1.OSI的七层模型分别是什么?各自功能分别是什么?
简要概括
- 物理层:底层数据传输,如网线;网卡标准。
- 数据链路层:定义数据的基本格式,如何传输,如何标识;如网卡MAC地址。
- 网络层:定义IP编址,定义路由功能;如不同设备的数据转发。
- 传输层:端到端传输数据的基本功能;如 TCP、UDP。
- 会话层:控制应用程序之间会话能力;如不同软件数据分发给不同软件。
- 表示层:数据格式标识,基本压缩加密功能。
- 应用层:各种应用软件,包括 Web 应用。
说明:
- 在四层,既传输层数据被称作段(Segments);
- 三层网络层数据被称做包(Packages);
- 二层数据链路层时数据被称为帧(Frames);
- 一层物理层时数据被称为比特流(Bits)。
总结
- 网络七层模型是一个标准,而非实现。
- 网络四层模型是一个实现的应用模型。
- 网络四层模型由七层模型简化合并而来。
2.为什么需要三次握手?两次不行?
通俗的讲三次握手
第一次握手:客户端发送网络包,服务端收到了。这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。
第二次握手:服务端发包,客户端收到了。这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。不过此时服务器并不能确认客户端的接收能力是否正常。
第三次握手:客户端发包,服务端收到了。这样服务端就能得出结论:客户端的接收、发送能力正常,服务器自己的发送、接收能力也正常。
三次握手的过程中,双方是由很多状态的改变的,而这些状态,也是面试官可能会问的点。所以我觉得在回答三次握手的时候,我们应该要描述的详细一点,而且描述的详细一点意味着可以扯久一点。加分的描述我觉得应该是这样:
刚开始客户端处于 closed 的状态,服务端处于 listen 状态。然后
1、第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 SYN_Send 状态。
2、第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s),同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_RCVD 的状态。
3、第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 established 状态。
4、服务器收到 ACK 报文之后,也处于 established 状态,此时,双方以建立起了链接
关于三次握手的额外知识
1、(ISN)是固定的吗
三次握手的一个重要功能是客户端和服务端交换ISN(Initial Sequence Number), 以便让对方知道接下来接收数据的时候如何按序列号组装数据。
如果ISN是固定的,攻击者很容易猜出后续的确认号,因此 ISN 是动态生成的。
2、什么是半连接队列
服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于SYN-ACK 重传次数的问题: 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传,如果重传次数超 过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s, 2s, 4s, 8s,
3、三次握手过程中可以携带数据吗
很多人可能会认为三次握手都不能携带数据,其实第三次握手的时候,是可以携带数据的。也就是说,第一次、第二次握手不可以携带数据,而第三次握手是可以携带数据的。
为什么这样呢?大家可以想一个问题,假如第一次握手可以携带数据的话,如果有人要恶意攻击服务器,那他每次都在第一次握手中的 SYN 报文中放入大量的数据,因为攻击者根本就不理服务器的接收、发送能力是否正常,然后疯狂着重复发 SYN 报文的话,这会让服务器花费很多时间、内存空间来接收这些报文。也就是说,第一次握手可以放数据的话,其中一个简单的原因就是会让服务器更加容易受到攻击了。
而对于第三次的话,此时客户端已经处于 established 状态,也就是说,对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据页没啥毛病。
3.为什么需要四次挥手?三次不行?
1、第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。
2、第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。
3、第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
4、第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态
5、服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
4.HTTP1.0,1.1,2.0 的版本区别
1996年5月,HTTP/1.0 版本发布,为了提高系统的效率,HTTP/1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
为了解决HTTP/1.0存在的缺陷,HTTP/1.1于1999年诞生。相比较于HTTP/1.0来说,最主要的改进就是引入了持久连接。所谓的持久连接即TCP连接默认不关闭,可以被多个请求复用。
HTTP/2 为了解决HTTP/1.1中仍然存在的效率问题,HTTP/2 采用了多路复用。即在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。能这样做有一个前提,就是HTTP/2进行了二进制分帧,即 HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码。
5.POST和GET的区别
使用场景
GET 用于获取资源,而 POST 用于传输实体主体。
参数
GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。不能因为 POST 参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(Fiddler)查看。
因为 URL 只支持 ASCII 码,因此 GET 的参数中如果存在中文等字符就需要先进行编码。例如 中文 会转换为 %E4%B8%AD%E6%96%87,而空格会转换为 %20。POST 参数支持标准字符集。
安全性
安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
安全的方法除了 GET 之外还有:HEAD、OPTIONS。
不安全的方法除了 POST 之外还有 PUT、DELETE。
幂等性
幂等的 HTTP 方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。
所有的安全方法也都是幂等的。
在正确实现的条件下,GET,HEAD,PUT 和 DELETE 等方法都是幂等的,而 POST 方法不是。
可缓存
- 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
- 响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
XMLHttpRequest
为了阐述 POST 和 GET 的另一个区别,需要先了解 XMLHttpRequest:
XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用
- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
- 而 GET 方法 Header 和 Data 会一起发送。
6.HTTP 哪些常用的状态码及使用场景?
