Facebook 签到地址预测
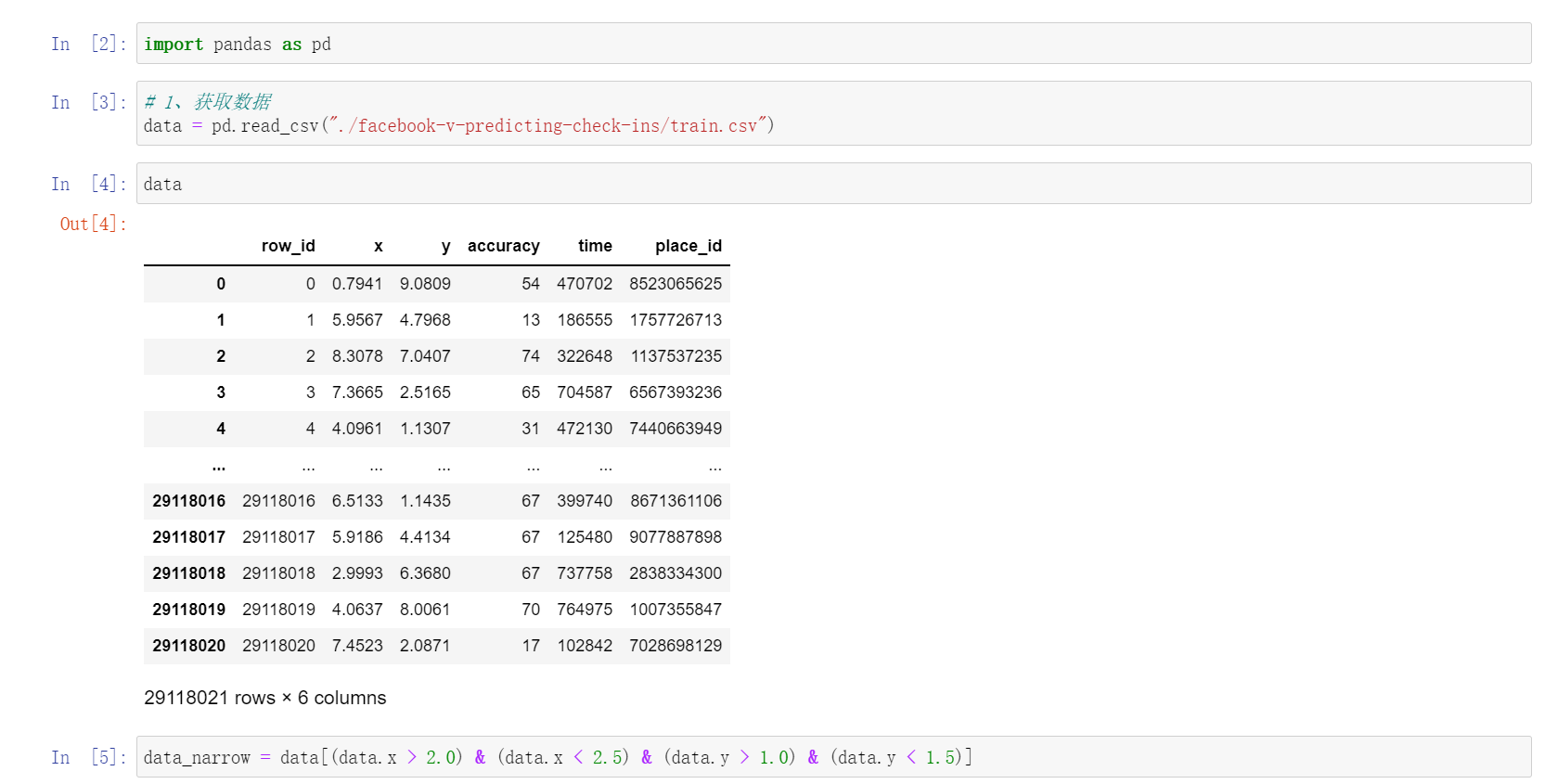
我们向Python输入了一个数据集。这个数据集有
row_id , x , y ,accuracy , time , place_id等字段。现在我们的目标是找出这些字段之间的数字规律,并通过数据进行预测。
1. 缩放数据的尺寸
data_narrow = data[(data.x > 2.0) & (data.x < 2.5) & (data.y > 1.0) & (data.y < 1.5)]
对我们而言,处理的只是数据的规模不同,但是处理的方法和思路是一样的。
这里有个要点,我们可以用query进行数据处理,也可以直接在data[]的索引中,直接加入我们需要的判断条件,但是每一个判断条件里面只能有一个true 或 false
2. 把转换我们看到的时间戳的格式
我们可以从图中看到,时间戳那一列,都是数字,这对于我们而言,很难区分具体的时间节点,所以我们要用
datetime数据结构进行数据的处理。
time_value = pd.to_datetime(data_narrow["time"],unit="s")
这样我们就把time从int转化为了datetime数据结构
3. 把处理好的时间数据,添加到原有的数据里
data_narrow["day"] = date.daydata_narrow["weekday"] = date.weekdaydata_narrow["hour"] = date.hour
4. 过滤掉签到次数比较少的地点
data_narrow.groupby('place_id')

此时我们输出的,是一个迭代器,所以我们直接显示
