1.实验目的
(依据需求制定至少三条,包括实验完成目标和学生培养目标)
2.实验原理(尽可能详细)
2.1 问题背景描述
深度学习(Deep Learning,DL)是机器学习领域中的一个研究方向,是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前的相关技术。它可以经过层间的轮班训练和一般的微调迫使计算机进行自我学习,并且随着网络层的增加,学习能力逐渐被委托深入的学习理论,如对比度分集算法、背乘算法、时延神经网络等专家混合系统,对于人工智能的发展具有重要意义。
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。随着深度学习的发展,人脸识别技术更加成熟。
在人脸识别领域中,深度学习一共有以下几种典型应用
(1)基于卷积神经网络的人脸识别方法;
(2)深度非线性人脸形状提取方法;
(3)基于深度学习的人脸姿态鲁棒性建模;
(4)约束环境下的全自动人脸识别;
(5)基于深度学习的视频监控下的人脸识别;
(6)基于深度学习的低分辨率人脸识别和其他基于深度学习的人脸相关信息的识别。
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。基于卷积神经网络的人脸识别方法,是深度监督学习下的机器学习模型,它可以挖掘数据的局部特征,并提取全局特征,然后进行分类,其权值共享结构网络更类似于生物神经网络,被应用于模式识别的各个领域。
2.1深度学习概述及发展深度学习是神经网络的重要组成部分,有时也被称为深度神经学习或深度神经网络。深度学习是由Hinton等人于2006年基于深度信网(DBN)提出的非监督贪心逐层训练算法。随着目标的正确识别逐渐成为人工智能的重要组成部分,基于深度学习的人脸识别目前也成了特征识别领域的研究热点。
2.2人脸识别细分类的深度学习算法脸部表达模型分为二维脸部和三维脸部,即2D和3D脸部。二维人脸识别的研究时间比较长,方法流程也比较成熟,应用于许多领域,但由于二维人脸识别信息存在深度数据丢失的缺陷,无法完全表达真实的人脸,因此在实际应用中存在着识别准确率低、活体检测率低等问题。现在市场上的3D人脸识别根据使用相机成像原理主要分为:3D结构光、TOF、双目立体视觉。
2.3人脸识别算法最近的几年来,随着相关领域人员对人脸识别的研究不断深入,现有的人脸识别技术主要针对现实环境和现实应用场景进行识别,具体包括以下3个方面:
(1)人脸模型的设计,包括线性鉴别分析、线性建模方法、非线性建模方法和三维人脸识别[4]。
(2)新特征表征,包括局部描述和深入研究,部分说明和深度学习方法。
(3)新的数据源,包括视频人脸识别以及草图和近红外图像。
以下是较为经典的三大人脸识别的经典算法:
(1)Deep Face采用了一种基于监测点的人脸检测方法。脸部检测部分将首先选取6个基准点,2个眼心,1个鼻点,3个口点,然后利用SVR对LBP特征进行特征学习,获得标记点。
(2)Face Net是谷歌提议的网络结构,它可以灵活地使用22层Zelier&Fergus的网络,也可以使用inception网络,后者目前在物体识别方面比较有效。它的主要特点是利用3个单元之间的距离来构造损失函数。(3)Center Loss不同于三元损失,中心损失并不直接优化距离,它保留了原来的分类模型,但是为每一类分别指定了一个分类中心。同一类图像对应的特征都应尽可能接近其各自类别的中心,不同类别的中心应尽可能远离。
人脸识别技术在深度学习中的广泛应用:
在不久的将来,全国主流的人脸识别技术将以识别13亿人像为重点。可以预见的是,建立一个全国统一的人脸图像数据库,使存储在这个数据库中的数十亿张人脸图像的容量达到几十亿甚至几千亿张。此时,可以出现大量性能和关键功能相似的人脸。如果没有基于深度学习的人脸识别技术,就没有办法建立更加复杂多样的人脸模型,这就是为什么要实现准确快速的人脸识别会更加困难的原因。
2.2 算法原理及分析(可添加适当的公式推理,必须确保准确无误)
深度学习的最大优势在于由训练算法自行调整参数权重,构造出一个准确率较高的f(x)函数,给定一张照片则可以获取到特征值,进而再归类。
本文中笔者试图用通俗的语言探讨人脸识别技术,首先概述人脸识别技术,接着探讨深度学习有效的原因以及梯度下降为什么可以训练出合适的权重参数,最后描述基于CNN卷积神经网络的人脸识别。
一、人脸识别技术概述
人脸识别技术大致由人脸检测和人脸识别两个环节组成。
之所以要有人脸检测,不光是为了检测出照片上是否有人脸,更重要的是把照片中人脸无关的部分删掉,否则整张照片的像素都传给f(x)识别函数肯定就不可用了。人脸检测不一定会使用深度学习技术,因为这里的技术要求相对低一些,只需要知道有没有人脸以及人脸在照片中的大致位置即可。一般我们考虑使用OpenCV、dlib等开源库的人脸检测功能(基于专家经验的传统特征值方法计算量少从而速度更快),也可以使用基于深度学习实现的技术如MTCNN(在神经网络较深较宽时运算量大从而慢一些)。
在人脸检测环节中,我们主要关注检测率、漏检率、误检率三个指标,其中:
• 检测率:存在人脸并且被检测出的图像在所有存在人脸图像中的比例;
• 漏检率:存在人脸但是没有检测出的图像在所有存在人脸图像中的比例;
• 误检率:不存在人脸但是检测出存在人脸的图像在所有不存在人脸图像中的比例。
当然,检测速度也很重要。本文不对人脸检测做进一步描述。
在人脸识别环节,其应用场景一般分为1:1和1:N。
1:1就是判断两张照片是否为同一个人,通常应用在人证匹配上,例如身份证与实时抓拍照是否为同一个人,常见于各种营业厅以及后面介绍的1:N场景中的注册环节。而1:N应用场景,则是首先执行注册环节,给定N个输入包括人脸照片以及其ID标识,再执行识别环节,给定人脸照片作为输入,输出则是注册环节中的某个ID标识或者不在注册照片中。可见,从概率角度上来看,前者相对简单许多,且由于证件照通常与当下照片年代间隔时间不定,所以通常我们设定的相似度阈值都是比较低的,以此获得比较好的通过率,容忍稍高的误识别率。
而后者1:N,随着N的变大,误识别率会升高,识别时间也会增长,所以相似度阈值通常都设定得较高,通过率会下降。这里简单解释下上面的几个名词:误识别率就是照片其实是A的却识别为B的比率;通过率就是照片确实是A的,但可能每5张A的照片才能识别出4张是A其通过率就为80%;相似度阈值是因为对特征值进行分类是概率行为,除非输入的两张照片其实是同一个文件,否则任何两张照片之间都有一个相似度,设定好相似度阈值后唯有两张照片的相似度超过阈值,才认为是同一个人。所以,单纯的评价某个人脸识别算法的准确率没有意义,我们最需要弄清楚的是误识别率小于某个值时(例如0.1%)的通过率。不管1:1还是1:N,其底层技术是相同的,只是难度不同而已。
取出人脸特征值是最难的,那么深度学习是如何取特征值的?
假定我们给出的人脸照片是100100像素大小,由于每个像素有RGB三个通道,每个像素通道由0-255范围的字节表示,则共有3个100100的矩阵计3万个字节作为输入数据。深度学习实际上就是生成一个近似函数,把上面的输入值转化为可以用作特征分类的特征值。那么,特征值可以是一个数字吗?当然不行,一个数字(或者叫标量)是无法有效表示出特征的。通常我们用多个数值组成的向量表示特征值,向量的维度即其中的数值个数。特征向量的维度并非越大越好,Google的FaceNet项目(参见https://arxiv.org/abs/1503.03832论文)做过的测试结果显示,128个数值组成的特征向量结果最好,如下图所示: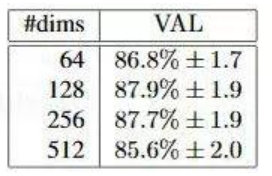
那么,现在问题就转化为怎么把3100100的矩阵转化为128维的向量,且这个向量能够准确的区分出不同的人脸?
