实验五 机器学习
背景:
自上世纪70年代以来,人脸识别已成为计算机视觉和生物识别技术研究的热点之一。基于手工特征的传统方法和传统的机器学习技术最近已经被用非常大的数据集训练的深度神经网络所取代。本文综述了当前流行的人脸识别方法,包括传统的(基于几何的、整体的、基于特征的和混合的)和深度学习方法。
人脸识别介绍:
范例:人脸识别
1.实验目的
(依据需求制定至少三条,包括实验完成目标和学生培养目标)
1.
2.实验原理(尽可能详细)
2.1 问题背景描述
人脸识别是指能够在图像或视频中识别或验证主体身份的技术。自从70年代第一个人脸识别算法被提出以来,人脸识别的准确性得到了提高,如今人脸识别往往比传统上被认为更健壮的其他生物识别方式(如指纹或虹膜识别[3])更受青睐。使人脸识别比其他生物识别方式更具吸引力的差异因素之一是其非侵入性。例如,指纹识别需要用户将手指放入传感器,虹膜识别需要用户明显靠近摄像头,扬声器识别需要用户大声说话。相比之下,现代的人脸识别系统只要求用户在摄像头的视野范围内(前提是他们与摄像头的距离在合理范围内)。这使得人脸识别成为用户最友好的生物识别方式。这也意味着人脸识别的潜在应用范围更广,因为它可以部署在用户不希望与系统合作的环境中,比如监控系统。人脸识别的其他常见应用包括访问控制、欺诈检测、身份验证和社交媒体。
由于人脸图像在现实世界中的高变异性(这些类型的人脸图像通常被称为野外人脸),在不受约束的环境中部署时,人脸识别是最具挑战性的生物识别方式之一。这些变化包括头部姿势、衰老、遮挡、光照条件和面部表情。
人脸识别技术已经发生了重大转变多年来。 传统方法依赖于手工制作的特征, 比如边缘和纹理描述符,结合机器学习技术,比如主成分分析, 线性判别分析或支持向量机。
对于在无约束环境中遇到的不同变化来说,工程特性的困难使研究人员专注于每一种变化类型的专门方法,例如年龄不变方法,姿态不变方法,光照不变方法,等。近年来,传统的人脸识别方法逐渐被基于卷积神经网络(cnn)的深度学习方法所取代。深度学习方法的主要优点是,它们可以用非常大的数据集进行训练,学习出代表数据的最佳特征。网络上的“公开数据集”的可用性使得我们能够收集包含真实世界变化的数据。使用这些数据集训练的基于cnn的人脸识别方法已经取得了非常高的精度,因为它们能够学习在训练过程中使用的人脸图像中存在的真实世界变化的健壮特征。
此外,计算机视觉深度学习方法的普及也加速了人脸识别的研究,cnn被用于解决许多其他的计算机视觉任务,如目标检测与识别、分割、光学字符识别、面部表情分析、年龄估计等。

人脸识别系统通常由以下部分组成:
1)人脸检测。人脸检测器查找人脸在图像中的位置,并(如果有的话)返回每个人脸的边界框的坐标。图3a对此进行了说明
2)人脸对齐。人脸对齐的目标是使用一组位于图像中固定位置的参考点,以相同的方式对人脸图像进行缩放和裁剪。这个过程通常需要使用地标探测器找到一组面部地标,在简单的2D对齐情况下,找到适合参考点的最佳仿射变换。图3b和3c显示了使用同一组参考点对齐的两张人脸图像。更复杂的3D对齐算法(例如:[16])也可以实现面部正面化,即改变面部的姿势到正面。
3) 人脸表征。在人脸表示阶段,将人脸图像的像素值转换为一个紧凑的、具有鉴别性的特征向量,也称为模板。理想情况下,同一主题的所有面孔应该映射到相似的特征向量。
4)人脸匹配。在人脸匹配构建模块中,将两个模板进行比较,产生一个相似度得分,表明它们属于同一主题的可能性。
人脸表征可以说是人脸识别系统中最重要的组成部分。
2.2 算法原理及分析(可添加适当的公式推理,必须确保准确无误)
3.实验内容
3.1 实验环境搭建
本次实验采用的是pycharm的python编辑平台,本次实验采用的包主要是sklearn的机器学习包和matplotlib数据显示包。
# import导入实验所用到的包import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import GridSearchCVfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import PCAfrom sklearn.svm import SVC
3.2 数据导入(包括预处理等,需给出具体实例和操作流程)
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]# Split into a training set and a test set using a stratified k fold# split into a training and testing set# 特征提取X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
lfw_people = fetch_lfw_people(min_faces_per_person=70,resize=0.4)
从fetch_lfw_people中加载人脸数据集。这里有关fetch_lfw_people的使用可以参考https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_lfw_people.html
3.3 实施算法
算法一:
Eigenface
Eigenfaces就是特征脸的意思,是一种从主成分分析(Principal Component Analysis,PCA)中导出的人脸识别和描述技术。特征脸方法的主要思路就是将输入的人脸图像看作一个个矩阵,通过在人脸空间中一组正交向量,并选择最重要的正交向量,作为“主成分”来描述原来的人脸空间。
1.特征脸训练与识别原理图
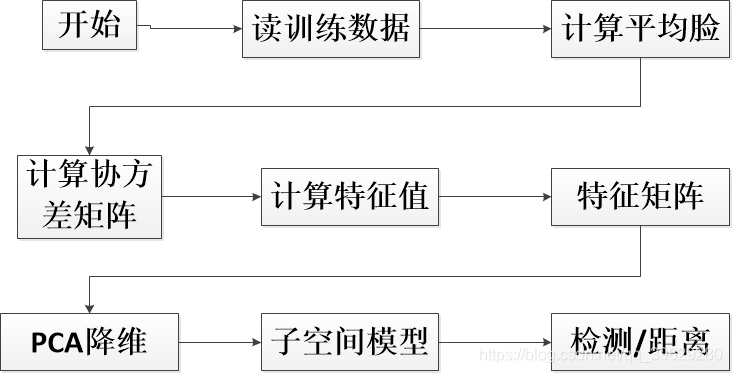
2.PCA主要过程
在很多应用中需要对大量数据进行分析计算并寻找其内在的规律,但是数据量巨大造成了问题分析的复杂性,因此我们需要一些合理的方法来减少分析的数据和变量同时尽量不破坏数据之间的关联性。于是这就有了主成分分析方法,PCA作用:
- 数据降维。减少变量个数;确保变量独立;提供一个合理的框架解释。
