摘要
图像在获取的过程中,由于环境、设备、传输、后处理等原因常常具有不同种类以及不同程度的退化。图像增强算法主要针对退化图像实现自适应的质量恢复,是主要的低层计算机视觉任务,在数码相机、自动驾驶等重要领域具有重要作用。本文旨在介绍通过神经网络训练超分辨率的基本流程,并且对不同模型和不同结构的神经网络进行对比研究,分析网络结构的改变对神经网络的超分辨率的性能的影响。
1.图像超分辨率介绍
1.1 问题介绍
图像超分辨率旨在从低分辨率图像恢复相应的高分辨率图像。通常的来说,低分辨率的图像是高分辨率图像经过退化模型之后的输出。
其中 对退化映射函数,
对退化映射函数, 对应高分辨率的图像,
对应高分辨率的图像, 是退化过程的参数。科研人员的研究目标就是从
是退化过程的参数。科研人员的研究目标就是从 中恢复一个以
中恢复一个以 为基准的近似图像,我们可以用如下的公式来表达:
为基准的近似图像,我们可以用如下的公式来表达:
其中 是超分辨率的模型,
是超分辨率的模型, 是模型的参数。
是模型的参数。
在大多数情况下,退化的过程是未知的,虽然退化过程是未知的,并且会受到各种因素的影响(例如,压缩伪影、各向异性退化、传感器噪声和散斑噪声)。所以在研究中,我们一般把下采样作为退化模型。
1.2 有监督图像超分辨率
目前,研究人员提出了各种具有深度学习的超分辨率模型。这些模型关注于有监督的SR,即使用LR图像和相应的HR图像进行训练。虽然这些模型之间的差异非常大,但它们本质上是一组组件的一些组合,如模型框架、上采样方法、网络设计和学习策略。从这个角度出发,研究人员将这些组件组合起来,构建了一个集成的SR模型,以适应特定的目的。
其中以图像的上采样为划分可以划分成,前置上采样超分模型和后置上采样超分模型。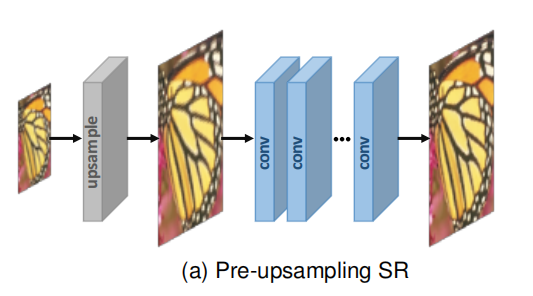
