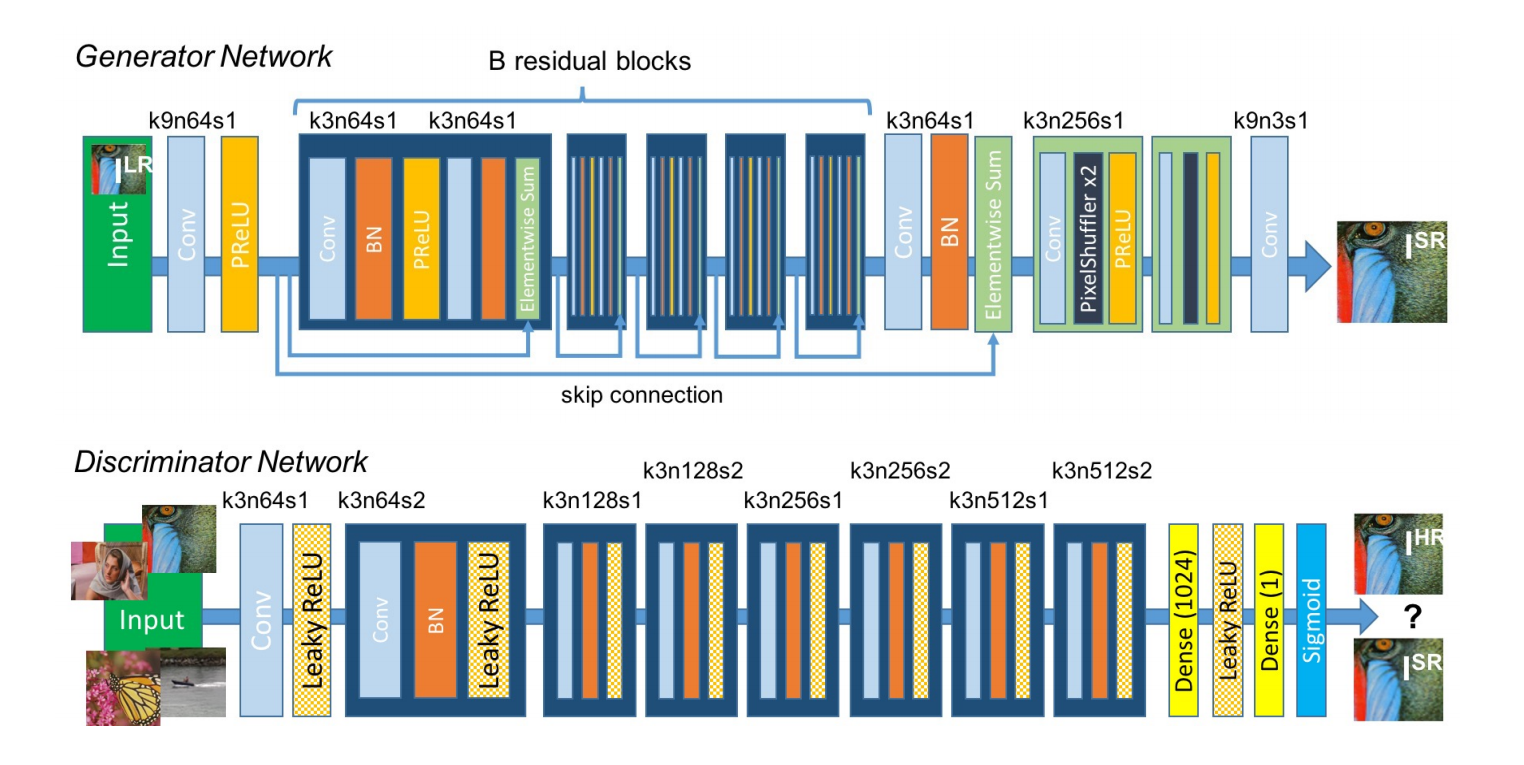
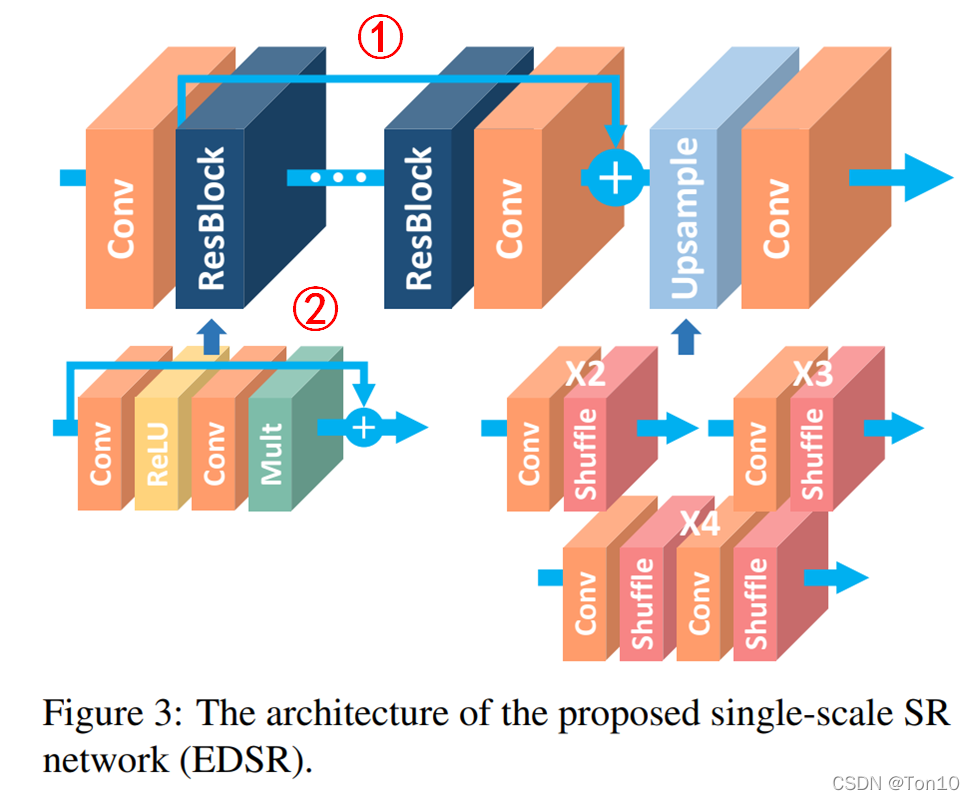
4.EDSR
EDSR=Enhanced Deep Residual Networks for Single-Image Super Resolution
https://arxiv.org/abs/1707.02921
- 作者推出了一种加强版本的基于Resnet块的超分方法,它实际上是在SRResnet上的改进,去除了其中没必要的的BN部分,从而在节省下来的空间下扩展模型的size来增强表现力,它就是EDSR,其取得了当时SOAT的水平。
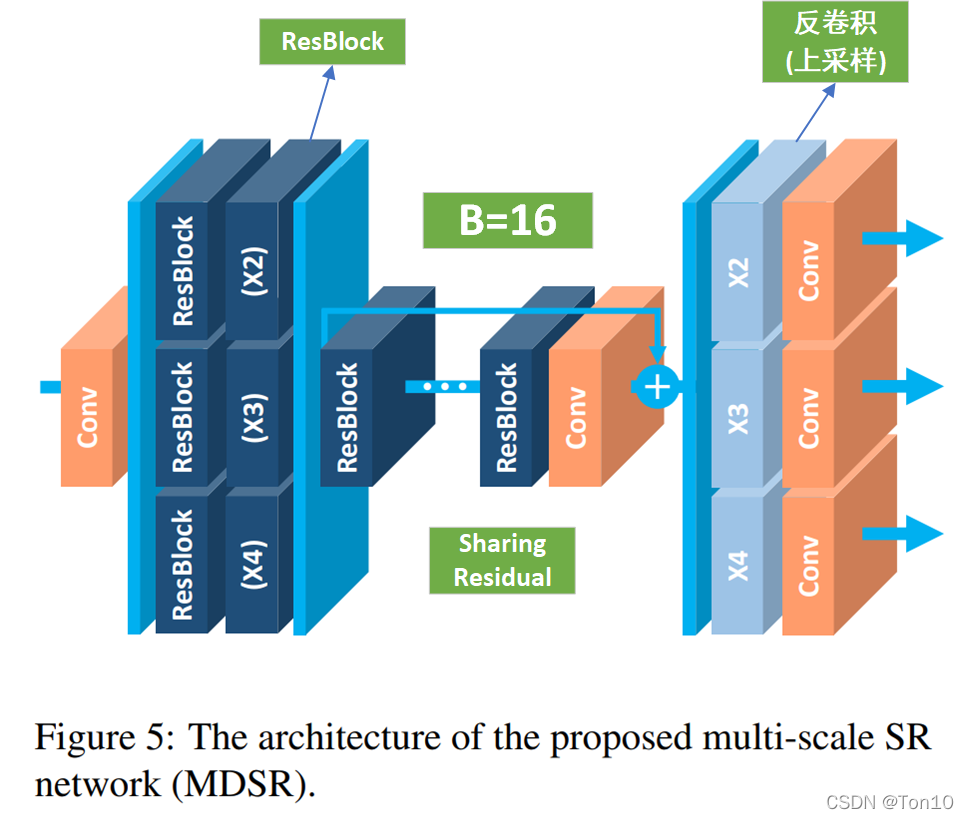
- 此外,作者在文中还介绍了一种基于EDSR的多缩放尺度融合在一起的新结构——MDSR。
- EDSR、MDSR在2017年分别赢得了NTIRE2017超分辨率挑战赛的冠军和亚军。
- 此外,作者通过实验证明使用L 1 − L o s s 比L 2 − L o s s具有更好的收敛特性。
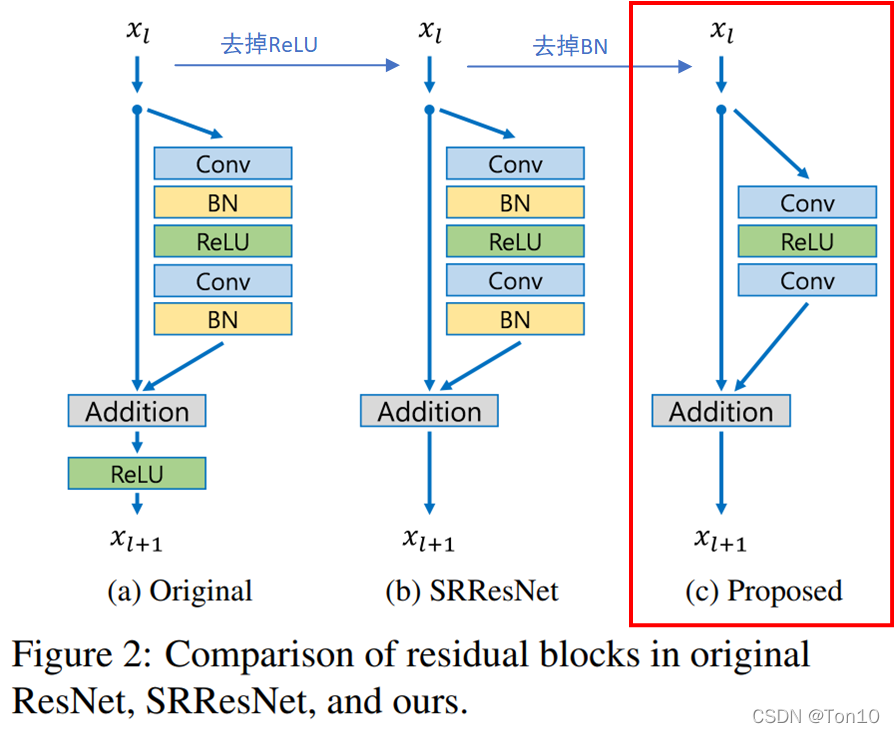
近几年来,深度学习在SR领域展现了较好的图像高分辨率重建表现,但是网络的结构上仍然存在着一些待优化的地方:
深受神经网络的影响,SR网络在超参数(Hyper-parameters)、网络结构(Architecture)十分敏感。
之前的算法(除了VDSR)总是为特定up-scale-factor而设计的SR网络,即scale-specific,将不同缩放尺度看成是互相独立的问题,因此我们需要一个统一的网络来处理不同缩放尺度的SR问题,比如× 2 , 3 , 4,这比训练3个不同缩放尺度的网络节省更多的资源消耗。