- 去除噪声,发现数据背后的固有模式。
PCA的主要过程:
- 特征中心化:将每一维的数据(矩阵A)都减去该维的均值,使得变换后(矩阵B)每一维均值为0;
- 计算变换后矩阵B的协方差矩阵C;
- 计算协方差矩阵C的特征值和特征向量;
选取大的特征值对应的特征向量作为”主成分”,并构成新的数据集
3.特征脸方法
特征脸方法就是将PCA方法应用到人脸识别中,将人脸图像看成是原始数据集,使用PCA方法对其进行处理和降维,得到“主成分”——即特征脸,然后每个人脸都可以用特征脸的组合进行表示。这种方法的核心思路是认为同一类事物必然存在相同特性(主成分),通过将同一目标(人脸图像)的特性寻在出来,就可以用来区分不同的事物了。人脸识别嘛,就是一个分类的问题,将不同的人脸区分开来。
特征脸方法的实现步骤:获取包含M张人脸图像的集合T。假设这里使用15张图片来作为人脸训练图像,每张图片的尺寸是100150,所以这里M=15。我们把导入的图像拉平,本来,100150的矩阵,拉平就是一个150001的矩阵,然后M张放在一个大矩阵下,该矩阵为1500015。
- 计算平均图像A,并获得偏差矩阵B,为15000*15平均图像也就是把每一行的15个元素平均计算,这样最后的平均图像就是一个我们所谓的大众脸。然后每张人脸都减去这个平均图像,最后得到:
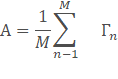
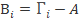
3.求得的方差矩阵。并计算的特征值和特征向量。这就是标准的PCA算法流程。很大的问题就是协方差矩阵的维度会大到无法计算,下面的方法可以解决:
设K是预处理图像的矩阵,每一列对应一个减去均值图像之后的图像。则协方差矩阵为S=K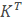
,并且对S的特征值分解 :
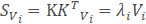
然而KKT是一个非常大的矩阵。因此,如果转而使用如下的特征值分解: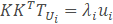
等式两边同时乘以K得到: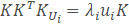
这就意味着,如果Ui是KKT的一个特征向量,则Vi=TUi是S的一个特征向量,反正到最后我们得KKT的一个特征向量,再用K与之相乘就是协方差矩阵的特征向量μ。而此时求得特征向量是1500015的矩阵,每一行(150001)如果变成图像大小矩阵(100150)的话,都可以看做是一个新人脸,被称为特征脸。
4.主成分分析。在求得的特征向量和特征值中,越大的特征值对于我们区分越重要,也就是主成分,只需要那些大的特征值对应的特征向量,而那些十分小甚至为0的特征值来说,对应的特征向量几乎没有意义。在这里通过一个阈值selecthr来控制,当排序后的特征值的一部分相加大于该阈值,选择这部分特征值对应的特征向量,此时剩下的矩阵15000M,M根据情况而变。这样不仅减少计算量,而且保留了主成分,减少了噪声的干扰。
5.人脸识别。此时导入一个新的人脸,使用上面主成分分析后得到的特征向量μ,来求得一个每一个特征向量对于导入人脸的权重向量Ω
‘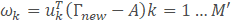
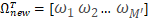
这里的A就是第二步求得的平均图像,特征向量其实就是训练集合的图像与均值图像在该方向上的偏差,通过未知人脸在特征向量的投影,我们就可以知道未知人脸与平均图像在不同方向上的差距。此时我们用上面第2步求得的偏差矩阵的每一行做这样的处理,每一行会得到一个权重向量。利用求得Ω和Ωk的欧式距离来判断未知人脸与第K张训练人脸之间的差距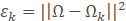
3.3.2 算法实例
3.3.2.1 基础实验实例(当前实验涉及子实验的相关原理实践)
# import导入实验所用到的包import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import GridSearchCVfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import PCAfrom sklearn.svm import SVC# 下载人脸数据lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]# Split into a training set and a test set using a stratified k fold# split into a training and testing set# 特征提取X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled# dataset): unsupervised feature extraction / dimensionality reductionn_components = 150pca = PCA(n_components=n_components, svd_solver='randomized',whiten=True).fit(X_train)eigenfaces = pca.components_.reshape((n_components, h, w))X_train_pca = pca.transform(X_train)X_test_pca = pca.transform(X_test)# Train a SVM classification model# 建立SVM分类模型param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)clf = clf.fit(X_train_pca, y_train)print("Best estimator found by grid search:")print(clf.best_estimator_)# Quantitative evaluation of the model quality on the test set# 模型评估y_pred = clf.predict(X_test_pca)print(classification_report(y_test, y_pred, target_names=target_names))print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
3.3.2.2 进阶实验实例(依据实验目的完成全部实验)
