一、实验目标
从老师给的题目中来看,本次实验的目标可以简化为,对输入的长度为8192的序列,做三分类处理。数据格式为
所以本质上是对输入序列做三分类处理。
从提供的数据集的数据量来看,给的数据集是一个小样本的数据集,所以本次实验的核心问题是:如何对小样本的输入序列进行三分类处理,同时避免模型产生过拟合。
二、实验数据
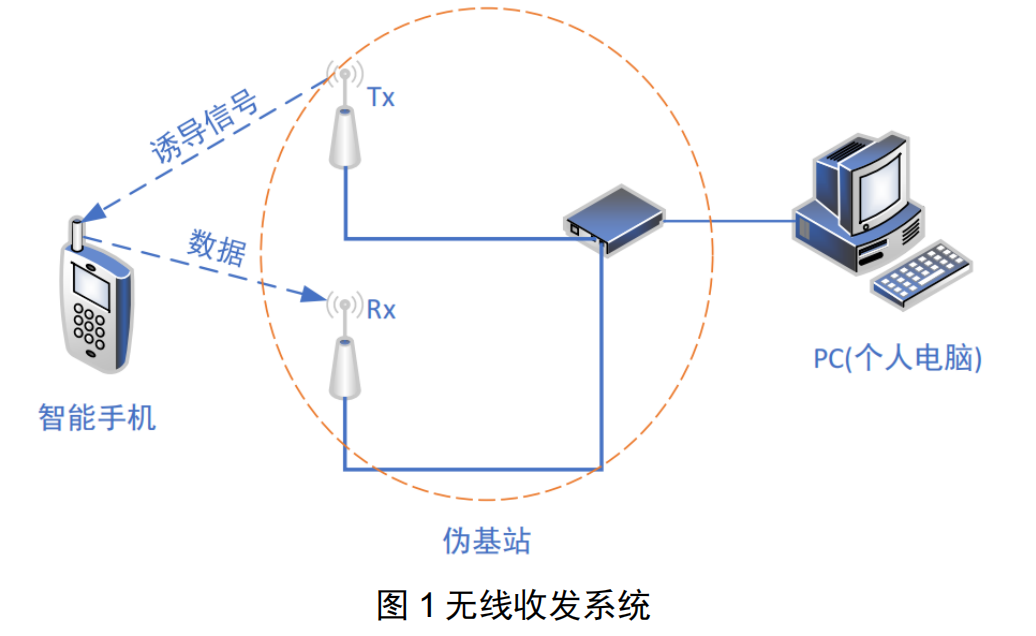
真实无线场景如图 1 所示,伪基站所接收到的数据后传给 PC,PC 对所接受到的时域数据进行了如图 2 的操作,得到频域上截断且信道均衡后的信号。其中,手机的工作制式为 4G LTE联通 FDD 制式,采用 OFDM-QPSK 调制,工作频段为 1850MHz,接收机采样频率为122.68MHz,数据保存格式为 int16 格式保存为 dat 文件,一个文件内有若个 OFDM 参考符号,且每一个 OFDM 参考符号采样为时域上 8192 个点(图 2)。
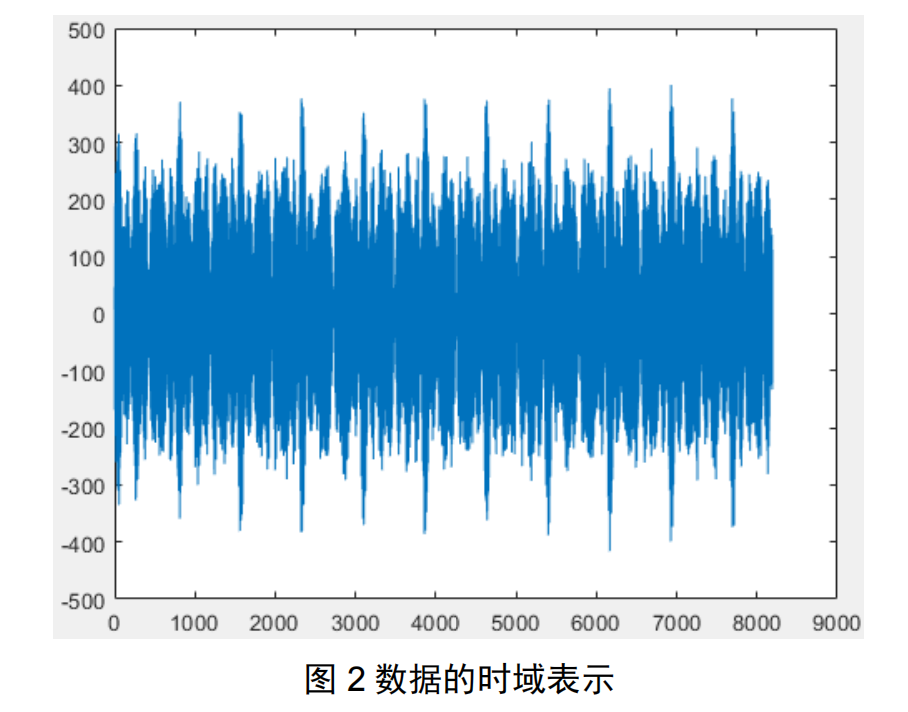
引用原文来看,输入的8192长度的时间序列,是存在一些先验关系的。输入的8192序列是OFDM调制信号,是手机发出的信号的时域表现形式。我们都知道,电子设备之间的通信主要是通过捕捉电磁波的频率来实现的。所以我们对捕捉到的信号应该要意识到一点问题就是,该数据集的8192长度的序列应该是经过STFT短时傅里叶变换之后的信号。
(图3 — 短时傅里叶变化信号图)
所以序列与相邻直接的关联比较大,与相距较远的关联较小。直接采用神经网络的全连接方法可能会产生过拟合的情况,反而会影响了模型的精度。
三、实验思路
