https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf

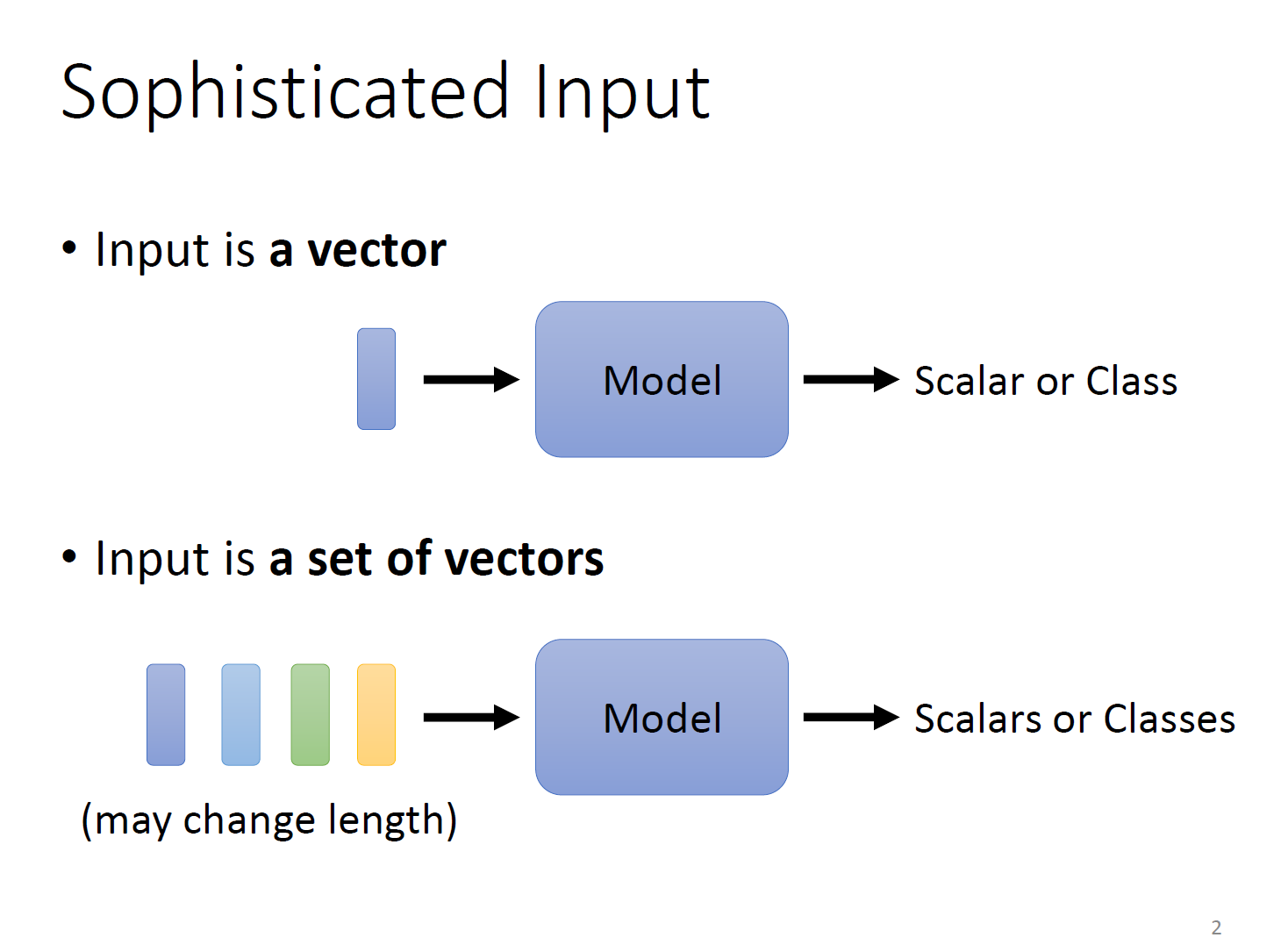
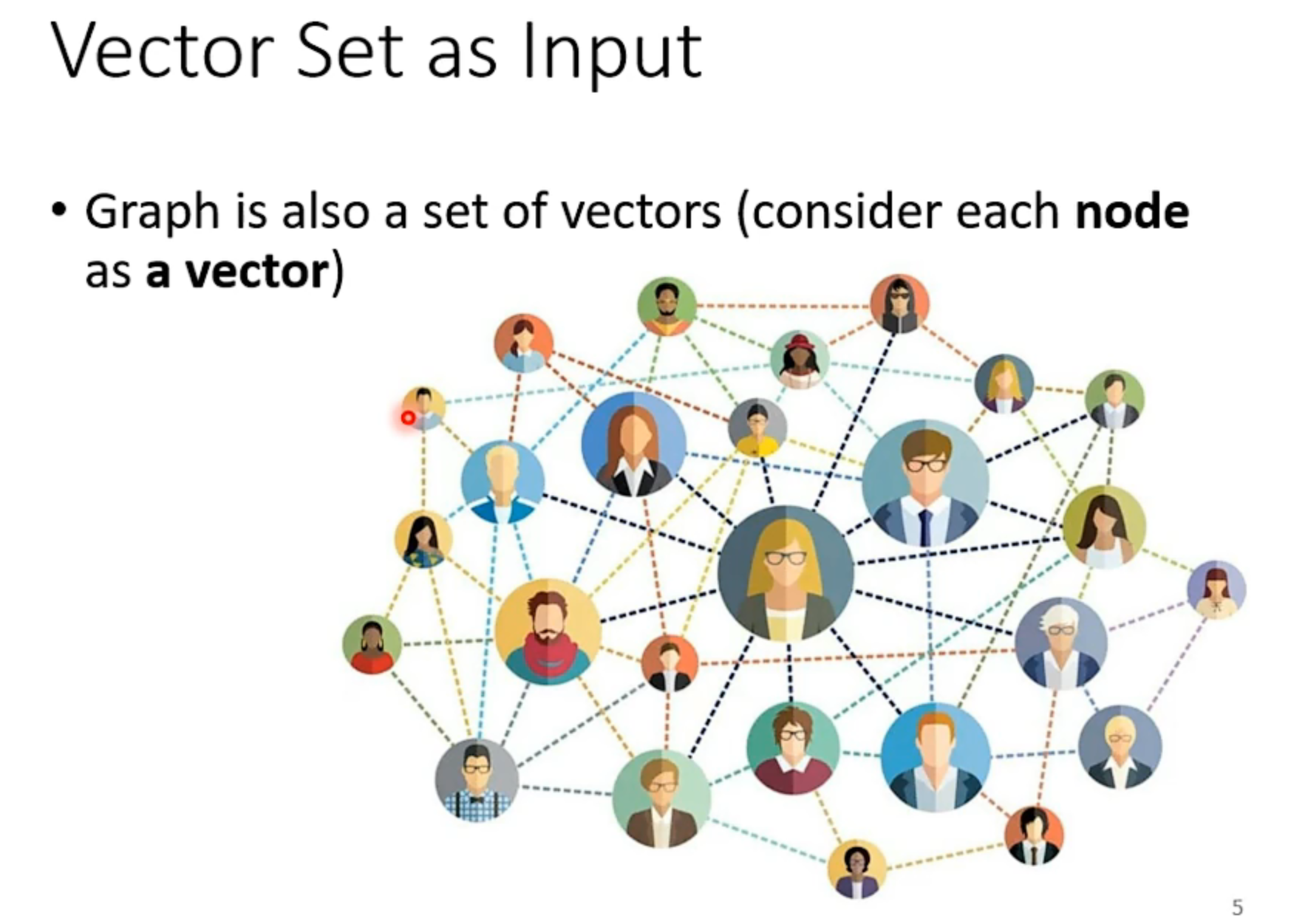