针对第一个网络结构问题,作者在SRResNet的基础上,对其网络中多余的BN层进行删除,从而节约了BN本身带来的存储消耗以及计算资源的消耗,相当于简化了网络结构。此外,选择一个合适的loss function,作者经过实验证明L 1 − L o s s比L 2 − L o s s具有更好的收敛特性。
针对第二个多缩放尺度问题,作者用2种不同的方式去处理:
使用低缩放尺度(× 2 )训练之后的模型作为高缩放尺度的初始化参数,结果取得很好的表现,说明不同尺度之间是有内在相关联系的。
作者设计以了一个可以结合多尺度的SR网络MDSR,除了网络的头部和尾部为各个缩放尺度独立之外,中间部分是共享网络。这种多尺度SR网络具有和单一缩放网络相近的表现力,且相比n个单一网络,n个尺度相结合的MDSR消耗更少的资源。
为什么BN不适合图像超分任务呢? https://blog.csdn.net/sinat_36197913/article/details/104845599?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1.pc_relevant_default&utm_relevant_index=2 看这一篇 移除BN有以下三个好处:
- 这样模型会更加轻量。BN层所消耗的存储空间等同于上一层CNN层所消耗的,作者指出相比于SRResNet,EDSR去掉BN层之后节约了40 % 40\%40%的存储资源。
- 在BN腾出来的空间下插入更多的类似于残差块等CNN-based子网络来增加模型的表现力。
- BN层天然会拉伸图像本身的色彩、对比度,这样反倒会使得输出图像会变坏,实验也证明去掉BN层反倒可以增加模型的表现力。
EDSR是SRResNet的增强版本,是一种基于上图红框所示的残差块。
