Redis基础篇
1.redis快速入门
redis也是一种数据库,但是不同于mysql数据库,mysql是关系型数据库,redis是非关系型数据库(不仅仅是数据库)。Nosql相对于mysql可以处理可以很好地处理用户的大量数据。
Nosql(No only sql)数据库是一种全新的数据库。Nosql中数据库以键值对(key-value)形式存储数据,和传统的关系型数据库不一样,不一定遵循传统的关系型数据库的一些基本要求。比如不遵循SQL查询标准,事务和表结构等。
Nosql主要有以下特点:非关系型的,分布式的,开源的和水平扩展的。
目前为止已经出现很多的Nosql型数据库:Redis,memcached,mongodb,Apache Cassandra,Apache CouchDB等。
2.SQL与Nosql的区别
| SQL | Nosql | 区别点 | |
|---|---|---|---|
| 数据结构 | 结构化 | 非结构化 | SQL语句有不同的类型结构,string/int/char/primarykey NoSQL有键值类型(redis),文档类型(mongodb),列类型(Hbase)等 |
| 数据关联 | 关联的 | 无关联的 | SQL中的可以创建关联表,数据不同重复设置,但是删除就很麻烦 Nosql中只需要用Json嵌套,没关联,但是重复。 |
| 查询方式 | SQL查询 | 非SQL | SQL数据库的查询语法相差并不多 Nosql中的查询语句不遵循sql格式,每个Nosql数据库查询语法不一样 |
| 事务特性 | ACID | BASE | |
| 存储方式 | 磁盘 | 内存 | SQL数据库的数据都是存储在磁盘中 Nosql数据库的数据存储在内存中,查询速度快! |
| 扩展性 | 垂直 | 水平 | SQL数据库想要提升速度和存储,只能提升硬件(主从只是备份) Nosql具有高可扩展性 |
| 使用场景 | 1.数据结构固定 2.相关业务对数据安全性,一致性较高 |
1.数据结构不固定 2.对一致性,安全性要求不高 3.对性能要求高 |
3.认识redis
Remote Dictionary Server,远程词典服务器。根据词典找Value。
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性。只是对于网络IO方面是多线程。核心命令依然是单线程。
- 低延迟,速度快(基于内存,IO多路复用,良好的编码C语言编写)
- 支持数据持久化
- 支持主从集群,分片集群(将1T数据拆分到多块放在集群中)
- 支持多语言客户端
- QPS每秒查询率为100000+,不比memcache差!
4.安装Redis
一台Centos7即可!
安装编译工具
yum install gcc tcl -y #redis是C语言编写的,所以就需要C语言的编译工具
上传并安装
将文件上传到/usr/local/src 下
tar -zxf redis-6.2.6.tar.gz #解压文件cd redis-6.2.6 #进入文件夹编译安装make && make install#默认安装位置为/usr/local/src/redis-6.2.6
Bin目录文件说明
| 命令文件名称 | 作用 |
|---|---|
| redis-benchmark | Redis性能测试工具 |
| redis-check-aof | 文件修复工具 |
| redis-check-rdb | 文件修复工具 |
| redis-cli | Redis命令行客户端 |
| redis-sentinel | Redis集群管理工具 |
| redis-server | Redis服务进程命令 |
5.启动停止redis
默认启动
编译安装完,就已经给我们添加了bin文件,直接输入命令就好了
redis-server #虽然也能启动,但是这是前台启动,会占用前台无法连接。#redis-server 就是使用默认的配置文件启动
后台启动
因为要修改配置文件,所以我们可以先做个备份。
cp redis.conf redis.conf.bck #备份文件,记得进入正确的文件夹中。vim redis.conf# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0bind 0.0.0.0# 守护进程,修改为yes后即可后台运行daemonize yes# 密码,设置后访问Redis必须输入密码requirepass 123321redis-server redis.conf #此时启动就是后台启动
Redis的其它常见配置:
# 监听的端口port 6379# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录dir .# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15databases 1# 设置redis能够使用的最大内存maxmemory 512mb# 日志文件,默认为空,不记录日志,可以指定日志文件名logfile "redis.log"
停止服务
redis-cli shutdown# 利用redis-cli shutdown 命令,即可停止 Redis 服务,# 因为之前配置了密码,因此需要通过 -u 来指定密码redis-cli -u 123321 shutdown
6.配置开机自启
我们通过写配置文件来实现开机自启
vim /etc/systemd/system/redis.service #编写redis.service文件[Unit]Description=redis-serverAfter=network.target[Service]Type=forkingExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.confPrivateTmp=true[Install]WantedBy=multi-user.target
此时我们重载服务系统
systemctl daemon-reload
此时就可以用以下命令进行开关机/自启动了。
# 启动systemctl start redis# 停止systemctl stop redis# 重启systemctl restart redis# 查看状态systemctl status redis# 设置开机自启systemctl enable redis
6.redis客户端
redis有多种客户端,都可以对redis数据库进行操作。
命令行客户端
redis-cli [options] [commonds]
常见的选项:
| 选项 | 作用 |
|---|---|
| -h IP | 指定连接的redis节点 |
| -p 6379 | 指定redis的节点端口 |
| -a 密码 | 指定redis的访问密码 |
下面介绍三种进入模式
redis-cli -h 127.0.0.1 -p 6379 #连接本地redis#你会发现,之前设置了密码但是现在直接进入
虽然此时能够进入,但是几乎无法做任何事,可以理解为游客模式。
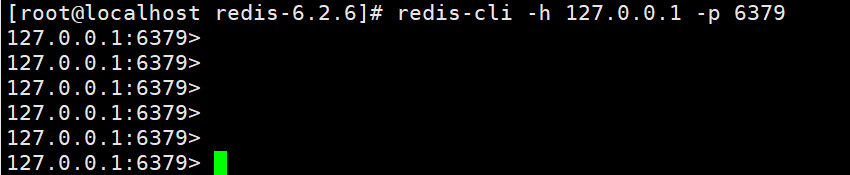
redis-cli -h 127.0.0.1 -p 6379 -a 123321 #直接使用密码#Ping就是心跳测试
redis-cli -h 127.0.0.1 -p 6379 #本地登录#此时还是游客模式AUTH 123321 #注意:这里让你输入-u 指定用户,我们没设置用户直接输入密码即可。

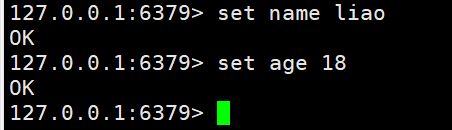
命令行操作
#创建两个键值对set name liaoset age 18#切换到其他数据表创建并查看键值
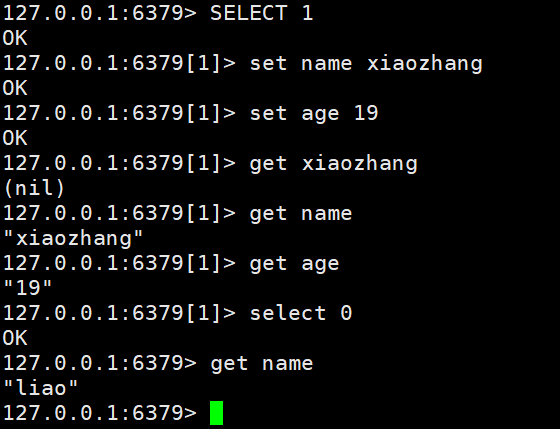
图形化界面客户端
Github上有个大佬,自己写了个图形化界面的客户端,不过需要自己编译。
https://github.com/uglide/RedisDesktopManager
但是也有免费版的,名字叫RDM:
https://github.com/lework/RedisDesktopManager-Windows/releases
我这边已经安装好了
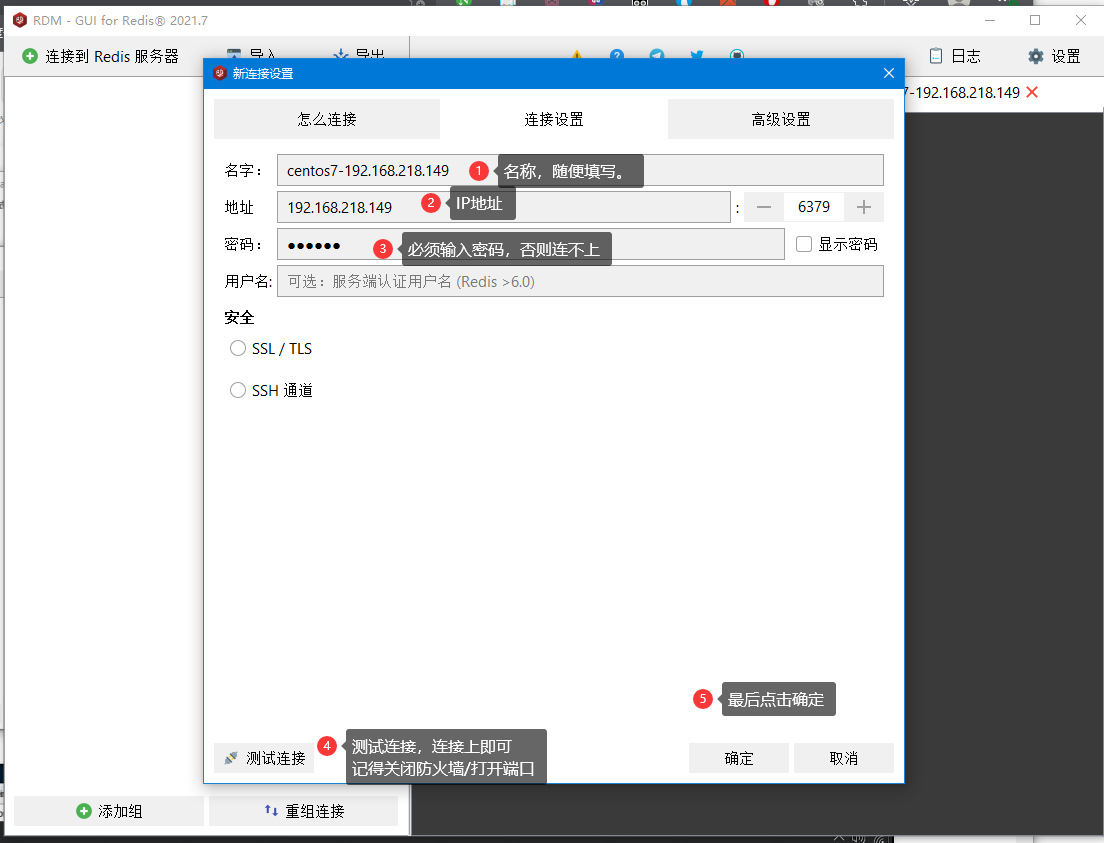
添加服务器
添加成功界面
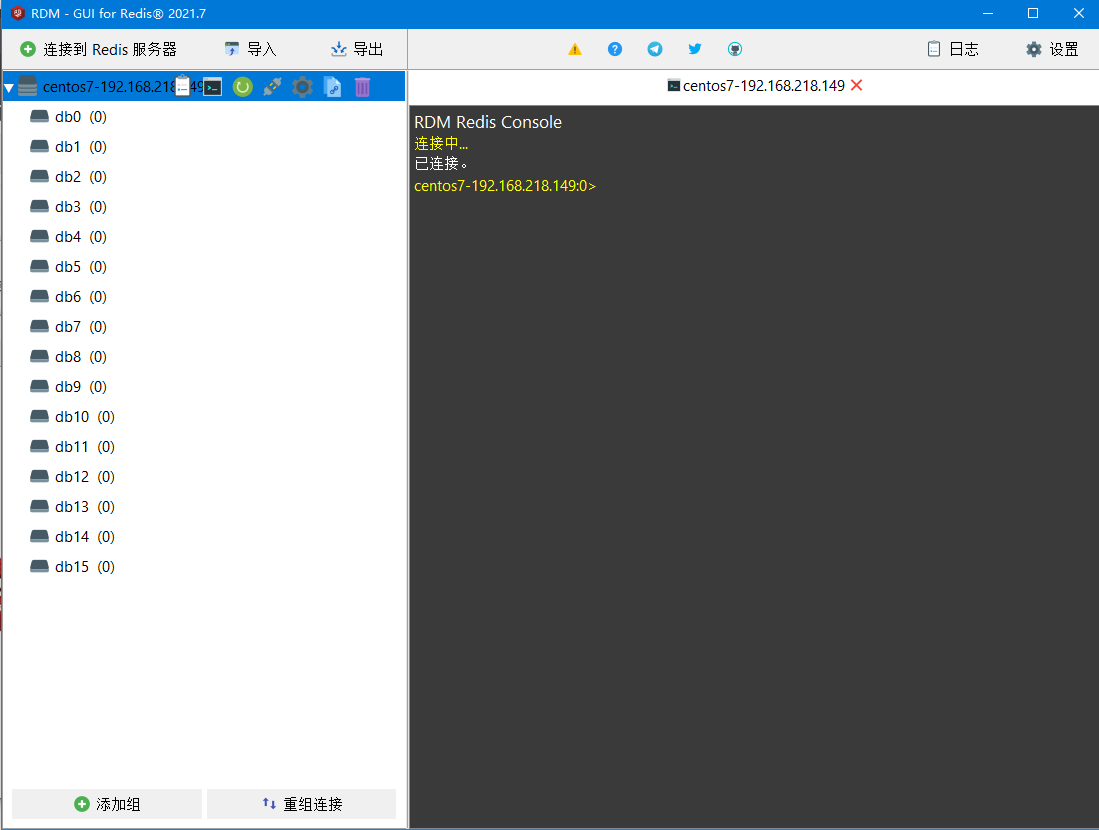
前面创建的三个键值对

