- 带团队后的日常(一)
- 带团队后的日常(二)
- 带团队后的日常(三)
一、日常问题
1)BUG反馈
参与制订业务方的BUG规范,业务方最近投诉我们技术部,在飞书群中提出BUG后,技术部没有人响应,认为我们的态度太冷漠。
后面我就提出任何看到的人,只要知道是谁负责的,就@那个人,大家都不要客气,这是第一步。
第二步就是业务方建条BUG单,方便之后的追踪和回溯,当然,如果条件不允许或者不会建,那就让测试组的人创建单子。
后面其他人补充了第三步,那就是测试组的人会检查这条单子是否重复,若重复就直接关闭。
我感觉这个流程中有个瓶颈,那就是测试组的人需要关注着BUG单,需要损耗一点他们组的人力。2)量化效率
经常会收到各类Web需求的优化,改完测试完后就上线,一套流水线,我们只是其中的一环。
虽然我们知道这是用来提升他们效率的,但是无法直接量化提升的效率,这是我最近在思考的问题。
量化后,就能知道自己为他们的工作带来的多大的价值,其实也可以提升我们的工作积极性和参与度。
经过验证后,发现可以通过之前搭建的监控系统的通信和点击日志,来一步步地计算出耗时,而通过优化前后的两个耗时,就能得出效率值。
当然,并不是所有的效率提升都能计算出来,还有很多需要业务方的反馈才能得到。3)协调人
当需要多端联合解决问题时,如果没有协调人从中穿针引线,强力push的话,那么问题解决将会异常缓慢、效率低下。当无人主动承担时,可由自己担任。
这两天客服反馈用户充值后,虚拟币没有到账,于是查看后台发现是很多是未支付状态,联系财务进入第三方支付后台,导出已支付订单。
将两边导出的数据做Excel比对,筛选出了50多张有问题的订单。发现订单在特定的时间段内(0点~6点之间)出现了问题,根据之前画的一张问题画像大致可以推断出是第三库的问题。
于是在日志中搜索他们要回调的接口,发现在那段时间里一条都没有。马上再去联系那边的商务,将问题抛给他们。
这里必须得吐槽下他们的工作效率实在太低,12点50分反馈,一直到17点才说是总部系统问题,期间还得打电话给他们催促。
那只能我们自救了,联系客服咨询补单流程,再去查看补单以及审核的代码。并且查看回调接口的逻辑,以免二次补发。
一切就绪后,和财务一起整理补单需要的数据,再联系当时的运营(他也充值了没收到虚拟币),测试一条,一切正常后,再让客服和财务处理剩余的问题订单。
这样来来回回,也搞了大概一天的时间。4)控制需求
控制需求并不是为了逃避责任,恰恰是为了更好地尽责,好钢用在刀刃上。
最近接到一个需求,是在隐私条款更新后,要在APP中弹个框告诉用户。那么这里就会涉及三端:客户端、服务端和前端。业务方希望能在后台开放一个可视化页面供他们操作,服务端希望由我们提供数据的写入,他们直接读取(我们组有操控数据库的权限)。客户端通过读取服务端的接口来做相应地提示。
理想情况下是做一张为此功能服务的新页面,但情况并不理想。需要控制下需求,功能要做,但实现方式需要商量,而且要给出明确的解释。
- 衡量后认为做新页面的性价比太低,不仅功能太单一,而且还要做两套(服务两个APP)。在目前的管理后台中有很多这样服务某个功能而已经废弃的页面,其实完全可以先预判一下,值不值得做或者有什么更合适的替代方案。
- 目前的人力资源捉襟见肘,优先级很高的需求正在进行中,若做新页面,时间成本我们无法负担。
- 那些页面被废弃除了公司的客观原因之外,还有人为原因,新来的运营都不知道有这些功能,久而久之就用其他方式替代了,他们的交接有严重的问题。
- 在后台为了应付这类动态配置,开发了一套通用配置系统,可以在此处配置参数,这是一段JSON格式的数据,对运营并不友好。因为更新不会频繁,所以若要更新数据,可由测试、产品或我们组的人代劳。
- 服务端若不想读取我们的数据库,则可以提供内部接口,帮他们读取。亦或者他们自己读库,缓存起来。
由通用配置来实现该需求是一个折中的方案,既能维持我们自己的开发进度,也不会影响产品的发版。综合考量后,决定采取此方案,当然在实际使用中还会碰到些问题,这些都好解决。
