https://www.bilibili.com/video/BV1yg411K7Yc?spm_id_from=333.337.search-card.all.click
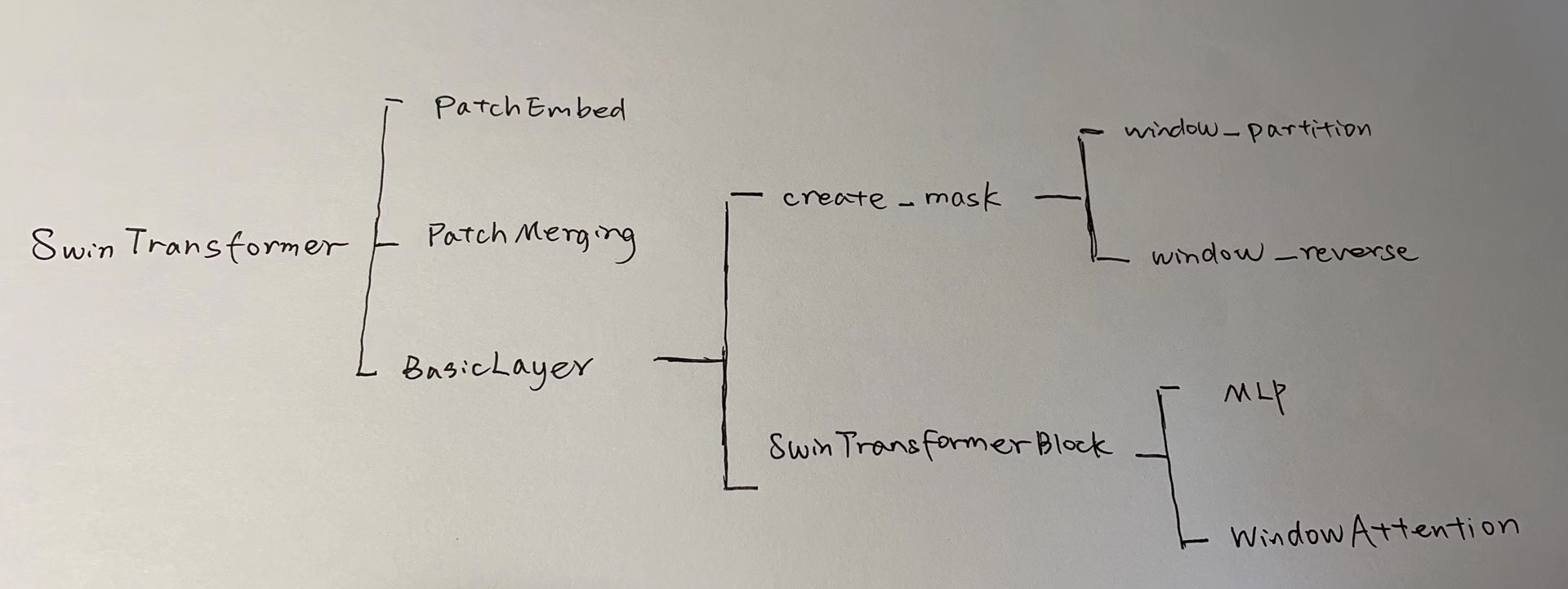
Class SwinTransformer
class SwinTransformer(nn.Module):r""" Swin TransformerA PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -https://arxiv.org/pdf/2103.14030Args:patch_size (int | tuple(int)): Patch size. Default: 4in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each Swin Transformer layer.num_heads (tuple(int)): Number of attention heads in different layers.window_size (int): Window size. Default: 7mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Truedrop_rate (float): Dropout rate. Default: 0attn_drop_rate (float): Attention dropout rate. Default: 0drop_path_rate (float): Stochastic depth rate. Default: 0.1norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.patch_norm (bool): If True, add normalization after patch embedding. Default: Trueuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False"""def __init__(self, patch_size=4, in_chans=3, num_classes=1000,embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),window_size=7, mlp_ratio=4., qkv_bias=True,drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, patch_norm=True,use_checkpoint=False, **kwargs):super().