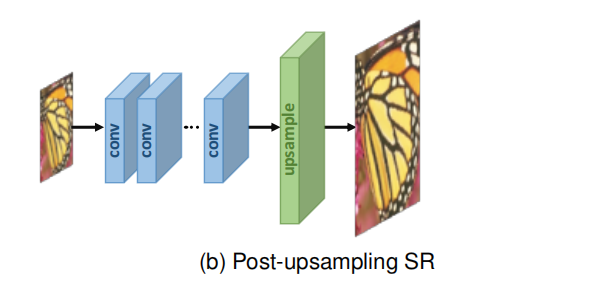
1.3 前置上采样超分辨率
由于从低维空间到高维空间的映射很难直接学习,利用传统的上采样算法获得更高分辨率的图像,然后使用深度神经网络进行细化是一个简单的解决方案。因此Dong等人。首先采用预上采样SR框架(如图a所示),并提出SRCNN学习从插值后的LR图像到HR图像的端到端映射。具体地说,利用传统的方法(如双三次插值)将LR图像上采样到所需大小的粗HR图像。由于完成了最困难的上采样操作,CNNs只需对粗糙图像进行细化,大大降低了学习难度。
1.4 后置上采样超分辨率
为了提高计算效率,充分利用深度学习技术自动提高分辨率,研究人员提出在模型末端集成端到端可学习层,取代预定义的上采样,在低维空间进行大部分计算。在该框架的开创性工作中,即上采样后的SR,如图(b)所示,LR输入图像在不增加分辨率的情况下被送入深度CNN,并在网络末端应用端到端可学习的上采样层。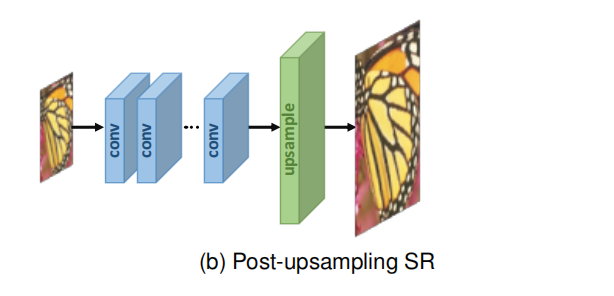
2.模型分析
2.1 SRCNN
提出了一种针对单图像超分辨率的深度学习方法。SRCNN直接学习低/高分辨率图像之间的端到端映射。将这种映射表示为以低分辨率图像为输入,输出高分辨率图像的深度卷积神经网络(CNN)。
(图2-1 SRCNN网络结构)
SRCNN由三层卷积层组成,我们可以把SRCNN的网络结构分成三个主要的部分。
1.Patch的提取及表示。2.非线性映射。3.重构。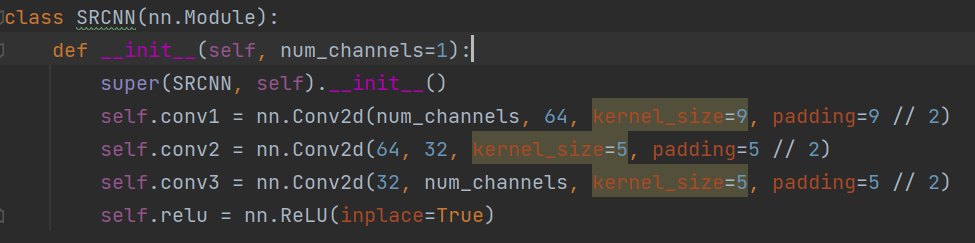
(图2-2 SRCNN的代码实现)
其中第一层采用了一个9x9的卷积核,第二层采用了5x5的卷积核,第三层也采用了5x5的卷积核。