面对三分类问题,我们很自然的会想到可以采用传统的机器学习算法,或者采用深度学习算法。来处理和训练该模型。如果使用机器学习算法的话,我们首先可以想到SVM支持向量机,和逻辑回归模型。由于是三分类问题,所以我们只要用两个超平面就可以实现三分割任务。简单的模型应对简单的问题,太复杂,太深的网络反而容易出现过拟合的情况。但是考虑到给的baseline.py的主干架构都是pytorch的深度学习架构。所以为了减少工作量,转而思考如何使用深度学习的方法来降低过拟合。
3.1 用一维卷积处理序列
深度学习中主要分为两个方向,图像处理和自然语言处理。我的主要研究方向是图像处理,就会想到用卷积来处理问题。之前常用的是Conv2d方法,但这是对图片进行处理,因为图片是2维的。但目前我们要处理的是一维的序列,应该使用更接近的transformer来训练模型。在使用transformer之前,我们先采用了一维卷积Conv1d方法来试试能否提高模型的性能。
- 所谓的一维卷积,也就是卷积核是一维的。原理和2D Conv类似,只不过1D Conv的卷积核移动方向只有一个,从滑动窗口的直观角度来看,多通道一维卷积核在数据长度方向上滑动。
用一维卷积来处理一维数据或许会是一个比较好的尝试。
采用一维卷积方法来处理序列的优势:
- 用一维卷积正好可以处理序列信号
- 卷积特有的卷积核,可以捕捉特定范围内的上下文信息
- 卷积的拟合能力比较强
代码如下:
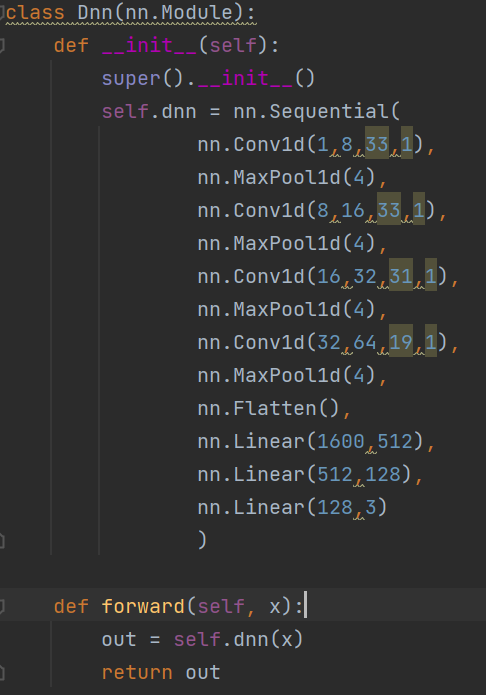
(图3-1 网络模型)
根据上文对实验数据的分析,我们采用了一维卷积来处理数据,kernel_size取的比较小是为了迎合输入信号的特点——即较远时间的信号关联不大。所以采用较小的kernel_size能够比较好的处理STFT产生的信号。
之后经过池化层,同时又在一定程度上增大了模型的感受野。