7.Redis的默认端口为什么是6379
6379在是手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字。
Alessia Merz(redis) 是一位意大利舞女、女演员。 Redis 作者 Antirez 早年看电视节目,觉得 Merz 在节目中的一些话愚蠢可笑,Antirez 喜欢造“梗”用于平时和朋友们交流,于是造了一个词 “MERZ”,形容愚蠢,与 “stupid” 含义相同。MERZ长期以来被Redis作者antirez及其朋友当作愚蠢的代名词。
Redis常见命令
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样:
| 类型 | 案例 |
|---|---|
| String | hello world |
| Hash | {name:”liao”,age:21} |
| List | [A -> B -> C -> D] |
| Set | {A,B,C} |
| SortedSet | {A:1,B:2,C:3} |
| GEO | {A:(120.3,30.5)} |
| Bitmap | 01010100100101 |
| Hyperlog | 01001010100101001 |
在redis官网,有命令文档。上面写了全部命令的详细使用方法。或者通过redis来查看也行,但是不如官网文档详细。
官方文档:官方文档-英文
Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
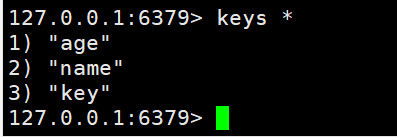
- KEYS:找到与给定模式匹配的所有键,查看符合模板的所有key
KEYS * #查找所有键值KEYS a* #查找以a开头的键值
**注意:尽量不要在生产服务器上轻易用 KEYS 。因为数据多,容易卡,并且Redis是单线程的。最多可以在从节点使用该命令
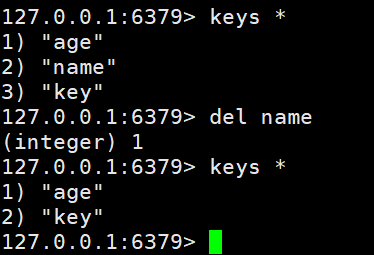
- DEL:删除key
DEL name #删除name(integer) 1 #返回值,代表删除的数量KEYS * #查看是否删除
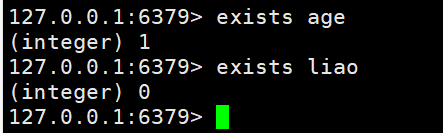
- EXISTS:检查key是否存在
EXISTS age #判断age是否存在(integer) 0 #就代表不存在
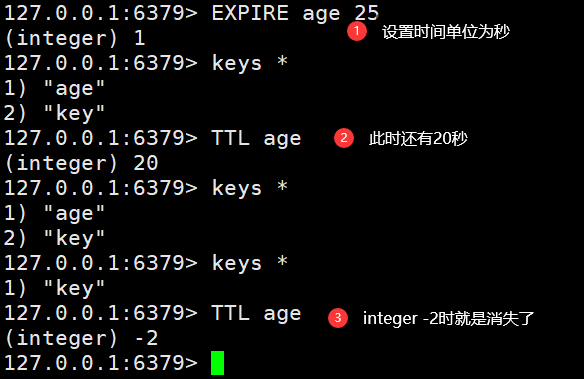
- EXPISE:给KEY设置有效期,到期会被自动删除
- TTL:查看KEY的有效期
EXPISE age 20 #给age设置20秒后删除TTL age #查看age还有多少时间
- 为何使用时间有效期:因为redis中的数据存储在内存中,数据多会导致卡顿。并且一些数据确实不需要长期在线,比如短信验证码。
- integet 10:该命令还有10秒
- integet -1:该数据没设置时间
- integet -2:该数据不存在
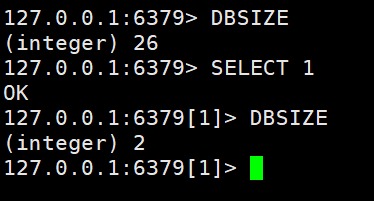
- DBSIZE:查看当前数据库中key的数目
DBSIZE #查看当前数据库key的数目,默认会查看第一个数据库
- MONITOR:实时输出redis服务器接收到的命令,可供调试使用
#在第一个窗口中输入:MONITOR#在第二个窗口中输入:SET name1 liao123#会出现以下显示:

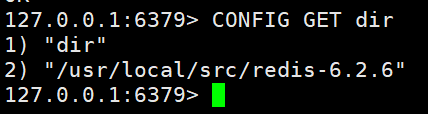
- CONFIG GET:获取redis的服务器信息
- CONFIG SET:获取redis的服务器信息
- CONFIG rewrite:将做的修改写入到配置文件中
CONFIG GET dirCONFIG SET requirepass "1233321" #修改密码变量,临时设置密码
- FLUSHDB:删除当前选择的数据库中的所有的key
- FLUSHALL:删除所有的数据库中所有的key
String类型
字符串类型,是Redis中最简单的存储类型
其value是字符串,不过根据字符串的格式不同分为以下三类:
- String:普通字符串
- int:整数类型,做自增自减
- float:浮点型,做自增自减 | Key | Value | | —- | —- | | msg | hello world | | num | 10 | | score | 92.5 |
不管是那种类型,底层都是字节数组存储形式,只不过是编码方式不同。字符串类型最大空间不能超过521MB。
常见命令:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
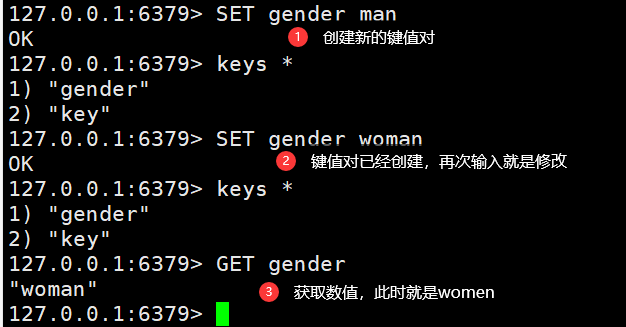
SET gender man #创建新的键值对GET gender #获取数值SET gender woman #修改键值对数值SET B1 wuhu EX 10 #创建新键值对,设置时间为10秒
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
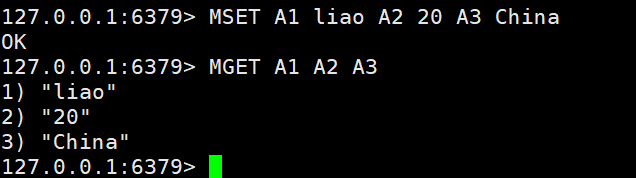
MSET A1 liao A2 20 A3 China #添加多个键值对MGET A1 A2 A3 #获取多个value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长
- INCRBYFLOAT:让一个浮点型的key自增并指定步长
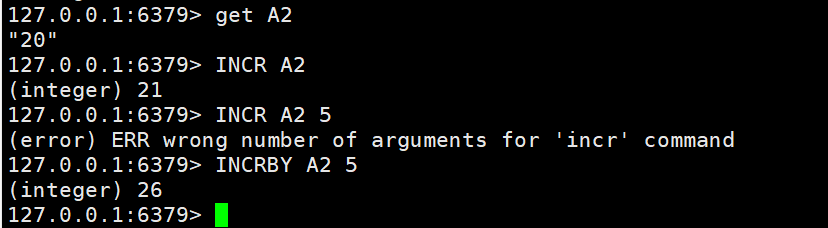
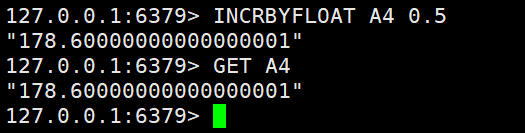
INCR A2 #A2参数自增1(integer) 21INCRBY A2 5 #A2参数自增5(integer) 25INCRBYFLOAT A4 0.5#INCRBY中数值改为负数,就是自减了哦!
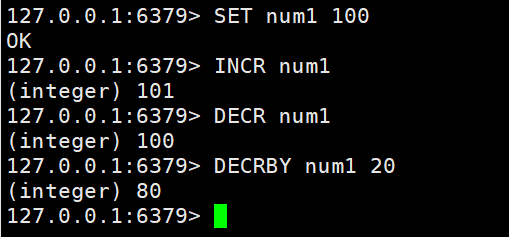
- DECR:指定一个整型的key自减1
- DECRBY:让一个整型的key自减并指定步长
DECR num1 #自减1DECRBY num1 20 #自减20
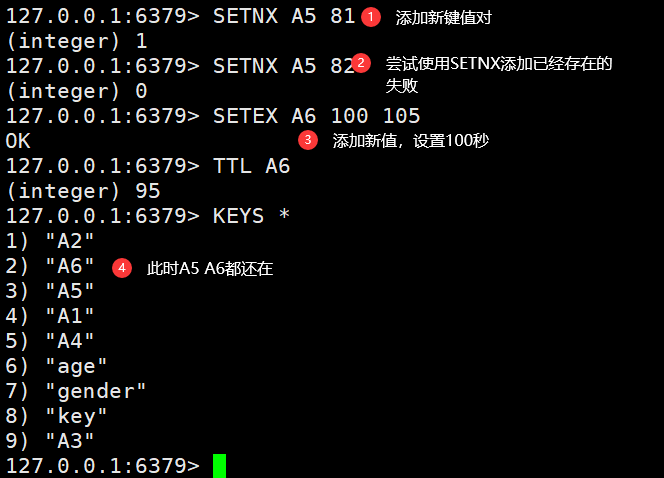
- SETNX:添加一个String类型的键值对,前提是key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
SETNX A5 81 #添加新键值对,成功SETNX A5 82 #添加新键值对,失败SETEX A6 100 105 #添加新值,设置时间为100
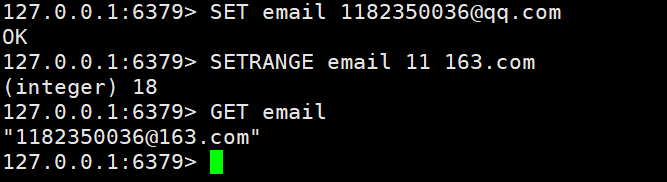
- SETRANGE:用value重写key所存储字符串值,从偏移量offset开始。不存在的当空白处理。
- GETRANGE:获取key中指定位置的字符串。如果是-1则是从末尾开始计数
SET email 1182350036@qq.comSETRANGE email 11 163.com"1182350036@163.com"GETRANGE email 0 9"1182350036"
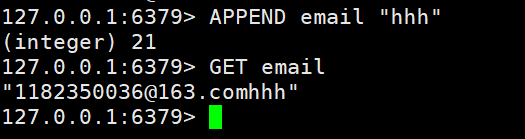
- APPEND key value:如果键值对存在,则是追加数值。如果键值对不存在,就是创建键值对
- STRLEN:返回所存储的字符串的长度
APPEND email "hhh"GET emailSTRLEN email(integer) 21
Key的层级格式
Redis中有没有类似Mysql中的table的概念?我们该如何区分不同类型的key呢?
例如:需要存储用户和商品信息,用户ID是1,商品ID是1,此时就冲突了,该如何解决
Key的结构
Redis的key允许有多个单词形成层级结构,多个单词之间用”.”隔开,格式如下:
项目名:业务名:类型:id
该格式当然非固定,可以根据需求来删除添加词条。
例如项目test中有两个不同类型的数据,我们可以这样定义key:
- test:name:1
- test:price:1
SET test:name:1 '{"id":1,"name":"liao,"age":18}'SET test:name:2 '{"id":2,"name":"xiaozhang,"age":20}'SET test:price:1 '{"id":1,"name":"redmi 10x,"price":1688}'SET test:price:2 '{"id":2,"name":"mac ook,"price":12666}'
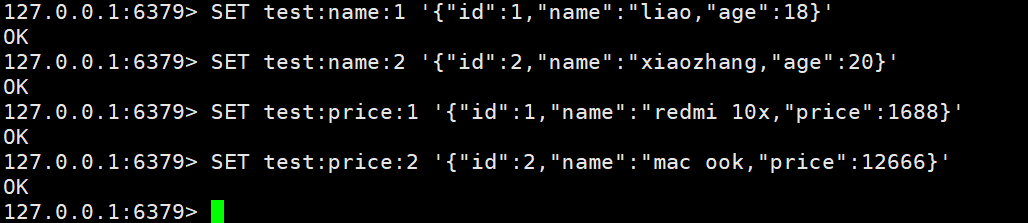
使用RDM连接服务器,这就很像JAVA。此时就实现了分级存储。
Hash类型
Hash类型也叫散列,其value是一个无序字典,类似Java中的Hashmap结构。
String结构是将对象序列化为json字符串后存储,当需要修改对象某个字段时很不方便
| Key | Value |
|---|---|
| liao:user:1 | {name:”java”,age:30} |
| liao:user:2 | {name:”python”,age:20} |
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRU。
| KEY | VALUE | |
|---|---|---|
| liao:user:1 | name | Java |
| age | 30 | |
| liao:user:2 | name | Python |
| age | 25 |
Hash类型的常见命令:
实际上大部分命令都是前面加了个H
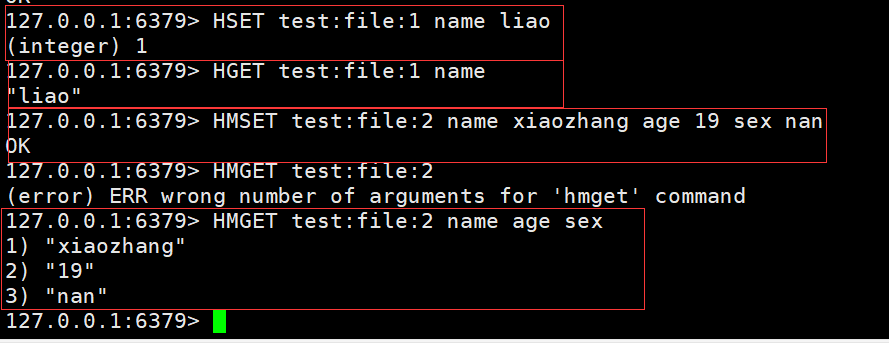
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field value:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型的key的filed的值
- HMGET:批量获取多个hash类型的key的filed的值
HSET test:file:1 name liaoHGET test:file:1 nameHMSET test:file:2 name xiaozhang age 19 sex nanHMGET test:file:2 name age sex
这是hash类型在RDM中的样式
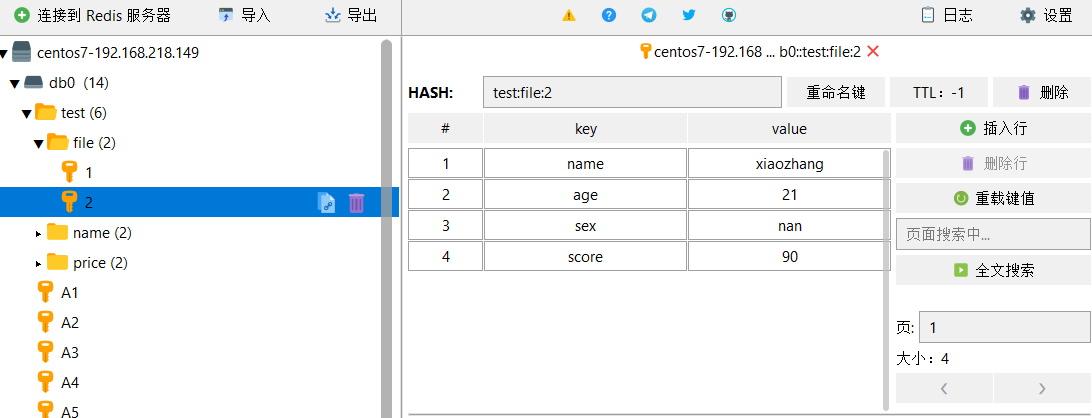
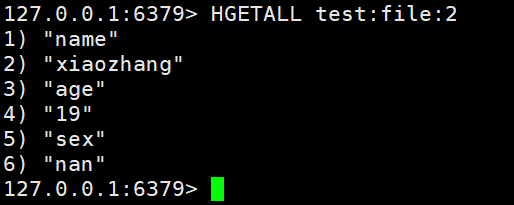
- HGETALL:获取一个HASH类型的key中所有的field和value
HGETALL test:file:2
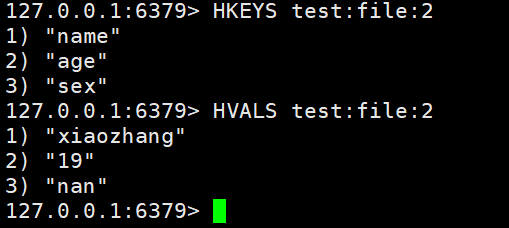
- HKEYS:获取一个hash类型的key中的filed
- HVALS:获取一个hash类型的key中的value
HKEYS test:file:2 #获取所有的keyHVALS test:file:2 #获取所有的value
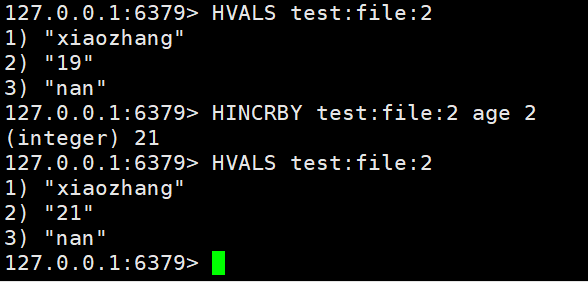
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field的值,前提是field不存在,否则不执行
HINCRBY test:file:2 age 2 #自增长2

- HLEN:返回散列表key中filed的数量
HLEN test:file:2

List类型
Redis中的list类型与java中的Linkedlist类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。

List常见命令有:
- LPUSH key element:向列表左侧插入一个或多个元素
- RPUSH key element:向列表右侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
LPUSHX和RPUSHX,只能插入,不能创建。
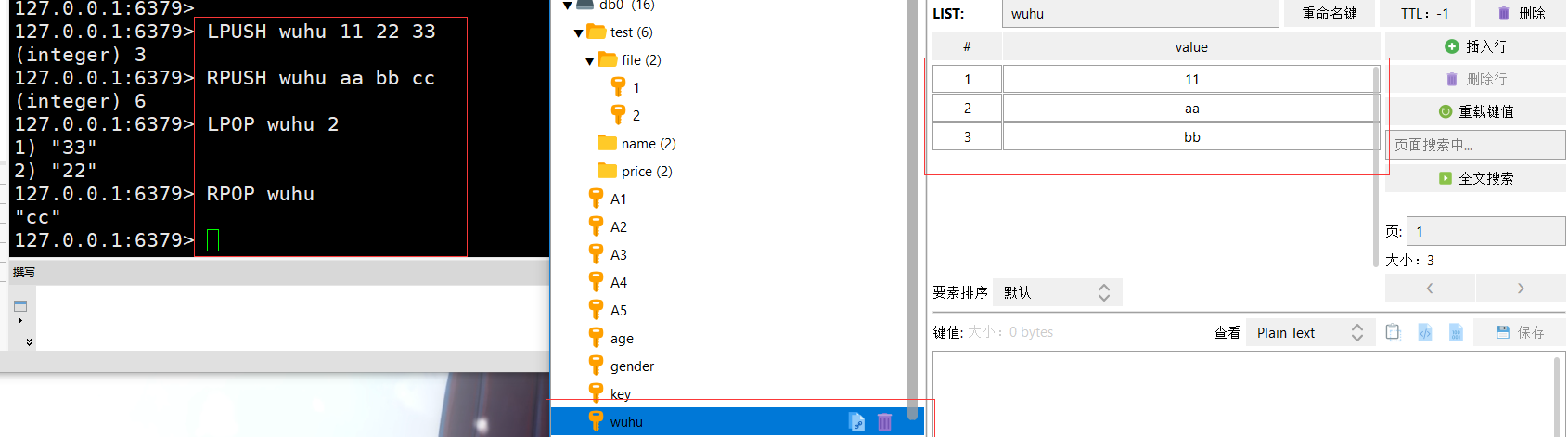
LPUSH wuhu 11 22 33 #在列表左侧添加数据RPUSH wuhu aa bb cc #在列表左右侧添加数据LPOP wuhu 2 #删除列表从左数两个数值RPOP wuhu #删除列表从右数一个数值
- LRANGE key start end:返回一段角标范围内的所有元素
- LLEN:返回列表key的长度
LRANGE是从0开始计算的,并且是从左往右(从上往下)。
LRANGE wuhu 0 2 #查询键值中从0到2的数值LRANGE wuhu 0 0 #查询键值中第1个数值LLEN wuhu #查询wuhu中key的长度,数值的数量(integer) 3
- BLPOP和BRPOP:与LPOP与RPOP类似,在没有元素时会进行等待,并且可以设置等待时间
#我再开一个窗口[窗口1] BLPOP wuhu2 100 #从左开始查询wuhu2,等待时间为100秒#此时wuhu2并没有建立,所以100秒后如果还没有命令就会失效[窗口2] LPUSH wuhu2 name liao #创建新的键值对,此时窗口1就执行成功