在项目的开发中会碰到很多这样的场景,而且我相信基本上开发时间人力资源都会很紧张。为了让自己不被动,需要想办法控制住需求,控制的方式有多种,例如提前未雨绸缪实现可复用的技术方案和系统,分析出需求存在的矛盾点引导产品顺着自己的思路走,让出现冲突的业务方自己PK先做胜的那方需求。
5)沟通细节
在跨组联调之前一定要沟通好细节,不能粗粗的一过。要细到数据库表的一个字段都没有歧义,否则很容易会在阴沟里翻船。
之前要做一个加密音频的功能,客户端播放加密的音频文件,服务端将这些文件下发给客户端,后台管理系统将原始音频上传到加密平台。
在一开始的会议时讨论的方案是从我们这边拿到加密后的文件地址,然后再更新数据库表的一个新字段,服务端读取此字段,最后下发给客户端。
但是中途他们的实现方案发生了改变,没有通知到我这边(信息不对称),导致在发生联调时数据不匹配。
我在中途也想当然的以为更新加密地址就行,没有对清楚需求。好在,服务端需要的数据在我的代码中已经读取到,只要换个参数就能完成联调。不过下次真的是要好好捋一捋了。
经过这次事件后,团队协作规范中也要补充一条确认细节,以免再次发生这类失误。
二、工作优化
1)Node服务升级
Node服务升级失败,本来想从 v8升级到 v10,但出现一个时区问题,无法解决,只得回退,本来打算用代理转发的方式,后来想想这样太绕了,没必要。
于是新建一个项目,分配独立域名,运用TS语言,依托框架 egg.js,它的优势包括:
- 基于KOA,定制上层框架的能力。
- 按照约定进行开发,奉行『约定优于配置』,团队协作成本低。
- 稳定,功能完善,文档齐全,适合多种场景。
- 支持TypeScript,提供了应用层开发规范,有了强类型约束和静态检查,可以降低软件腐化的速度。
- 支持代码的声明索引,不用再通过项目搜索来查找变量或方法的声明处了。
- 让成员使用新技术新语法的,开辟新的成长空间,并与当前主流接轨。
具体迁移步骤包括:
- 引入JWT(egg-jwt),自定义JWT验证中间件。
- MySQL,MongoDB,Redis的连接和配置,引入egg专用插件,egg-sequelize,egg-mongoose和egg-redis。
- 日志的配置,包括自定义的请求日志,数据库查询语句日志(包括MySQL和MongoDB),内部请求通信日志。
- 将config目录中的文件全部上传到配置服务器中,保留 config.default.ts、config.{env}.ts和plugin.ts文件。
- 在服务器中部署时需要先将TS文件编译成JS文件,再执行start命令,并且传递环境参数。
- 当sequelize版本6以上时,要求MySQL最低版本得是5.7,但目前线上的版本都是5.6,因此无法更改,得想办法将egg-sequelize降配。
在部署Node性能监控平台的时候也遇到了点麻烦,搜集不到监控数据,主要是运维配置的问题,前前后后搞了好几天。
2)问题画像图
将问题和技术点通过一张图联系起来,可快速而有序地定位到问题的出处。
统计每周遇到的BUG,浏览公司的BUG单平台,再将BUG抽象成问题画像图,按照“问题 —> 平台 —> 技术点”的方式梳理。
Web端的很多业务都是各类短期活动,并非阶段性的,因此在提炼的时候比较难以抽象共性,很多问题不具代表性。
下图是经过整理后的问题画像图。
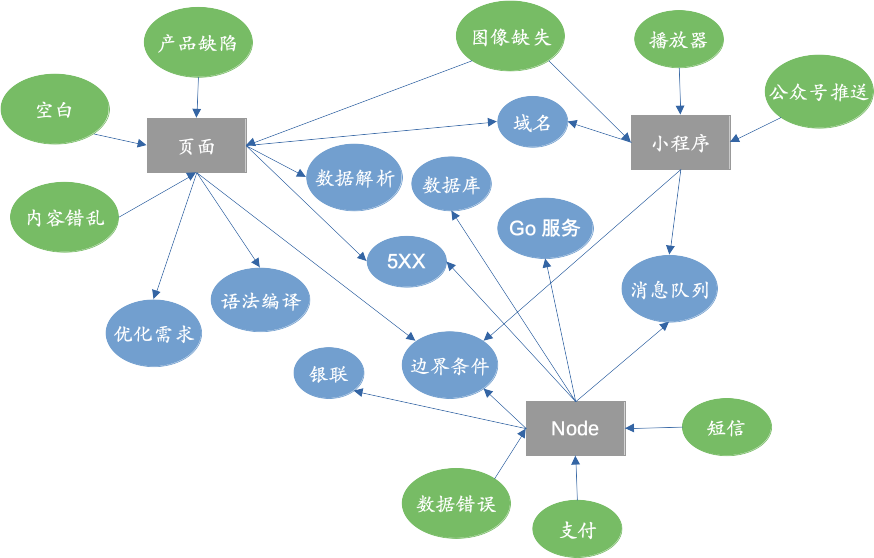
例如遇到页面空白,那有可能是JSON.parse()数据解析遇到了问题,也可能是语法编译后浏览器不支持,亦或者是接口504了得不到渲染数据等等。
最后推荐一款开源的办公软件:LibreOffice,支持PPT、Word、Draw,本次的图就是用该软件制作的,它也支持各个平台,包括mac、windows和linux。3)疑难杂症