EDSR主要就是改了一下SRResNet的残差结构。
5.RCAN
https://arxiv.org/abs/1807.02758
Image Super-Resolution Using Very Deep Residual Channel Attention Networks
存在的问题:
- 观察到图像SR的非常深的网络更难以训练,以及简单地堆叠残差块以构建更深的网络几乎无法获得更好的改进。更深层次的网络是否能进一步促进图像SR的性能,以及如何构建非常深的可训练网络,仍有待探讨。 【无脑堆叠以及无脑加深已经不一定有用了】
- 图像SR可以看作是这样一个过程:试图恢复尽可能多的高频信息。LR图像包含大多数低频信息,这些信息可以直接传递到最终的HR输出,不需要太多的计算。 【?】
- 基于CNN的很多方法(例如,EDSR )将从原始LR输入中提取特征,但这些信息在信道上被平等对待。这样的过程会浪费不必要的计算以获得丰富的低频特征,缺乏跨特征通道的判别性学习能力【怎么理解这个】,最终阻碍了CNN的表示能力。
主要贡献:
- 提出了一种非常深的残差信道注意网络(RCAN),用于高精度的图像SR。RCAN的深度可以构造的比以前基于CNN的网络更深,并获得更好的SR性能。 【改了模型之后可以更深】
- 提出了Residual in Residual结构(RIR)来构建非常深的可训练网络。RIR中的长跳和短跳连接有助于传递丰富的低频信息,使主网络学习到更有效的信息。 【用RIR可以训练更深的网络】
- 提出了信道注意(CA)机制,通过考虑特征信道之间的相互依赖性自适应地调整特征。这种CA机制进一步提高了网络的表达能 力。【利用CA找信道之间的联系】——不知道可不可以用在SwinIR中,比如说改进attention机制?