__init__()self.num_classes = num_classesself.num_layers = len(depths)self.embed_dim = embed_dimself.patch_norm = patch_norm# stage4输出特征矩阵的channelsself.num_features = int(embed_dim * 2 ** (self.num_layers - 1))self.mlp_ratio = mlp_ratio# split image into non-overlapping patchesself.patch_embed = PatchEmbed(patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)self.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):# 注意这里构建的stage和论文图中有些差异# 这里的stage不包含该stage的patch_merging层,包含的是下个stage的layers = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,mlp_ratio=self.mlp_ratio,qkv_bias=qkv_bias,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,use_checkpoint=use_checkpoint)self.layers.append(layers)self.norm = norm_layer(self.num_features)self.avgpool = nn.AdaptiveAvgPool1d(1)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)def forward(self, x):# x: [B, L, C]x, H, W = self.patch_embed(x)x = self.pos_drop(x)for layer in self.layers:x, H, W = layer(x, H, W)x = self.norm(x) # [B, L, C]x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]x = torch.flatten(x, 1)x = self.head(x)return x
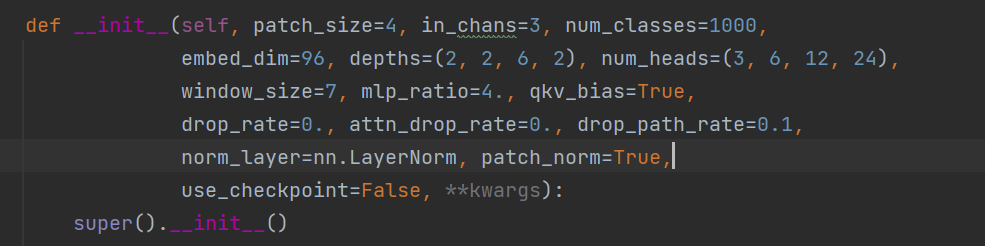
在这里有个def init()
里面是用来初始化Swin Transformer模型的。
1.patch_size
patch在Swin Transformer中指最小的图像块的大小。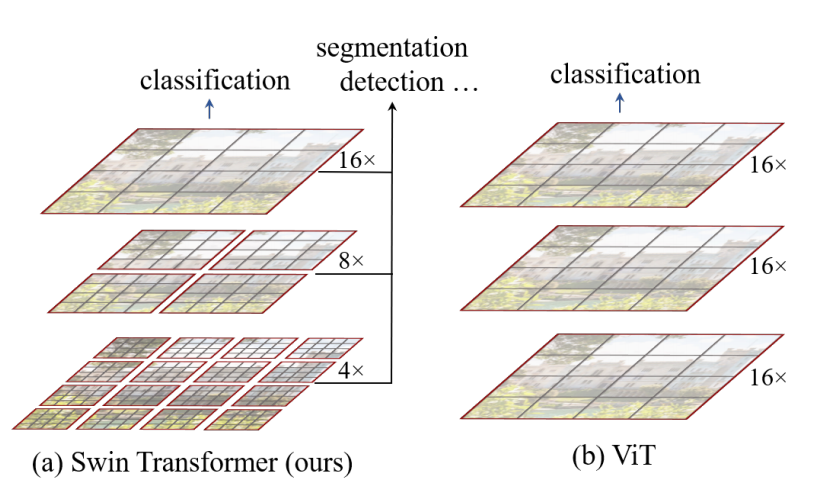
patch_size = 4就是4倍的下采样。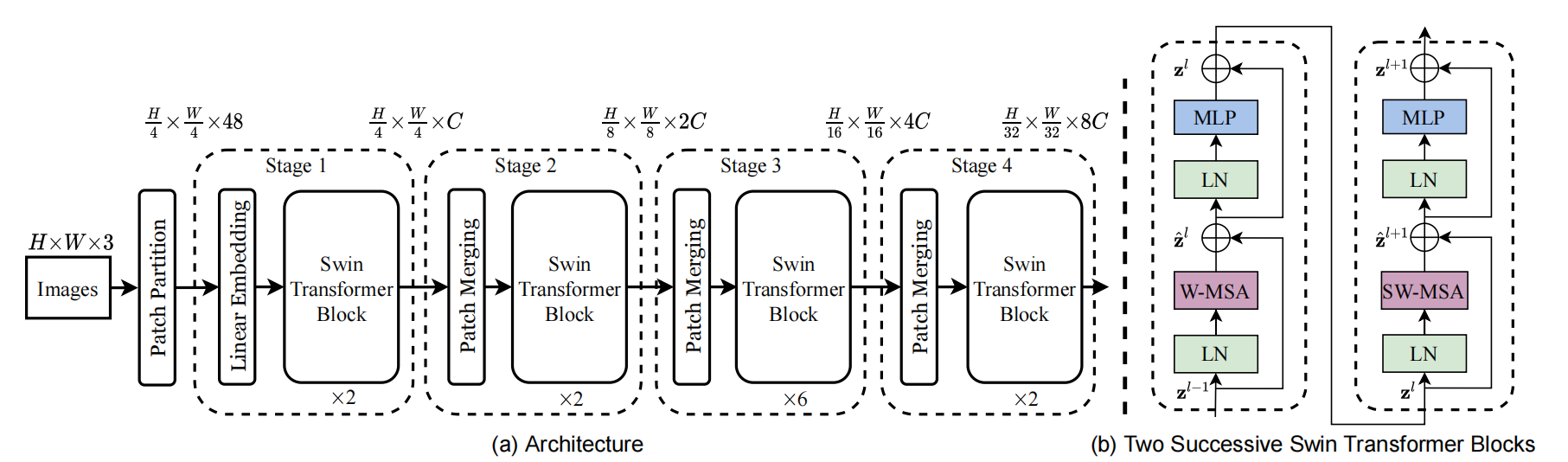
对应图中就是H/4 X W/4
2.depths=(2,2,6,2)
是对应于Stage1 ,2 ,3 ,4 分别用了几个Swin Transformer Block