状态码分类
1xx:表示目前是协议的中间状态,还需要后续请求
2xx:表示请求成功
3xx:表示重定向状态,需要重新请求
4xx:表示请求报文错误
5xx:服务器端错误
常用状态码
101 切换请求协议,从 HTTP 切换到 WebSocket
200 请求成功,有响应体
301 永久重定向:会缓存
302 临时重定向:不会缓存
304 协商缓存命中
403 服务器禁止访问
404 资源未找到
400 请求错误
500 服务器端错误
503 服务器繁忙
7.HTTP 方法有哪些?
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
- GET:获取资源,当前网络中绝大部分使用的都是 GET;
- HEAD:获取报文首部,和 GET 方法类似,但是不返回报文实体主体部分;
- POST:传输实体主体
- PUT:上传文件,由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
- PATCH:对资源进行部分修改。PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
- OPTIONS:查询指定的 URL 支持的方法;
- CONNECT:要求在与代理服务器通信时建立隧道。使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
- TRACE:追踪路径。服务器会将通信路径返回给客户端。发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
9.Delete:删除文件,与 PUT 功能相反,并且同样不带验证机制。
8.在浏览器中输入 URL 地址到显示主页的过程?
- DNS 解析:浏览器查询 DNS,获取域名对应的 IP 地址:具体过程包括浏览器搜索自身的 DNS 缓存、搜索操作系统的 DNS 缓存、读取本地的 Host 文件和向本地 DNS 服务器进行查询等。对于向本地 DNS 服务器进行查询,如果要查询的域名包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析(此解析具有权威性);如果要查询的域名不由本地 DNS 服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个 IP 地址映射,完成域名解析(此解析不具有权威性)。如果本地域名服务器并未缓存该网址映射关系,那么将根据其设置发起递归查询或者迭代查询;
- TCP 连接:浏览器获得域名对应的 IP 地址以后,浏览器向服务器请求建立链接,发起三次握手;
- 发送 HTTP 请求:TCP 连接建立起来后,浏览器向服务器发送 HTTP 请求;
- 服务器处理请求并返回 HTTP 报文:服务器接收到这个请求,并根据路径参数映射到特定的请求处理器进行处理,并将处理结果及相应的视图返回给浏览器;
- 浏览器解析渲染页面:浏览器解析并渲染视图,若遇到对 js 文件、css 文件及图片等静态资源的引用,则重复上述步骤并向服务器请求这些资源;浏览器根据其请求到的资源、数据渲染页面,最终向用户呈现一个完整的页面。
- 连接结束。
9.DNS 的解析过程?
- 主机向本地域名服务器的查询一般都是采用递归查询。所谓递归查询就是:如果主机所询问的本地域名服务器不知道被查询的域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向根域名服务器继续发出查询请求报文(即替主机继续查询),而不是让主机自己进行下一步查询。因此,递归查询返回的查询结果或者是所要查询的 IP 地址,或者是报错,表示无法查询到所需的 IP 地址。
- 本地域名服务器向根域名服务器的查询的迭代查询。迭代查询的特点:当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的 IP 地址,要么告诉本地服务器:“你下一步应当向哪一个域名服务器进行查询”。然后让本地服务器进行后续的查询。根域名服务器通常是把自己知道的顶级域名服务器的 IP 地址告诉本地域名服务器,让本地域名服务器再向顶级域名服务器查询。顶级域名服务器在收到本地域名服务器的查询请求后,要么给出所要查询的 IP 地址,要么告诉本地服务器下一步应当向哪一个权限域名服务器进行查询。最后,本地域名服务器得到了所要解析的 IP 地址或报错,然后把这个结果返回给发起查询的主机。
10.HTTPS 的工作过程?