RCAN主要由四部分组成:浅特征提取、residual in residual (RIR) 深度特征提取、上采样模块和重建部分。假设I(LR)和I(SR)表示为RCAN的输入和输出。
(1)、浅特征提取:仅使用一个卷积层(conv)从LR输入中提取浅特征F0(其中Hsf表示卷积运算,F0用于RIR模块的深度特征提取):
(2)、residual in residual (RIR) 深度特征提取(Hrir表示的是RIR模块,包括G个残差组):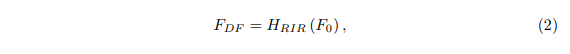
(3)、上采样模块(Hup表示上采样的算法,Fup表示上采样之后得到的特征图):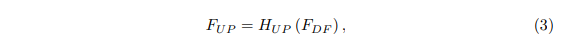
有几种选择可用作上采样的模块,例如反卷积层(也称为转置卷积),最近邻上采样+
卷积以及ESPCN的亚像素卷神经网络。
(4)、重建,通过一个Conv层重建升级的特征: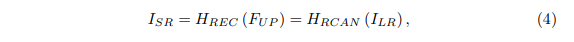
(5)、损失函数:超分辨loss有l1,l2,gan的loss以及纹理结构perceptual loss,为了保证有效性,选择了L1 loss:
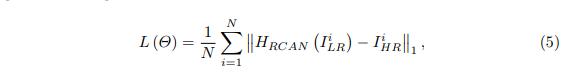
网络细节:
(1)、Residual in Residual (RIR):
RIR结构包含G个residual组(RG)和长跳跃连接(LSC),每一个RG包含B个具有短跳跃连接的残差通道注意块(RCAB),这种RIR的结构能够使高性能的图像SR算法训练的更深(超过400层)。第G组中的RG表示如下: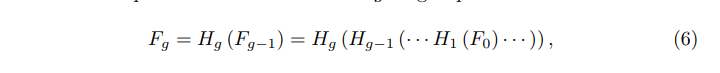
Hg表示的是第G个RG,Fg-1和Fg分别是第G个RG的输入和输出,作者发现,简单地堆叠多个RG将无法获得更好的性能。为了解决这个问题,在RIR中进一步引入了长跳跃连接(LSC),以稳定训练深的网络。LSC表示如下: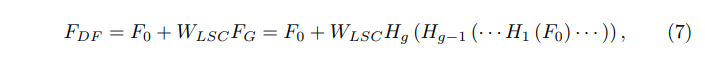
表达式中,Wlsc为最后一个RIR模块后接的一个conv层的权重,为了简单起见,省略了偏置项。
LSC不仅可以简化RG之间的信息流,而且可以在粗略的级别学习残差信息。在LR输入和特征包含着丰富的信息,SR网络的目标是恢复更多有用的信息。丰富的低频信息可以通过跳跃连接传输到后面。
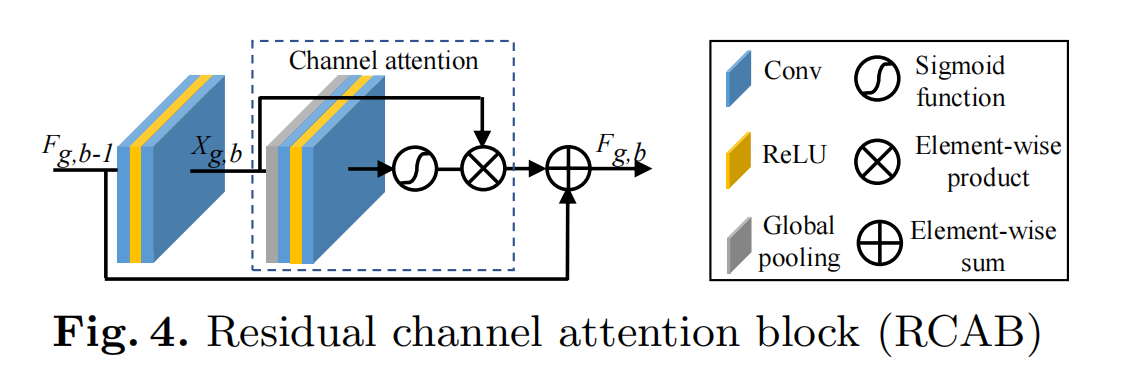
此外,每个RG中堆叠B个残差信道注意块。第g个RG中的第b个残留信道关注块(RCAB)可以表示为: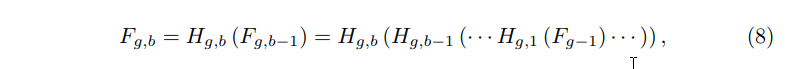
Fg,b-1和Fg,b表示的是第g个RG中的第b个RCAB的输入和输出,与RG块类似,这B个残差信道注意块也具有跳跃连接,称为短跳跃连接(SSC):