经过几轮的一维卷积之后,再通过Flatten方法,压平输入的数据,让其返回一维序列的格式。再通过全连接层实现了三分类功能。
模型中的全连接层的第一层的输入1600,是通过计算得出的。即每次卷积之后都会让序列减少一定的长度。相比于baseline方法的改进
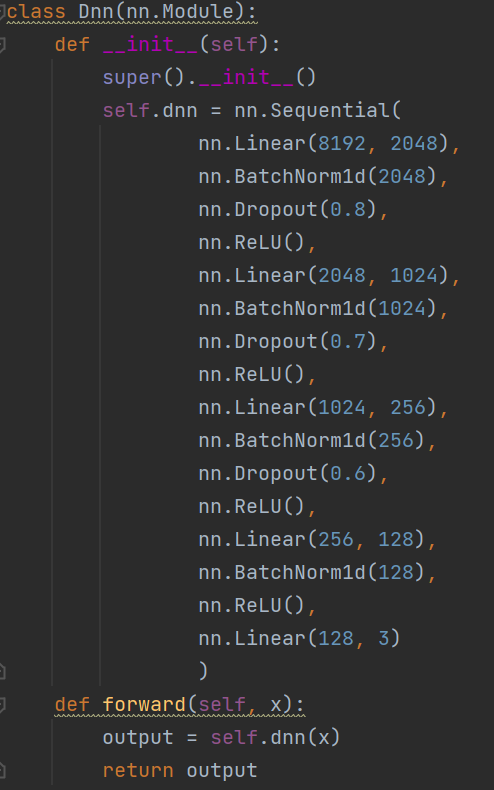
(图3-2 baseline模型)
baseline模型中,采用的是全连接方法,并且多次使用BatchNormalization和Dropout,太复杂的模型反而容易出现过拟合问题。面对小样本的数据处理任务,应该要使用轻量级的模型。轻量级的模型处理轻量级的问题,面对数据量大的问题,应该要使用结构复杂的模型。如果模型深度不是很深,感觉没有太大必要使用BatchNorm来进行数据预处理,采用了BN之后,可以增大模型的学习率。但是在本次实验中似乎没有这个必要,采用了BN泛而增加了模型的复杂度,增加了运算的压力。
3.2 数据预处理
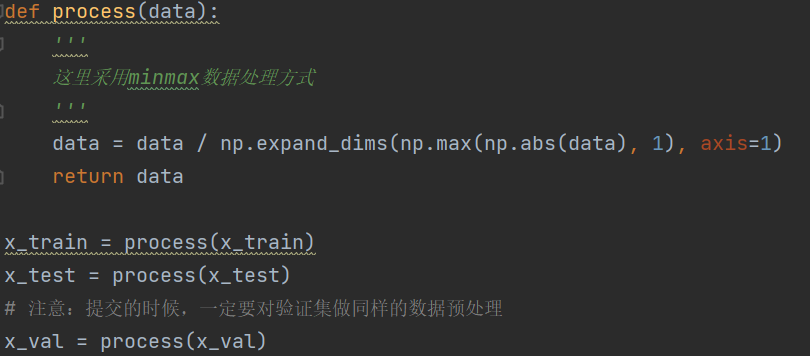
(图3-3 数据预处理)
此处的数据预处理是采用baseline的方法,并没有做过多的改变。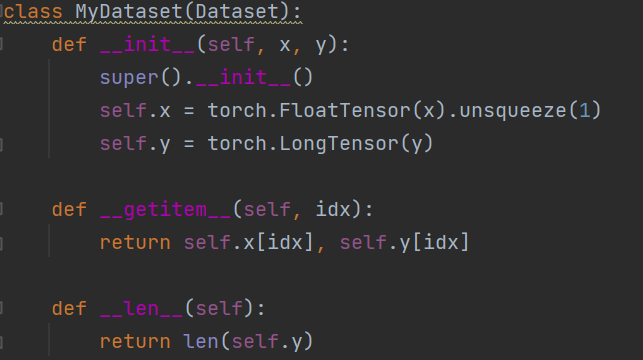
(图3-4 数据封装)
由于使用的是conv1d方法,使原本的数据多了一个特征维度,所以我们要对输入的训练数据进行预处理,对训练集的数据做升维处理,增加一个特征维度。
3.3 模型训练

(图3-5 模型训练1)
相比于原先的baseline我添加了一个变梯度的学习方法,在epochs=60,100,150的时候降低学习率为原来的0.5。通过采用变学习率的方法可以避免梯度爆炸和梯度消失,也可以防止学习率太大从而无法收敛的问题。

(图3-6 模型训练2)