data_narrow.groupby(‘place_id’)是无法显示的。
但是我们在对分组进行聚合之后,我们又能看到相应的数据。
data_narrow.groupby('place_id').count()
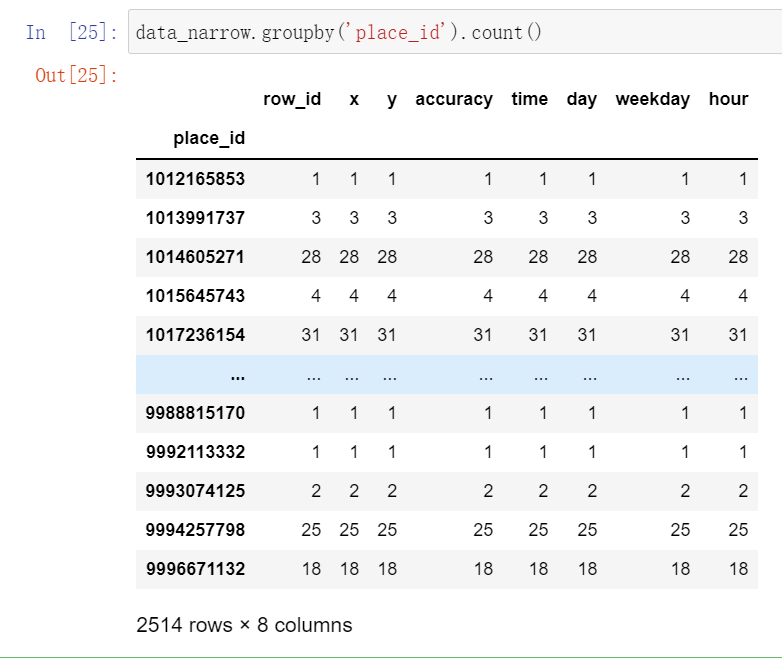
现在我们有这样一组数据,我们想要统计place_id出现的频率,我们可以采用 分组和聚合 的方法
data_narrow.groupby('place_id') # 对DataFrame进行分组place_id = data_narrow.groupby('place_id').count() #再对分组进行聚合
只是分组没有聚合,输出的是一个迭代器,里面是分好组的DataFrame
这样我们就得到了,分好组的place.count()
现在我们只需要第一列就行了
place_count = place_count['row_id']
Pandas的索引条件,必须是索引值对应 True 或 False
如果是True或者False说明,我们已经经过了一次判断了。
place_count_index = place_count[place_count > 3] # 这样就可以把所有频率大于3的找出来
place_count = place_count[place_count_index]
这样我们就去除了一些小的不满足签到次数的地点。
现在,我们要再创建一个index去删除data_narrow里面的数据
index_new = data_narrow['place_id'].isin(place_count)
这样我们就会得到一个index_new的索引判断