Wg是第g个RB模块尾部的一个conv的权重。LSC和SSC的存在,使更丰富的低频信息在训练过程流动到更深层。
(2)、Channel Attention (CA)
以前基于CNN的SR方法对LR信道特征的处理是相同的,这在实际情况中并不灵活。为了使网络专注于更多信息特征,利用特征信道之间的相互依赖性,形成信道注意力机制。如下图所示: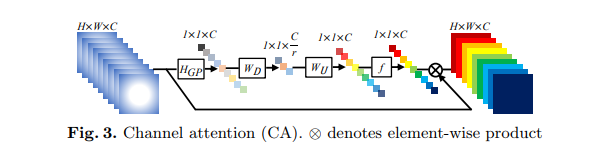
使用全局平均池来将通道的全局空间信息转换为通道描述符,也就是获取1x1xc的特征图,然后压缩成1x1xc/r的特征图,接着再恢复回1x1xc,最后再通过一个sigmoid激活函数获取1x1xc的表示每个通道的权值的描述符,最后各通道权重值分别和原特征图对应通道的二维矩阵相乘。(f表示sigmoid,δ表示relu,s是通道的权重,Xc是全局平均池化前的特征图): 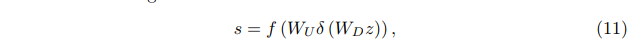
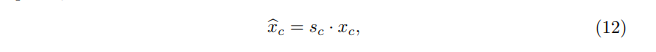
(3)、Residual Channel Attention Block (RCAB)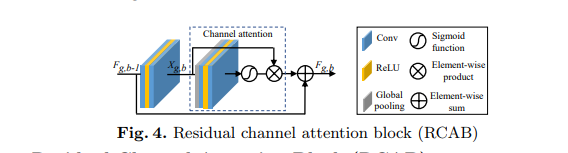
将CA集成到RB中并提出残余信道注意块(RCAB)(如上图)。对于第g个RG中的第b个RB,表示如下(Rg,b表示的是CA函数模块,fg,b−1与fg,b分别表示的是输入和输出,Xg,b表示的是残差块中的2个堆叠的卷积):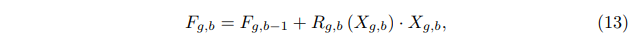
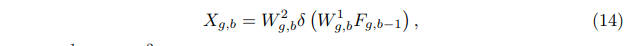
6.SAN
2019SOTA【还没具体的理解得多看几遍论文】
Second-order Attention Network for Single Image Super-Resolution
https://blog.csdn.net/weixin_44712669/article/details/111028838
https://blog.csdn.net/u012880986/article/details/102544661
http://openaccess.thecvf.com/content_CVPR_2019/papers/Dai_Second-Order_Attention_Network_for_Single_Image_Super-Resolution_CVPR_2019_paper.pdf
SAN摘要:
基于CNN的超分辨方法虽然取得了最好的结果,但此类方法关注更宽或更深的结构设计,忽略了中间层特征之间的关系,本文提出二阶注意力网络,以达到更强的特征表达和特征关系学习。具体来说:本文开发了一种新的二阶通道注意力模块,能够自适应的调整通道特征来获得更有区别性的表示,另外,本文提出了一种非局部残差加强结构,不仅包含了非局部操作而且有多个局部信息注意力块,用于学习日益抽象的特征表示。
