Enhanced Deep Residual Networks for Single Image Super-Resolution
Enhanced Deep Residual Networks for Single Image Super-Resolution.pdf
https://blog.csdn.net/MR_kdcon/article/details/123518292
这篇文章是SRResnet的升级版——EDSR,其对网络结构进行了优化(去除了BN层),省下来的空间可以用于提升模型的size来增强表现力。此外,作者提出了一种基于EDSR且适用于多缩放尺度的超分结构——MDSR。
EDSR在2017年赢得了NTIRE2017超分辨率挑战赛的冠军。
摘要
- 作者推出了一种加强版本的基于Resnet块的超分方法,它实际上是在SRResnet上的改进,去除了其中没必要的的BN部分,从而在节省下来的空间下扩展模型的size来增强表现力,它就是EDSR,其取得了当时SOAT的水平。
- 此外,作者在文中还介绍了一种基于EDSR的多缩放尺度融合在一起的新结构——MDSR。
- EDSR、MDSR在2017年分别赢得了NTIRE2017超分辨率挑战赛的冠军和亚军。
- 此外,作者通过实验证明使用L 1 − L o s s比L 2 − L o s s 具有更好的收敛特性。
介绍
近几年来,深度学习在SR领域展现了较好的图像高分辨率重建表现,但是网络的结构上仍然存在着一些待优化的地方:
深受神经网络的影响,SR网络在超参数(Hyper-parameters)、网络结构(Architecture)十分敏感。
之前的算法(除了VDSR)总是为特定up-scale-factor而设计的SR网络,即scale-specific,将不同缩放尺度看成是互相独立的问题,因此我们需要一个统一的网络来处理不同缩放尺度的SR问题,比如× 2 , 3 , 4,这比训练3个不同缩放尺度的网络节省更多的资源消耗。