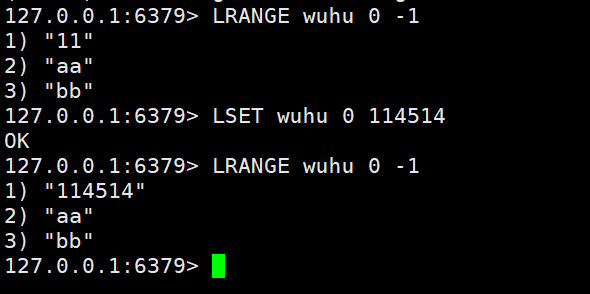
- LSET:设置key中指定索引的元素值,索引从0开始计算。
LRANGE wuhu 0 -11) "11"2) "aa"3) "bb"LSET wuhu 0 114514 #将第一个value改为114514
- LTRIM:保留让列表key保留指定区间内的元素
- LINDEX:返回指定列表中指定位置的元素
LTRIM wuhu 4 6 #保留指定区间LINDEX wuhu 1"aa"
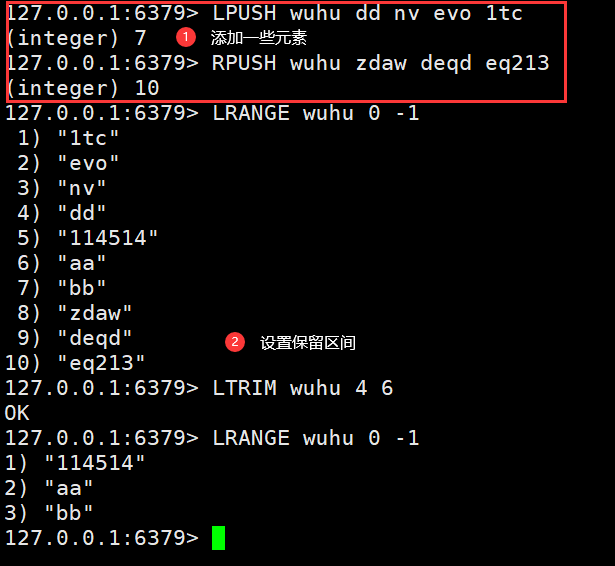
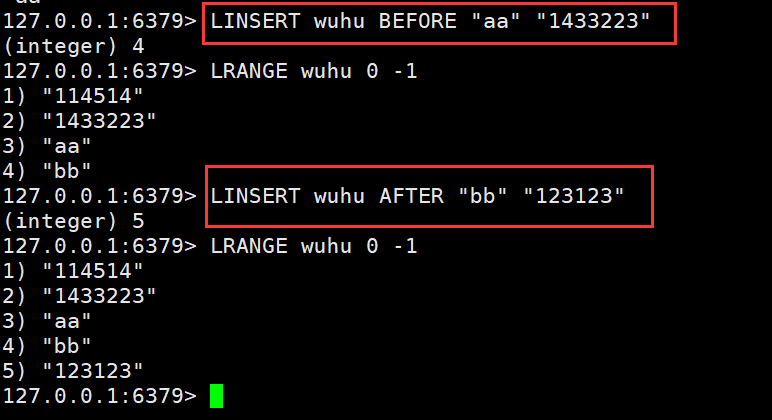
- LINSERT:将value插入到列表key中位于pivot之前或之后
LINSERT wuhu BEFORE "aa" "1433223" #插入数据到aa之前LINSERT wuhu AFTER "bb" "123123" #插入数据到bb之后
思考:
如何用List结构模拟一个栈?
- 入口和出口在同一边
- 入时用RPUSH,出时用RPOP
如何用List结构模拟一个队列?
- 入口和出口不在同一边
- 入时用LPUSH,出时用RPOP
如何用List结构模拟一个阻塞队列?
- 入口出口在不同边,有数值就取,没数值就等
- 出队时采用BLPOP或BRPOP
Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集,并集,差集等功能。
Set类型的常见命令
String的常见命令有:
- SADD key member…:向Set中添加一个或多个元素
- SREM key member..:移除Set中的指定元素
- SCARD key:返回Set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
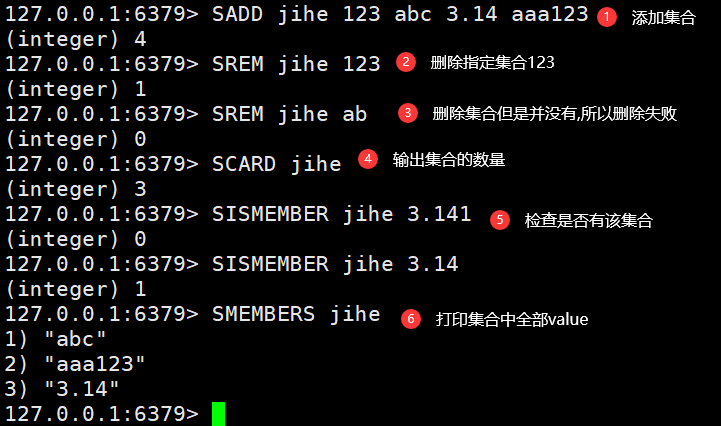
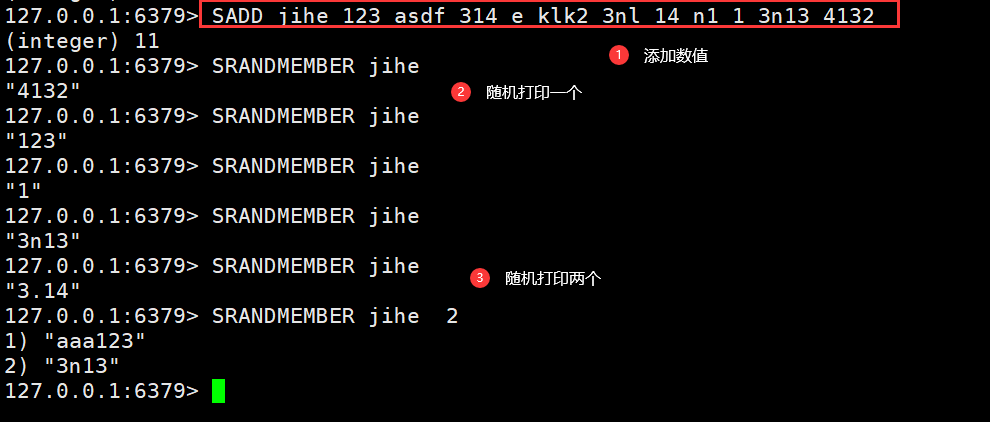
SADD jihe 123 abc 3.14 aaa123 #集合中添加元素SREM jihe 123 #删除元素SCARD jihe #返回元素中的个数SISMEMBER jihe 3.14 #查看该元素是否存在SMEMBERS jihe #打印全部的元素
- SMOVE srouce destination member:将一个集合的数值删除转移到另一个集合中。如果destination未创建,则创建一份,并加入该数值
SMOVE jihe jihe1 abc
- SRANDMEMBER KEY [COUNT]:从集合中返回指定数量随机元素
SRANDMEMBER jiheSRANDMEMBER jihe 2
- SINTER key1 key2…:求key1与key2的交集
- SDIFF key1 key2…:求key1与key2的差集
- SUNION key1 key2…:求key1与key2的并集
- 后面加上STORE,就是将交集/差集/并集保存到新的set集合中
- SINTERSTORE DESTINATION key key
案例练习
将下列数据用Redis的Set集合来存储:
- 张三好友有:李四,王五,赵六
- 李四好友有:王五、麻子、二狗