2.2 VDSR
VDSR提出了一种高精度的单图像超分辨率(SR)方法。VDSR使用了一个非常深的卷积网络,其灵感来自于用于ImageNet分类的VGG-net。作者发现,增加网络深度可以显著提高准确性。VDSR最终的模型使用了20个卷积层。通过在深度网络结构中多次级联小滤波器,可以有效地利用大图像区域的上下文信息。然而,对于非常深的网络,收敛速度成为训练过程中的一个关键问题。VDSR提出一个简单而有效的培训程序。
(图2-3 VDSR的网络结构)
VDSR除了第一层和最后一层都采用了一样的网络结构,64个滤波器并且每个都是3x3x64的结构。
VDSR的主要卷积部分是参考了VGG-Net的设计思路。VGGNet全部使用33的卷积核和22的池化核,通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。同时,两个33卷积层的串联相当于1个55的卷积层,3个33的卷积层串联相当于1个77的卷积层,即3个33卷积层的感受野大小相当于1个77的卷积层。但是3个33的卷积层参数量只有77的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强。
(图2-4 VGG-Net示意图)

(图2-5 VDSR中的残差结构)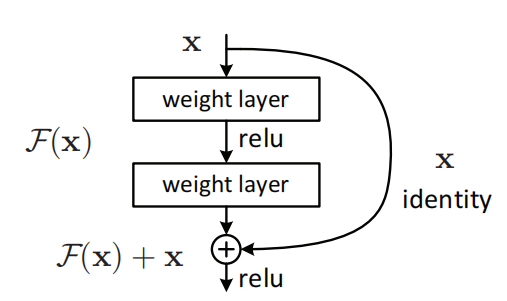
(图2-6 残差结构示意图)
VDSR的第一层用于处理图像的输入,VDSR的最后一层用于实现图像的重构包含一个单一的3x3x64结构的滤波器。该网络获取一个插值的低分辨率图像(到所需的大小)作为输入并预测图像细节。VDSR对输入的图像的预处理与SRCNN的预处理是相同的。
2.3 VDSR相比于SRCNN的提升
SRCNN网络结构存在3点局限性:
1.依赖较小的图像区域的上下文信息
2.网络训练收敛速度慢
3.网络只能解决单一尺度的图像超分辨率
由于SRCNN的网络深度较浅,所以SRCNN的卷积的感受野较小,无法捕捉较大区域的图像上下文信息,导致SRCNN在进行超分恢复时效果不尽人意。SRCNN并未使用残差网络结构,在训练时无法采用较大的学习率,导致学习效率较低。
VDSR提出了一些新的方法来解决了这些问题
1.更深的网络使用更大的感受野来获取图像上下文信息。作者是用了基于VGG-Net的深度卷积网络,使用更小的卷积核以及更深的网络,可以增加网络的非线性能力最终提高网络的性能。
2.网络进行残差学习(residual-learning CNN),并且使用极高的学习率,提高收敛(Convergence)速度。采用大学习率,容易遇到梯度消失和梯度爆炸(vanishing/exploding gradients)的问题,这里使用残差学习和可调梯度裁剪技术(adjustable gradient clipping)来抑制梯度问题的产生。
3.一个单一神经网络可以针对不同尺度(Scale Factor)进行图像超分辨率重构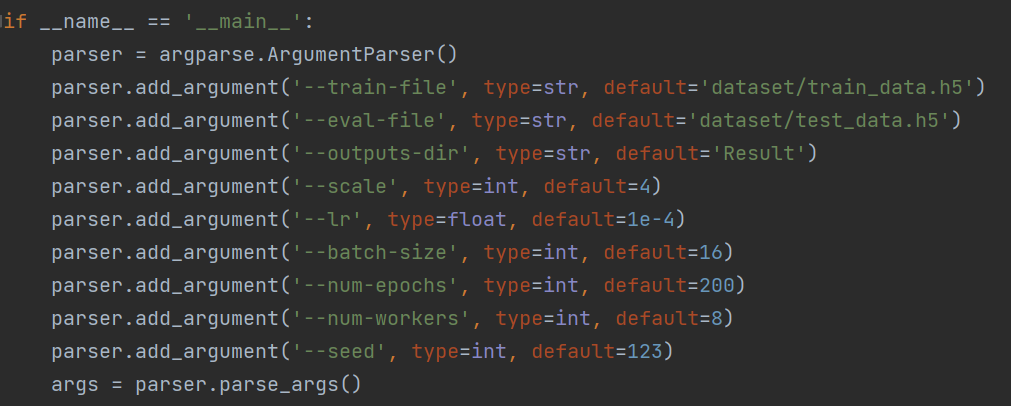
(图2-7 SRCNN的参数设置,学习率为1e-4)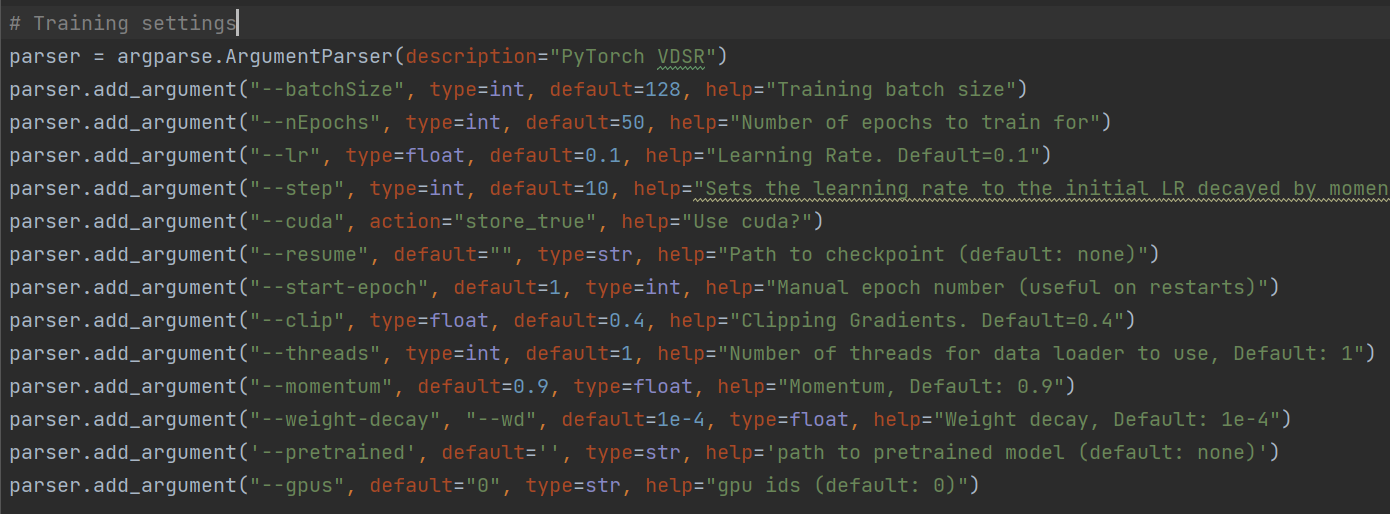
(图2-8 VDSR的参数设置,学习率为0.1)
可以看出,VDSR采用了残差学习的方法之后,提高了学习率使网络训练的时间大幅度降低,并且更深的网络结构也提高了网络的测试精度。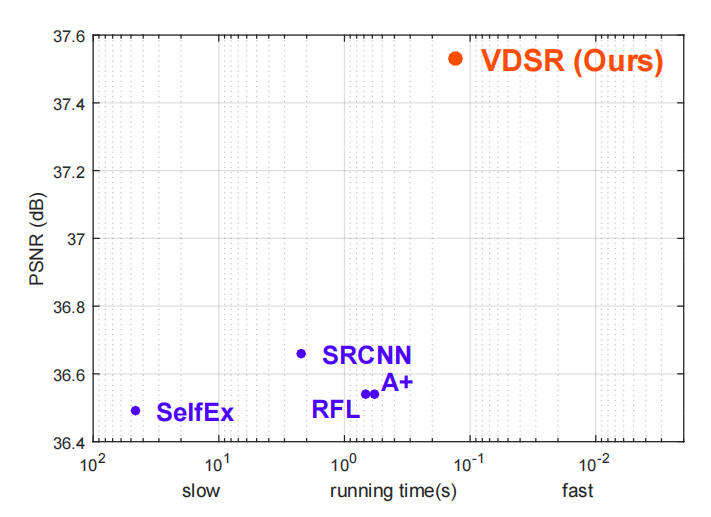
(图2-9 VDSR相比于SRCNN的提升)
3. 数据预处理