假定照片为x,特征值为y,也就是说存在一个函数f(x)=y可以完美的找出照片的人脸特征值。现在我们有一个f(x)近似函数,其中它有参数w(或者叫权重w)可以设置,例如写成f(x;w),若有训练集x及其id标识y,设初始参数p1后,那么每次f(x;w)得到的y`与实际标识y相比,若正确则通过,若错误则适当调整参数w,如果能够正确的调整好参数w,f(x;w)就会与理想中的f(x)函数足够接近,我们就获得了概率上足够高准确率的f(x;w)函数。这一过程叫做监督学习下的训练。而计算f(x;w)值的过程因为是正常的函数运算,我们称为前向运算,而训练过程中比较y`与实际标识id值y结果后,调整参数p的过程则是反过来的,称为反向传播。
由于我们传递的x入参毕竟是一张照片,照片既有对焦、光线、角度等导致的不太容易衡量的质量问题,也有本身的像素数多少问题。如果x本身含有的数据太少,即图片非常不清晰,例如2828像素的照片,那么谁也无法准确的分辨出是哪个人。可以想见,必然像素数越多识别也越准,但像素数越多导致的计算、传输、存储消耗也越大,我们需要有根据地找到合适的阈值。下图是FaceNet论文的结果,虽然只是一家之言,但Google的严谨态度使得数据也很有参考价值。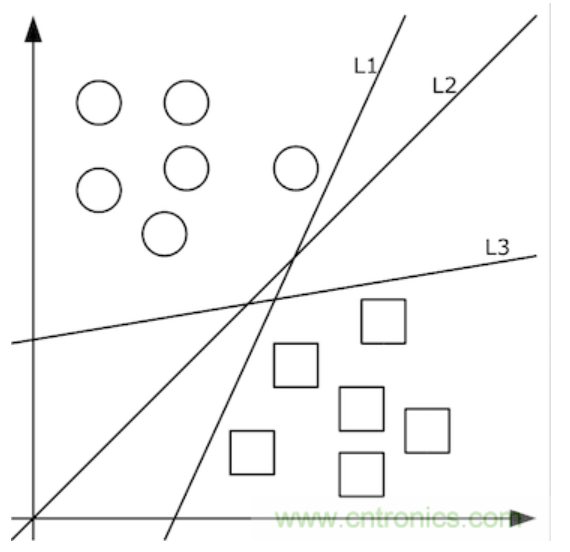
从图中可见,排除照片其他质量外,像素数至少也要有100100(纯人脸部分)才能保证比较高的识别率。
二、深度学习技术的原理
由清晰的人脸照转化出的像素值矩阵,应当设计出什么样的函数f(x)转化为特征值呢?这个问题的答案依赖于分类问题。即,先不谈特征值,首先如何把照片集合按人正确地分类?这里就要先谈谈机器学习。机器学习认为可以从有限的训练集样本中把算法很好地泛化。所以,我们先找到有限的训练集,设计好初始函数f(x;w),并已经量化好了训练集中x->y。如果数据x是低维的、简单的,例如只有二维,那么分类很简单,如下图所示: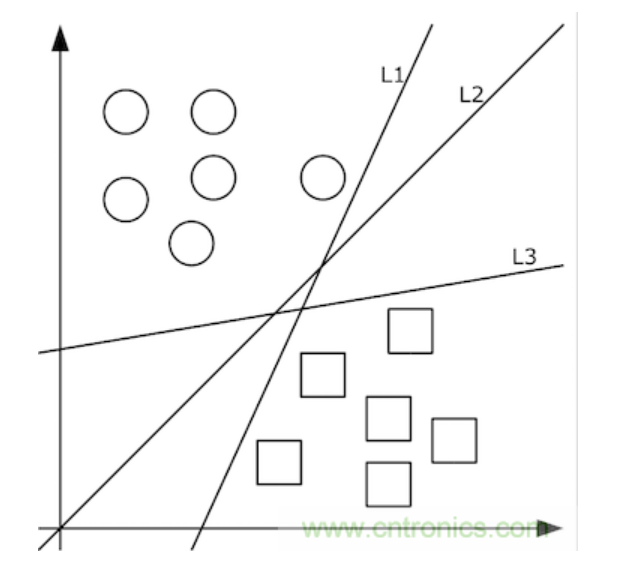
上图中的二维数据x只有方形和圆形两个类别y,很好分,我们需要学习的分类函数用最简单的f(x,y)=ax+by+c就能表示出分类直线。例如f(x,y)大于0时表示圆形,小于0时表示方形。
给定随机数作为a,c,b的初始值,我们通过训练数据不断的优化参数a,b,c,把不合适的L1、L3等分类函数逐渐训练成L2,这样的L2去面对泛化的测试数据就可能获得更好的效果。然而如果有多个类别,就需要多条分类直线才能分出,如下图所示:
这其实相当于多条分类函数执行与&&、或||操作后的结果。这个时候还可能用f1>0 && f2<0 && f3>0这样的分类函数,但如果更复杂的话,例如本身的特征不明显也没有汇聚在一起,这种找特征的方式就玩不转了,如下图所示,不同的颜色表示不同的分类,此时的训练数据完全是非线性可分的状态: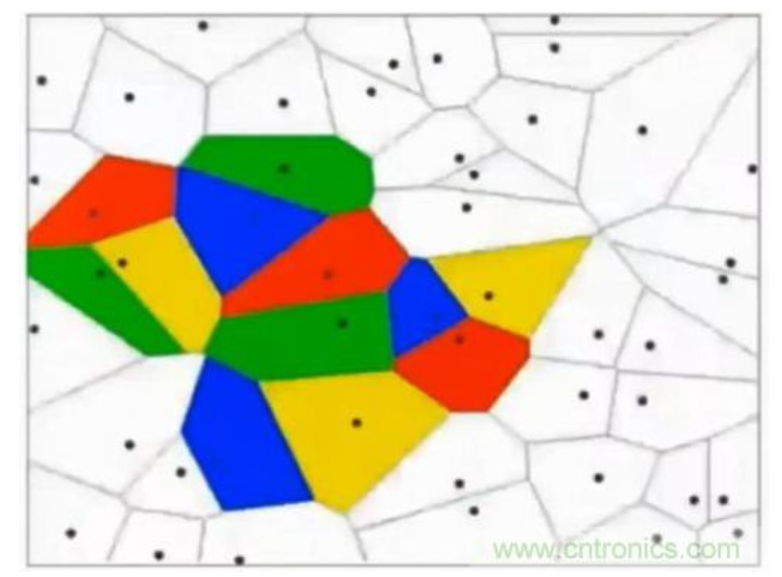
这个时候,我们可以通过多层函数嵌套的方法来解决,例如f(x)=f1(f2(x)),这样f2函数可以是数条直线,而f1函数可以通过不同的权重w以及激励函数完成与&&、或||等等操作。这里只有两层函数,如果函数嵌套层数越多,它越能表达出复杂的分类方法,这对高维数据很有帮助。例如我们的照片毫无疑问就是这样的输入。所谓激励函数就是把函数f计算出的非常大的值域转化为[0,1]这样较小的值域,这允许多层函数不断地前向运算、分类。
前向运算只是把输入交给f1(x,w1)函数,计算出的值再交给f2(y1,w2)函数,依次类推,很简单就可以得到最终的分类值。但是,因为初始的w权重其实没有多大意义,它得出的分类值f(x)肯定是错的,在训练集上我们知道正确的值y,那么事实上我们其实是希望y-f(x)的值最小,这样分类就越准。这其实变成了求最小值的问题。当然,y-f(x)只是示意,事实上我们得到的f(x)只是落到各个分类上的概率,把这个概率与真实的分类相比较得到最小值的过程,我们称为损失函数,其值为loss,我们的目标是把损失函数的值loss最小化。在人脸识别场景中,softmax是一个效果比较好的损失函数,我们简单看下它是如何使用的。
比如我们有训练数据集照片对应着cat、dog、ship三个类别,某个输入照片经过函数f(x)=xW+b,前向运算得到该照片属于这3个分类的得分值。此时,这个函数被称为得分函数,如下图所示,假设左边关于猫的input image是一个4维向量[56,231,24,2],而W权重是一个43的矩阵,那么相乘后再加上向量[1.1,3.2,-1.2]可得到在cat、 dog、ship三个类别上的得分: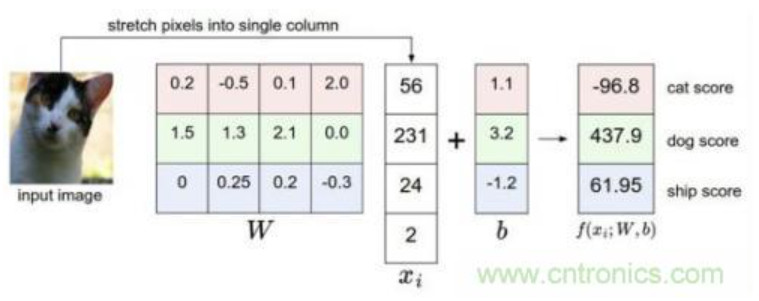
从上图示例可见,虽然输入照片是猫,但得分上属于狗的得分值437.9最高,但究竟比猫和船高多少呢?很难衡量!如果我们把得分值转化为0-100的百分比概率,这就方便度量了。这里我们可以使用sigmoid函数,如下图所示: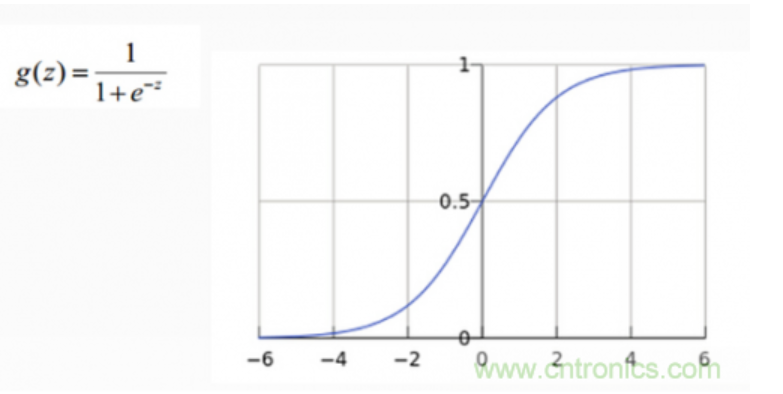
从上图公式及图形可知,sigmoid可以把任意实数转换为0-1之间的某个数作为概率。但sigmoid概率不具有归一性,也就是说我们需要保证输入照片在所有类别的概率之和为1,这样我们还需要对得分值按softmax方式做以下处理: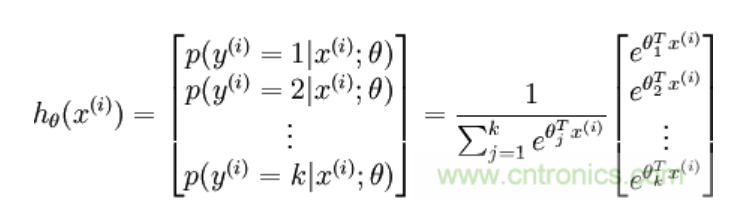
这样给定x后可以得到x在各个类别下的概率。假定三个类别的得分值分别为3、1、-3,则按照上面的公式运算后可得概率分别为[0.88、0.12、0],计算过程如下图所示: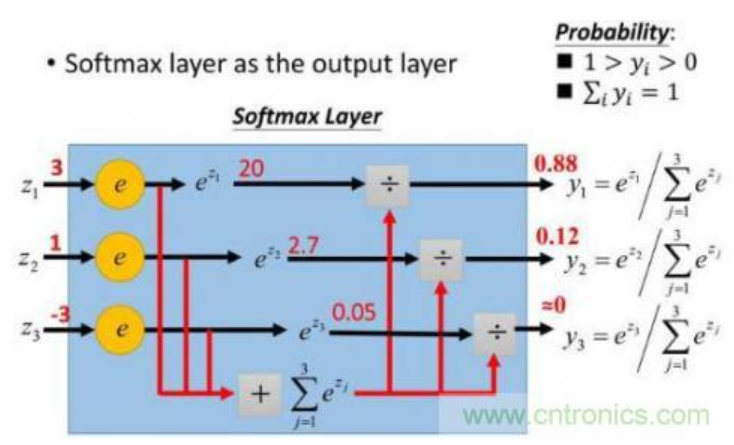
然而实际上x对应的概率其实是第一类,比如[1,0,0],现在拿到的概率(或者可称为似然)是[0.88、0.12、0]。那么它们之间究竟有多大的差距呢?这个差距就是损失值loss。如何获取到损失值呢?在softmax里我们用互熵损失函数计算量最小(方便求导),如下所示:
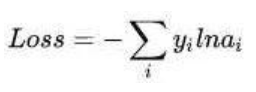
其中i就是正确的分类,例如上面的例子中其loss值就是-ln0.88。这样我们有了损失函数f(x)后,怎么调整x才能够使得函数的loss值最小呢?这涉及到微分导数。
三、梯度下降(上)
梯度下降就是为了快速的调整权重w,使得损失函数f(x;w)的值最小。因为损失函数的值loss最小,就表示上面所说的在训练集上的得分结果与正确的分类值最接近!
导数求的是函数在某一点上的变化率。例如从A点开车到B点,通过距离和时间可以算出平均速度,但在其中C点的瞬时速度是多少呢?如果用x表示时间,f(x)表示车子从A点驶出的距离,那么在x0的瞬时速度可以转化为:从x0时再开一个很小的时间,例如1秒,那么这一秒的平均速度就是这一秒开出的距离除以1秒,即(f(1+x0)-f(x0))/1。如果我们用的不是1秒而是1微秒,那么这个1微秒内的平均速度必然更接近x0时的瞬时速度。于是,到该时间段t趋向于0时,我们就得到了x0时的瞬时速度。这个瞬时速度就是函数f在x0上的变化率,所有x上的变化率就构成了函数f(x)的导数,称为f`(x)。即: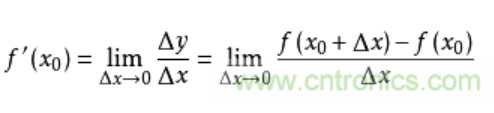
从几何意义上看,变化率就变成了斜率,这更容易理解怎样求函数的最小值。例如下图中有函数y=f(x)用粗体黑线表示,其在P0点的变化率就是切线红线的斜率: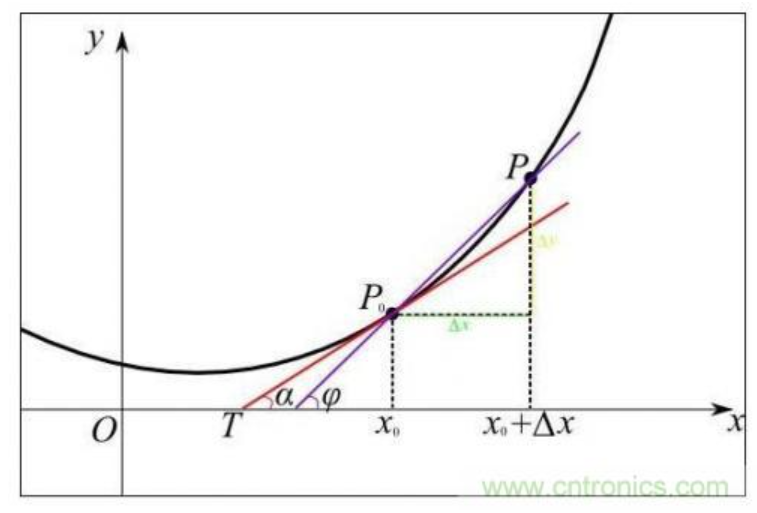
可以形象的看出,当斜率的值为正数时,把x向左移动变小一些,f(x)的值就会小一些;当斜率的值为负数时,把x向右移动变大一些,f(x)的值也会小一些,如下图所示: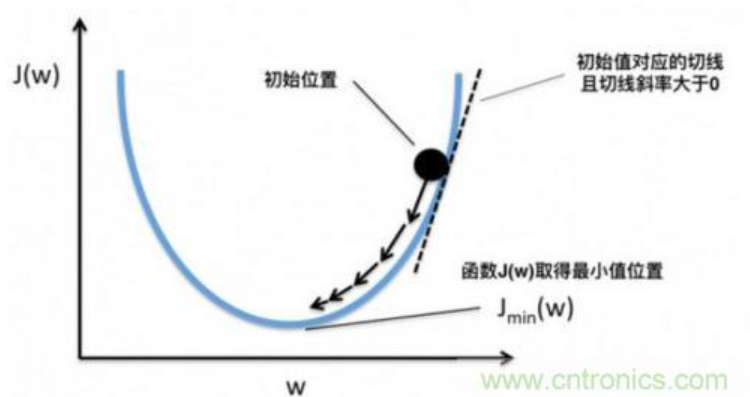