基于模型的方法虽然能灵活的生成高质量的HR图像,但优化困难时间复杂度高,当图像信息分布与获得的先验差距较大时,其效果会迅速下降。
深度卷积神经网络最近在各种问题上取得了空前的成就,CNN因为其强大的特征表示和端到端的训练参数使其成为解决超分辨问题的一种有效方案,最近几年,提出了大量的基于CNN的方法来学习LR与HR之间的映射关系,通过充分的探索训练数据中图像的先验信息,CNN在超分辨领域取得了目前最优的结果,但基于CNN的方法仍然存在一些局限性:1.不能充分利用LR图像的信息,导致性能较差,2.大多数CNN方法主要关注设计更深或更宽的网络学习更具有区分性的特征,很少有模型去探索特征之间的固有联系,因此阻碍了CNN的表达能力。
本文提出了二阶注意力机制(SOCA)更好的学习特征之间的联系,此模块通过利用二阶特征的分布自适应的学习特征的内部依赖关系,SOCA的机制是网络能够专注于更有益的信息且能够提高判别学习的能力,此外,本文提出了一种非局部加强残差组结构能进一步结合非局部操作来提取长程的空间上下文信息。通过堆叠非局部残差组,本文的方法能够利用LR图像的信息且能够忽略低频信息,
本文贡献主要有以下三点:
1.提出了用于图像超分辨的深度二阶注意力网络,
2.提出了二阶注意力机制通过利用高阶的特征自适应的调整特征,另外利用了协方差归一化的方法来加速网络的训练。
3.提出了非局部加强残差组NLRG结构构建网络,进一步结合非局部操作来提取空间上的上下文信息,并共享残差结构来学习深度特征,另外通过跳跃链接来过滤低频信息且简化了深层网络的训练。

- 提出一个深的二阶注意力网络(Second-order Attention Network,SAN)
- 提出了一个非局部增强残差组(Non-locally Enhanced Residual Group,NLRG) ,提取深度特征,捕获长距离空间上下文信息(long-distance spatial contextual information)
- 提出了一个二阶通道注意力机制(Second-order Channel Attention,SOCA)以实现特征的相关性学习

从图中1可以看出SAN的主要由四部分组成:浅层特征提取(shallow feature extraction)即第一个卷积,非局部增强残差组(NLRG) 提取深度特征(deep feature,DF),上采样模块(upscale module),重建模块(reconstruction part)即最后一个卷积。
四个部分对应四个公式:
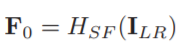
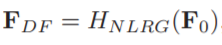