SRCNN和VDSR的数据预处理模块是相同的,SRCNN与VDSR都是属于前置上采样超分辨率。先通过传统的双三次插值算法对图像进行上采样,之后再把上采样后的图片输入到神经网络中进行一个端到端的训练。
由于输入的数据,长宽不一,且未必是超分系数的整数倍。所以我们也要先对输入的图像进行预处理。
使输入的图像可以刚好依照超分系数进行相应的下采样操作。
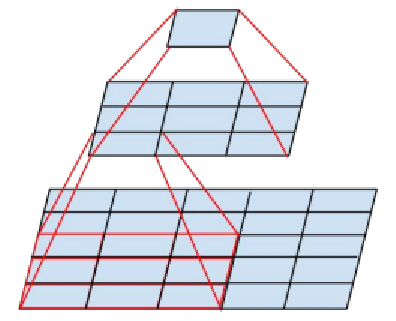
(图3-1 图像尺寸裁剪)
对图像的预处理,需要先对输入的高分辨率图像进行下采样,得到相应的低分辨率图像,但由于神经网络进行的是一个端到端的学习,所以我们还需要把下采样之后的低分辨率图像进行一个上采样放大,使输入神经网络的图片的尺寸与我们最终想要得到的高分辨率图片的尺寸相同。
(图3-2 低分辨率图像上采样)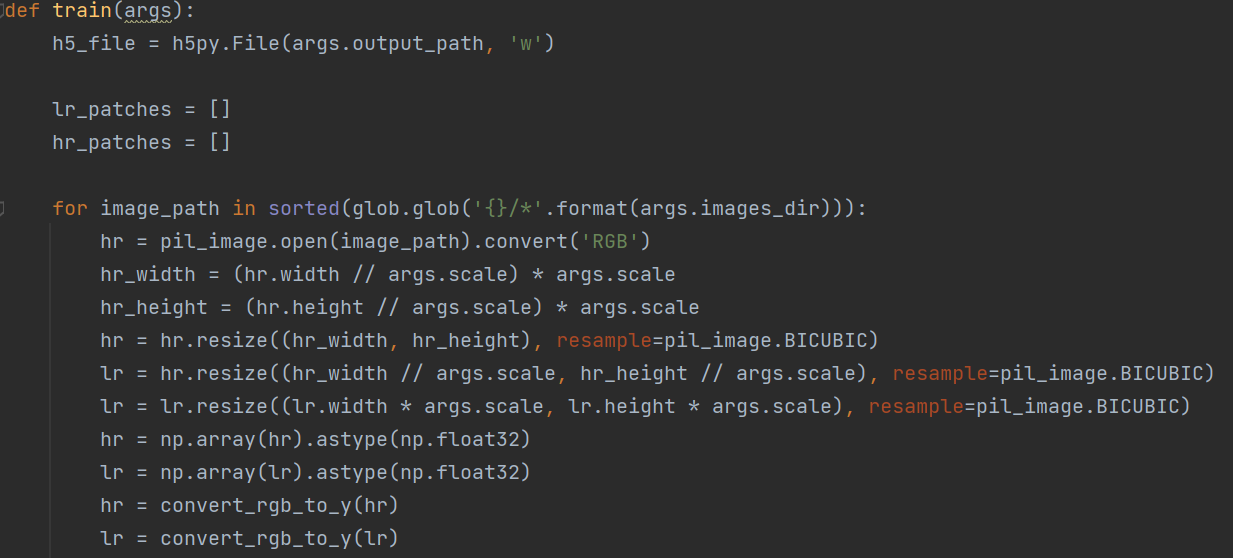
(图3-3 数据预处理模块)
最后,根据模型需要的数据类型,把处理好的高分辨率图像和低分辨率图像打包成.h5的文件形式作为数据集来使用。
4.模型训练部分
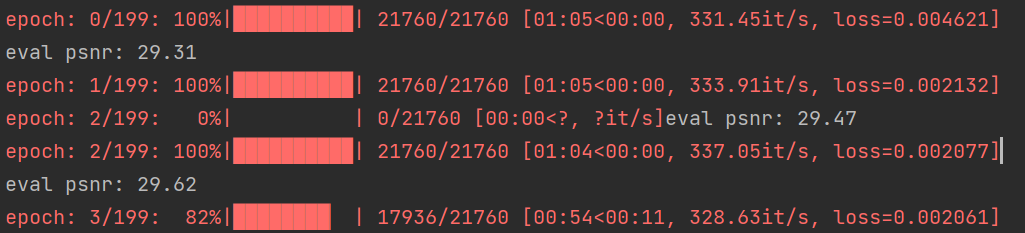
(图4-1 SRCNN的训练过程)
(图4-2 VDSR的训练过程)
可以看出采用VDSR模型的时候,PSNR的值会大于SRCNN,效果更好。
5.测试部分
测试图片的原图来自于Set5测试集里面的Butterfly.png
(图5-1 原图)
经过BICUBIC算法处理之后的上采样图片:

(图5-2 BICUBIC处理之后的图片)
(图5-3 SRCNN的输出图片)
经过SRCNN处理之后的PSNR为25.93
(图5-4 VDSR的输出图片)
VDSR网络输出的PSNR为26.94

若有收获,就点个赞吧
0 人点赞