这样,斜率为0时我们其实就得到了函数f在该点可以得到最小值。那么,把x向左或者向右移一点,到底移多少呢?如果移多了,可能移过了,如果移得很少,则可能要移很久才能找到最小点。还有一个问题,如果f(x)操作函数有多个局部最小点、全局最小点时,如果x移的非常小,则可能导致通过导数只能找到某个并不足够小的局部最小点。如下图所示: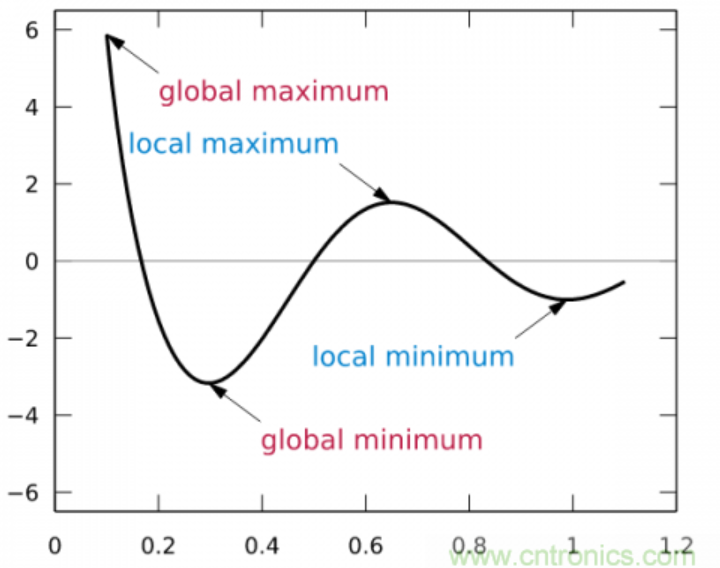
蓝色的为局部最小点,红色是全局最小点。所以x移动多少是个问题,x每次的移动步长过大或者过小都可能导致找不到全局最小点。这个步长除了跟导数斜率有关外,我们还需要有一个超参数来控制它的移动速度,这个超参数称为学习率,由于它很难优化,所以一般需要手动设置而不能自动调整。考虑到训练时间也是成本,我们通常在初始训练阶段把学习率设的大一些,越往后学习率设的越小。
那么每次移动的步长与导数的值有关吗?这是自然的,导数的正负值决定了移动的方向,而导数的绝对值大小则决定了斜率是否陡峭。越陡峭则移动的步长应当越大。所以,步长由学习率和导数共同决定。就像下面这个函数,λ是学习率,而∂F(ωj) / ∂ωj是在ωj点的导数。
ωj = ωj – λ ∂F(ωj) / ∂ωj
根据导数判断损失函数f在x0点上应当如何移动,才能使得f最快到达最小值的方法,我们称为梯度下降。梯度也就是导数,沿着负梯度的方向,按照梯度值控制移动步长,就能快速到达最小值。当然,实际上我们未必能找到最小点,特别是本身存在多个最小点时,但如果这个值本身也足够小,我们也是可以接受的,如下图所示: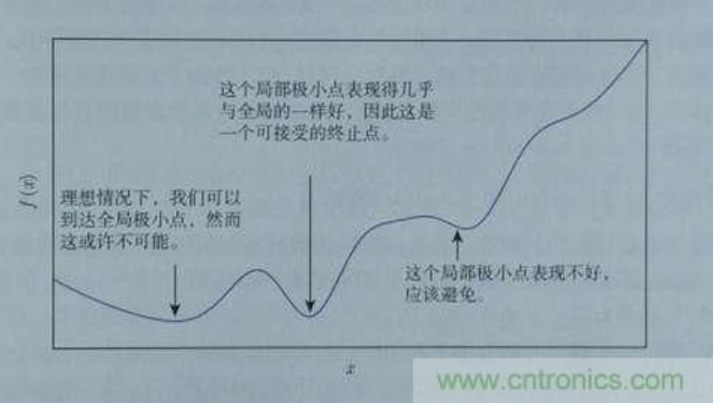
以上我们是以一维数据来看梯度下降,但我们的照片是多维数据,此时如何求导数?又如何梯度下降呢?此时我们需要用到偏导数的概念。其实它与导数很相似,因为x是多维向量,那么我们假定计算Xi的导数时,x上的其他数值不变,这就是Xi的偏导数。此时应用梯度下降法就如下图所示,θ是二维的,我们分别求θ0和θ1的导数,就可以同时从θ0和θ1两个方向移动相应的步长,寻找最低点,如下图所示: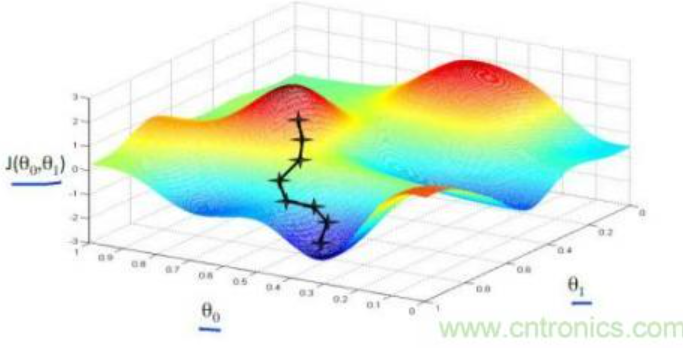
3.实验内容
3.1 实验环境搭建
本次实验环境主要使用pytorch和opencv,编译平台采用的是Pycharm
数据准备:
数据集为人脸数据集,下载链接如下:
链接:https://pan.baidu.com/s/1nwVy8Y7dvNFt4qWPQpaxfQ
提取码:face
3.2 数据导入(包括预处理等,需给出具体实例和操作流程)
face_data的人脸数据集内容如下:
其中“1”文件夹内的图片为非人脸图片。
“faces”文件夹内的图片为人脸图片,且图片的文件名也注释了“faceimage”字样。
import osimport cv2from torchvision import transformsfrom torch.utils.data import Dataset, DataLoaderdef get_labels(labels):"""Return text labels for the dataset."""text_labels = ['face', 'nonface']return [text_labels[int(i)] for i in labels]def Myloader(path):return cv2.imread(path)def get_data(data_path):data = []for file in os.listdir(data_path):label = find_label(file)image_path = os.path.join(data_path, file)data.append([image_path, label])return datadef find_label(title):if 'faceimage' in title:return 0else:return 1class MyDataset(Dataset):def __init__(self, data, transform, loader):self.data = dataself.transform = transformself.loader = loaderdef __getitem__(self, item):img_path, label = self.data[item]img = self.loader(img_path)img = self.transform(img)return img, labeldef __len__(self):return len(self.data)def load_data(batch_size):transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 归一化])path1 = 'face_data/training_data/faces'data1 = get_data(path1)path2 = 'face_data/training_data/1'data2 = get_data(path2)path3 = 'face_data/testing_data/faces'data3 = get_data(path3)path4 = 'face_data/testing_data/1'data4 = get_data(path4)train_data = data1 + data2train = MyDataset(train_data, transform=transform, loader=Myloader)test_data = data3 + data4test = MyDataset(test_data, transform=transform, loader=Myloader)train_data = DataLoader(dataset=train, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)test_data = DataLoader(dataset=test, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)return train_data, test_data
本次实验通过Pytorch搭建卷积神经网络来实现人脸识别。Pytorch能够处理和识别的数据类型为Tensor类型的数据。所以在实验的一开始需要先对数据进行预处理,把输入的人脸图像数据转化成可以被Pytorch处理的Tensor数据类型。
数据导入
1.为每张图片建立标签,由代码中的 findlabel(title) 函数实现;
2.将数据集每张图片的路径与其标签读取到一个列表里, 由 getdata(data_path) 函数实现;
3.通过 opencv 读取图片,读出来的数据类型是 numpy.ndarray;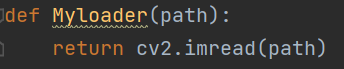
4.通过transforms 模块对图片数据进行预处理,由于 opencv 读出来的数据类型是 numpy.ndarray,而 transforms 模块只能对 PIL 和 tensor 格式的数据进行处理,首先要将其转换成 PILImage;然后将图片统一成 224*224 的大小;最后归一化到 [-1:1];
5.重写 torch.utils.data.Dataset 的__getitem(self, item) 方法,最后通过 torch.utils.data.DataLoader 将数据加载成迭代对象。