为每个项目增加疑难杂症的wiki,记录花费了很多时间修复或常见问题的排查过程。
目的是在下次遇到时,不用再重头开始,减少修复时间,提升工作效率。既能间接地补充文档,也能梳理旧逻辑。
像之前的那些充值问题,就可以记录在案,下次遇到类似问题,都可以此为参考。
在休息时间,线上遇到BUG,若找不到相关人员或相关人员不方便操作电脑,那么就能让其他人员按照记录的排查步骤,一步步地修复,尽量做到一个问题可多人修复。4)前后端分离
这是我进公司后一直在推进的一件事,但是得不到服务端的支持,所以一直搁置着。最近遇到个站内信发送的问题,才将此问题又提上了日程。
目前服务端与我们组分工的职责界线很模糊,很容易发生冲突,所以我才一直致力于前后端分离。
我们组维护着一个比较庞大的管理后台,它连接的数据库多达8个,但其中只有一个MySQL和MongoDB才是我们组维护的,其他都是与业务相关的数据库。
我的设想是除了自己维护的系统之外,其他逻辑都应通过调用接口的方式与后端交互(包括增删改查),我们组需要与服务端的数据库表以及缓存做隔离。
前端监控系统,开发者工具,后台账户管理等是我们组的自有系统,仍然由我们来维护。
讨论后的方案:未来管理后台数据请求直接走服务端接口,服务端提供一个新的跨域域名。
- 保留管理后台的鉴权和权限功能,在登录时将用户的权限传输给服务端。
- 服务端的鉴权和权限验证与当前保持一致。
- 日志保存在MongoDB中,需将其与服务端隔离,开放操作日志接口,供服务端调用,统一日志格式。
H5活动会走一个Node.js提供的中间层服务,通过它再调用服务端接口。
主流的前后端分离是前端只做页面交互,数据处理全由服务端提供接口,目前在我们公司有很多现实问题使得难以这么搞。
折中的方案是我们自己维护Node中间层,业务数据从服务端读取。但如果是一个大活动,会有很大并发量的,那么就不走中间层,全部读取服务端接口。
讨论后的方案:
- 未来还是要走分离线路,但目前服务端对活动这块还是空白,需要有个搭建过程。
- 先从几个小活动开始,尝试着分离,稳步前进。
5)单元测试
在公司的几个项目中,其实早就将单元测试的环境搭建完成,但一直没有启用。
不做的理由一大堆,诸如:接口就是简单的增删改查,让测试组做功能测试就行了;工期太紧,来不及做;异步通信需要有后台接口等。
后面读了篇专栏才了解到,单元测试是不需要依赖外部服务的,也就是说不需要连接数据库,调用内部接口、读取本地文件等。
借助单元测试框架库(例如sinon.js),能够模拟出那部分外部服务,从而就能完成各个功能的单元测试。
结合当前项目的实际情况,我并不要求组内成员覆盖率达到一个数字,只需要对那些比较核心和复杂的业务逻辑加上单元测试即可。
我在使用时,会修改源码,让源码更容易测试,以函数或方法作为一个单元,在测试的过程中,发现了些潜在的问题,并当场修复,省得测试的时候出现而返工。6)Code Review
虽然每周都会开个周会,但Code Review还从未做过,根本原因还是因为没有认识到Code Review的价值。
最近有个比较重要的年中活动,所以在提测之前先做了简单的Code Review。
在这个过程中纠正了一些影响思路和视觉的写法,例如 if 的一个判断分支要一百多行,另一个分支就两行,那可以将短的分支移到上面加个 return,长分支转移到后面即可。
还找到了几个联调错误,避免在测试阶段才发现,造成不必要的返工,影响测试进度。7)B计划
软件的风险管理是必须要考虑的,在项目的开发阶段,就要提前考虑线上出现状况时的B计划,未雨绸缪,防患于未来。
例如定时任务中会计算榜单,当计算出现错误时,该如何快速恢复榜单数据?补救措施是提前备好脚本,在后台管理系统中留执行该脚本的入口。
还例如会员充值从银联支付替换为微信公众号支付,在试运行期间需要保留一个可以在两者之间切换的开关,当出现问题时,可快速应对。

若有收获,就点个赞吧
0 人点赞