针对第一个网络结构问题,作者在SRResNet的基础上,对其网络中多余的BN层进行删除,从而节约了BN本身带来的存储消耗以及计算资源的消耗,相当于简化了网络结构。此外,选择一个合适的loss function,作者经过实验证明L 1 − L o s s比L 2 − L o s s 具有更好的收敛特性。
Note:
MSE就是典型的L 2 − L o s s L2-LossL2−Loss。
针对第二个多缩放尺度问题,作者用2种不同的方式去处理:
- 使用低缩放尺度(× 2)训练之后的模型作为高缩放尺度的初始化参数,结果取得很好的表现,说明不同尺度之间是有内在相关联系的。
- 作者设计以了一个可以结合多尺度的SR网络MDSR,除了网络的头部和尾部为各个缩放尺度独立之外,中间部分是共享网络。这种多尺度SR网络具有和单一缩放网络相近的表现力,且相比n nn个单一网络,n nn个尺度相结合的MDSR消耗更少的资源。
提出的方法
本节将正式开始介绍一种增强版本的SRResNet——EDSR(一种single-scale网络),它通过移除了适合分类这种高级计算机视觉任务而不适合SR这种低级计算机视觉任务的BN层来减少计算资源损耗。
除此之外,本节还会介绍一种集合了多尺度于一个网络中的multi-scale超分网络——MDSR。
为什么BN不适合低级CV任务? Batch Norm可谓深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,可以防止模型过拟合。在很多基于CNN的分类任务中,被大量使用。 但在图像超分辨率和图像生成方面,Batch Norm的表现并不好,加入了Batch Norm,反而使得训练速度缓慢,不稳定,甚至最后发散。
以图像超分辨率来说,网络输出的图像在色彩、对比度、亮度上要求和输入一致,改变的仅仅是分辨率和一些细节,而Batch Norm,对图像来说类似于一种对比度的拉伸,任何图像经过Batch Norm后,其色彩的分布都会被归一化,也就是说,它破坏了图像原本的对比度信息,所以Batch Norm的加入反而影响了网络输出的质量。虽然Batch Norm中的scale和shift参数可以抵消归一化的效果,但这样就增加了训练的难度和时间,还不如直接不用。