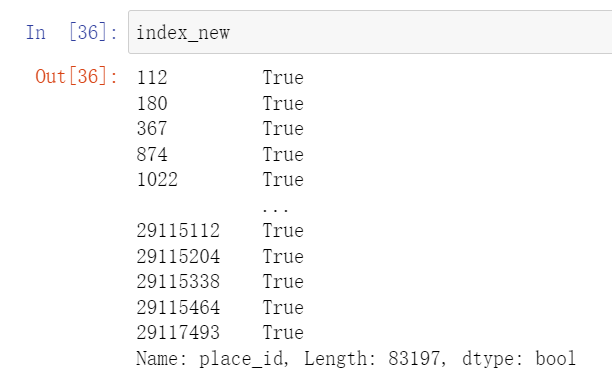
index_new有个特点,就是前面是index,后面对应了Boolean值。
data_narrow[index_new]
5.获取数据集的特征值和目标值
data_final = data_narrow
现在我们有一组数据,并且数据之间是有关联关系的。
我们需要从数据中选出合适的内容,来进行数据集划分。
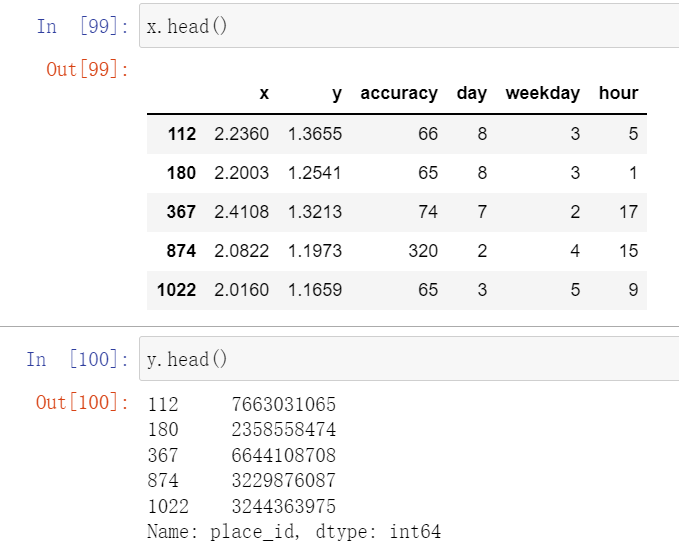
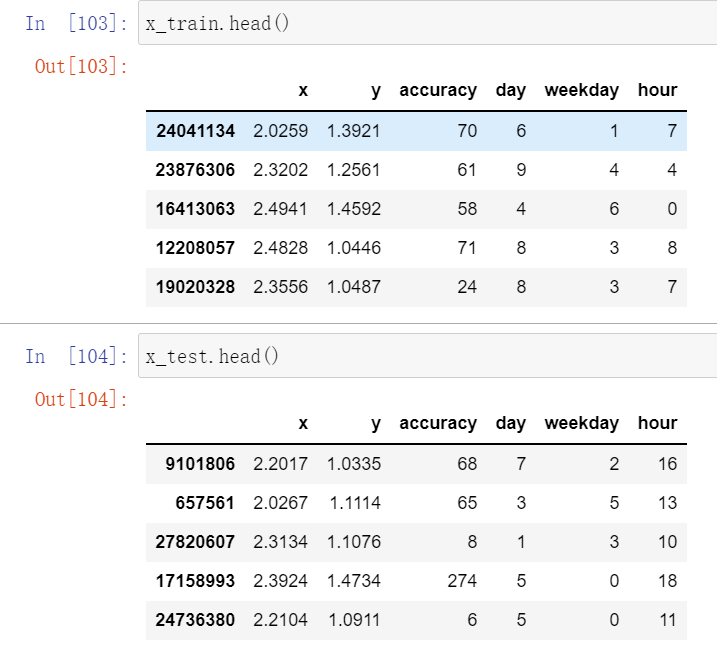
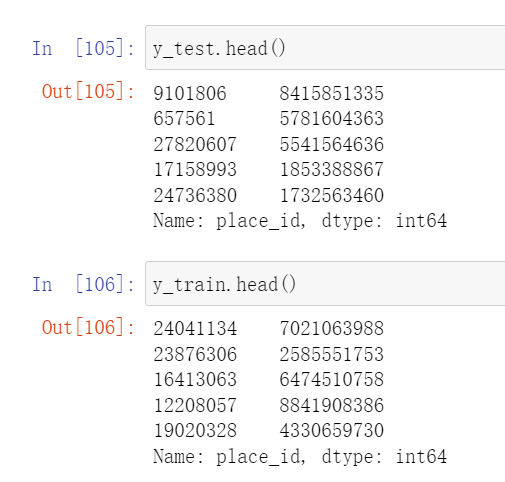
x = data_final[['x','y','accuracy','day','weekday','hour']] # 这一行选择的是数据的输入y = data_final['place_id']
6.训练集划分
从原始数据中切割出特征值和目标值之后,我们需要进行训练集和测试集的划分
from sklearn.model_selection import train_test_splitx_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
7 特征工程——数据预处理
我们需要对划分好训练集和测试集的数据,进行运算。
因为我们用的是KNN算法,所以我们之后应该要进行的是聚类运算,所以我们要对数据进行标准化去量纲化处理。
from sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassiferfrom sklearn.model_selection import GridSearchCVtransfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)