最终脚本文件:py_dataloader.py
import osimport cv2from torchvision import transformsfrom torch.utils.data import Dataset, DataLoaderdef get_labels(labels):"""Return text labels for the dataset."""text_labels = ['face', 'nonface']return [text_labels[int(i)] for i in labels]def Myloader(path):return cv2.imread(path)def get_data(data_path):data = []for file in os.listdir(data_path):label = find_label(file)image_path = os.path.join(data_path, file)data.append([image_path, label])return datadef find_label(title):if 'faceimage' in title:return 0else:return 1class MyDataset(Dataset):def __init__(self, data, transform, loader):self.data = dataself.transform = transformself.loader = loaderdef __getitem__(self, item):img_path, label = self.data[item]img = self.loader(img_path)img = self.transform(img)return img, labeldef __len__(self):return len(self.data)def load_data(batch_size):transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 归一化])path1 = 'face_data/training_data/faces'data1 = get_data(path1)path2 = 'face_data/training_data/1'data2 = get_data(path2)path3 = 'face_data/testing_data/faces'data3 = get_data(path3)path4 = 'face_data/testing_data/1'data4 = get_data(path4)train_data = data1 + data2train = MyDataset(train_data, transform=transform, loader=Myloader)test_data = data3 + data4test = MyDataset(test_data, transform=transform, loader=Myloader)train_data = DataLoader(dataset=train, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)test_data = DataLoader(dataset=test, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)return train_data, test_data
这里重点讲一下MyDataset类的重写。
MyDataset继承了Dataset类,Dataset类需要重写,init(),getitem(),len(),三个方法。
其中init()方法主要是要获取,外部输入的数据,对数据进行转换的函数。
这里self.data = data即是读取外部数据,self.transform = transform的目的是为了读取之后对数据进行预处理的函数方法。
对getitem()方法的重写是,MyDataset类的重点,核心在于最后能够输出,Pytorch模型所匹配的Tensor数据类型。
img = self.loader(img_path)
的作用是,将输入的img_path转化成ndarray形式。
之后再通过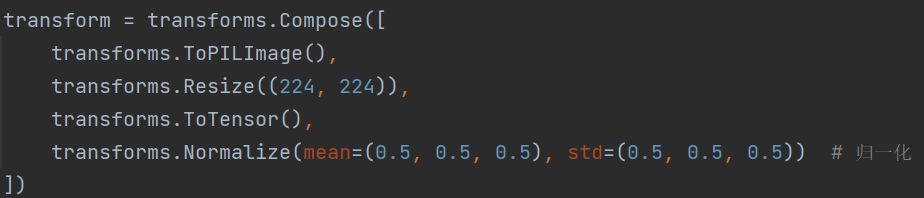
transforms.Compose函数把ndarray形式的数据转化为Pytorch训练时所需要的Tensor数据类型。
3.3 实施算法
3.3.1 算法流程
3.3.2 算法实例
3.3.2.1 基础实验实例(当前实验涉及子实验的相关原理实践)
人脸检测:
人脸检测可通过opencv自带人脸特征数据进行检测,也可通过卷积神经网络进行检测。
1.通过Opencv实现人脸检测:
通过 opencv 实现人脸检测的代码很简单,只需要指定使用的人脸特征数据的路径即可。我使用的是 haarcascade_frontalface_alt2.xml。由于 opencv 读取的图片格式是BGR,可以将其转换为灰度图,提高人脸检测的速度。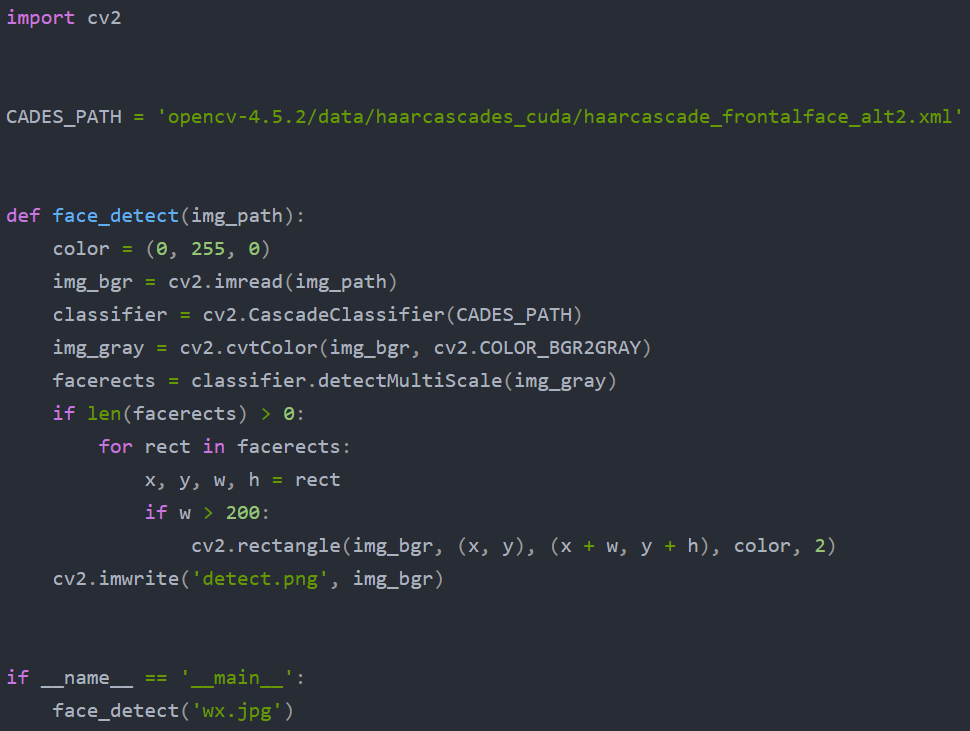
最后通过 opencv 进行人脸检测的效果如下。
2.通过神经网络实现人脸检测
通过卷积神经网络进行人脸检测主要包括三个步骤:
1.将人脸数据读取成 pytorch 可训练的 tensor 张量类型,并对数据进行预处理;
2.搭建一个二分类网络,对人脸数据进行训练;
3.利用训练好的网络,对特定图片实现人脸检测任务;
import osimport cv2from torchvision import transformsfrom torch.utils.data import Dataset, DataLoaderdef get_labels(labels):"""Return text labels for the dataset."""text_labels = ['face', 'nonface']return [text_labels[int(i)] for i in labels]def Myloader(path):return cv2.imread(path)def get_data(data_path):data = []for file in os.listdir(data_path):label = find_label(file)image_path = os.path.join(data_path, file)data.append([image_path, label])return datadef find_label(title):if 'faceimage' in title:return 0else:return 1class MyDataset(Dataset):def __init__(self, data, transform, loader):self.data = dataself.transform = transformself.loader = loaderdef __getitem__(self, item):img_path, label = self.data[item]img = self.loader(img_path)img = self.transform(img)return img, labeldef __len__(self):return len(self.data)def