Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Batch Normalization.pdf
1.为什么会出现BN
训练深度神经网络的时候,在训练过程中,每一层的输入的分布一直在改变。这是因为前一层的参数一直在改变,而前一层的输出又作为后面一层的输入,如此一来,每一层的输入的分布就处于一个变化的状态。在这种情况下,需要以一个非常小的学习率进行训练,而且对参数的初始化也要很小心,这将减慢训练速度。此外,对存在非线性饱和的模(modelswithsaturating nonlinearities),训练将非常的难。作者称这种现象叫“内部协变量转移(internal covariate shift)”。
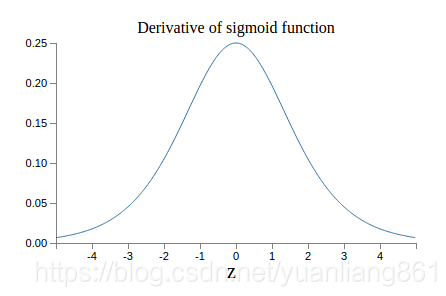
比如说使用sigmoid激活函数的模型,当输入比较大或者比较小的时候,激活函数的导数约为0,那么得到的梯度将也约为0,那么训练的时候,参数更新会变得非常慢,甚至几乎不更新,也就时说训练不起作用了。(如下面两图可以看出)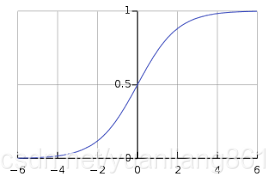
那么解决的策略是什么呢?把输入标准化。在本文中,将标准化输入这件事变成了模型的一部分,并且对每一个训练的mini-batch进行标准化操作。使用Batch Normalization操作,将允许我们在训练的时候采用更大的学习率,不用太关注参数初始化,而Batch Normalization有正则化的作用,使得模型对Dropout的需求降低,这也是一件好事(因为使用Dropout,训练的时候,loss波动会大一些,训练速度也会需要多一点)。在达到相同准确率的情况下,使用Batch Normalization比不采Batch Normalization要快14倍。
梯度爆炸和梯度消失
解决的问题是梯度消失与梯度爆炸。
关于梯度消失,以sigmoid函数为例子,sigmoid函数使得输出在[0,1]之间。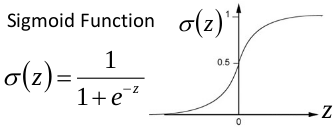
事实上x到了一定大小,经过sigmoid函数的输出范围就很小了,参考下图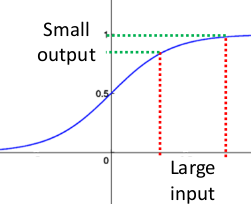
自我理解
为什么BN可以使得训练的时候采用更大的学习率呢,而且可以处理非线性饱和问题?
当输入的分布比较乱时,数据一会大一会小,那么模型中参数的变化会比较大,想要训练出一个模型能够在整个训练集上都有较好的表现时相对困难的。而且会出现非线性饱和的现象,这个时候训练就会变得很慢。不止是sigmoid激活函数,tanh(x)也是一样的,只不过比sigmoid好一点。
使用BN的作用,就是把整个数据的分布归一化到均值为0,方差为1的分布上。这意味着强行把数据调整到激活函数的敏感区,这样,无论是什么样的数据,都将会得到一个比较大的梯度,训练时收敛的自然就会快。
优势
作者通过实验验证了BN的作用,只是简单的对在模型中使用Batch Normalization不能充分发挥Batch Normalization的作用。作者各处了一下几点,充分发挥BN的作用:
(1)增大学习率(Increase learning rate)
(2)去掉Dropout(Remove Dropout)
(3)去掉L2正则化(Reduce the L2 weight regularization)
(4)加速学习率的衰减(Accelerate the learning rate decay)
(5)删除局部响应归一化(Remove Local Response Normalization)
(6)将训练集充分打乱(Shuffle training examples more thoroughly),这一点有助于提升准确率。
(7)减少图像的拉伸形变,更多的专注于真实图像(Reduce the photometric distortions)

若有收获,就点个赞吧
0 人点赞