1、 客户端发送自己支持的加密规则给服务器,代表告诉服务器要进行连接了;
2、 服务器从中选出一套加密算法和 hash 算法以及自己的身份信息(地址等)以证书的形式发送给浏览器,证书中包含服务器信息,加密公钥,证书的办法机构;
3、客户端收到网站的证书之后要做下面的事情:
- 验证证书的合法性;
- 如果验证通过证书,浏览器会生成一串随机数,并用证书中的公钥进行加密;
- 用约定好的 hash 算法计算握手消息,然后用生成的密钥进行加密,然后一起发送给服务器。
4、服务器接收到客户端传送来的信息,要做下面的事情:
- 4.1 用私钥解析出密码,用密码解析握手消息,验证 hash 值是否和浏览器发来的一致;
- 4.2 使用密钥加密消息;
5、如果计算法 hash 值一致,握手成功。
11.什么是SQL注入?举个例子
SQL注入就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
1). SQL注入攻击的总体思路
(1). 寻找到SQL注入的位置
(2). 判断服务器类型和后台数据库类型
(3). 针对不同的服务器和数据库特点进行SQL注入攻击
2). SQL注入攻击实例
比如,在一个登录界面,要求输入用户名和密码,可以这样输入实现免帐号登录:
用户名: ‘or 1 = 1 --密 码:
用户一旦点击登录,如若没有做特殊处理,那么这个非法用户就很得意的登陆进去了。这是为什么呢?
下面我们分析一下:从理论上说,后台认证程序中会有如下的SQL语句:
String sql = “select * from user_table where username=’ “+userName+” ’ and password=’ “+password+” ‘”;
因此,当输入了上面的用户名和密码,上面的SQL语句变成:
SELECT * FROM user_table WHERE username=’’or 1 = 1 –- and password=’’
分析上述SQL语句我们知道,username=‘ or 1=1 这个语句一定会成功;然后后面加两个 -,这意味着注释,它将后面的语句注释,让他们不起作用。这样,上述语句永远都能正确执行,用户轻易骗过系统,获取合法身份。
3). 应对方法
(1). 参数绑定
使用预编译手段,绑定参数是最好的防SQL注入的方法。目前许多的ORM框架及JDBC等都实现了SQL预编译和参数绑定功能,攻击者的恶意SQL会被当做SQL的参数而不是SQL命令被执行。在mybatis的mapper文件中,对于传递的参数我们一般是使用 # 和$来获取参数值。
当使用#时,变量是占位符,就是一般我们使用javajdbc的PrepareStatement时的占位符,所有可以防止sql注入;当使用$时,变量就是直接追加在sql中,一般会有sql注入问题。
(2). 使用正则表达式过滤传入的参数
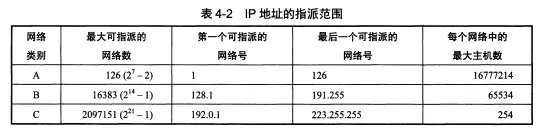
12.IP地址有哪些分类?
A类地址(1~126):网络号占前8位,以0开头,主机号占后24位。
B类地址(128~191):网络号占前16位,以10开头,主机号占后16位。
C类地址(192~223):网络号占前24位,以110开头,主机号占后8位。
D类地址(224~239):以1110开头,保留位多播地址。
E类地址(240~255):以1111开头,保留位今后使用

13.HTTP 和 HTTPS 的区别?
- 开销:HTTPS 协议需要到 CA 申请证书,一般免费证书很少,需要交费;
- 资源消耗:HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的 ssl 加密传输协议,需要消耗更多的 CPU 和内存资源;
- 端口不同:HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443;
- 安全性:HTTP 的连接很简单,是无状态的;HTTPS 协议是由 TSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全
14.HTTPS的优缺点
优点:
- 使用 HTTPS 协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
- HTTPS 协议是由 SSL + HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 HTTP 协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性;
- HTTPS 是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
缺点:
- HTTPS 协议握手阶段比较费时,会使页面的加载时间延长近 50%,增加 10% 到 20% 的耗电;
- HTTPS 连接缓存不如 HTTP 高效,会增加数据开销和功耗,甚至已有的安全措施也会因此而受到影响;
- SSL 证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用;
- SSL 证书通常需要绑定 IP,不能在同一 IP 上绑定多个域名,IPv4 资源不可能支撑这个消耗;
- HTTPS 协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。最关键的,SSL 证书的信用链体系并不安全,特别是在某些国家可以控制 CA 根证书的情况下,中间人攻击一样可行。

若有收获,就点个赞吧
0 人点赞