利用Set命令实现下列功能:
- 计算张三的好友有几人
SCARD zs(integer) 3
- 计算张三和李四有哪些共同好友
SINTER zs ls1) "wangwu"
- 查询哪些人是张三的好友却不是李四的好友
SDIFF zs ls1) "zhaoliu"2) "lisi"
- 查询张三和李四的好友总共有哪些人
SUNION zs ls1) "wangwu"2) "lisi"3) "zhaoliu"4) "mazi"5) "ergou"
- 判断李四是否是张三的好友
SISMEMBER ls zhangsan(integer) 0
- 判断张三是否是李四的好友
SISMEMBER zs lisi(integer) 1
- 将李四从张三的好友列表中移除
SREM zs lisi(integer) 1
SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sortedset,若存在则更新score值
- ZREM key member:删除sortedset中的一个指定元素
ZADD stu 100 liao 98 xiaozhang 85 zs 87 ls 90 wwu #添加数据(integer) 5ZADD stu 98 qy 89 aoge #添加数据(integer) 2ZREM stu aoge #删除数据(integer) 1
- ZSCORE key member:获取sortedset中的指定元素的score值
ZSCORE stu liao #获取分数"98"
- ZRANK key member:获取sotedset指定元素排名
- ZCARD key:获取sortedset中的元素个数
默认是升序排名哦!
ZRANK stu wwu #查看该元素的排行(integer) 2ZRANK stu zs(integer) 0ZCARD stu #获取元素个数(integer) 6
- ZCOUNT key min max:统计score值在给定范围内的所有元素个数
- ZINCRBY key increment member:让sortedset中的指定元素自增,步长为increment
- ZRANGE key min max:按照Score排序后,获取指定排名范围内的元素
- ZRANGEBYSOCRE key min max:按照score排序后,获取指定score范围内的元素
ZCOUNT stu 85 90 #查看score为85到90的个数(integer) 3ZINCRBY stu 2 zs #让zs的score涨两个"87"ZRANGE stu 1 3 #查看排名为1到3的元素1) "zs"2) "wwu"3) "qy"ZRANGEBYSCORE stu 85 95 #查看85到95范围内的元素1) "ls"2) "zs"3) "wwu"
- ZREMRANGEBYRANK:删除指定有序集合中的指定区间内的所有元素
- ZREMRANGEBYSCORE:删除指定有序集合中的指定score区间内的所有元素
- ZDIFF/ZUNION/ZINTER:求差集,求并集,求交集
案例练习
将班级的下列学生得分存入Redis的SortedSet中:
Jack 85,Lucy 89,Rose 82,Tom 95, Jerry 78, Amy 92, Miles 76
ZADD stu1 85 jack 89 lucy 82 rose 78 jerry 95 tom 92 amy 76 miles(integer) 7
- 删除Tom同学
ZREM stu1 tom(integer) 1
- 获取Amy同学的分数
ZSCORE stu1 amy"92"
- 获取Rose同学的排名
ZREVRANK stu1 rose #因为是升序,所以这里要用降序排行3
- 查询80分以下有几个学生
ZCOUNT stu1 0 80(integer) 2
- 给Amy同学加2分
ZINCRBY stu1 2 amy"94"
- 查出成绩前3名的同学
ZRANGE stu1 0 2 REV #因为默认是升序,使用REV变成降序1) "amy"2) "lucy"3) "jack"
- 查出成绩80分以下的所有同学
ZRANGEBYSCORE stu1 0 801) "miles"2) "jerry"
Redis新数据类型
Bitmaps
Bitmaps本身不是一种数据结构,实际上它就是字符串 ,但是它可以对字符串的位进行操作。
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。
可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。操作二进制位进行记录,就只有0和1两个状态
位存储,位图
例如:全中国有14人,为了统计疫情感染,我们创建一个字符为14亿个0。当有人感染我们就将他对应的0变为1。
统计用户信息,今日是否有人登录,登录了为1,没登录为0。
- SETBIT:创建bitmap数据
- GETBIT:获取指定位置的数据
- BITCOUNT:统计范围内有多少数据,默认整个key
统计一周打卡情况
#创建一周打卡情况SETBIT 2022:sign:liao 0 0(integer) 0SETBIT 2022:sign:liao 1 1(integer) 0SETBIT 2022:sign:liao 2 1(integer) 0SETBIT 2022:sign:liao 3 0(integer) 0SETBIT 2022:sign:liao 4 0(integer) 0SETBIT 2022:sign:liao 5 1(integer) 0SETBIT 2022:sign:liao 6 1(integer) 0#查看某天是否打卡getbit 2022:sign:liao 3(integer) 0getbit 2022:sign:liao 6(integer) 1#统计打卡天数BITCOUNT 2022:sign:liao(integer) 4
Geospatial
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
Redis GEO 操作方法有:
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
#添加地理位置的坐标。geoadd henan 14.1231245 54.123345 "zhengzhou" 65.21357 76.3452 "kaifeng"(integer) 2geoadd beijing 54.7564 23.4363 "shijiazhuang" 65.8685 34.6456 "hebei"(integer) 2#获取地理位置的坐标。geopos henan zhengzhou kaifengGEOPOS beijing shijiazhuang hebei#计算两个位置之间的距离。GEODIST beijing shijiazhuang hebei m"1647422.6820"GEODIST henan zhengzhou kaifeng km"3230.1067"#以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。GEORADIUS henan 15 55 1000 km#转为哈希值GEOHASH beijing shijiazhuang hebei1) "thnvq42qkd0"2) "tqnv4g5cpr0"#根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。GEORADIUSBYMEMBER beijing hebei 10000 km1) "shijiazhuang"2) "hebei"
HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
简介
Hyperloglog,基数统计算法
优点:占用内存时固定的!2^64个数据只需要12kb内存。
缺点:有0.81%的错误率,在一些情况下可以忽略。
例如计算网页浏览量,一个人看一次是一次浏览,那一个人看多次在一些情况下不能算浏览量,此时基数统计算法就出现了。
传统解决方式:set集合,保存用户ID,使用set元素作为标准判断。
- 如果保存用户多就比较麻烦消耗资源多
命令:
PFADD mykey a b c d fdaf fdgdfgw jhtjtyu s #添加第一组基数类型(integer) 1PFCOUNT mykey #查看基数类型数量(integer) 8PFADD mykey2 c b a d s y #添加第二组基数类型(integer) 1PFCOUNT mykey2 #查看基数类型数量(integer) 6PFMERGE mykey3 mykey mykey2 #合并成新的基数OKPFCOUNT mykey2(integer) 6PFCOUNT mykey3 #此时并不是8+6 14个 而是去掉了重复的 成为了9个(integer) 9
Redis配置与信息
INFO数据信息 ★
# Serverredis_version:6.2.6 #redis服务器版本redis_git_sha1:00000000redis_git_dirty:0redis_build_id:776b78884361146fredis_mode:standaloneos:Linux 3.10.0-1160.53.1.el7.x86_64 x86_64 #内核版本arch_bits:64multiplexing_api:epoll #redis循环机制atomicvar_api:atomic-builtingcc_version:4.8.5process_id:9595process_supervised:norun_id:78792e27b03f0fcd3da03371c31c11494b565a70 #redis服务器随机值tcp_port:6379 #端口server_time_usec:1646794531907634uptime_in_seconds:129894 #正常运行时间uptime_in_days:1 #正常运行天数hz:10configured_hz:10lru_clock:2627363executable:/usr/local/src/redis-6.2.6/redis-server #可执行文件config_file:/usr/local/src/redis-6.2.6/redis.conf #遵循的配置文件io_threads_active:0 #IO线程活动# Clientsconnected_clients:5 #当前连接的客户端数cluster_connections:0 #集群连接数量maxclients:10000 #最大连接数client_recent_max_input_buffer:56 #客户端最新的最大输入缓冲区client_recent_max_output_buffer:0 #客户端最新的最大输出缓冲区blocked_clients:0 #被阻塞的客户端数tracking_clients:0 #跟踪客户端数clients_in_timeout_table:0 #超时的客户端# Memoryused_memory:961784 #使用的内存used_memory_human:939.24K #以更直观的单位显示分配的内存总量used_memory_rss:10280960 #系统给redis分配的内存used_memory_rss_human:9.80Mused_memory_peak:1019936 #内存使用峰值used_memory_peak_human:996.03Kused_memory_peak_perc:94.30% #使用内存达到峰值内存的百分比used_memory_overhead:914136 #Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlogused_memory_startup:810120 #Redis服务器启动时消耗的内存used_memory_dataset:47648 #数据占用的内存大小used_memory_dataset_perc:31.42% #数据占用的内存大小的百分比allocator_allocated:1023824 #分配器分配allocator_active:1343488 #分配器活跃allocator_resident:3710976total_system_memory:3953958912 #系统总内存total_system_memory_human:3.68Gused_memory_lua:37888 #LUA使用内存used_memory_lua_human:37.00Kused_memory_scripts:0 #使用的内存脚本used_memory_scripts_human:0Bnumber_of_cached_scripts:0 #缓存脚本的数量maxmemory:0 #最大内存maxmemory_human:0Bmaxmemory_policy:noeviction #最大内存策略allocator_frag_ratio:1.31 #分配器的碎片率/比例allocator_frag_bytes:319664 #分配器的碎片数量allocator_rss_ratio:2.76allocator_rss_bytes:2367488rss_overhead_ratio:2.77 #开销/使用比例rss_overhead_bytes:6569984mem_fragmentation_ratio:11.19 #扩容比例正常情况下稍大于1。低于1,Redis实例可能会把部分数据交换到硬盘上,内存交换会严重影响Redis的性能,所以应该增加可用物理内存。大于1.5表示碎片过多。额外碎片的产生是由于Redis释放了内存块,但内存分配器并没有返回内存给操作系统,这个内存分配器是在编译时指定的,可以是libc、jemalloc或者tcmalloc。mem_fragmentation_bytes:9361944mem_not_counted_for_evict:0mem_replication_backlog:0 #内存日志副本mem_clients_slaves:0 #内存客户端从节点mem_clients_normal:102576mem_aof_buffer:0 #缓冲区的内存mem_allocator:jemalloc-5.1.0 #内存分配器 Redis支持glibc’s malloc、jemalloc11、tcmalloc几种不同的内存分配器,每个分配器在内存分配和碎片上都有不同的实现。不建议普通管理员修改Redis默认内存分配器,因为这需要完全理解这几种内存分配器的差异,也要重新编译Redis。active_defrag_running:0 #正在运行的碎片整理lazyfree_pending_objects:0lazyfreed_objects:0# Persistenceloading:0 #服务器是否正在载入持久化文件current_cow_size:0current_cow_size_age:0current_fork_perc:0.00current_save_keys_processed:0current_save_keys_total:0rdb_changes_since_last_save:0 #从上次RDB保存以后更改的次数rdb_bgsave_in_progress:0 #服务器是否正在创建rdb文件rdb_last_save_time:1646794418 #离最近一次成功创建rdb文件的时间戳rdb_last_bgsave_status:ok #最近一次rdb持久化是否成功rdb_last_bgsave_time_sec:0 #最近一次成功生成rdb文件耗时秒数rdb_current_bgsave_time_sec:-1 #如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数rdb_last_cow_size:2498560aof_enabled:0 #是否开启了aofaof_rewrite_in_progress:0 #标识aof的rewrite操作是否在进行中aof_rewrite_scheduled:0 #rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewriteaof_last_rewrite_time_sec:-1 #最近一次aof rewrite耗费的时长aof_current_rewrite_time_sec:-1 #如果rewrite操作正在进行,则记录所使用的时间,单位秒aof_last_bgrewrite_status:ok #上次bgrewriteaof操作的状态aof_last_write_status:ok #上次aof写入状态aof_last_cow_size:0module_fork_in_progress:0module_fork_last_cow_size:0# Statstotal_connections_received:48 #新创建连接个数,如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置total_commands_processed:787 #redis处理的命令数instantaneous_ops_per_sec:0 #redis当前的qps,redis内部较实时的每秒执行的命令数total_net_input_bytes:23682 #redis网络入口流量字节数total_net_output_bytes:430158 #redis网络出口流量字节数instantaneous_input_kbps:0.00 #redis网络入口kpsinstantaneous_output_kbps:0.00 #redis网络出口kpsrejected_connections:0 #拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数sync_full:0 #主从完全同步成功次数sync_partial_ok:0 #主从部分同步成功次数sync_partial_err:0 #主从部分同步失败次数expired_keys:3 #运行以来过期的key的数量expired_stale_perc:0.00expired_time_cap_reached_count:0expire_cycle_cpu_milliseconds:806evicted_keys:0 #运行以来剔除(超过了maxmemory后)的key的数量keyspace_hits:296 #命中次数keyspace_misses:10 #没命中次数pubsub_channels:0 #当前使用中的频道数量pubsub_patterns:0 #当前使用的模式的数量latest_fork_usec:2266 #最近一次fork操作阻塞redis进程的耗时数,单位微秒total_forks:11migrate_cached_sockets:0 # Replication(主从信息,master上显示的信息)slave_expires_tracked_keys:0active_defrag_hits:0active_defrag_misses:0active_defrag_key_hits:0active_defrag_key_misses:0tracking_total_keys:0tracking_total_items:0tracking_total_prefixes:0unexpected_error_replies:0total_error_replies:27dump_payload_sanitizations:0total_reads_processed:749total_writes_processed:705io_threaded_reads_processed:0io_threaded_writes_processed:0# Replicationrole:masterconnected_slaves:0 #连接的slave实例个数master_failover_state:no-failovermaster_replid:3980da85e0713a5314ec560193db486344c438cemaster_replid2:0000000000000000000000000000000000000000master_repl_offset:0second_repl_offset:-1repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0# CPUused_cpu_sys:31.441830#将所有redis主进程在核心态所占用的CPU时求和累计起来used_cpu_user:36.362707#将所有redis主进程在用户态所占用的CPU时求和累计起来used_cpu_sys_children:0.083921#将后台进程在核心态所占用的CPU时求和累计起来used_cpu_user_children:0.004215#将后台进程在用户态所占用的CPU时求和累计起来used_cpu_sys_main_thread:31.137550used_cpu_user_main_thread:36.478927# Modules# Errorstatserrorstat_ERR:count=21errorstat_NOAUTH:count=4errorstat_WRONGTYPE:count=2# Clustercluster_enabled:0 #集群信息# Keyspacedb0:keys=26,expires=0,avg_ttl=0db1:keys=2,expires=0,avg_ttl=0
Redis.conf详解 ★
appendfsync evertsecbind 0.0.0.0 与 bind 127.0.0.1bind 127.0.0.1 #只能通过本地访问bind 0.0.0.0 #绑定服务器的所有网卡,可以从本地访问,也可以通过服务器其他网卡访问。protected-mode yes #开启保护模式,无法进行远程访问protected-mode no #关闭保护模式,可以进行远程访问#保护模式是指当没有设置密码的时候,只能通过本地访问,设了密码之后其他电脑也能访问。port 6379 #设置redis服务端口tcp-backlog 511 #tcp,通过三次握手建立连接,四次挥手释放连接。进行tcp握手挥手的总和的值。timeout 0 #设置可离开redis界面时间,默认0永不超时,单位为秒tcp-keepalive 300 #检测心跳,如果在指定秒内,没做任何操作则释放连接daemonize yes #开启后台启动pidfile /var/run/redis_6379.pid #在该文件中保存每次启动的进程号loglevel notice #日志级别debug #开发环境,显示全部信息verbose #有用的信息notice #生产环境中使用,只显示有用的和警告信息waring #只显示警告信息logfile "redis.log" #redis日志写入到该文件中databases 16 #设置默认reids的16个库always-show-logo no #始终显示标志set-proc-title yes #设置程序标题stop-writes-on-bgsave-error #持久化出错是否还要继续工作#然而,如果你已经设置了对Redis服务器的适当监控和持久性,你可能想禁用这个功能,这样Redis就会 继续像往常一样工作,即使磁盘出现了问题。权限等问题,Redis也能照常工作。requirepass 123321 #设置密码maxclients 10000 #设置最大连接数rdbcompression yes #对于存储到磁盘中的Redis快照,可以设置是否进行压缩存储,默认为yes。如果指定为yes,Redis会采用LZF压缩算法对存储到磁盘中的Rredis快照进行压缩。如果不想小号CPU来压缩快照,就指定为no关闭该选项,但是存储在磁盘上的快照会比较大rdbcompress yes #是否压缩rdb文件,需要消耗一些cpu资源rdbchecksum yes #保存rdb文件的时候,进行错误的检查校验dir ./ #rdb文件保存目录dbfilename "dump.rdb" #指定本地数据库存放目录slaveof <masterip> <masterport> #指定当前本机为Slave服务时,Mater服务器的ip地址及端口。在redis启动时,它会自动从Master服务器进行同步masterauth <password> #指定当master服务设置了密码保护时,slave服务连接master服务的密码maxmemory <bytes> #指定redis的最大内存限制,redis在启动时会把数据缓存到内中,达到最大内存后,redis会尝试清除已到期的key,redis新的vm(虚拟内存)机制会把key存放在内存,把value存放在swap区appendonly on #是否开启AOF 指定redis是否在每次执行更新操作后进行日志记录,在默认情况下redis是异步地把内存中的数据写入磁盘。如果不开启此项,可能会在主机断电的时候丢失一些数据.appendfilename appendonly.aof #指定AOF更新日志文件名appendfsync evertsec #指定更新日志的条件#no 表示等操作系统进行数据缓存后才同步到磁盘,速度快#always 每次执行更新操作后,需要手动调用fsync()将数据写到磁盘,特点是速度慢,比较安全#evertsec 每秒同步一次数据到磁盘,是上面两个选项的这种选项,也是默认的vm-enabled no #指定是否启动虚拟内存机制,默认值为novm-swap-file /tmp/redis.swap #指定虚拟内存文件路径,不可多个实例共享vm-max-memory 0 #指定将所有大于vm-max-memory的数据存入虚拟内存,默认值为0,无论vm-max-memory多小,所有索引数据都是内存存储,也就是说当vm-max-memory设置为0时,所有的value都是存储在磁盘vm-page-size 32 #redis的swap文件被分成了很多个page,一个对象可以保存再多个page上,page不能被多个对象共享vm-pages-134217728 #指定swap文件中page数量vm-max-threads 4 #指定访问swap文件的线程数,此选项值最好不要超过计算机的核心数。如果改为0哪位所有swap文件的操作都是串行的,此选项会造成较长时间的延迟glueoutputbuf yes #指定在向客户端响应时,是否把较小的包合并为一个包发送,默认值为yes
Redis高级
PHP中使用redis
yum install wget php php-devel zlib-devel gcc -y #安装所需工具cd /usr/local/src #进入src目录wget https://pecl.php.net/get/redis-4.0.1.tgz #获取redis包tar -zxf redis-4.0.1.tgz #解压redis包cd redis-4.0.1 #进入redis解压文件夹phpize #扩展库扫描./configure --with-php-config=/usr/bin/php-config #安装make && make install #编译安装