对于训练模型,我们设置了200个epochs。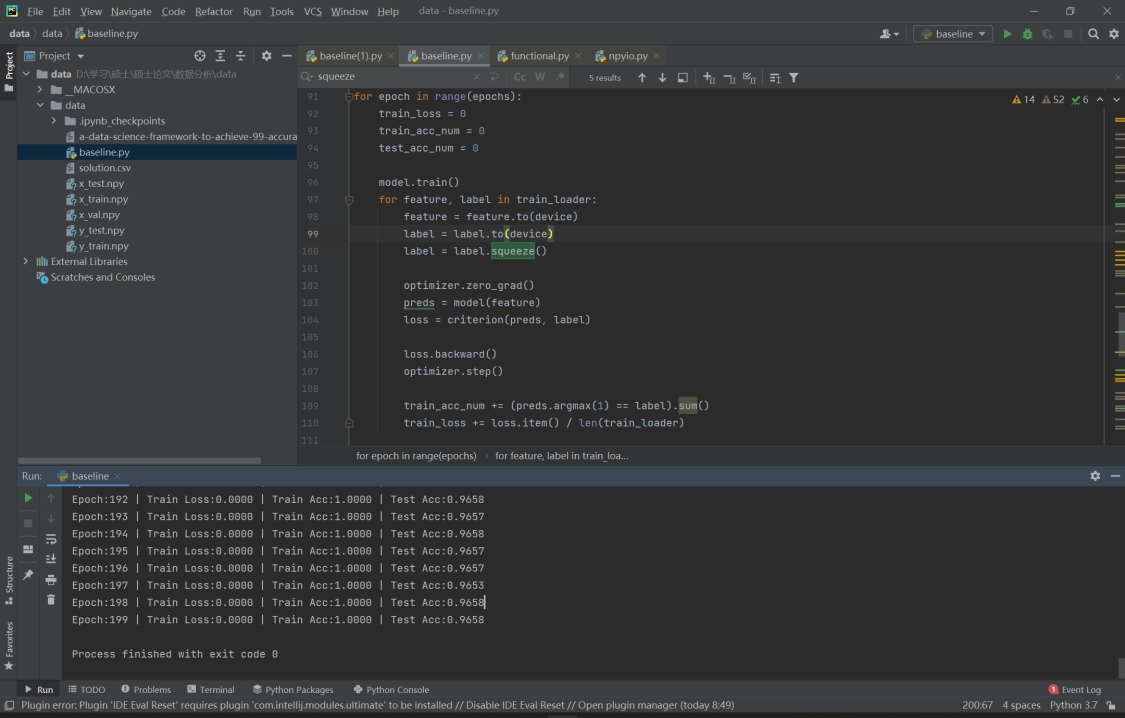
(图3-7 训练结果)
从训练结果中可以看出,相比于baseline,采用了conv1d来对序列进行处理,使模型性能得到了大幅的提高,训练精度高达100%,预测精度高达96%
3.4 程序使用
本次实验代码修改的内容并不多,只是对网络结构做了修改。程序的核心还是在于,模型的搭建。
(图3-8 模型预测)
根据之前训练好的模型,来对x_val进行预测。每次预测的样本数为sample_batch = 100
程序的训练只需要run baseline.py即可。
四、结论
通过实验数据可以看出,采用了conv1d为核心的深度神经网络模型,对小样本的手机信号序列的分类任务取得了较好的成绩,相比于采用全连接方法取得了较大的提升。采用全连接方法对手机信号序列的处理,可能无法取得较好的成果,容易产生训练的过拟合,这是由于数据本身的特质——即手机发出的信号是经过短时傅里叶变化处理后的信号,决定的。采用了一维卷积之后可以更好的适应信号本身的特点,从而取得了更好的实验效果。
参考文献
[1] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR, 2015: 448-456.
[2] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011: 315-323.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[4] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25.

若有收获,就点个赞吧
0 人点赞
