https://blog.csdn.net/TracelessLe/article/details/106452469
Generative Adversarial Nets
Generative Aderverisal Network.pdf
【我只能说想出GAN的人真牛比】
什么是GAN
百度百科:生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
简而言之,就是,生成器和鉴别器互相博弈。
GAN由两个部分组成:
- 生成器 Generator,例如生成一张新的猫咪图片(不在数据集里)
- 判别器 Discriminator,例如给定一张图,判断这张图里的动物是猫还是狗
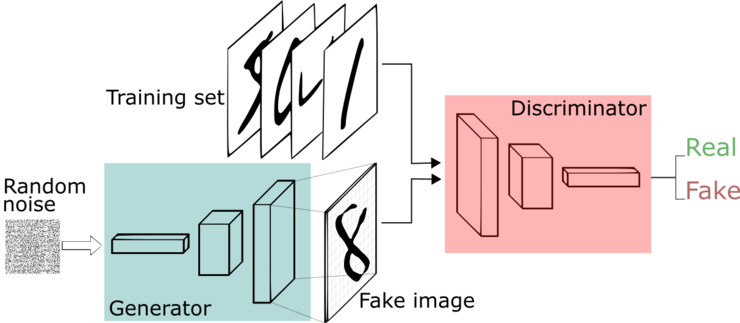
核心思想:
零和博弈,通过让生成器 Generator和判别器 Discriminator相互对抗,Generator试图生成接近真实的数据,Discriminator试图区分真实的数据和由Generator生成的数据。最终达到一个“平衡”,即Generator生成的数据足够真实,Discriminator只是是随机猜测,无法再区分真实数据与生成数据的区别。
GAN的原理
真实数据集的分布为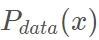 ,对于生成器Generator而言,它的目标是希望能够学习到真实样本的分布,这样就可以随机生成以假乱真的样本。
,对于生成器Generator而言,它的目标是希望能够学习到真实样本的分布,这样就可以随机生成以假乱真的样本。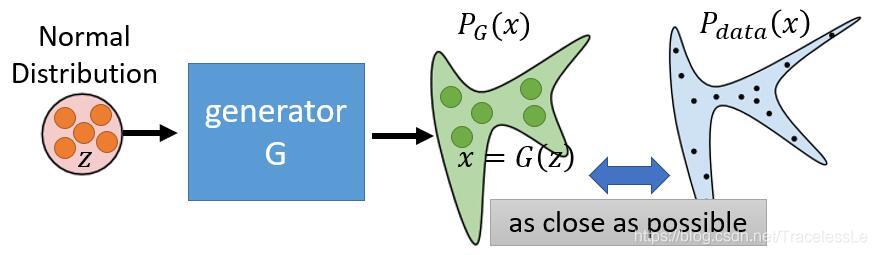
给定输入噪声 ,现有的 Generator 生成的数据分布假设为
,现有的 Generator 生成的数据分布假设为 ,这是一个由
,这是一个由 控制的分布,
控制的分布, 是这个分布的参数(如果是高斯混合模型,那么θ就是每个高斯分布的平均值和方差))。然后定义判别器
是这个分布的参数(如果是高斯混合模型,那么θ就是每个高斯分布的平均值和方差))。然后定义判别器 ,其中
,其中 表示,x来自
表示,x来自 而非
而非 的概率。
的概率。
我们的目标是训练判断器D以使其能最大可能地区分来自 和
和 的样本,同时训练生成器G以最小化
的样本,同时训练生成器G以最小化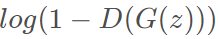 ,从而生成真假难辨的数据。
,从而生成真假难辨的数据。
这里就是GAN的核心——数学核心及思想上的核心,纳什均衡
D和G博弈的价值函数
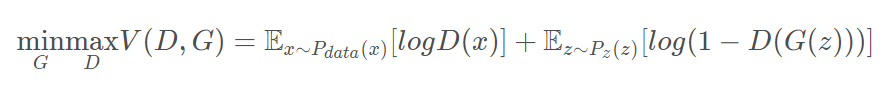
这里的价值函数是整个GAN的核心。
其中, 表示D判断真实数据是否是真实的概率,
表示D判断真实数据是否是真实的概率, 表示D判断G生成的数据是否是真实的概率。
表示D判断G生成的数据是否是真实的概率。
G希望 尽可能大,此时
尽可能大,此时 会变小,即
会变小,即
D希望 尽可能大,
尽可能大, 尽可能地小,此时
尽可能地小,此时 会变大,即
会变大,即
如何同时满足G和D的努力方向呢?只要把他们加起来就好了。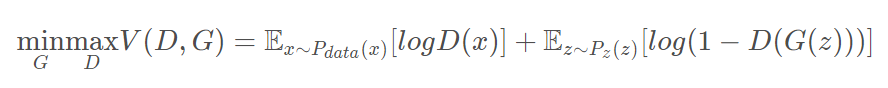
交替训练最终达到纳什平衡状态。
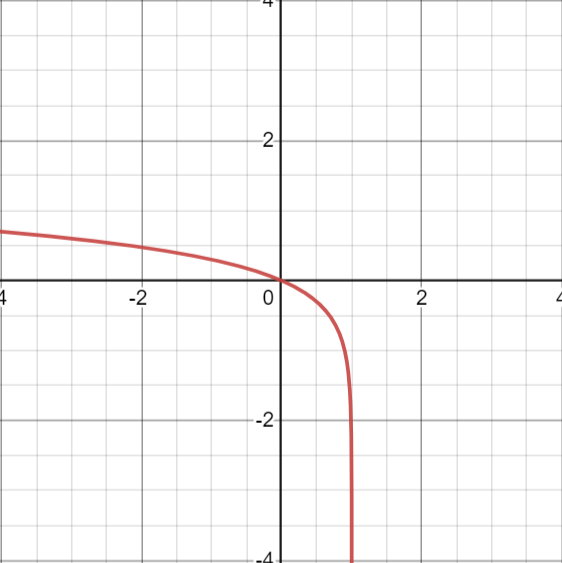 这是log(1-x)的图像。
这是log(1-x)的图像。

这里一个小题外话——纳什均衡是普遍的大趋势

若有收获,就点个赞吧
0 人点赞