8 利用预处理好的数据进行模型训练
模型训练主要用的是estimator
estimator.fit
estimator.predict
estimator.score
estimator = KNeighborsClassfier()para_dict = {'n_neighbors':[1,3,5,7,9,11]}estimator = GridSearchCV(estimator,param_grid=para_dict)estimator.fit(x_train,y_train)y_predict = estimator(x_test)print("y_predict:\n",y_predict)print("直接比较预测结果:\n",y_predict == y_test)score = estimator.score(x_test,y_test)print("计算的准确率为:\n",score)
这样我们的模型就训练好了。
但是有个问题,最后训练出来的模型准确率很低。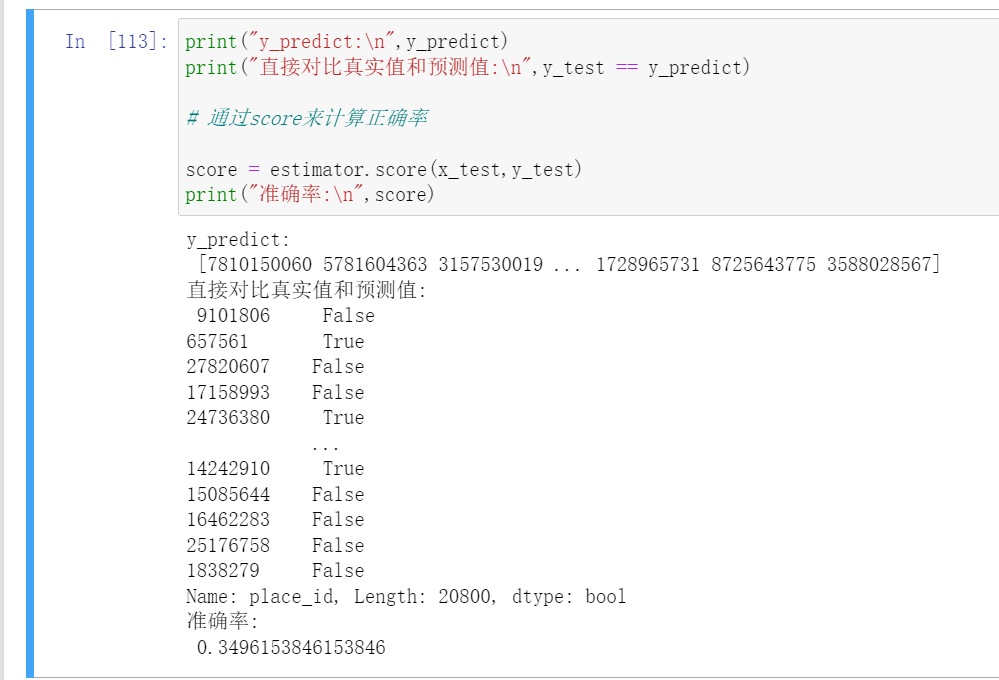
这说明了一个什么问题?
结论:
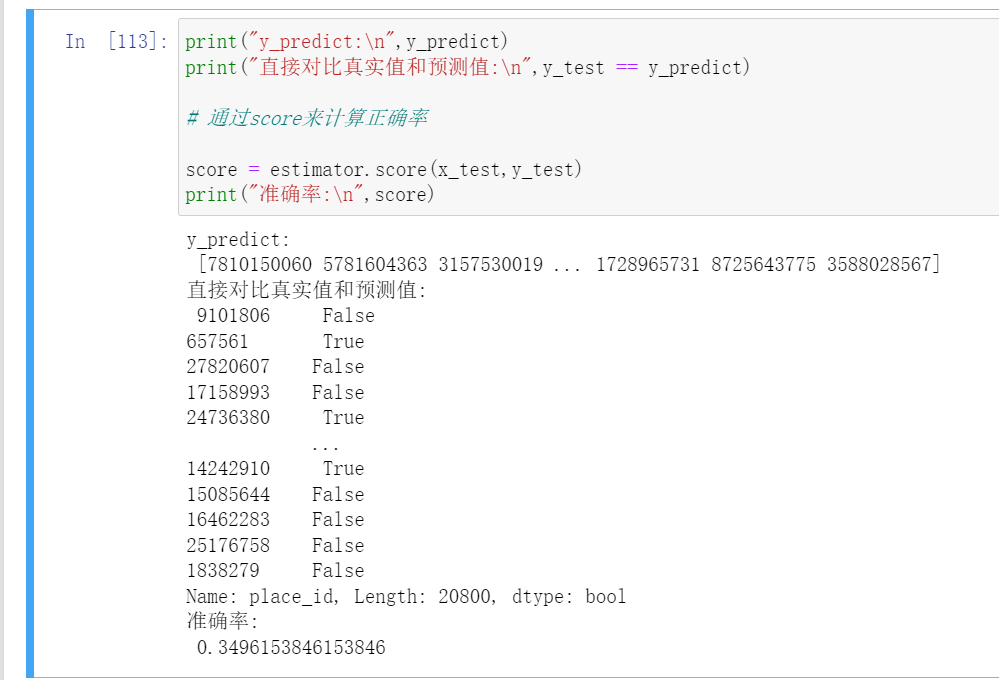
最后准确率低是正常的,不低才有鬼了。
我们的place_id是用数字来表示的,这里的数字id只是一个id是一个编号,其实是不具备实际的数学意义的,把place_id拿来加入计算是不合理的行为。

若有收获,就点个赞吧
0 人点赞