vim /usr/local/php.ini #增加extension=redis.so

php -m | grep redis #查看是否有redis模块

存储session
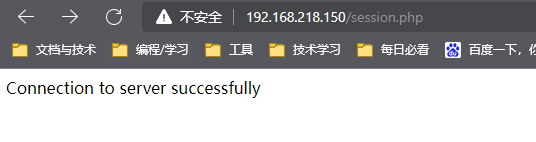
vim /etc/php.ini #进入php配置文件session.save_handler = "redis"session.save_path = "tcp://127.0.0.1:6379"vim /var/www/session.php #创建session.php文件<?php//连接本地的 Redis 服务$redis = new Redis();$redis->connect('127.0.0.1', 6379);echo "Connection to server successfully";//查看服务是否运行echo "Server is running: " . $redis->ping();?>php /var/www/html/session.php #启动session
当从网页中打开是如下显示,即连接成功。
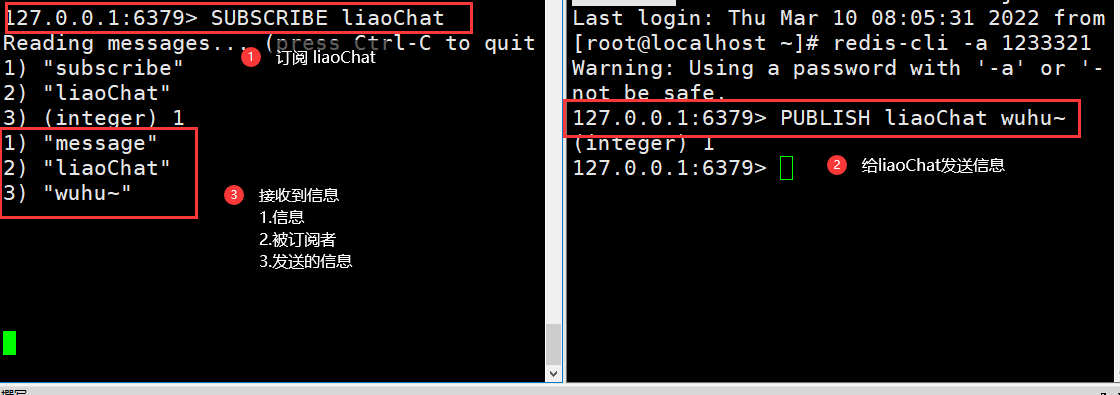
Redis发布与订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。Redis 客户端可以订阅任意数量的频道。
Client1——Client2——Client3 订阅 channel1
channel1 发送信息 Client1——Client2——Client3
开启两个窗口
窗口1:
SUBSCRIBE liaoChat
窗口2:
PUBLISH liaoChat wuhu~
Redis事务
原子性 隔离性 一致性 持久性
Redis中单挑命令保存原子性,但是事务不保存原子性
指事务的不可分割性,一个事务的所有操作要么不间断地全部被执行,要么一个也没有执行。
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务,无法被干扰。
- 命令入队列。
- 执行事务,按照命令依次执行。
开启MULTI事务,将多段代码输入,但是暂时不执行,输入EXEC命令才开始执行。
127.0.0.1:6379(TX)> MULTIOK127.0.0.1:6379(TX)> SET book-name "0-100 life"QUEUED127.0.0.1:6379(TX)> GET book-nameQUEUED127.0.0.1:6379(TX)> SADD tag "liao-write"QUEUED127.0.0.1:6379(TX)> SMEMBERS tagQUEUED#在EXEC执行前,输入查询命令都是无效的哦127.0.0.1:6379(TX)> EXEC1) OK2) "0-100 life"3) (integer) 14) 1) "liao-write"
编译型异常(代码有问题,命令有错!),事务中所有命令都不会执行

运行时异常 如果事务队列中存在语法性异常,那么执行命令的时候其他命令都是可以正常运行的。
Rredis乐观锁与悲观锁
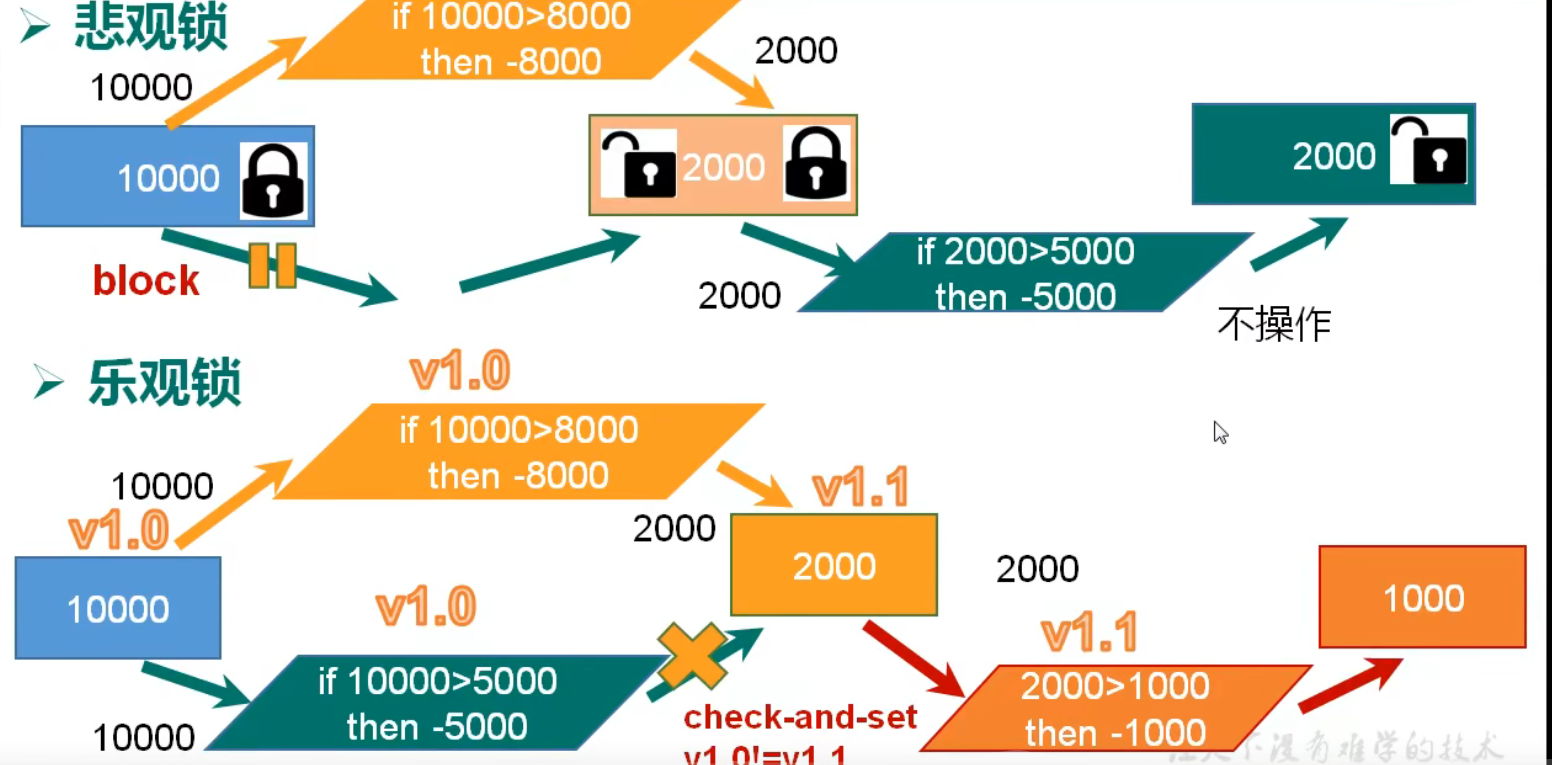
悲观锁
- 很悲观,认为什么时候都会出问题,无论做什么都会加锁
- 每次拿数据的时候都认为别人会修改,所以每次拿数据都会先上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里面就用到了很多这种锁机制,比如行锁,表锁,读锁,写锁等。都是操作之前先上锁。
- 缺点:效率低,无法多人进行
乐观锁
- 很乐观,认为什么时候都不会出问题,所以不会上锁。更新数据的时候去判断一下,在此期间是否有人修改过数据。获取version,更新时比较version
- 每次拿数据都认为别人都不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间会判断别人有没有更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的
Redis测监视测试(乐观锁)
正常执行
127.0.0.1:6379> set money 100OK127.0.0.1:6379> set out 0OK127.0.0.1:6379> watch money #监视money对象OK127.0.0.1:6379> multi #事务正常结束,数据期间没有发生变动OK127.0.0.1:6379(TX)> DECRBY money 20QUEUED127.0.0.1:6379(TX)> INCRBY out 20QUEUED127.0.0.1:6379(TX)> exec1) (integer) 802) (integer) 20
测试多线程修改值
#窗口1127.0.0.1:6379> watch money #监控moneyOK127.0.0.1:6379> MULTI #开启事务OK127.0.0.1:6379(TX)> DECRBY money 15 #修改moneyQUEUED127.0.0.1:6379(TX)> INCRBY out 15QUEUED#窗口2127.0.0.1:6379> set money 10000 #其他窗口修改了moneyOK#窗口1127.0.0.1:6379(TX)> get moneyQUEUED127.0.0.1:6379(TX)> exec #此时我们对于money的修改就失败了(nil)
事务三特性
- 单独的隔离操作
- 事务中的所有命令都会序列化,按照顺序执行。事务在执行的过程中,不会被其他客户端发来的命令请求所打断。
- 没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
- 不保证原子性
- 事务中如果有一条命令执行失败其后
Redis性能与测试
redis-benchmark
官方自带的压力测试工具

| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | —csv | 以 CSV 格式输出 | |
| 12 | *_-l(L 的小写字母)_ | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | *_-I(i 的大写字母)_ | Idle 模式。仅打开 N 个 idle 连接并等待。 |
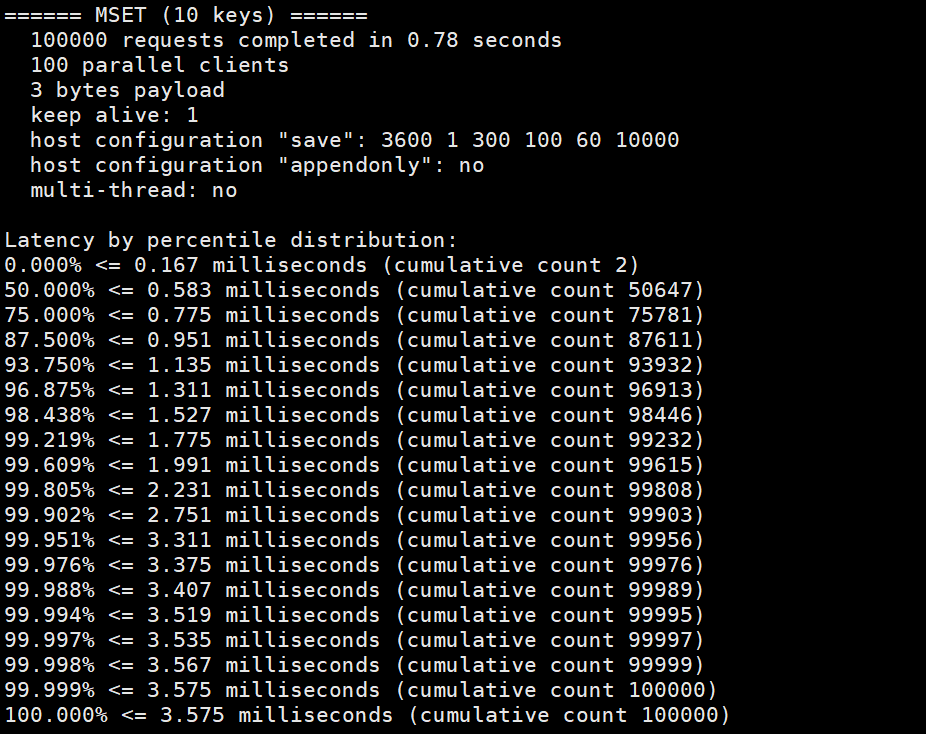
#提前开一个窗口并且连上redis服务器redis-cli -a 1233321#测试100个并发连接:100000 请求redis-benchmark -h 127.0.0.1 -p 6379 -a 1233321 -c 100 -n 100000#并且会创建一些数据在库中,记得删除
- 对我们10万个请求进行写入测试
- 100个并发客户端
- 每次写入3个字节
- 只有一台服务器来处理这些请求
Redis持久化
RDB(redis database)
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失,所以redis提供了持久化功能。
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
Redis会单独创建 ( fork )一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
在生产环境下,dump.rdb文件需要备份
dbfilename "dump.rdb" #设置rdb文件名称save 60 5 #只要60秒内修改了5次key 就出发rdb操作#此时创建5个key,就创建了dump.rdb文件
触发机制
自动触发
1.当满足save规则,自动触发rdb规则,生成dump.rdb
2.执行flushall也会触发rdb规则
3.退出redis,也是产生rdb
手动触发
1.直接输入save
- 该命令会阻塞当前redis服务器,执行save期间不能处理其他命令,直到RDB执行完成
2.直接输入bgsave ★
- redis会后台异步执行快照操作,同时还能响应客户端请求。具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
如何恢复rdb文件
1.只需要将rdb文件放在redis启动目录就可以,redis启动的时候会自动检查dump.rdb恢复其中的数据
2.查看dump.rdb存放位置
127.0.0.1:6379> config get dir1) "dir"2) "/usr/local/src/redis-6.2.6"
优点:
- 适合大规模数据恢复!dump.rdb 不要删除
- 对数据完整性要求不高
- 速度比较快
缺点:
- 需要一定的时间间隔进行持久化操作
- 意外宕机最后一次修改数据就没有了,无法实时持久化
- fork保存进程会占用一些空间
AOF(Append Only File)
将我们所有的命令记录下载,历史命令,恢复的时候将这个文件全部执行一遍
以日志的形式来记录每个写操作,将Redis执行过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
Aof保存文件时 appendonly.aof文件
AOF配置
appendonly yes #默认AOF是不开启的,需要手动开启appendfilename "appendonly.aof" #设置AOF名称appendfsync everysec #每秒同步一次数据到磁盘,是上面两个选项的这种选项,也是默认的no-appendfsync-on-rewrite no #是否重写auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb #当文件大于64m则重新新建一个文件,fork一个新的进程
set d1 1OKset d2 2OKset d3 3OKset d4 4OKset d5 5OKcat appendonly.aof #查看aof文件
aof修复
如果aof有错位,这时候redis是启动不起来的,我们需要修复这个aof文件
redis给我们提供一个工具 redis-check-aof --fix
优点:
- 每次修改都同步,完整性会非常好
- 默认每秒同步一次,可能会丢失一秒的数据
缺点:
- 相对于数据文件来说,aof远大于rdb,修复的速度
- AOF运行效率也要比rdb慢,所以redis默认配置就是rdb而不是aof。
扩展
1、RDB持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式
- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。
5、性能建议
- 因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。
- 如果Enable AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite的最后将 rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重写可以改到适当的数值。
Redis主从复制
主从复制
主从复制,是指将一台Redis服务器的数据,复制到具他的Redis服务器。前者称为主节点(master/leacer),后者称为从节点(slave/fallower);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。主从复制的作用主要包括:
- 数据冗余∶主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复∶当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡︰在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用集群︰除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的,原因如下
- 从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
- 从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G。
环境配置
准备两台redis服务器,mater和slave。(最常见的还是一主二从)
只配置从库,不用配置主库!默认情况下每台redis都是主节点。
>info replication# Replicationrole:master #角色connected_slaves:0 #从节点数量master_failover_state:no-failovermaster_replid:e7b46e93f77ecf18c44d6630d9b08cb9cabe9cb6master_replid2:0000000000000000000000000000000000000000master_repl_offset:0second_repl_offset:-1repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0#slave节点需要设置主机密码masterauth "1233321
配置主从
两个节点分别开启redis
#slave节点输入该命令:SLAVEOF 192.168.218.149 6379 #临时绑定主机#查看主机的replication# Replicationrole:masterconnected_slaves:1 #1个从节点slave0:ip=192.168.218.150,port=6379,state=online,offset=14,lag=0master_failover_state:no-failovermaster_replid:5d91c62400c1dafd2a153811f5f9ef43ed58666bmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:14second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:14#查看从机的replication127.0.0.1:6379> info replication# Replicationrole:slavemaster_host:192.168.218.149master_port:6379master_link_status:up #状态 开启master_last_io_seconds_ago:4master_sync_in_progress:0slave_read_repl_offset:0slave_repl_offset:0slave_priority:100slave_read_only:1replica_announced:1connected_slaves:0master_failover_state:no-failovermaster_replid:5d91c62400c1dafd2a153811f5f9ef43ed58666bmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:0second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:0SLAVE NO ONE #变回主机
在配置文件中设置replicaof 即可永久绑定主机,将该机器设置为从机。
主机能写和读,从机只能读