load_data(batch_size):transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 归一化])path1 = 'face_data/training_data/faces'data1 = get_data(path1)path2 = 'face_data/training_data/1'data2 = get_data(path2)path3 = 'face_data/testing_data/faces'data3 = get_data(path3)path4 = 'face_data/testing_data/1'data4 = get_data(path4)train_data = data1 + data2train = MyDataset(train_data, transform=transform, loader=Myloader)test_data = data3 + data4test = MyDataset(test_data, transform=transform, loader=Myloader)train_data = DataLoader(dataset=train, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)test_data = DataLoader(dataset=test, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)return train_data, test_data
CNN模型训练
我这里使用的是残差网络,因为残差块的输入可以通过层间的残余连接更快地向前传播,可以训练出一个有效的深层神经网络,残差块的结构如下图所示。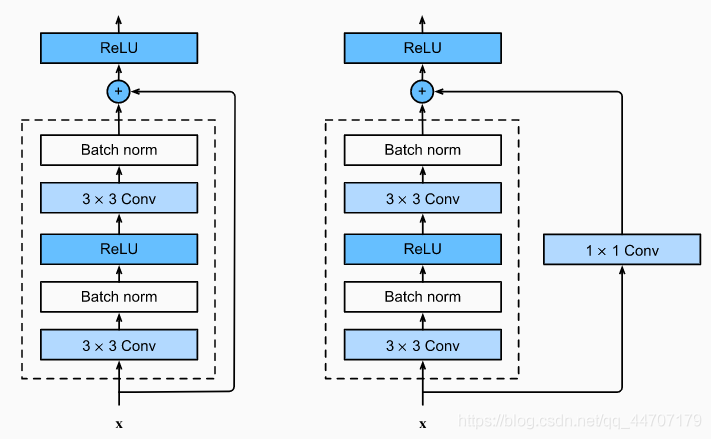
最后我选择了 resnet18 模型,该模型使用 4 个由残差块组成的模块,每个模块有 4 个卷积层(不包括恒等映射的1×1卷积层),加上第一个7×7卷积层和最后一个全连接层,共有 18 层。具体的 pytorch 实现如下。
import torch
from torch import nn
from d2l import torch as d2l
from py_dataloader import load_data
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU (defined in Chapter 6)."""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1, bias=False)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides, bias=False)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 2))
lr, num_epochs = 0.1, 10
train_iter, test_iter = load_data(128)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
torch.save(net.state_dict(), 'face_SGD_224_resnet18.params')

init_weights函数的目的是为了初始化参数。
参数初始化(Weight Initialization)
PyTorch 中参数的默认初始化在各个层的 reset_parameters() 方法中。
下面是几种常见的初始化方式。
Xavier Initialization
Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0。这是通用的方法,适用于任何激活函数。

这里的net.apply(),其实是nn.Module.apply方法,该方法会将fn递归的应用于模块的每一个子模块(.children()的结果)及其自身。典型的用法是,对一个model的参数进行初始化。
官方文档如下:
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
此处的net.apply(init_weights)的作用是,使用init_weights方法对模型以及模型的各个子模块进行初始化。
这段代码的意思就是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
这里采用SGD随机梯度下降算法作为模型的优化算法。
并且采用nn.CrossEntropyLoss()即交叉熵作为损失函数。
animator是一个绘图工具包。可以获得最后的实验数据结果。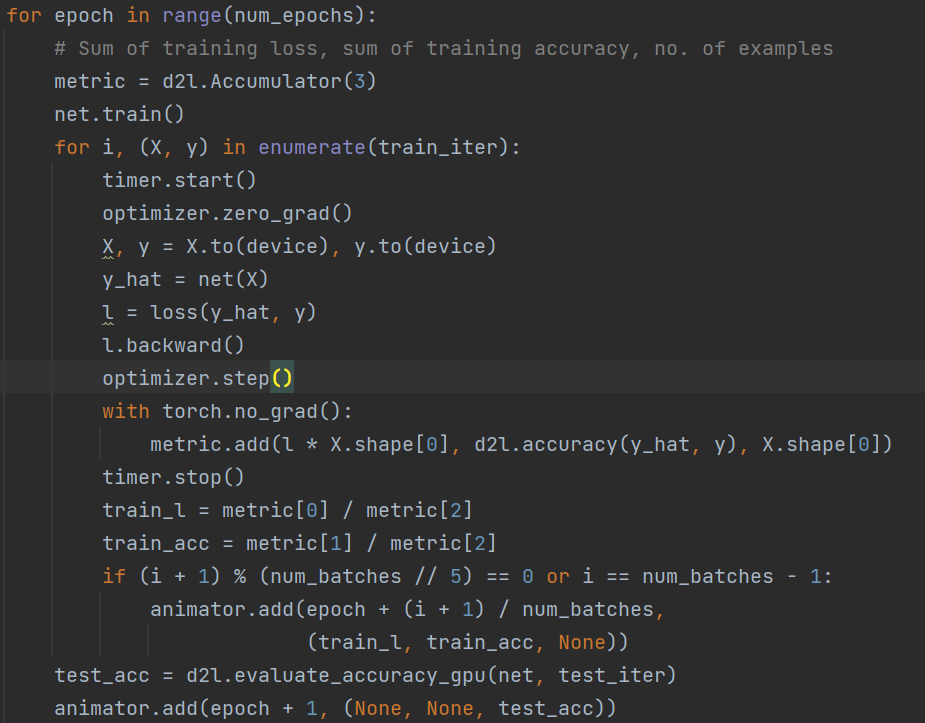
深度学习中常用for epoch in range(num_epochs)这样的循环作为模型训练的主干部分。
最核心的函数为:
optimizer.zero_grad(),对优化器进行梯度初始化
y_hat = net(X), 对X进行预测,得到y_hat
l.backward(),对损失函数进行反向传播
optimizer.step(),利用损失函数来更新模型。
以上四个步骤为模型训练的最主要的部分。for epoch in range(num_epochs)是用来决定,我们要对模型进行多少次的循环学习。
算法模型:
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1, bias=False)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides, bias=False)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
本次使用的模型比较的简单,是一个简单的利用残差网络搭建卷积的模型。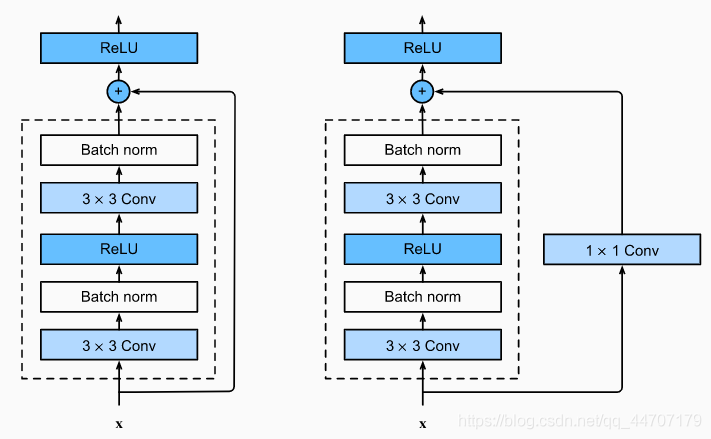
在init()里面,主要定义的是模型的之后在训练中使用的层。
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
这里是根据Conv2d来定义一个二维的卷积层。
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
这里是根据BatchNorm2d来定义一个BatchNorm的预处理层,对数据实行标准化。
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
这里的forward()函数的作用是定义,模型的层的顺序。即先经过ReLU的激活层,再通过bn2的预处理层,最后才进入卷积层进行模型训练。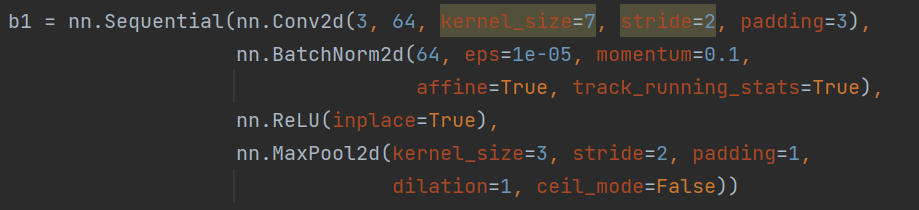
通过nn.Sequential来对模型进行一个串联,串联顺序自上而下。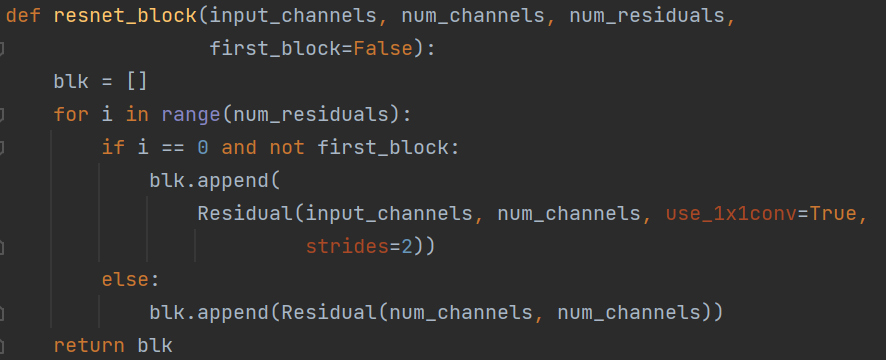
resnet_block函数很显然的是对模型的一个串联。对之前定义的Residual的一个串联。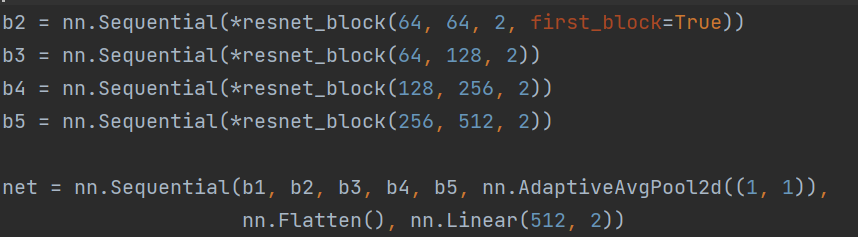
通过多个网络的串联来构建一个net模型。
最后是设置学习率,和训练次数。
再通过运行train_ch6来实现模型的训练。
3.3.2.2 进阶实验实例(依据实验目的完成全部实验)
人脸检测
创建一个resnet18.py文件来存放训练好的模型。