3.num_heads = (3,6,12,24)
在Swin Transformer中,所采用的multi-head self-attention的个数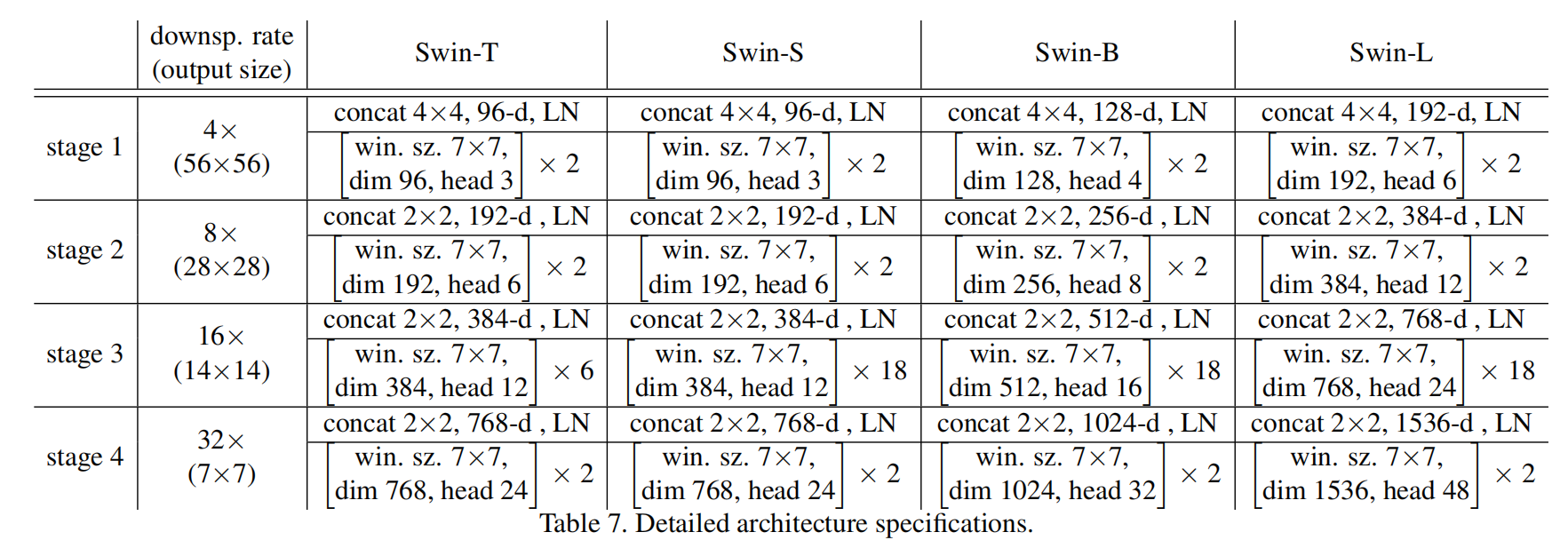
 这里有写3 ,6, 12, 24
这里有写3 ,6, 12, 24
除了这些参数,还有很多参数需要设置,但本质上都是配置模型。有些参数还得从ViT——Vision Transformer中去理解。
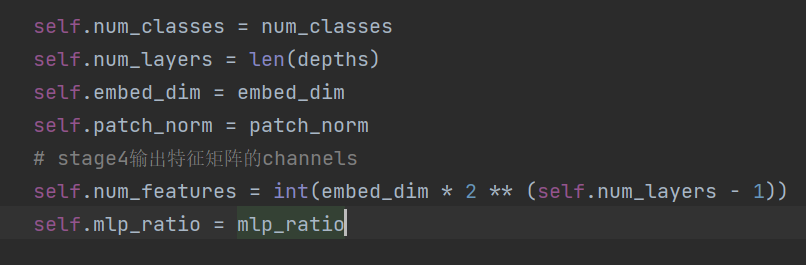
这里是把初始化的参数赋值给我们之后需要用到的参数。
Class PatchEmbed
PatchEmbed的作用就是将图片划分成一个个没有重叠的patches。
对应于——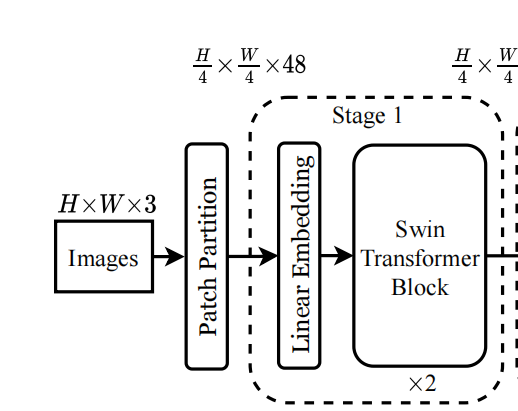 ,Patch Partition和Linear Embedding两个操作。
,Patch Partition和Linear Embedding两个操作。
self.patch_embed = PatchEmbed(patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):super().__init__()patch_size = (patch_size, patch_size)self.patch_size = patch_sizeself.in_chans = in_cself.embed_dim = embed_dimself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):_, _, H, W = x.shape# padding# 如果输入图片的H,W不是patch_size的整数倍,需要进行paddingpad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)if pad_input:# to pad the last 3 dimensions,# (W_left, W_right, H_top,H_bottom, C_front, C_back)x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],0, self.patch_size[0] - H % self.patch_size[0],0, 0))# 下采样patch_size倍x = self.proj(x)_, _, H, W = x.shape# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = x.flatten(2).transpose(1, 2)x = self.norm(x)return x, H, W
1.embed_dim=96
这里决定的是,transformer输入的维度。
2.下采样