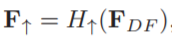
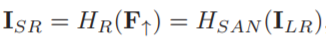
7.CSNLN
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9157565
https://blog.csdn.net/weixin_43514766/article/details/109996899
背景:
现有的基于非局部注意力机制的方法如RCAN、SAN,都只探索了统一尺度的特征,而忽略了不同尺度间的丰富信息,造成重建结果相对较差。
那么,什么是Cross-Scale呢?
一般来说,在做单图像超分辨率时,我们会将注意力集中在LR图像上,也就是说,我们想尽可能地利用这个LR图像提供的信息,跟LR死磕,这就是Single-Scale;而Cross-Scale的思想是,我们别只盯着LR看了,看看别的吧!于是乎,我们将LR做下采样,希望该下采样的结果和LR之间的相对关系也能为HR的重建提供信息。(之后会细讲)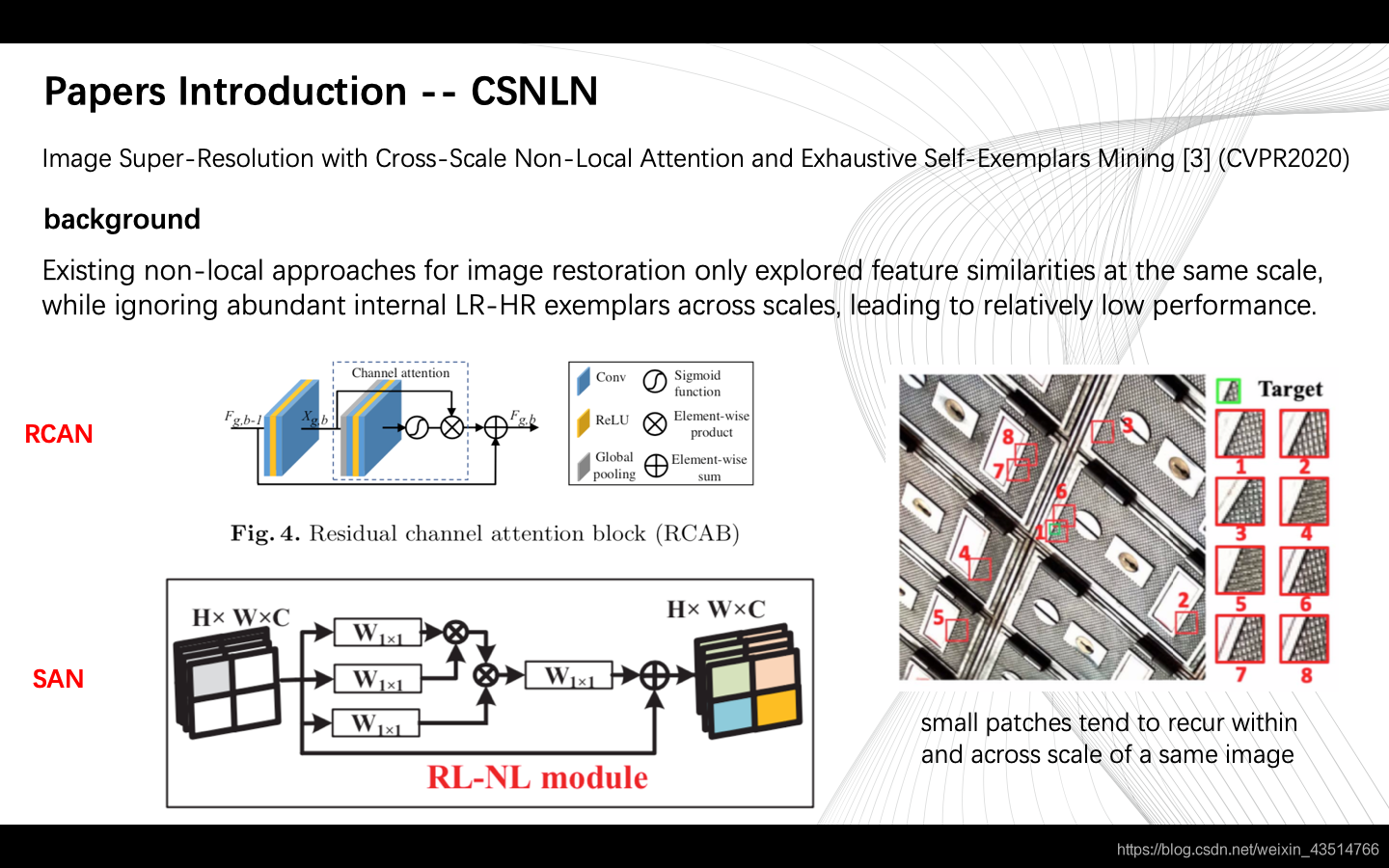
Introduction
自然图像中广泛存在跨尺度的块相似性,也就是说除了计算与本尺度内其他像素的相似度以外,像素还可以与更大的图像块做匹配【不太理解】。 自然的跨尺度特征对应关系使我们可以直接从LR图像中搜索高频细节,从而实现更加真实,更加准确的重建。——具体看一下
论文主要有以下三点贡献:
- 提出了用于SISR任务的第一个跨尺度非局部(CS-NL)注意力模块,计算图像内部的像素到块以及块到块的相似性,实验证明挖掘跨尺度自相似性可以极大地提高SISR性能。
- 提出了一个强大的SEM单元,在单元内部,通过结合局部,尺度内非局部和跨尺度非局部特征相关性,尽可能挖掘更多的的先验信息。
- 该网络在多个图像基准数据集上达到了最佳性能。文章末尾的消融实验进一步验证了该新型网络的有效性。
Attention Mechanism
In recent years, there is an emerging trend of applying non-local attention mechanism to solve various computer vision problems. In general, non-local attention in deep CNNs allows the network to concentrate more on informative areas.
下图是注意力机制在卷积神经网络中的一种体现——通道注意力,来自SENet文章。

在计算注意力之前,各通道的权重是相同的,在颜色上看来,都是白色;在加上注意力后,根据重要程度,每个通道被赋予不同的权重,在图上看来,每个通道用不同的颜色表示。
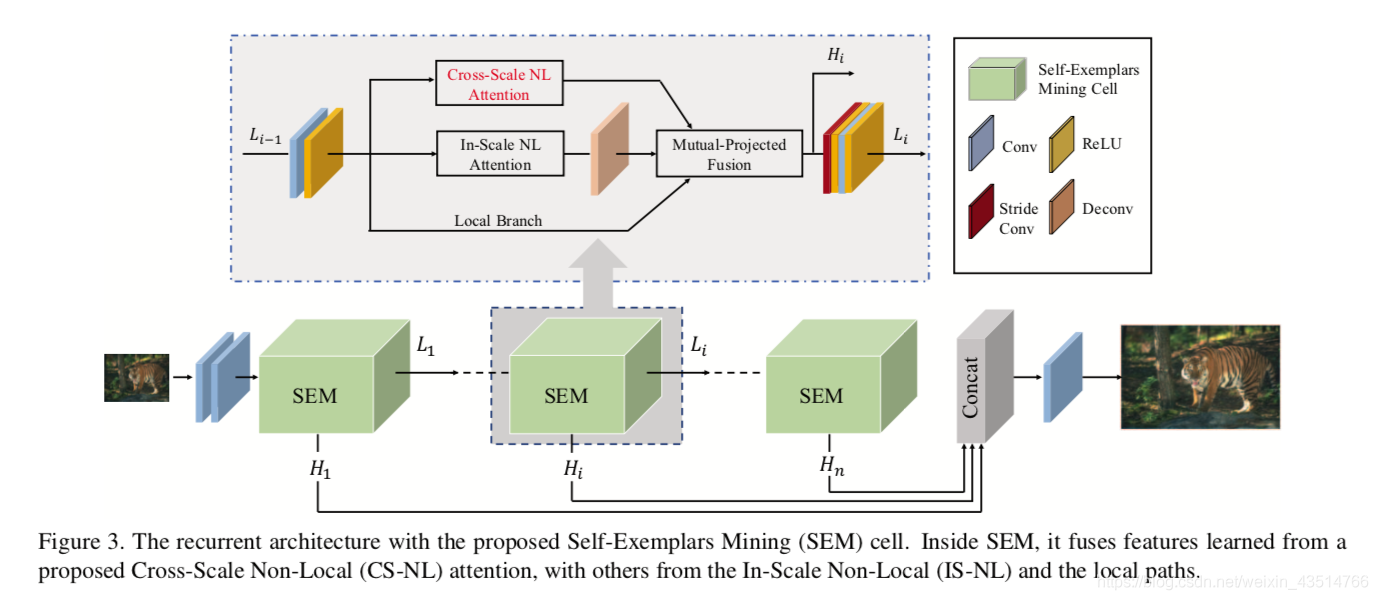