在之前我们处理的问题都是只有一个输入向量的情况。如果我们的模型有多个输入向量呢。
比如说,在文字处理领域。
在文字处理的时候,一个单词代表一个向量。
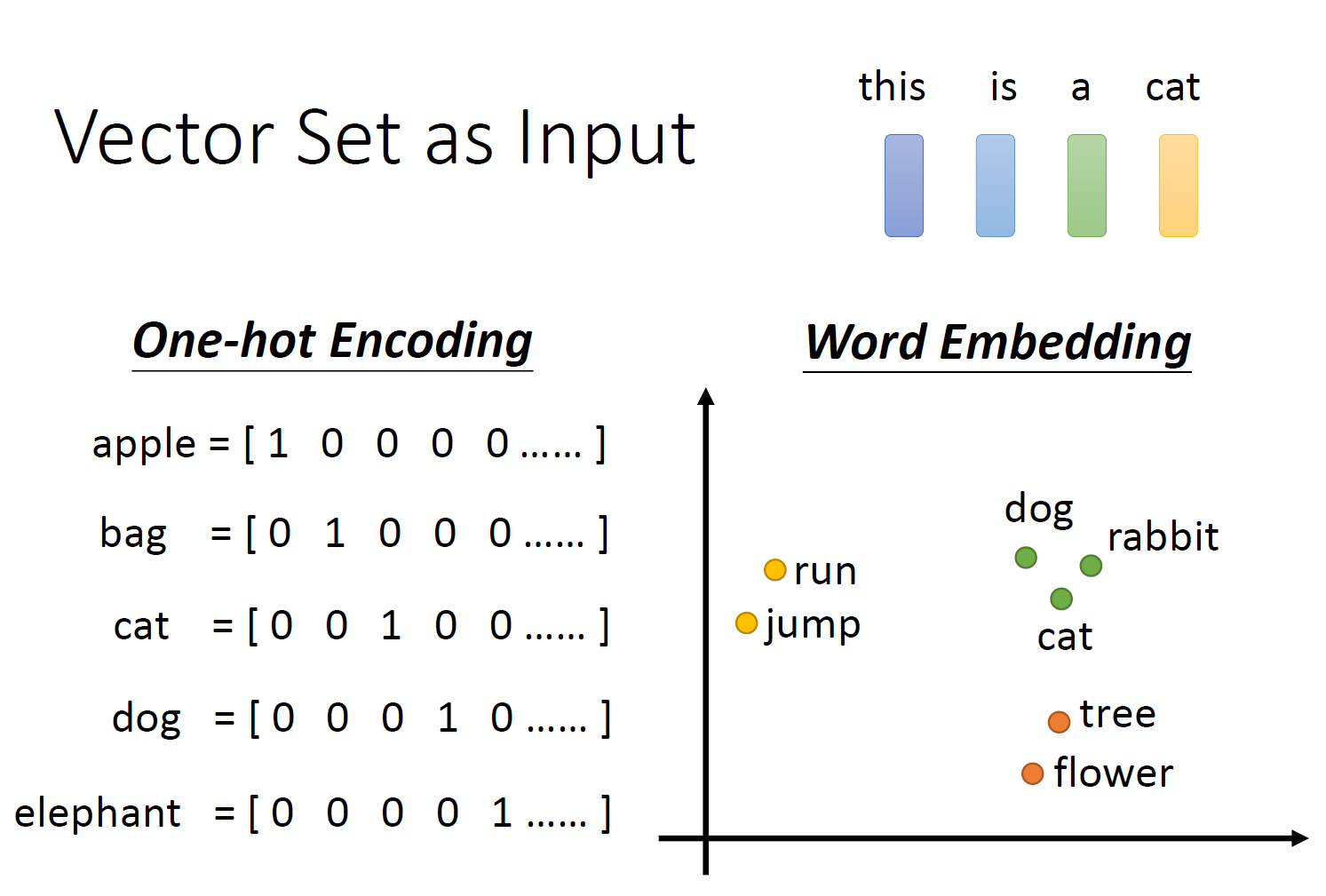
把单词转化成向量的时候,我们可以使用one-hot编码,但one-hot编码有几个问题,首先,内存肯定要存储很多东西,其次,我们找不到两个单词之间的联系。