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
这里利用卷积来实现下采样。
Conv2d的参数有:
1.in_channels
2.out_channels
3.kernel_size
4.stride
这里的kernel_size = patch_size 说明是用4x4来进行下采样。stride = patch_size,这样说明不会重叠。
3.def forward
def forward(self, x):_, _, H, W = x.shape# padding# 如果输入图片的H,W不是patch_size的整数倍,需要进行paddingpad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)if pad_input:# to pad the last 3 dimensions,# (W_left, W_right, H_top,H_bottom, C_front, C_back)x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],0, self.patch_size[0] - H % self.patch_size[0],0, 0))# 下采样patch_size倍x = self.proj(x)_, _, H, W = x.shape# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = x.flatten(2).transpose(1, 2)x = self.norm(x)return x, H, W
在开始卷积运算之前,要先做Padding的工作
pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)if pad_input:# to pad the last 3 dimensions,# (W_left, W_right, H_top,H_bottom, C_front, C_back)x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],0, self.patch_size[0] - H % self.patch_size[0],0, 0))
这里先用pad_input 判断输入是否需要pad
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
0, self.patch_size[0] - H % self.patch_size[0],
0, 0))
这里的
self.patch_size[1] - W % self.patch_size[1]
这句话的意思是,把缺德地方补上0。比如说,patch_size = 4 但是只有3个
4 - (4%3) =1 所以补上1个。
pad之后,就是Patch_size的整数倍了,就可以进行下采样了。
def forward从整体上来看,就是一个前向传播的过程。

若有收获,就点个赞吧
0 人点赞