from torch import nn
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides, bias=False)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1, bias=False)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides, bias=False)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(num_channels, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
def get_net():
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 2))
return net
def get_net_lf():
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
dilation=1, ceil_mode=False))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 3))
return net
最后就是利用训练好的 resnet18 进行人脸检测,这里涉及到三个思想。
1.由于我们训练好的网络 resnet18 的输入是 224×224 的人脸,但是实际图片中的人脸大小不一定正好是 224×224 的,所以要对图片大小进行缩放变换;
2.然后将一个大小为 224×224 的矩形框在缩放后的图片上从左到右,从上到下滑动,计算每个位置存在人脸的概率;
3.最后得到的人脸框,可能不止一个,这是需要使用一个非极大值抑制的算法,将多余的框去掉,保留最好的。
最后的代码如下
import torch
import cv2
from torchvision import transforms
import numpy as np
from resnet18 import get_net
from d2l import torch as d2l
DEVICE = d2l.try_gpu() # 使用GPU计算
PARAMS_PATH = 'face_SGD_224_resnet18-3.params' # 网络参数
def face_detect(img_file, device=DEVICE):
gpu()
net = get_net()
net.load_state_dict(torch.load(PARAMS_PATH))
net.to(device)
scales = [] # 缩放变换比例
factor = 0.79
img = cv2.imread(img_file)
largest = min(2, 4000 / max(img.shape[0:2]))
scale = largest
mind = largest * min(img.shape[0:2])
while mind >= 224:
scales.append(scale)
scale *= factor
mind *= factor
total_box = []
for scale in scales:
scale_img = cv2.resize(img, (int(img.shape[1] * scale), int(img.shape[0] * scale)))
for box_img, box_pos in box_move(scale_img):
box_img = trans_form(box_img)
box_img = box_img.to(device)
prob = torch.softmax(net(box_img), dim=1)[0][0].data
if prob > 0.92:
x0, y0, x1, y1 = box_pos
x0 = int(x0 / scale)
y0 = int(y0 / scale)
x1 = int(x1 / scale)
y1 = int(y1 / scale)
total_box.append([x0, y0, x1, y1, prob])
total_box = nms(total_box)
for box in total_box:
x0, y0, x1, y1, prob = box
cv2.rectangle(img, (x0, y0), (x1, y1), (0, 255, 0), 2)
cv2.putText(img, str(prob.item()), (x0, y0), cv2.FONT_HERSHEY_PLAIN, 2, (0, 255, 0), 2)
cv2.imwrite('detect.png', img)
return 0
def box_move(img, row_stride=16, col_stride=16):
"""窗口滑动"""
h, w = img.shape[0:2]
cellsize = 224
row = int((w - cellsize) / row_stride) + 1
col = int((h - cellsize) / col_stride) + 1
for i in range(col):
for j in range(row):
box_pos = (j*row_stride, i*col_stride, j*row_stride+cellsize, i*col_stride+cellsize)
box_img = img[i*col_stride:i*col_stride+cellsize, j*row_stride:j*row_stride+cellsize]
yield box_img, box_pos
def trans_form(img):
transform = transforms.Compose([transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
img = transform(img)
img = img.unsqueeze(0)
return img
def nms(bounding_boxes, Nt=0.70):
"""非极大值抑制"""
if len(bounding_boxes) == 0:
return []
bboxes = np.array(bounding_boxes)
# 计算 n 个候选框的面积大小
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
scores = bboxes[:, 4]
areas = (x2 - x1) * (y2 - y1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序
order = np.argsort(scores)
picked_boxes = [] # 返回值
while order.size > 0:
# 将当前置信度最大的框加入返回值列表中
index = order[-1]
picked_boxes.append(bounding_boxes[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11)
h = np.maximum(0.0, y22 - y11)
intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除