比如说cat和dog都是动物,但是从one-hot编码上看不出任何联系。
所以一般用Word Embedding编码,至于Word Embedding怎么实现的,这个就不管了。
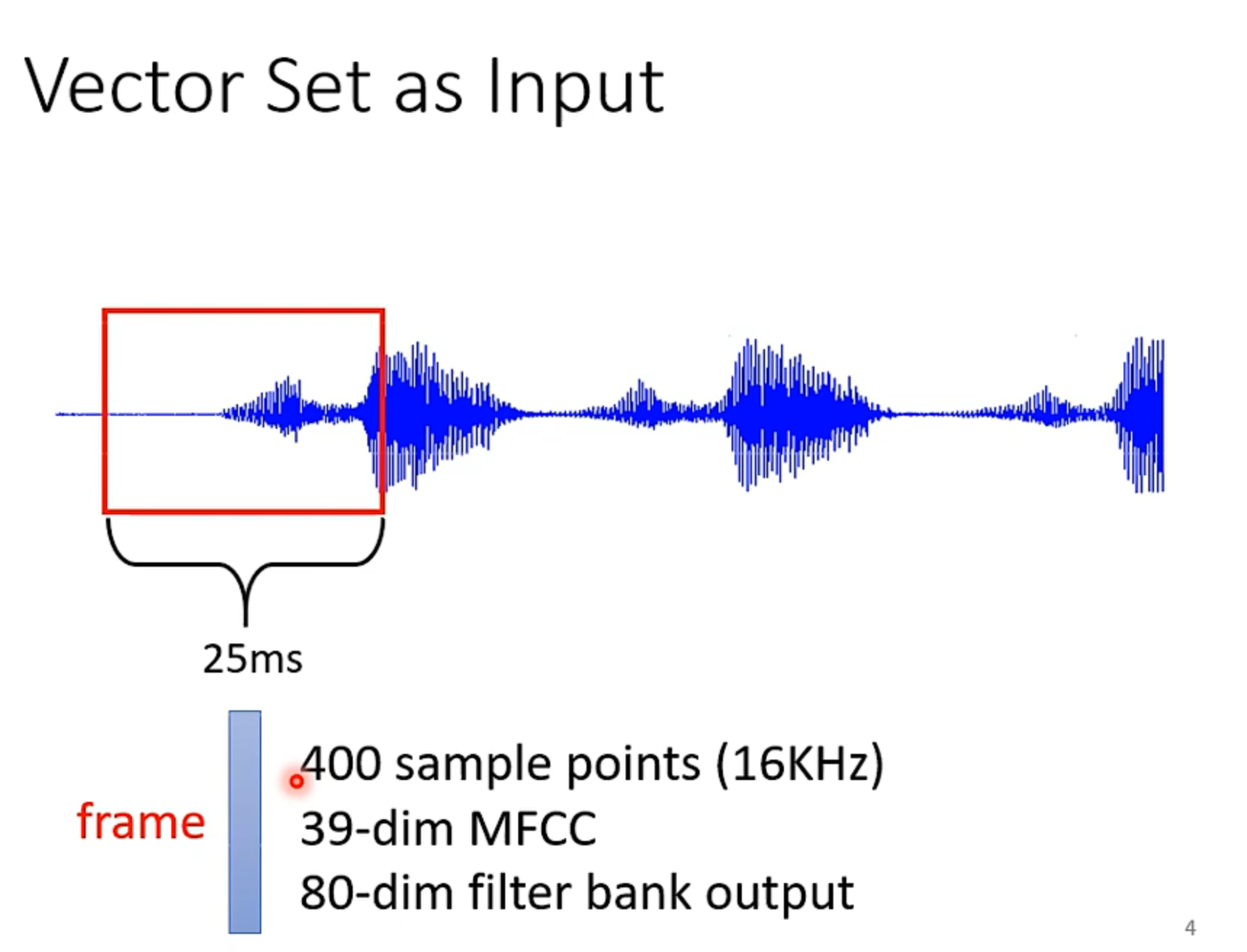
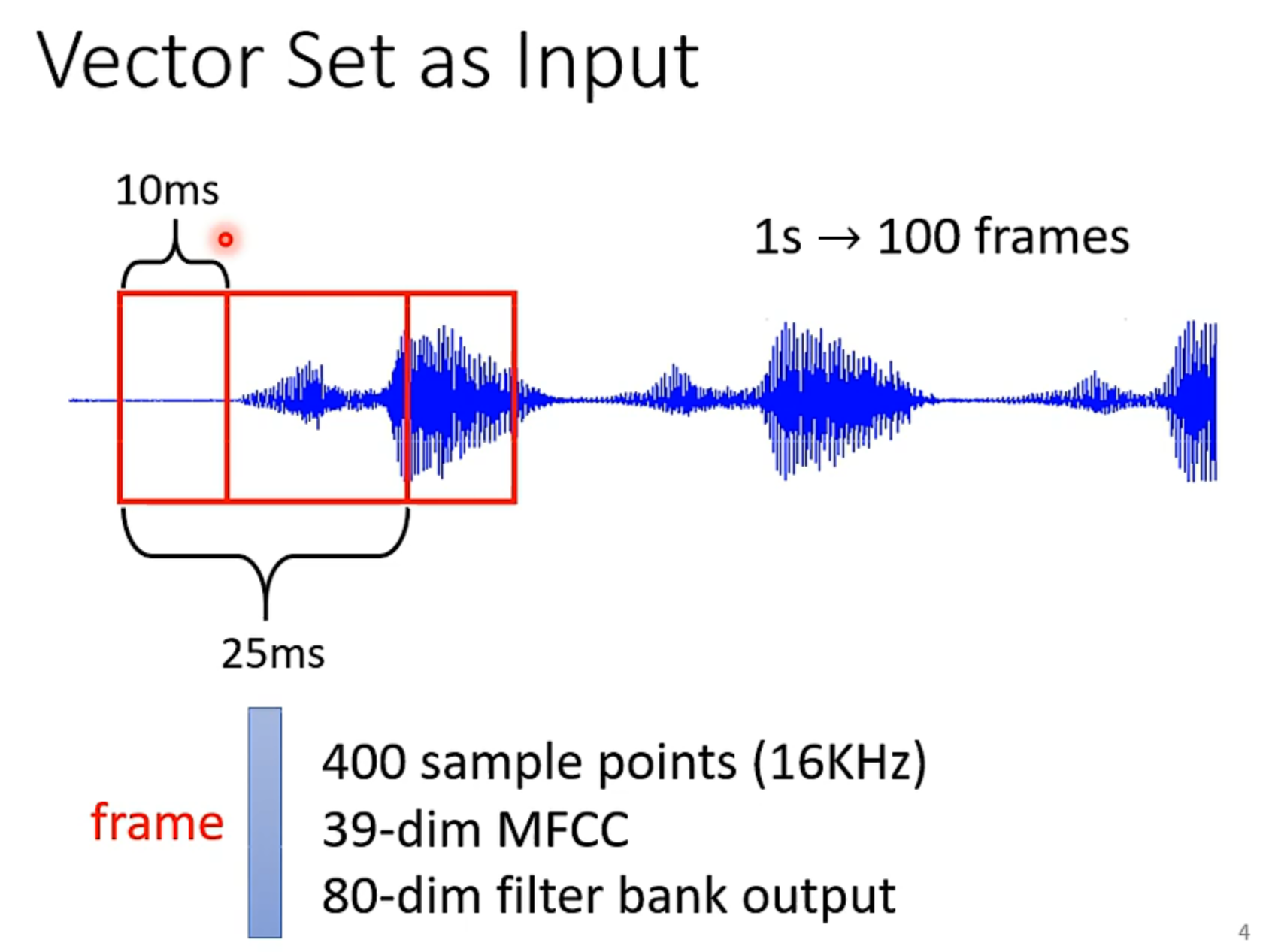