主机断开连接,从机依旧连接到主机,但是没有写操作,主机如果回来了,从机依然可以直接获取到主机写的信息。并且如果没做哨兵机制,是无法篡位做主机的。
复制的原理
Slave启动成功连接到master后会发送一个sync命令
Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
增量复制
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
薪火相传
上一个Slave可以是下一个slave的 Master,Slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻master的写压力,去中心化降低风险。
中途变更转向:会清除之前的数据,重新建立拷贝最新的
风险是—旦某个slave宕机,后面的slave都没法备份
主机挂了,从机还是从机,无法写数据了
哨兵模式
当主机宕机,自动选举主机的模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel (哨兵)架构来解决这个问题。
谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
哨兵模式的作用
- 监控(Monitoring):哨兵进程会不断地检查Master和Slave是否运作正常。
- 提醒(Notification): 当被监控的某个节点出现问题时,哨兵进程可以通过API向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic Failover): 当一个Master不能正常工作时,哨兵进程会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave 改为复制新的Master.当客户端试图连接失效的Master时,Redis集群也会向客户端返回新Master的地址,使得Redis集群可以使用现在的Master替换失效Master。Redis Sentinel故障转移架构。
- 配置提供者:在哨兵模式下,客户端在初始化时连接的是哨兵节点集合,从中获取主节点的信息。
哨兵机制
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failoveri故障转移操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
测试
先搭建一仆二主模式
| 机器 | ip | 端口 |
|---|---|---|
| 主机 | 192.168.218.150 | 6379 |
| 从机1 | 192.168.218.150 | 6380 |
| 从机2 | 192.168.218.150 | 6381 |
#在一台机器开启两个redis只需要复制配置文件并且修改端口即可。cp redis.conf redis6380.conf #复制配置文件redis-server redis6380.conf #开启第三个redis服务
创建哨兵机器
配置哨兵配置文件sentinel.conf
#随便一台机器上均可配置哨兵文件,记得多开一个窗口vim sentinel.conf#做哨兵 监控 自定义名称 ip 端口 权重投票值sentinel monitor myreids1 192.168.218.149 6379 1sentinel auth-pass myredis1 1233321
启动哨兵机制
redis-sentinel setninel.conf#将当前的主机的redis shutdown#此时哨兵机器会根据判断,设置新的master。#将原来的主机redis重启,会变成slave,并且跟随新的master
由于所有的写操作都是先在 Master上操作,然后同步更新到slave上,所以从Master同步到slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
哨兵过程
1.多个Sentinel发 现并确认Master有问题
2.选出一个Sentinel作为领导。
3.选出一个Slave作为Master。
4.通知其余Slave成为新的Master的Slave。5.通知客户端主从变化。
6.等待旧的Master成为新Master的Slave
优点:
- 哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
- 主从可以切换,故障可以转移,系统的可用性就会更好
- 哨兵模式就是主从模式的升级,手动到自动,更加健壮!
缺点:
- Redis不好在线扩容,集群容量一旦到达上限,在线扩容就十分麻烦!
- 实现哨兵模式的配置其实是很麻烦的,里面有很多选择!
Redis集群
Redis集群是个由多个主从节点组成的分布式服务器群, 它具有复制、 高可用和分片特性。Redis 集群将所有数据存储区域划分为16384 个槽(Slot), 每个节点负责一部分槽,槽的信息存储于每个节点中。Redis 集群要将每个节点设置成集群模式,它没有中心节点,可水平扩展,它的性能和高可用性均优于主从模式和哨兵模式,而且集群配置非常简单。
相较于哨兵模式,这种方案的优点在于提高了读写的并发率,散发了I/O,在保障高可用的前提下提高了性能。
Redis集群环境
Redis集群的节点要求如下:
- 主节点不能少于总节点的一半。
- 主节点至少要有3个
准备6台机器
| 机器 | ip | 端口 |
|---|---|---|
| Centos | 192.168.218.150 | 6379 |
| Centos | 192.168.218.150 | 6380 |
| Centos | 192.168.218.150 | 6381 |
| Centos | 192.168.218.150 | 6382 |
| Centos | 192.168.218.150 | 6383 |
| Centos | 192.168.218.150 | 6384 |
在配置文件中添加/修改如下内容
六台机器都做修改
vim redis.confcluster-enabled yes #启动集群模式cluster-config-file nodes-6379.conf #集群节点信息cluster-node-timeout 5000 #集群节点的超时时限
redis-cli --cluster create --cluster-replicas 1 192.168.218.150:6379 192.168.218.150:6380 192.168.218.150:6381 192.168.218.150:6382 192.168.218.150:6383 192.168.218.150:6384#--cluster create 创建集群#--cluster-replicas 1 以最简单的方式创建集群,一主一从
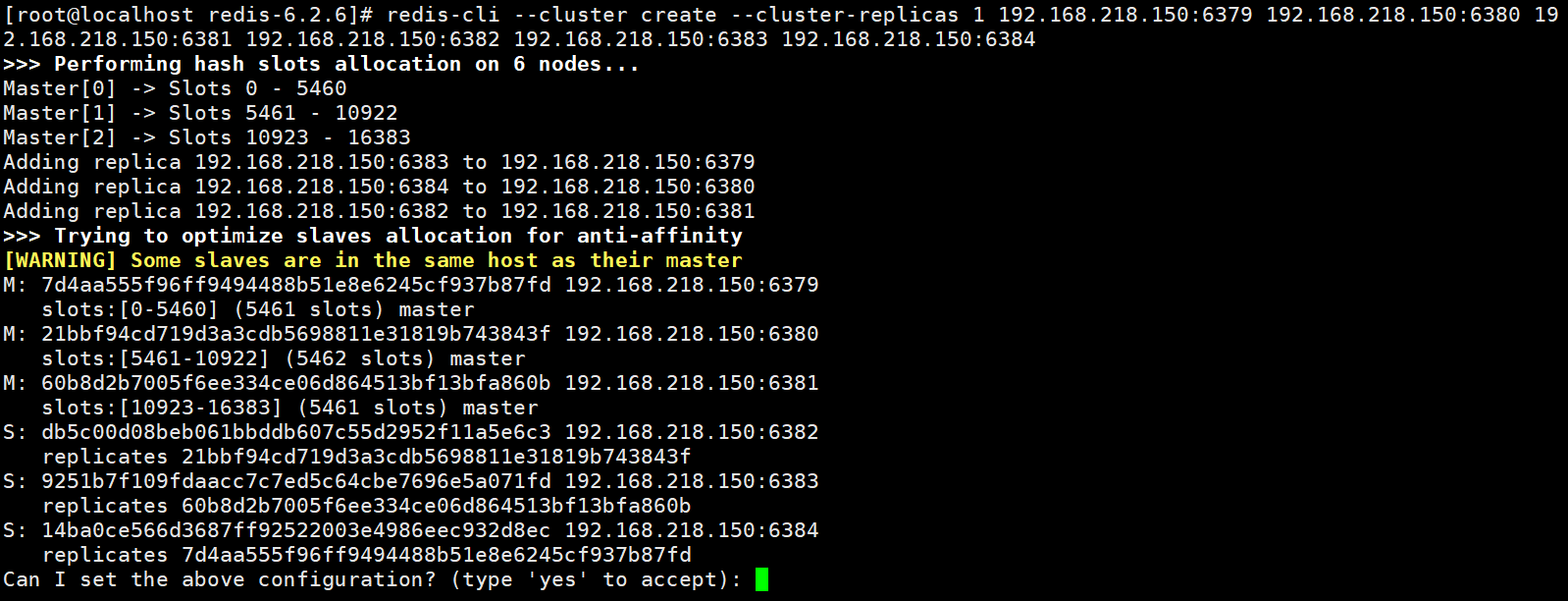
当出现如下字符就是创建成功
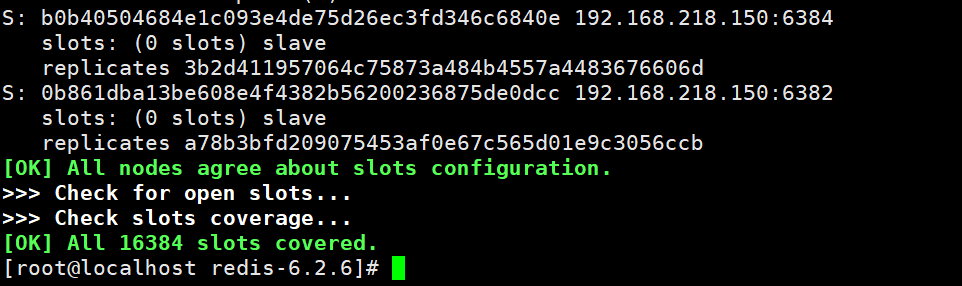
集群验证
redis-cli -c -h 192.168.218.150 -p 6379 #-c 进去集群192.168.218.150:6379> set name liao-> Redirected to slot [5798] located at 192.168.218.150:6380OK#在6379中执行了命令,跳转重定向到了6380
cluster info 查看集群信息
192.168.218.150:6380> cluster infocluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6 #6个节点cluster_size:3cluster_current_epoch:6cluster_my_epoch:2cluster_stats_messages_ping_sent:239cluster_stats_messages_pong_sent:227cluster_stats_messages_meet_sent:1cluster_stats_messages_publish_sent:581cluster_stats_messages_sent:1048cluster_stats_messages_ping_received:227cluster_stats_messages_pong_received:240cluster_stats_messages_publish_received:345cluster_stats_messages_received:812
cluster nodes 查看集群节点列表
192.168.218.150:6380> cluster nodes4fc7f6d66f6d394b3bfe41a21dbfd572efa42c49 192.168.218.150:6380@16380 myself,master - 0 1647007479000 2 connected 5461-109227b351edf211c94f71d9dae2ce7915809dc36ccc2 192.168.218.150:6383@16383 slave 4fc7f6d66f6d394b3bfe41a21dbfd572efa42c49 0 1647007484000 2 connectedb0b40504684e1c093e4de75d26ec3fd346c6840e 192.168.218.150:6384@16384 slave 3b2d411957064c75873a484b4557a4483676606d 0 1647007483515 3 connected0b861dba13be608e4f4382b56200236875de0dcc 192.168.218.150:6382@16382 slave a78b3bfd209075453af0e67c565d01e9c3056ccb 0 1647007484000 1 connecteda78b3bfd209075453af0e67c565d01e9c3056ccb 192.168.218.150:6379@16379 master - 0 1647007485000 1 connected 0-54603b2d411957064c75873a484b4557a4483676606d 192.168.218.150:6381@16381 master - 0 1647007485564 3 connected 10923-16383
Redis集群操作和故障恢复
关闭一个集群
redis-cli -c -h 192.168.218.150 -p 6379 shutdown#此时6379端口的redis服务已经关闭


分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为yes,那么整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为no,那么该插槽数据全都不能使用,也无法存储
Slots 插槽
一个Redis集群包含16384个,0-16383。主节点会平均分配这些插槽。
当创建键值对,会计算他的值。例如key1的值为100,就放到0-5460的主机中。
redis-cli -p 6380 -c #进入6380集群127.0.0.1:6380> set k1 v1-> Redirected to slot [12706] located at 192.168.218.150:6381 #会转移到10923-16383的6381集群中OK192.168.218.150:6381> mset names liao age 20 address henan sex nan #连续创建时会出错(error) CROSSSLOT Keys in request don't hash to the same slot #请求中的键没有哈希到同一个槽'192.168.218.150:6380> HMSET user:test names liao age 20 address henan sex nan #使用hash连续创建则不会出错-> Redirected to slot [12617] located at 192.168.218.150:6381
查看插槽
cluster keyslot k1 #查看k1的插槽位置(integer) 12706cluster countkeysinslot 12706 #查看该插槽有多个键值对,只能查看自己插槽范围的数值(integer) 1cluster getkeysinslot 12706 1 #查询该插槽中第一个数值
Jedis
Jedis是Redis官方推荐的Java连接开发工具。想要在java中控制使用redis,就要使用Jedis工具(当然官网还有其他java可用的redis工具)。
Jedis安装
下载安装IDEA——文件——新建——项目
Maven——选择SDK——下一步——创建项目
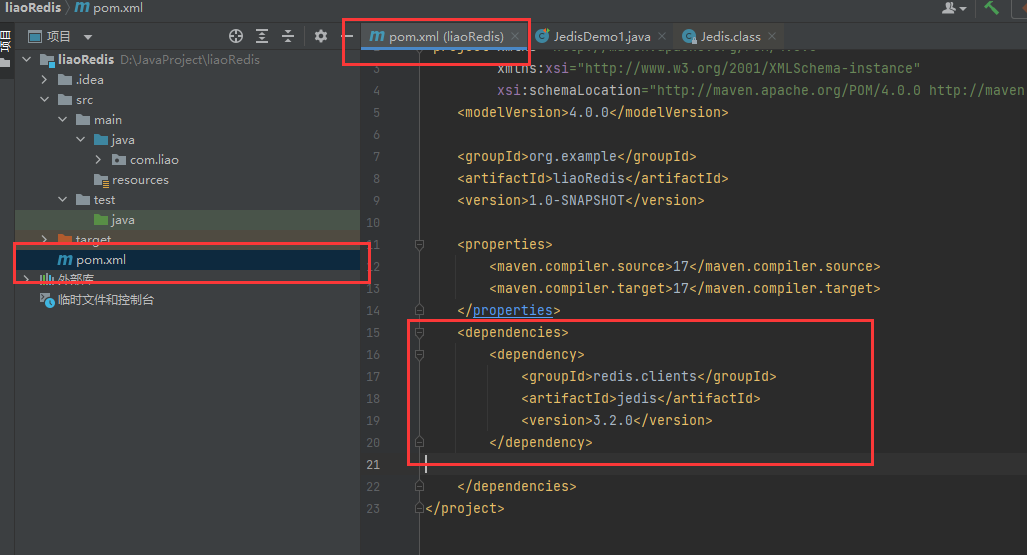
在Maven项目中自带的xml文件加入如下代码
<dependencies><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.2.0</version></dependency></dependencies>
基础使用
package com.liao;import org.junit.Test; //导入Junit包,使得我们可以只运行函数中的命令import redis.clients.jedis.Jedis; //导入jedis包import java.util.List; //导入List包,后面使用list列表import java.util.Set; //导入Set包,后面使用Set列表public class JedisDemo1 {public static void main(String[] args) {Jedis jedis = new Jedis("192.168.218.150",6380); //连接redis,IP,Port//测试String value = jedis.ping(); //使用PING命令System.out.println(value); //打印输入Ping命令的输出}//操作key@Testpublic void demo1(){//创建测试对象Jedis jedis = new Jedis("192.168.218.150",6385);//添加对象//jedis.set("name","liao"); set创建//mset创建多个jedis.mset("names","liao","age","20","sex","nan","address","henan","birthday","2002-10-1");List<String> mgets = jedis.mget("age","sex","address","birthday");//获取String name = jedis.get("name");System.out.println(name);System.out.println(mgets);Set<String> keys = jedis.keys("*");for(String key:keys){ //for循环打印出所有的值System.out.println(key);}}//操作key@Testpublic void demo2(){//创建测试对象Jedis jedis = new Jedis("192.168.218.150",6385);//jedis.set("k4","awa");jedis.lpush("k5","wuhu","qwq");List<String> values = jedis.lrange("k5",0,-1);System.out.println(values);}//操作set@Testpublic void demo3(){//创建测试对象Jedis jedis = new Jedis("192.168.218.150",6385);jedis.sadd("name1","xiaozhang","aoge");Set<String> names = jedis.smembers("name1");System.out.println(names);}//操作set@Testpublic void demo4(){//创建测试对象Jedis jedis = new Jedis("192.168.218.150",6385);jedis.hset("users","ages","20");String hgets = jedis.hget("users","ages");System.out.println(hgets);}//操作zset@Testpublic void demo5(){//创建测试对象Jedis jedis = new Jedis("192.168.218.150",6385);jedis.zadd("china",100d,"shanghai");Set<String> china = jedis.zrange("china",0,-1);System.out.println(china);}}

若有收获,就点个赞吧
0 人点赞