ious = intersection / np.minimum(areas[index], areas[order[:-1]])
left = np.where(ious < Nt)
order = order[left]
return picked_boxes
def gpu():
"""GPU预热"""
x = torch.randn(size=(100, 100), device=DEVICE)
for i in range(10):
torch.mm(x, x)
if __name__ == '__main__':
face_detect('wx.jpg')
实现的效果如图,可以看到实现效果比 opencv 要好,将两个人脸都检测到了。
3.3.3.1定量实验分析
最后的训练结果如图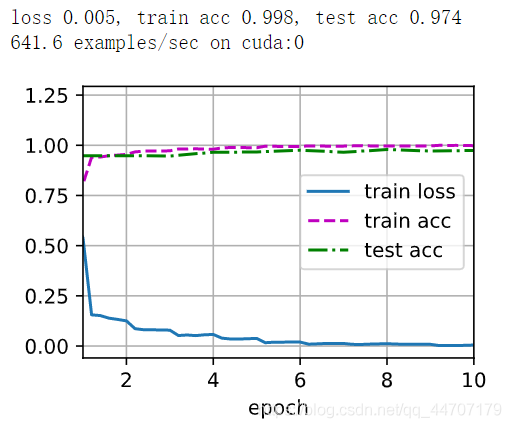
通过残差网络来学习我们可以从图中发现,训练的损失函数下降得很快,并且训练精度和测试精度都接近于1。
3.4 对比分析
4.总结
4.1 阐述实验过程,
4.2理解实验原理
4.3分析实验问题
4.4 达到实验目的
5.思考
6.附加
6.1关于torchvision的详细介绍
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。以下是torchvision的构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
torchvision的详细参考文档:
https://pytorch.org/vision/stable/index.html
在本次实验中,使用了其中的torchvision.transforms包。
from torchvision import transforms
torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起:
transforms.Compose([
transforms.CenterCrop(10),
transforms.ToTensor(),
])
这样就把两个步骤整合到了一起。
接下来介绍transforms中的函数: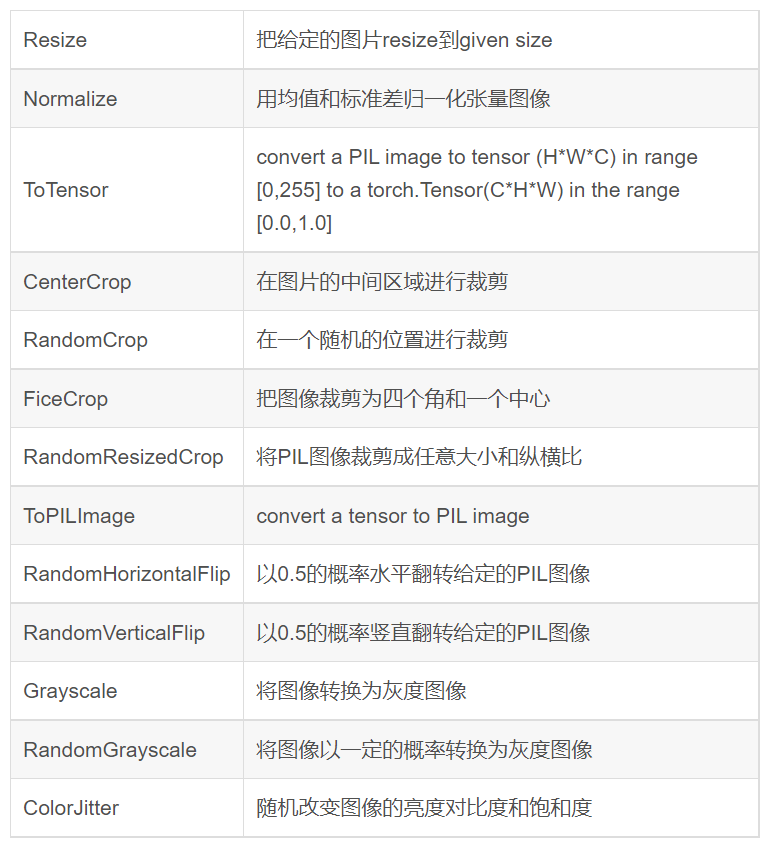
备注:Python图像库PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了。
实例:
transform.ToTensor(),
transform.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
那transform.Normalize()是怎么工作的呢?以上面代码为例,
- ToTensor()能够把灰度范围从0-255变换到0-1之间,
- 而后面的transform.Normalize()则把0-1变换到(-1,1).
具体地说,对每个通道而言,Normalize执行以下操作:
image=(image-mean)/std
其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1,而最大值1则变成(1-0.5)/0.5=1.
6.2关于Pytorch中Dataset的详解
https://blog.csdn.net/rowevine/article/details/123631144
Pytorch中Dataset的详细官方文档:
https://pytorch.org/docs/stable/data.html?highlight=dataset#torch.utils.data.Dataset
1.前言
我们在用Pytorch开发项目的时候,常常将项目代码分为数据处理模块、模型构建模块与训练控制模块。数据处理模块的主要任务是构建数据集。为方便深度学习项目构建数据集,Pytorch为我们提供了Dataset类。那么,假如现在已经有训练数据和标签,该怎么用Dataset类构建一个符合Pytorch规范的数据集呢?为此,本文将会具体解释如何构建Dataset数据集。首先学习在Pytorch中构建数据集的步骤。为此,本文将从两个方面进行介绍。首先介绍在Pytorch中构建数据集的步骤,然后介绍用Dataset类构建数据集的底层逻辑。
2 在Pytorch中构建数据集的步骤
下面用一个具体实例来说明拿到数据后,如何根据模型训练的需要来构建数据集。
- .实例一:图像二分类训练任务,识别1元纸币和100元纸币
如下图所示,现已有1元和100元纸币图像样本分别存放在“1”和“100”两个文件夹中。
在构建数据集前,我们要先明确模型需要哪些输入数据,除了模型所需的输入数据,在训练时还需要哪些数据。在本例中,模型需要图像数据作为输入。除了图像数据,还需要与图像数据相对应的类别标签,以用它来计算loss。所以,如下图所示,inputs和labels分别是从列表data中得到的图像数据序列和类别标签序列。也就是说,我们构建数据集的应该包含这两部分数据。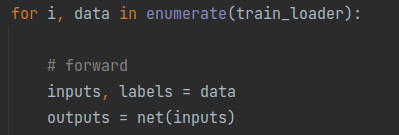
明确了需要构建什么数据后,下一步就是通过继承Pytorch的dataset类来编写自己的dataset类。Pytorch的dataset类是一个抽象类,继承dataset,需要实现它的getitem()方法和len()方法,下图是Pytorch官方文档中关于dataset类的说明。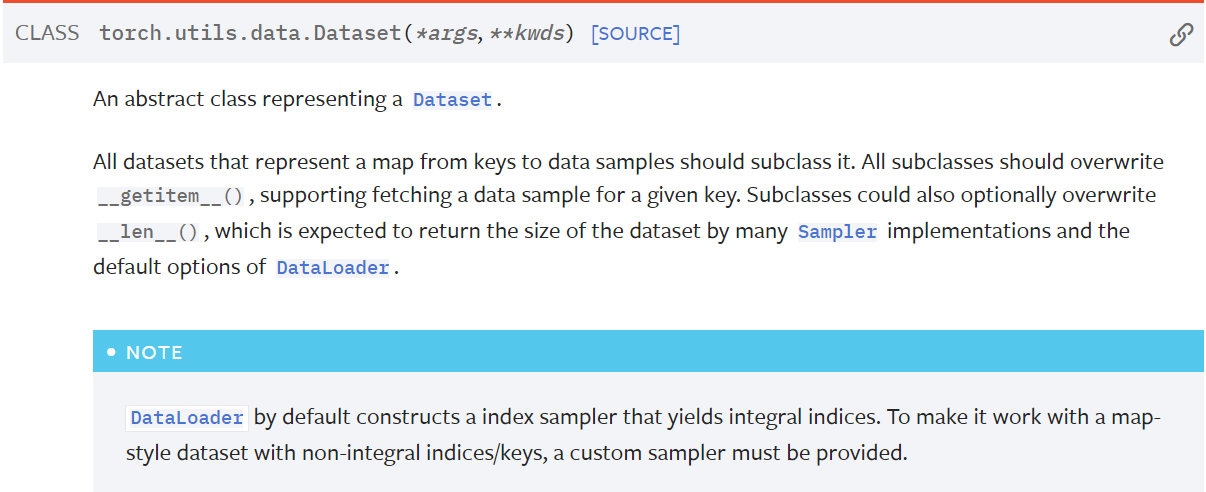
class CashDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
纸币分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
# data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.data_info = self.get_img_info(data_dir)
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
上面代码中的静态方法getimginfo(datadir)就是用来构建数据列表的,它返回数据列表datainfo,datainfo中的元素由元组(图像路径,图像标签)构成。
在getitem(self, index)方法中,通过datainfo中存储的文件路径去读取图像数据,最后返回索引下标为index的图像数据和标签。这里返回哪些数据主要是由训练代码中需要哪些数据来决定。也就是说,我们根据训练代码需要什么数据来重写getitem(self, index)方法并返回相应的数据。
最后还要重写len(self)方法。实现len(self)方法比较简单,只需一行代码,也就是返回数据列表的的长度,即数据集的样本数量。
下面对构建CashDataset类做个小结,主要步骤如下:
1) 确定训练代码需要哪些数据;
2) 重写getitem(self, index)方法,根据index返回训练代码所需的数据;
3) 编写静态方法,构建并返回数据列表data_info;
4) 重写__len(self)方法,返回数据列表长度;
看到这里,也许会有两个困惑:
困惑1:在训练代码中是怎么调用到__getitem( )的,是编写代码手动调用,还是Pytorch函数内部自动调用?
困惑2:__getitem( )返回的数据是单个 (图像, 标签),为什么在训练代码中得到的数据格式不是[(图像1, 标签1), (图像2, 标签2),, …, (图像n, 标签n)]这种格式,而是[图像1, 图像2, …, 图像n]、[标签1, 标签2, …, 标签n] 这种格式?