我们输入了一串语音信号,现在我们一般25ms取一个框,然后再转化为向量。至于怎么转化的就有很多方法了。
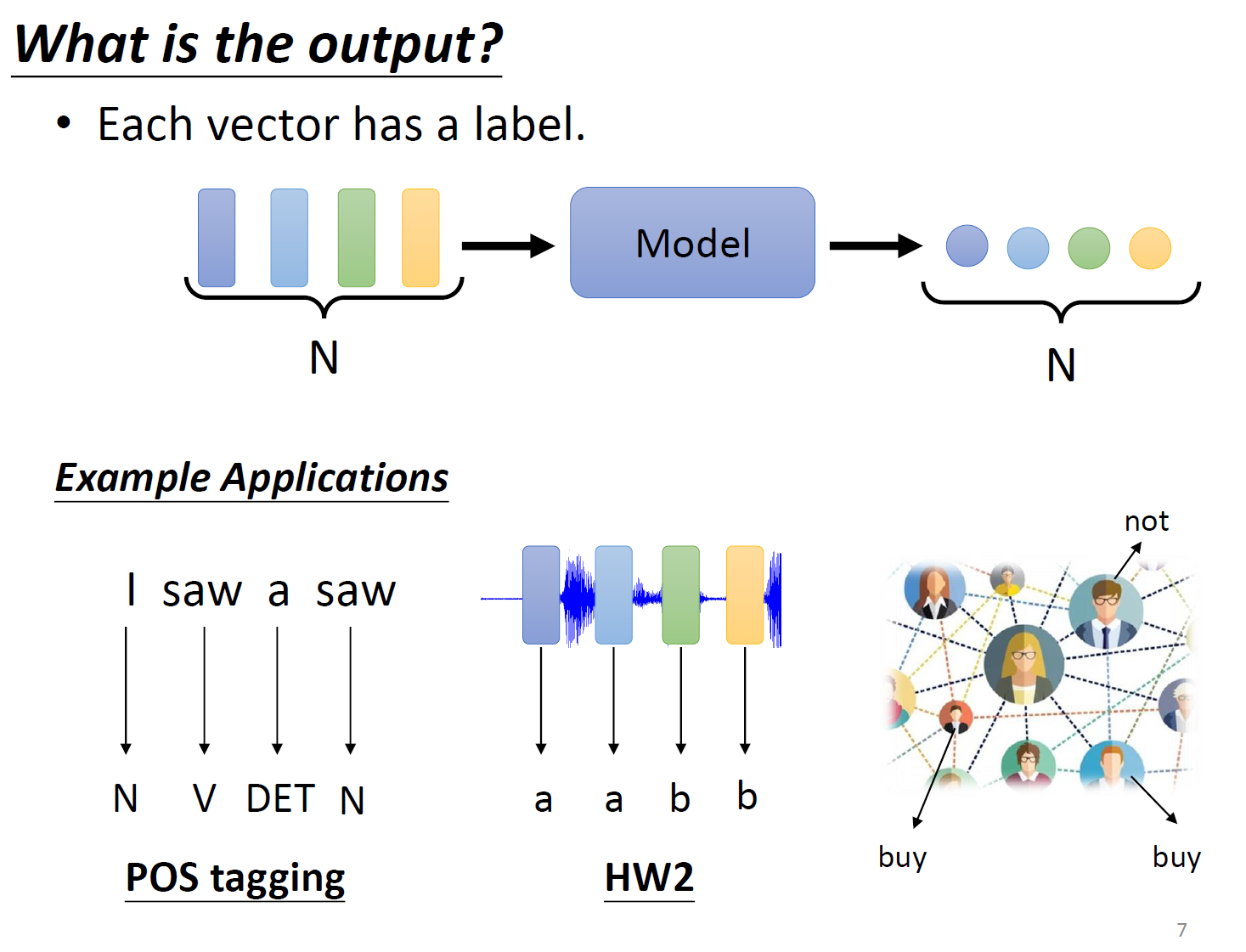
几个向量输入,就有几个对应的输出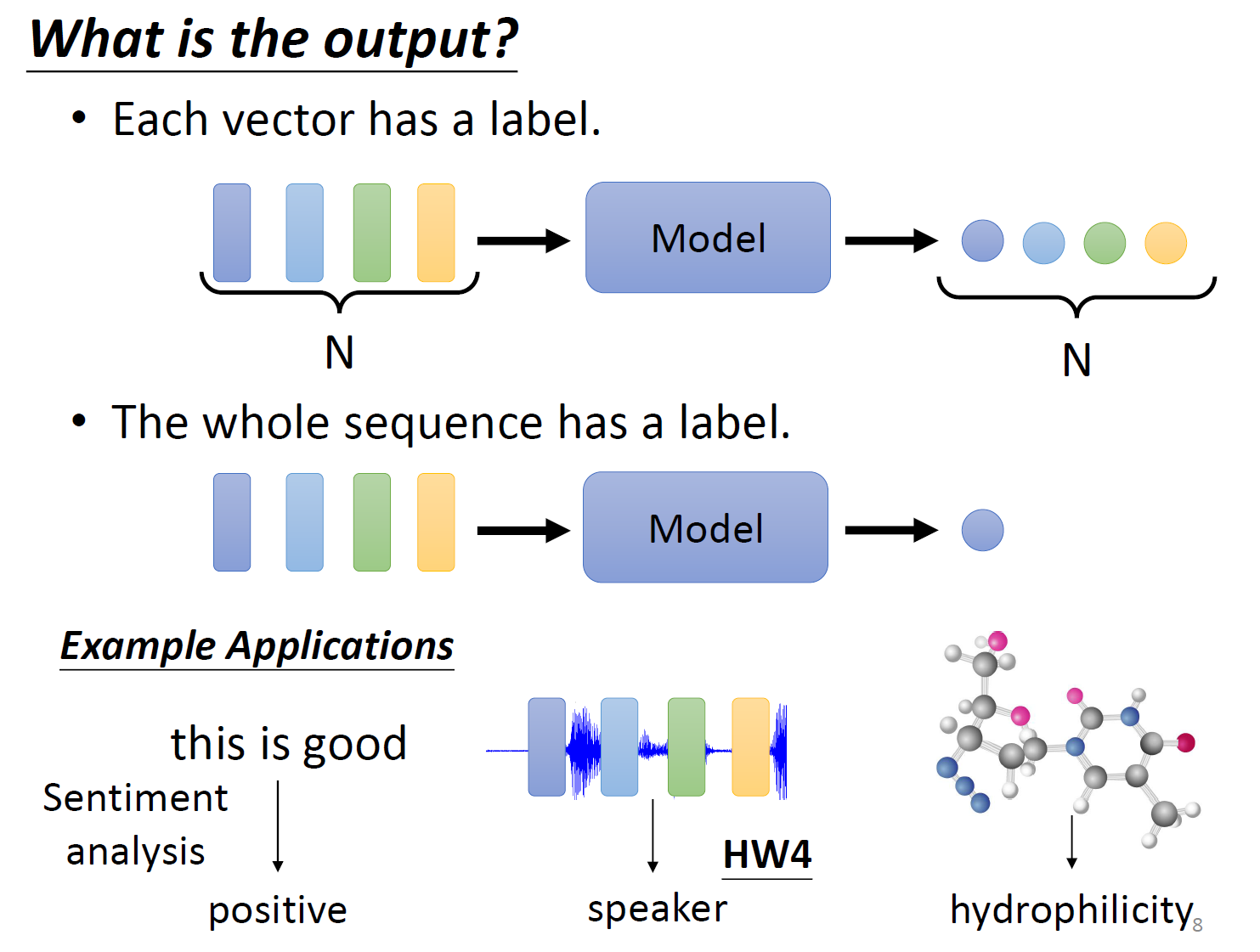