Residual blocks
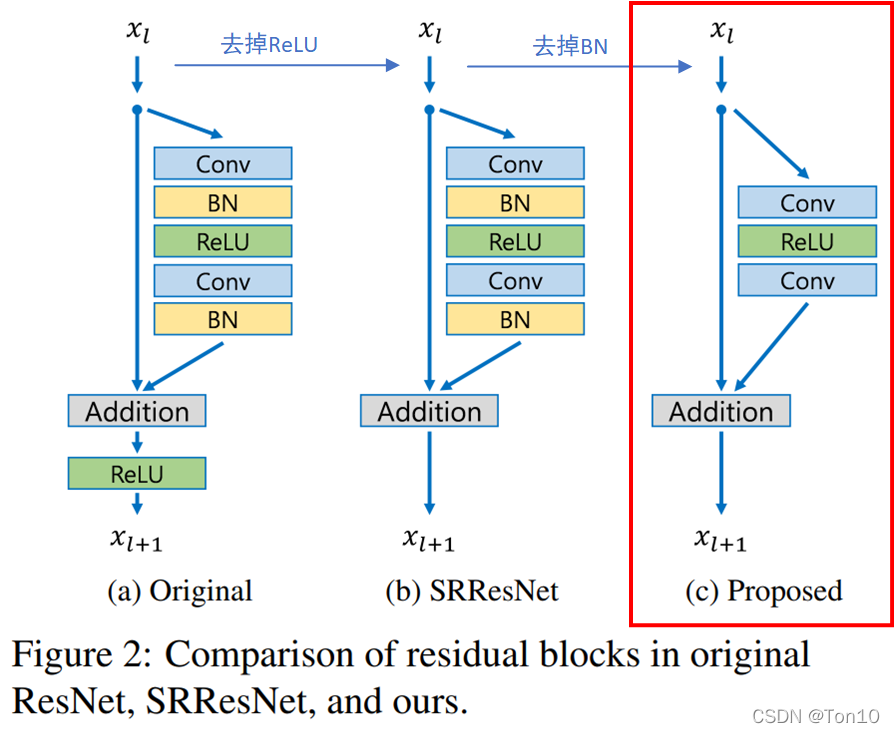
移除BN有以下三个好处:
- 这样模型会更加轻量。BN层所消耗的存储空间等同于上一层CNN层所消耗的,作者指出相比于SRResNet,EDSR去掉BN层之后节约了40 % 的存储资源。
- 在BN腾出来的空间下插入更多的类似于残差块等CNN-based子网络来增加模型的表现力。
- BN层天然会拉伸图像本身的色彩、对比度,这样反倒会使得输出图像会变坏,实验也证明去掉BN层反倒可以增加模型的表现力。
Single-Scale Model
EDSR是SRResNet的增强版本,是一种基于上图红框所示的残差块。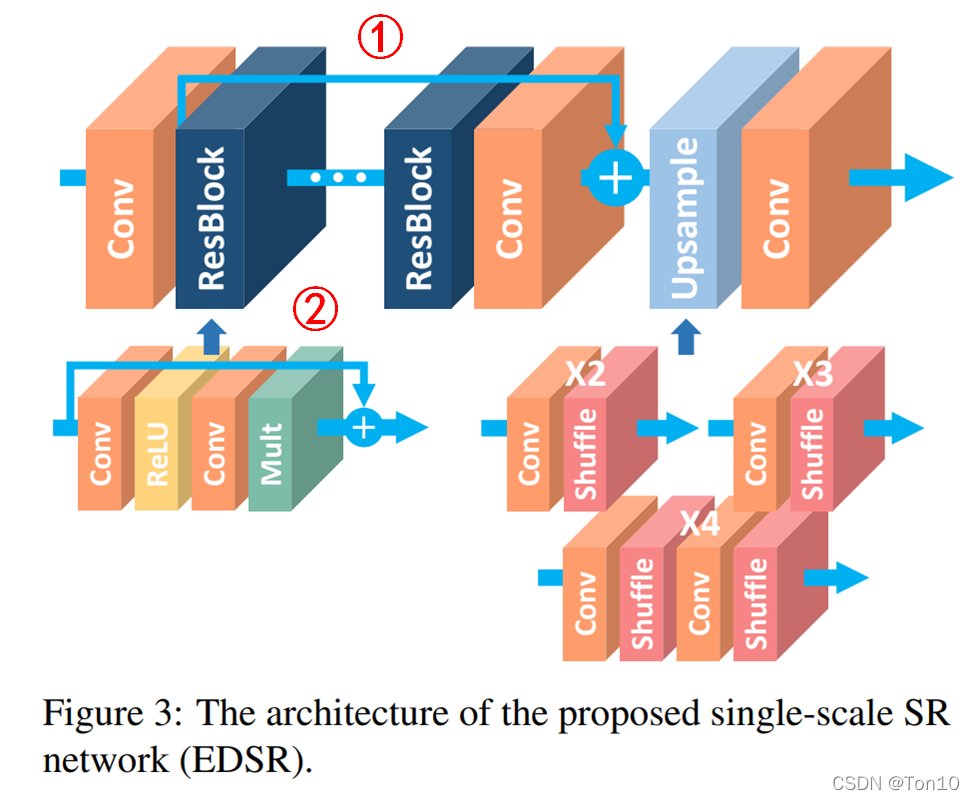
如上图所示就是EDSR的结构:最上面一排是网络结构,可以大致分为低层特征信息提取、高层特征信息提取、反卷积(上采样)层、重建层,基本和SRResNet、SRDenseNet是类似的。下面第二层分别表示残差块的构造以及反卷积层(分别是× 2 、 × 3 、 × 4)的构造。
Note:
- 连接①是将不同level的特征信息进行合并;连接②是ResNet块内部的残差连接。
- 在EDSR的baseline中,是没有residual scaling的,因为只是用到了64层feature map,相对通道数较低,几乎没有不稳定现象。但是在最后实验的EDSR中,作者是设置了residual scaling中的缩减系数为0.1,且B = 32 , F = 256。
增加模型表现力最直接的方式就是增加模型的参数(复杂度),一般可以通过增加模型层数B(即网络深度)以及滤波器个数F(即网络宽度或者说通道数)。此外两者对于存储资源的消耗大约是 ,增加的参数大约是