要想知道这两个答案,就需要了解Pytorch调用CashDataset的底层逻辑。
3 用Dataset类构建数据集的底层逻辑
# 构建CashDataset实例
train_data = CashDataset(data_dir=train_dir, transform=train_transform)
valid_data = CashDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
如上面代码第六行所示,在创建DataLoader对象时,将数据集traindata作为参数传入DataLoader中。所以,我们大概能猜到应该是在DataLoader内部直接或间接地调用了getitem( )。DataLoader是Pytorch的数据加载器,下面让我们深入其内部看看它是怎样一步一步执行,最终调用到_getitem( )。
在Pytorch官网可以查到Dataloader的构造方法有很多参数,我们这里主要关注其中四个,如下图所示。
DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False)
dataset:需要载入的数据集
batchsize:批大小,即迭代器一次加载多少个样本
numworkers:使用多少个子进程来加载数据,0表示只在主进程中加载数据。Pytorch会根据此参数来判断是创建单进程SingleProcessDataLoaderIter类对象,还是创建多进程MultiProcessingDataLoaderIter类对象
shuffle:是否在每个epoch训练前打乱数据集中的样本顺序
为了能弄清dataloader的整个执行过程,需通过打断点、步进的方式进入到dataloader类内部。
如上图所示,在for循环处打个断点,然后点击步进按钮,可以得到大致的执行流程,如下图所示。下图中冒号左侧是类名,冒号右侧是类方法,方框中只列出类方法中的主要代码。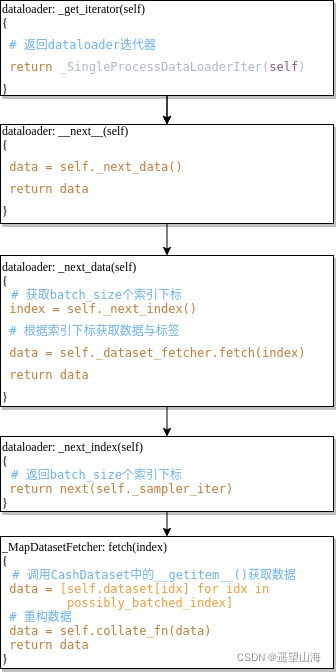
如上图最后一步所示,在_MapDatasetFetcher类中的fetch( )方法中,执行self.dataset[idx]会去调用_getitem( )方法,以获取train_data中的数据。经过batch_size次循环得到数据列表data,再通过self.collate_fn( )方法重构data。也就是将 [(图像1, 标签1), (图像2, 标签2),, …, (图像n, 标签n)] 这种格式,变换为 [图像1, 图像2, …, 图像n]、[标签1, 标签2, …, 标签n] 这种格式。
4 总结
关于Pytorch如何调用CashDataset以获取训练数据的底层逻辑,可以概括为三点:Ⅰ) 由Dataloader创建一个迭代器dataloaderIter;Ⅱ) dataloaderIter通过调用sampleriter得到一个batchsize的索引下标序列;Ⅲ) 在_MapDatasetFetcher类的fetch( )方法中调用__getitem( ),以获取数据与类标签,再通过collate_fn( )重构数据列表。
6.3关于pytorch函数包在本次实验中的用法详解
1.to(device)
在学习深度学习的时候,我们写代码经常会见到类似的代码:
img = img.to(device=torch.device("cuda" if torch.cuda.is_available() else "cpu"))
model = models.vgg16_bn(pretrained=True).to(device=torch.device("cuda" if torch.cuda.is_available() else "cpu"))
也可以先定义device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
img = img.to(device)
- 那么段代码到底有什么用呢?
这段代码的意思就是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
2. 你可能会问,为什么要在GPU上做运算呢?
首先,在做高维特征运算的时候,采用GPU无疑是比用CPU效率更高,如果两个数据中一个加了.cuda()或者.to(device),而另外一个没有加,就会造成类型不匹配而报错。
tensor和numpy都是矩阵,前者能在GPU上运行,后者只能在CPU运行,所以要注意数据类型的转换。
3. .cuda()和.to(device)的效果一样吗?为什么后者更好?
两个方法都可以达到同样的效果,在pytorch中,即使是有GPU的机器,它也不会自动使用GPU,而是需要在程序中显示指定。调用model.cuda(),可以将模型加载到GPU上去。这种方法不被提倡,而建议使用model.to(device)的方式,这样可以显示指定需要使用的计算资源,特别是有多个GPU的情况下。
4. 如果你有多个GPU,那么可以参考以下代码:device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model = Model() if torch.cuda.device_count() > 1: model = nn.DataParallel(model,device_ids=[0,1,2]) model.to(device)
2.torch.optim
torch.optim神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。在pytorch中提供了torch.optim方法优化我们的神经网络,torch.optim是实现各种优化算法的包。最常用的方法都已经支持,接口很常规,所以以后也可以很容易地集成更复杂的方法。
pytorch官方文档如下:https://pytorch.org/docs/stable/optim.html
Optim必须构造一个优化器对象,该对象将保存当前状态,并根据计算的梯度更新参数。
构建它要构造一个优化器,你必须给它一个包含要优化的参数(都应该是 Variable)的迭代。 然后,您可以指定特定于优化器的选项,例如学习率、权重衰减等。
如果您需要通过 .cuda() 将模型移动到 GPU,请在为其构建优化器之前执行此操作。 .cuda() 之后的模型参数将是与调用之前不同的对象。
通常,在构建和使用优化器时,您应该确保优化的参数位于一致的位置。
例子:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
每个参数选项
优化器还支持指定每个参数的选项。 为此,不要传递 Variable 的迭代,而是传递 dict 的迭代。 它们中的每一个都将定义一个单独的参数组,并且应该包含一个 params 键,其中包含一个属于它的参数列表。 其他键应与优化器接受的关键字参数匹配,并将用作该组的优化选项。
您仍然可以将选项作为关键字参数传递。 它们将在没有覆盖它们的组中用作默认值。 当您只想改变单个选项,同时在参数组之间保持所有其他选项一致时,这很有用。
例如,当您想要指定每层学习率时,这非常有用:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
这意味着model.base的参数将使用默认的1e-2学习率,model.classifier的参数将使用1e-3的学习率,所有参数将使用0.9的动量。采取优化步骤所有优化器都实现了一个 step() 方法,该方法更新参数。 它可以通过两种方式使用:optimizer.step()这是大多数优化器支持的简化版本。 一旦使用例如backward()计算梯度,就可以调用该函数。
例子:
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
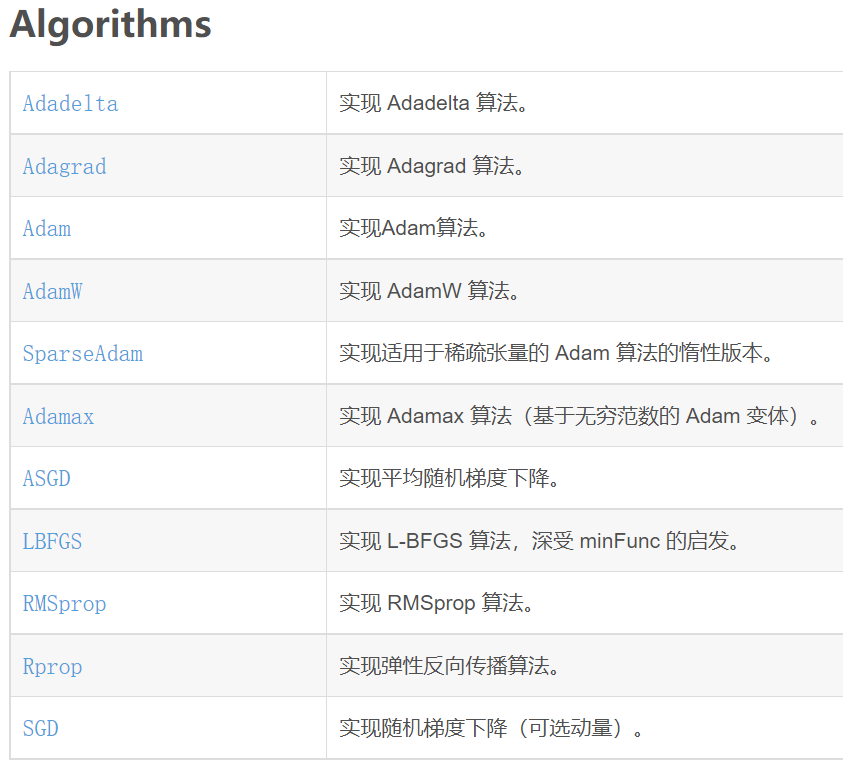
3.d2l包详解
d2l 包 是李沐老师对与《动手学习深度学习》 中提供代码的使用其他框架时候的公共库。
包含3大类的可使用库:
- mxnet
- pytorch
- TensorFlow
本文,主要针对这个d2l 库进行一些基本的解析和学习,以便我们自己在进行深度学习代码编写的时候
有所参考。
d2l包官方文档:https://github.com/d2l-ai/d2l-zh/blob/master/d2l/torch.py
class Animator:
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
"""Defined in :numref:`sec_softmax_scratch`"""
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)

若有收获,就点个赞吧
0 人点赞