判断语义是正面的还是负面的,说话的人是谁。

把向量的前后,上下文共同输入模型。
更好的方法考虑Input Sequence的机制呢?



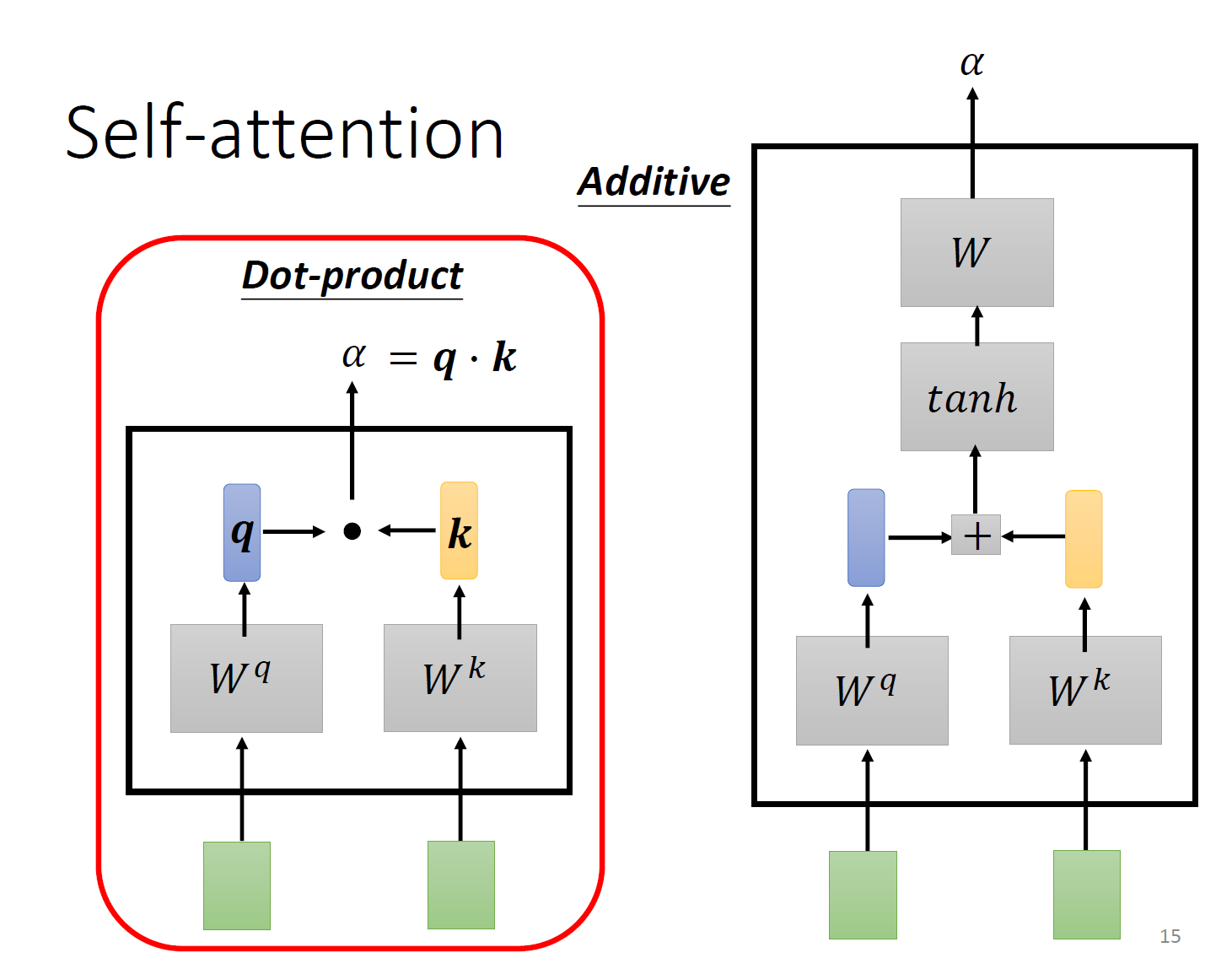
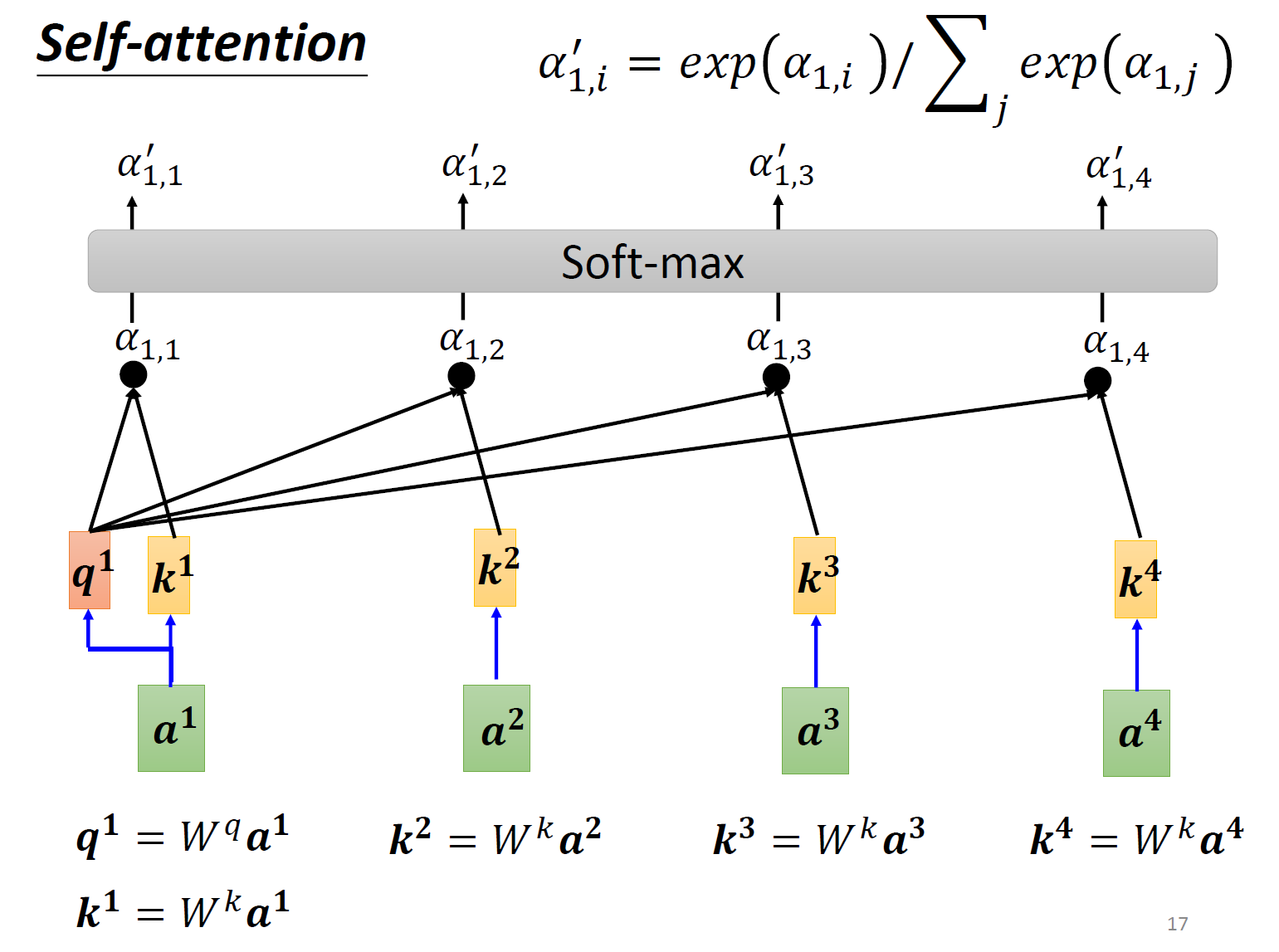