Method
总的网络结构如下图所示。本质上是一个递归神经网络,每个递归单元称为自样本挖掘模块(SEM),它们完全融合了局部,规模内非局部以及新提出的跨尺度非局部(CS-NL)信息。
CS-NL Attention Module
该模块的核心公式: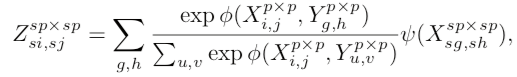
X:特征图;大小为原始低分辨率图像大小。
Y:下采样后的特征图。
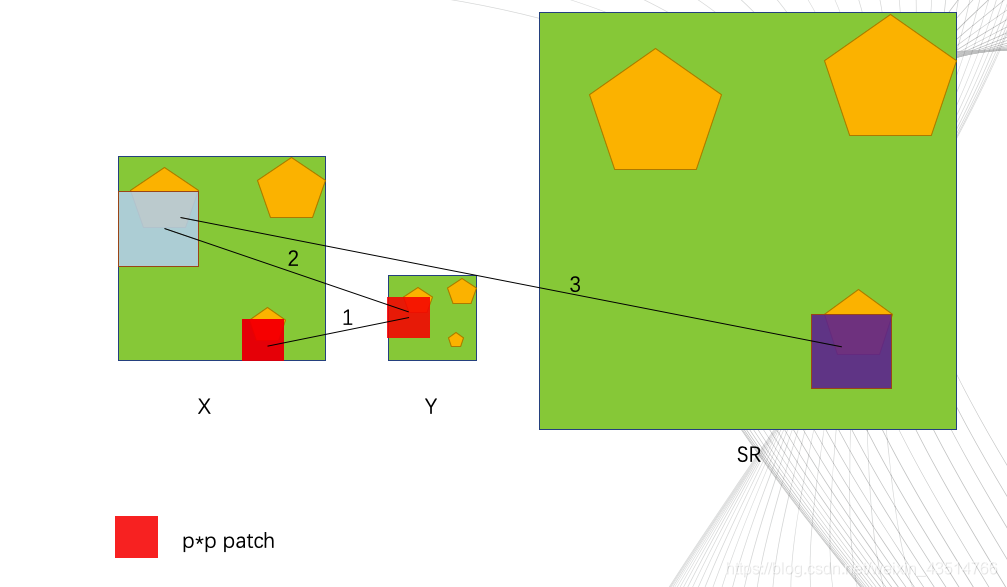
对草图的简要说明:
红色的小方块儿是pxp(p是可调参数)尺寸的,举个例子🌰,如果我们想重建X中的红色小方块的部分(target),首先我们在X的下采样结果Y中搜寻与该target接近的小块儿(不止一个,为了方便,只画了一个,实际上应该是多个结果进行加权),Y中的小块就是与target接近的小块,此时,我们在X中找到对应该小块的“大”块,就是蓝色这块;最后,用蓝色块中的信息辅助重建目标块——SR中的紫色块。(不知道说没说明白,语言表达能力太差😕)
再看看公式:
黄框里的部分就实现的块匹配(patch-matching),计算各小块的权重。
黄框外的部分就是用得到的权重将原始图映射到目标尺寸,得到重建后的图。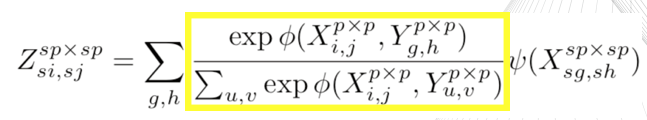
Self-Exemplars Mining (SEM) Cell
这一模块的结构如下图所示。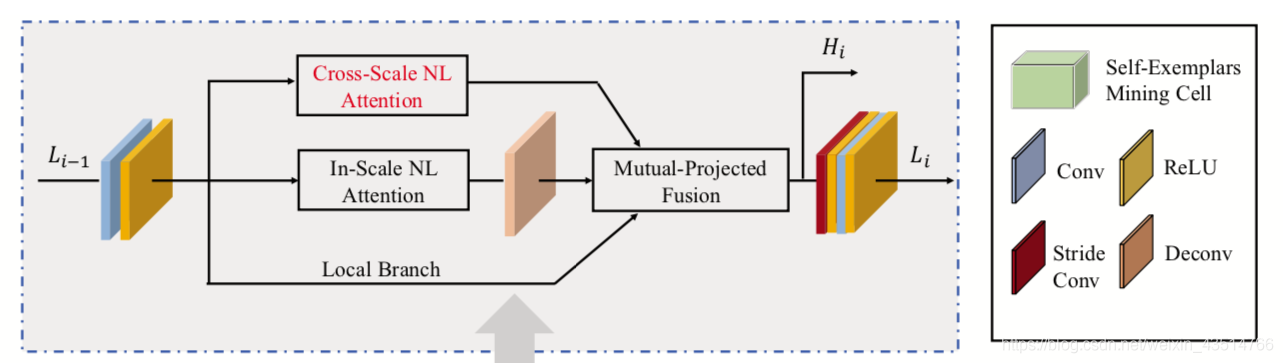
Local Branch不对Li-1做任何操作,直接搬过来;Cross-Scale NL Attention上一部分已经说了;In-Scale NL Attention计算的是特征图内像素间的非局部相似性。Mutual-Projected Fusion块将三部分的特征进行融合,融合方法见下图。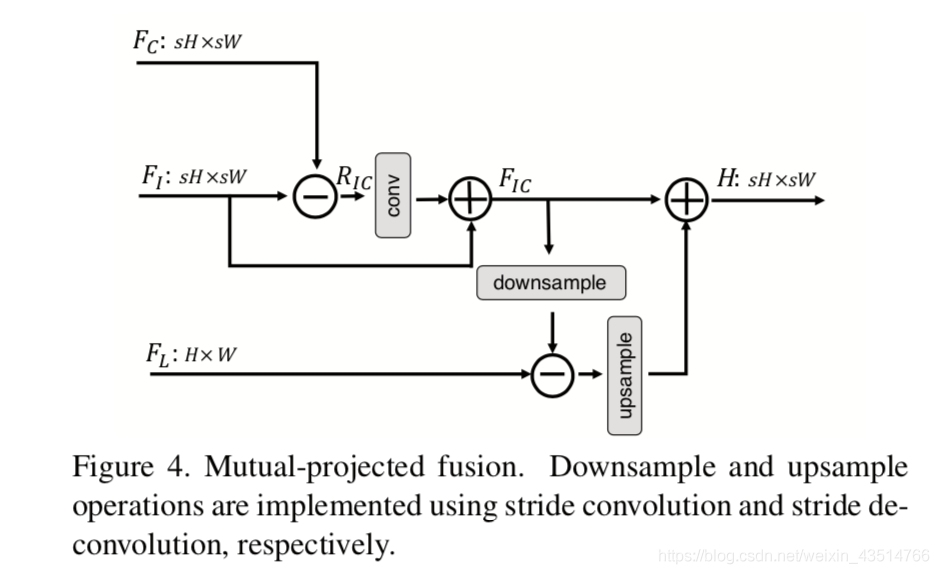
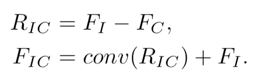
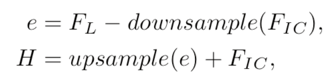
残差特征RIC表示一个来源中存在而另一来源中不存在的细节。 这种残差间的投影使网络绕过共有信息,仅关注不同源之间的特殊信息,从而提高了网络的判别能力。同时加入了反投影的思路,Mutual-Projected Fusion结构可确保在融合不同特征的同时进行残差学习,与琐碎的加法(adding)或串联(concatenating)操作相比,该融合方法可进行更具判别性的特征学习。
Recurrent Framework
重复的SEM单元嵌入到循环框架中,具体,还是看这张图。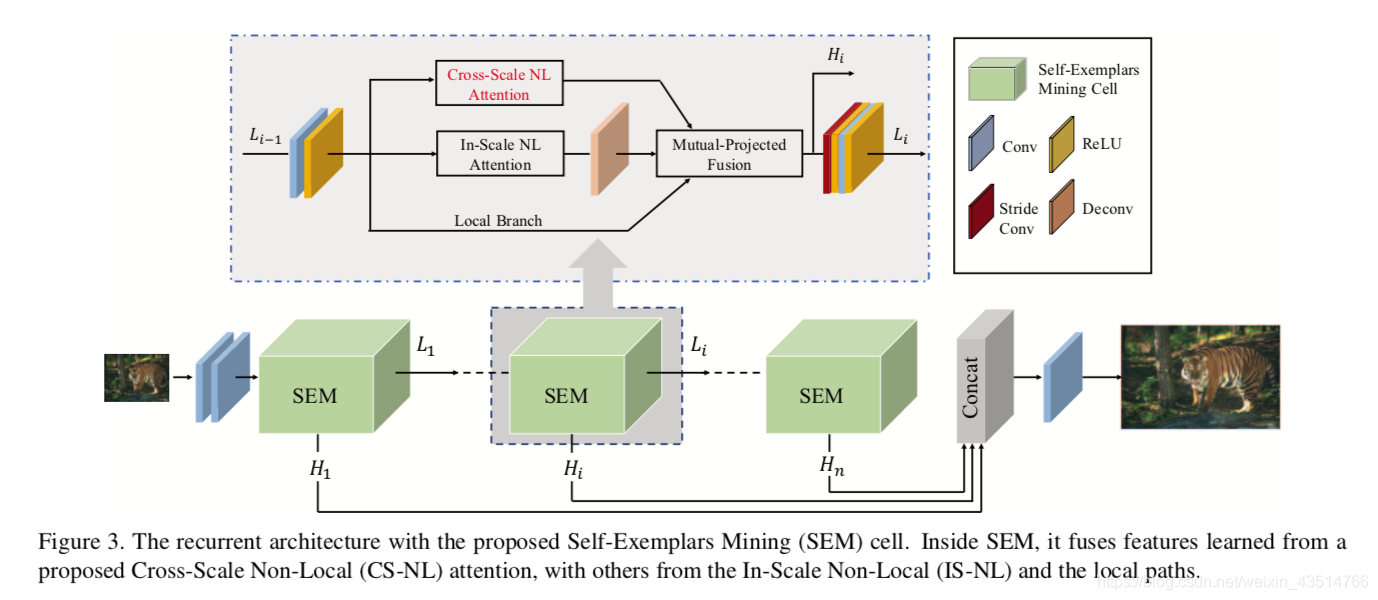

若有收获,就点个赞吧
0 人点赞