,增加的参数大约是 ,因此增加滤波器个数才能在有限存储空间下最大化参数个数。
,因此增加滤波器个数才能在有限存储空间下最大化参数个数。
Multiple-Scale Model
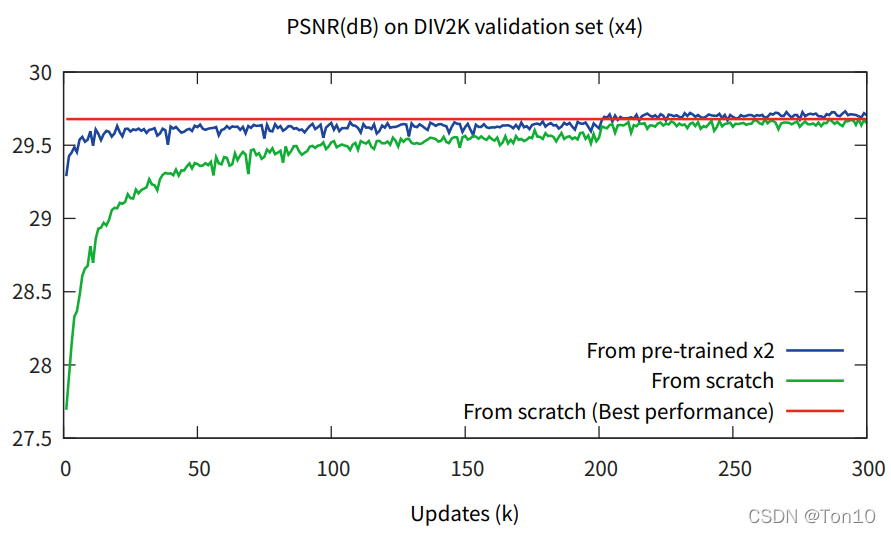 上图蓝色线表示的用训练好的up-scale-factor=2的EDSR网络作为× 3 , 4 训练时候的初始化参数,结果来看收敛速度以及表现力的提升都是有目共睹的,这一定程度上说明了不同缩放尺度之间是存在某种内在联系的。
上图蓝色线表示的用训练好的up-scale-factor=2的EDSR网络作为× 3 , 4 训练时候的初始化参数,结果来看收敛速度以及表现力的提升都是有目共睹的,这一定程度上说明了不同缩放尺度之间是存在某种内在联系的。
因此作者设计了一种在单一网络中实现多尺度融合的SR网络——MDSR,其结构如下: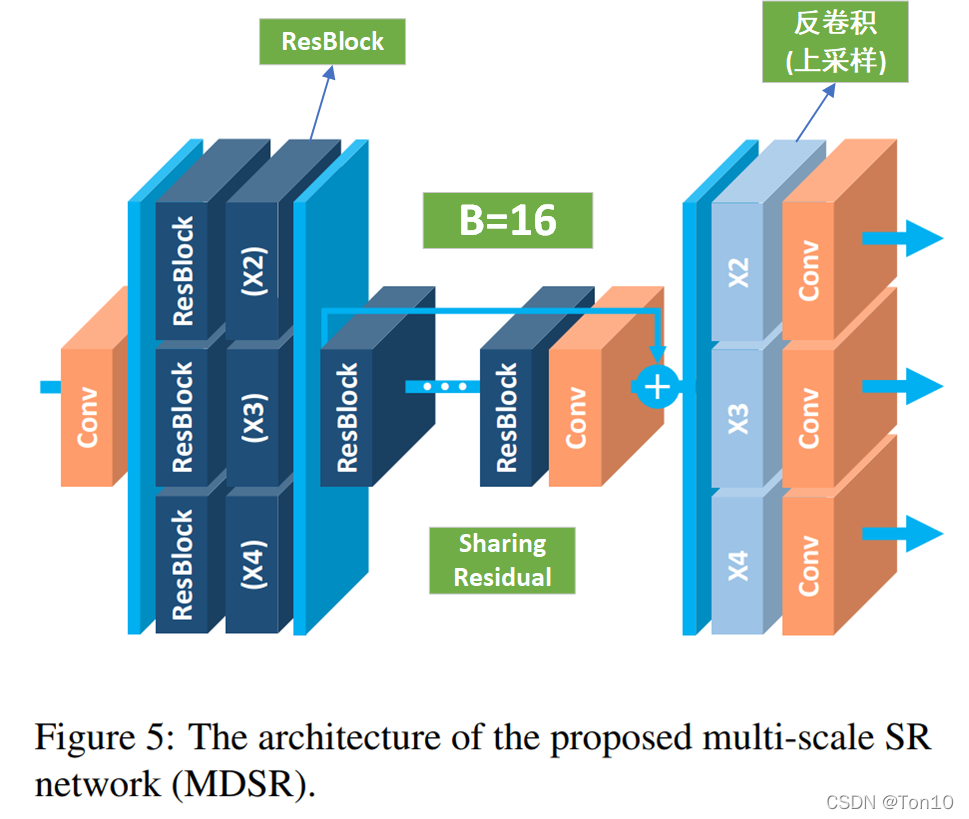
如上图所示是MDSR的网络结构,每个预处理模块由2个5 × 5 的卷积层组成,针对每一种up-scale-factor设置不同的残差快;中间是一个共享残差网络;尾巴处是针对不同缩放倍数设计的上采样网络: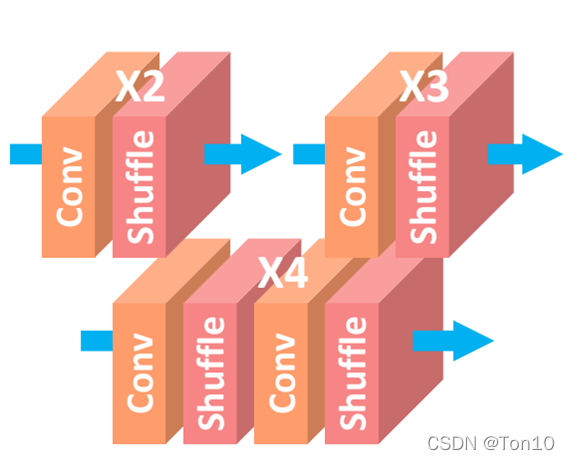
Note:
- 总体来说,MDSR是基于EDSR的结构。
- 预处理阶段的残差块中的卷积采用较大的5 × 5卷积核来增大初始阶段的感受野。
- 作者统计了一笔数据,训练3个单独的EDSR-baseline来实现不同放大倍数的SR需要消耗1.5 M ∗ 3 = 4.5 M 1.5M*3=4.5M1.5M∗3=4.5M的参数量;而训练一个MDSR的baseline需要3.2 M 3.2M3.2M的参数量,而MDSR在后续实验中表现也还不错,因此MDSR是一种资源消耗相对少且有一定表现力的SR网络。

若有收获,就点个赞吧
0 人点赞