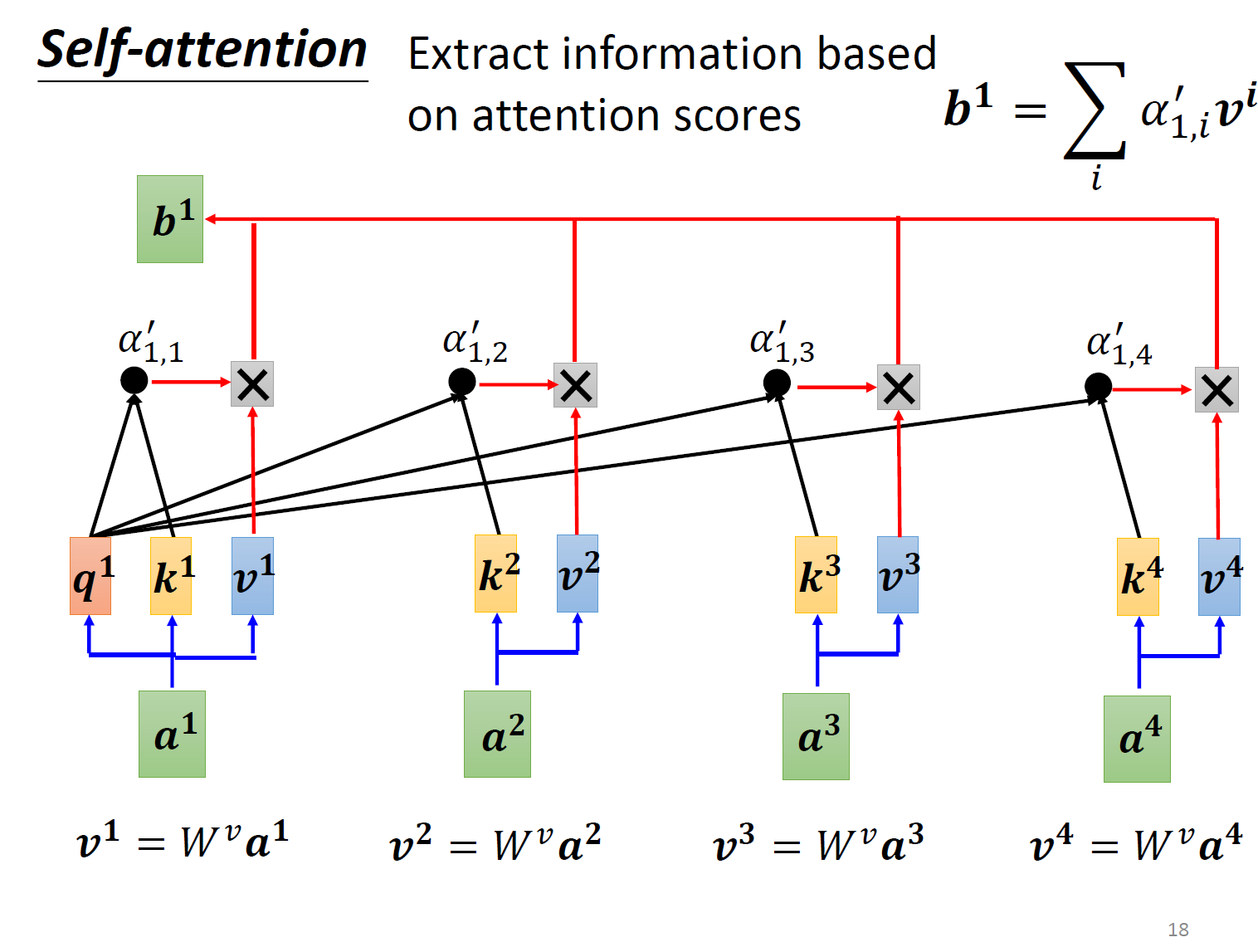
根据相关性进行加权。
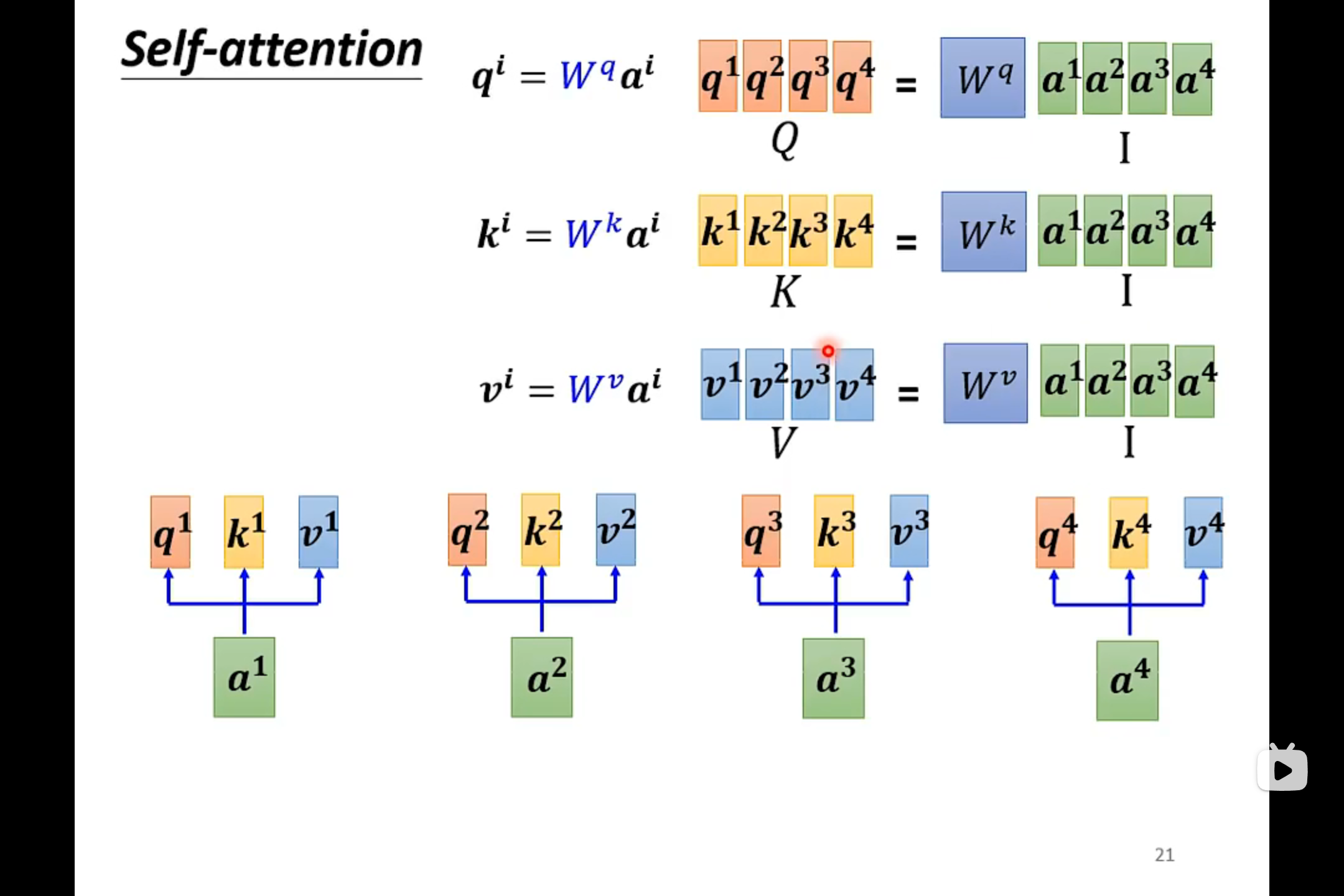
把输入乘上三个不同的QKV矩阵,就得到了qkv


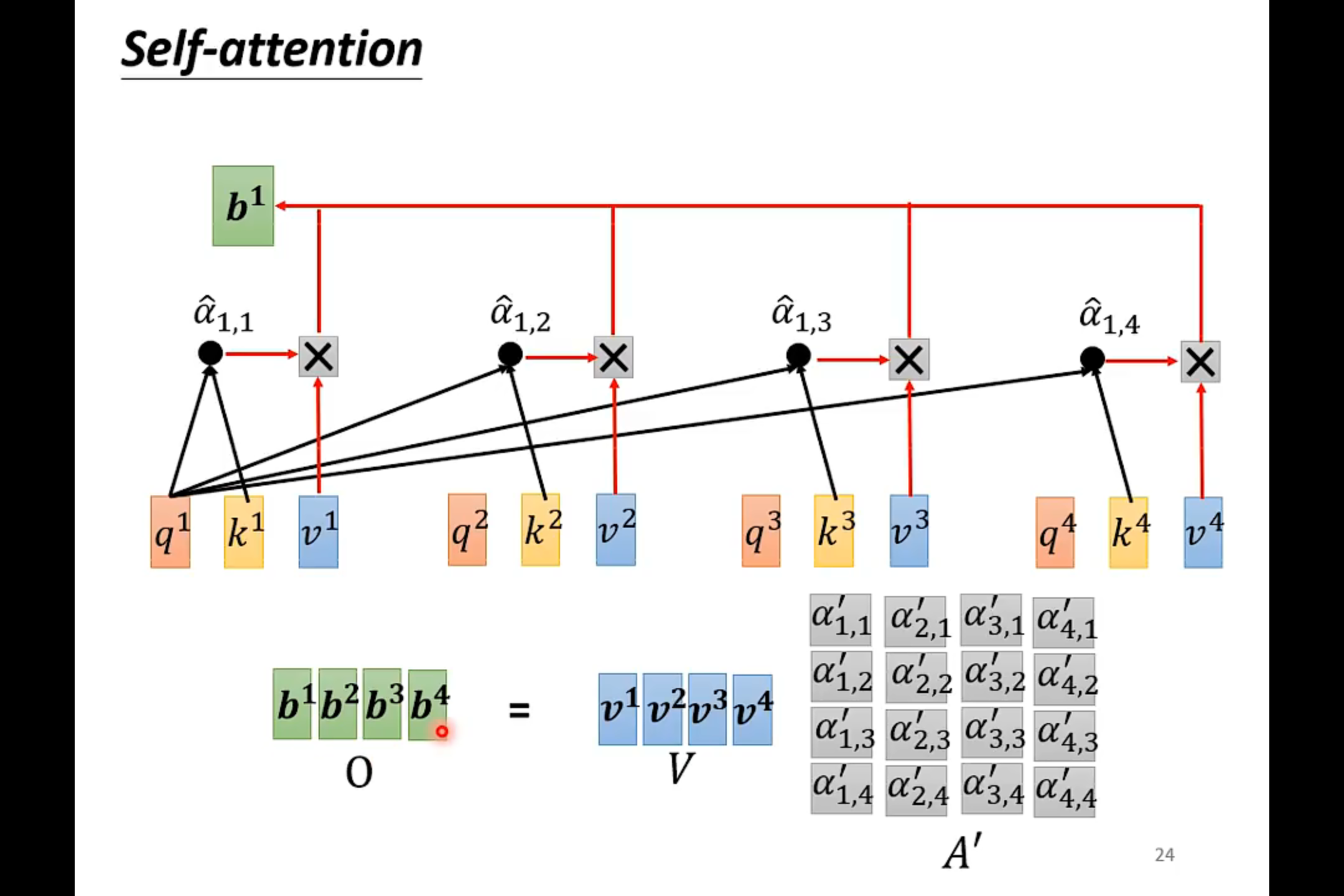