# import导入实验所用到的包import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import GridSearchCVfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import PCAfrom sklearn.svm import SVC# 下载人脸数据lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]# Split into a training set and a test set using a stratified k fold# split into a training and testing set# 特征提取X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled# dataset): unsupervised feature extraction / dimensionality reductionn_components = 150pca = PCA(n_components=n_components, svd_solver='randomized',whiten=True).fit(X_train)eigenfaces = pca.components_.reshape((n_components, h, w))X_train_pca = pca.transform(X_train)X_test_pca = pca.transform(X_test)# Train a SVM classification model# 建立SVM分类模型param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)clf = clf.fit(X_train_pca, y_train)print("Best estimator found by grid search:")print(clf.best_estimator_)# Quantitative evaluation of the model quality on the test set# 模型评估y_pred = clf.predict(X_test_pca)print(classification_report(y_test, y_pred, target_names=target_names))print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))# Qualitative evaluation of the predictions using matplotlib# 预测结果可视化def plot_gallery(images, titles, h, w, n_row=3, n_col=4):"""Helper function to plot a gallery of portraits"""plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)plt.title(titles[i], size=12)plt.xticks(())plt.yticks(())# plot the result of the prediction on a portion of the test setdef title(y_pred, y_test, target_names, i):pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]return 'predicted: %s\ntrue: %s' % (pred_name, true_name)prediction_titles = [title(y_pred, y_test, target_names, i)for i in range(y_pred.shape[0])]plot_gallery(X_test, prediction_titles, h, w)# plot the gallery of the most significative eigenfaceseigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]plot_gallery(eigenfaces, eigenface_titles, h, w)plt.show()
3.3.3 实验结果分析
3.3.3.1 定量实验分析
3.3.3.2 定性实验分析
特征脸分析
https://blog.csdn.net/qq_39629280/article/details/109456478
https://blog.csdn.net/lanyuelvyun/article/details/82384179——PCA分析
算法二:
3.3.1 算法流程
3.3.2 算法实例
3.3.2.1 基础实验实例(当前实验涉及子实验的相关原理实践)
3.3.2.2 进阶实验实例(依据实验目的完成全部实验)
3.3.3 实验结果分析
3.3.3.1定量实验分析
定性实验分析
3.4 对比分析
4.总结
4.1 阐述实验过程,
4.2理解实验原理
4.3分析实验问题
4.4 达到实验目的
5.思考

若有收获,就点个赞吧
0 人点赞