Multi-head Self-attention
感觉有点类似于CNN的卷积


这里的Self-attention并没有引入时序的概念。


利用self-attention处理图片的时候,我们把RGB三个维度看成一个向量,一个5x10x3的图片,我们就可以认为是
由5x10个vector组成的vector set。
self-attention的目的是建立起向量和向量之间的联系。主要是用于处理多向量作为输入的情况。

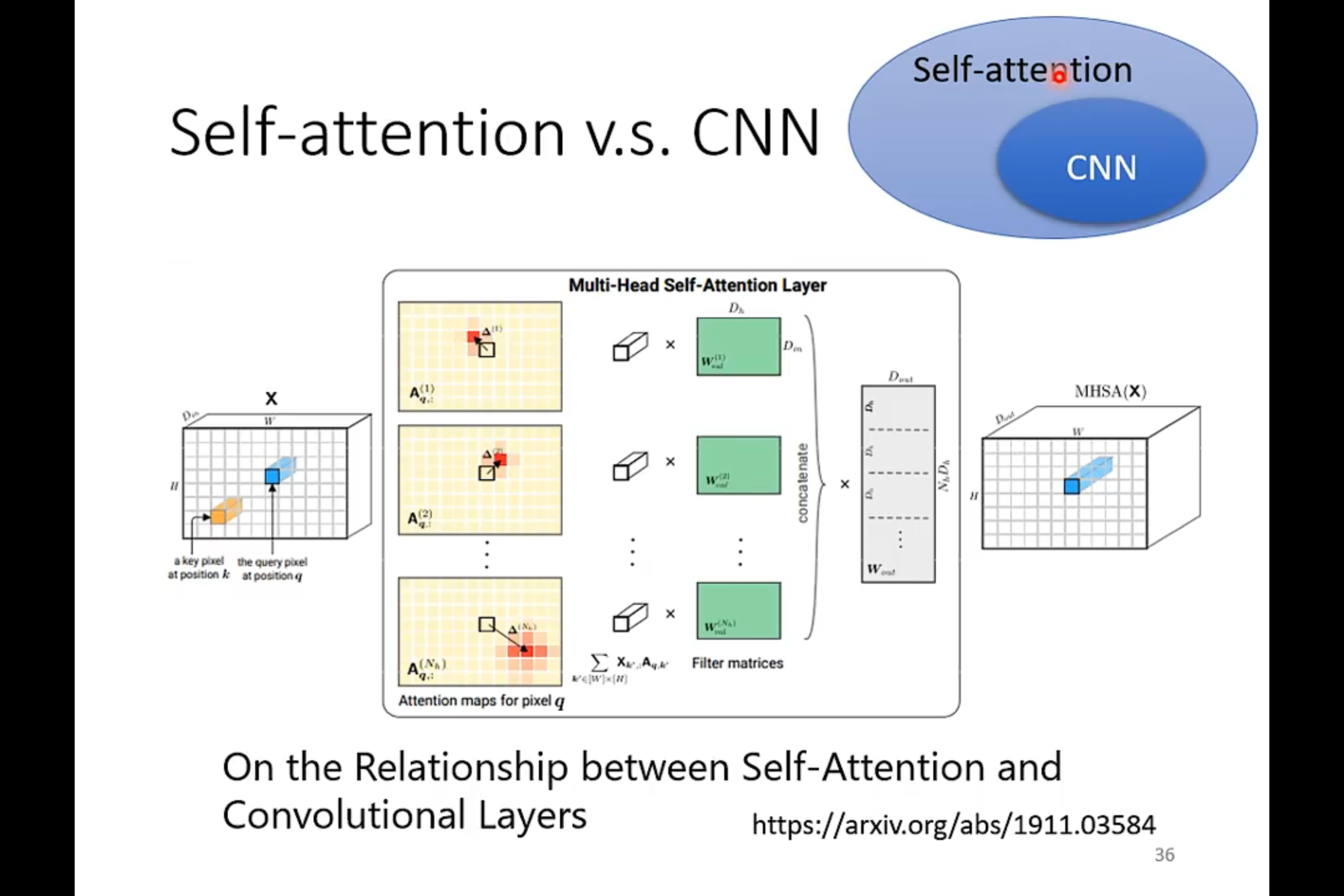
如果一个模型更feasible,我们在训练的时候就需要更多的参数,不然就容易产生overfitting的情况。

若有收获,就点个赞吧
0 人点赞
