Python安装与配置
视频:https://www.bilibili.com/video/BV12E411A7ZQ的笔记
Linux安装python环境
建议安装桌面linux组件
- 到官网下载linux的tar安装包
tar -zxf Python-3.7.3.tar.xz
- 安装需要的环境附属
yum install -y gcc zlib zlib-devel openssl-devel readline readline-develide
- 进入解压的安装包中进行编译
./configure --prefix=/usr/local/python --with-ssl
- 编译安装
make && make install
- 配置环境变量
export PYTHON_HOME=/usr/local/python3.10export PATH=${PYTHON_HOME}/bin:$PATH
此时使用命令:pyhthon3 就可以进入python3环境了。
Linux下IDE的安装
- 到pycharm下载安装包,要是.tar结尾的!
tar -zxf pycharm
- 进入解压的文件夹中的bin目录,执行./pycharm.sh
cd pycharm
cd bin && ./pycharm.sh
Linxu创建虚拟环境
python3 -m venv ~/mypysource ~/mypy /bin/activate
Python语法基础
设置中文
# coding:utf-8
print 输出
输出
age = 18 #创建变量print("我的名字是%s,我的国籍是%s" %("里奥","中国")) #输出占位符print("我的年龄是:%d岁" %age) #输出变量
- %s 字符占位符
- %d 数字占位符
sep 设置输出时连接符号
print("aaa","bbb","ccc") #python会默认用 空格 连接print("www","baidu","com",sep=".") #sep 设置连接符号
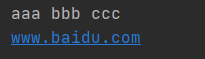
end 设置末尾操作
因为print是默认换行的,所以可以在末尾添加 end="" 进行操作和限制
print("www",end="") #取消换行print("wuhu",end="\t") #多一段距离print("world",end="\n")#换行
- \t 如同按一下Tab键
- \n 进行换行
input 输入
获取用户在键盘上的输入信息
password = input("请输入密码") #获取键盘的输入,并转为stringprint("您输入的密码为:%s" %password)
type() 查看数据类型
type(a) 查看变量a的数据类型
a,b,c,d = 20 , 5.5 , True , 4+3aprint(type(a),type(b),type(c),type(d))#运行:<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
类型转换
| 函数 | 说明 |
|---|---|
| int(X) | 转换为整数 |
| float(x) | 转换为浮点数 |
| str(x) | 转换为字符串 |
| bool(x) | 转换为布尔型 |
注意:布尔型转换时,true为1flase为0。
运算符
算数运算符
两个比较特殊的>>> 2 // 4 # 除法,得到一个整数0>>> 2 ** 5 # 乘方32
成员运算符
in 如果在指定的序列中找到值,返回true,否则返回falsenot in 如果在指定的序列中没有找到值,返回false,否则返回true
身份运算符
is 判断两个标识符是否引用同一个对象 x is y 类似 id(x) == id(y)is not 判断两个标识符是否引用不同对象 x is not y 类似 id(a) != id(b)
id(x) 是取对象的内存地址
逻辑运算符
and or not 与 或 非。
逻辑运算符的特殊用法:
a = 36a < 10 and print("hello world")#当and前面的结果是false的情况下,后面的结果不会执行。a = 50a > 10 or print("hello world")#因为前面的等式成立了,所以后面的代码并不会执行
判断语句和循环语句
循环时不需要使用{} 大括号,只需使用缩进,对其即可。
: 不能缺少代表着 条件 的结束 语句 的开始。
if True:print("true")else:print("false")
如果出现没有对齐的情况,要么报错,要么执行位置不对:
if True:print("qwq")print("qwq")print("false") #第四行出现错误else:print("false")print("false")#此行少了一格,如果没有第四行#则会直接输出,不会进行if中的判断
多重条件判断
python的if语句中的多重判断,不是else if : 而是 elif :
score = 70if score <=100 and score >=90:print("考试成绩优秀")elif score < 90 and score >=80:print("还可以")else:print("及格")
只有在最后时,才是else,其余的多重条件判断都用elif
if嵌套
因为没了{} 所以嵌套时要注意缩进各个代码之间的位置。
并且为了方便写代码,部分编辑器在嵌套时会有提示线
xingbie = 1danshen = 1if xingbie == 1:print("男生") #执行语句和条件语句位置一样if danshen == 1:print("我现在单身,帅哥一枚")else:print("我不是单身")else :print("女生")if danshen == 1:print("我是单身,求撩啊!")else:print("我不是单身!")
常用模块
如何导入模块:
import random #直接导入整个库random.randint(0,100) #78import getpass as gp #给库起一个别名gp.getpass()from random import randint #从库中导入某个功能randint(0,100)
关于模块的加载:
- 当导入模块时,模块会被加载一次,并且只加载一次。
- 只加载一次可以阻止多重导入时代码被多次执行
- 如果两个文件互相导入,防止了无限的相互加载
- 模块加载时,顶层代码会自动执行,所以只将函数放入模块的顶层是良好的编程习惯
模块导入的特性
- 模块具有一个
__name__特殊属性 - 当模块文件直接执行时,
__name__的值为__main__ - 当模块被另一个文件导入时,
__name__的值就是该模块的名字
生成随机密码
import random 导入随机数库,可以使用其中的函数了!
import random # 导入需要用到的随机模块from string import ascii_letters, digits # 导入模块,第一个代表所有字母的大小写,第二个模块代表0-9def password(x=8): # 设置默认需要8位随机密码# all_chs = '123456789qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM' # 设置随机的字符all_chs = ascii_letters + digitsresult = '' # 随机生成的数值for i in range(x): # 接收x的值ch = random.choice(all_chs) # 从all_chs中选取随机一个字符result += ch # 添加到result中return result
shutil模块
shell+util。工具模块。做一些复制粘贴移动等操作。
| 函数 | 用法 |
|---|---|
| copy | 将文件复制粘贴(上层方法,省事) |
| copy2 | 复制粘贴文件,并且保留元数据 (stat qwe.txt查看) |
| move | 剪切文件 |
| copymode | 修改文件的模式权限属性 |
| copytree | 复制目录 |
| rmtree | 删除目录 |
| chowm | 修改文件所属组和所属用户 |
| copystat | 将权限位最后访问时间进行复制 |
import shutilf1 = open("qwe.txt", "rb")f2 = open("test.txt", "wb")shutil.copyfileobj(f1, f2) # 将文件复制粘贴(底层方法)f1.close()f2.close()shutil.copy("test.txt", "wuhu.txt") # 将文件复制粘贴(上层方法,省事)shutil.copy2("qwe.txt", "wuhu.txt") # 复制粘贴文件,并且保留元数据 (stat qwe.txt查看)shutil.move("qwe.txt", "wuhu.txt") # 剪切文件shutil.copymode("qwe.txt", "wuhu.txt") # 复制文件的权限属性shutil.copytree("/etc/systemctl", "/tmp/systemctl") # 复制文件夹shutil.rmtree("/tmp/systemctl") # 删除文件夹shutil.chown("/tmp/123.txt", user='liao123', group='liao123') # 修改文件的所属用户和所属组shutil.copystat("qwe.txt", "wuhu.txt") # 将权限位最后访问时间进行复制
subprocess
- 模块用于执行系统命令
- 允许产生新的进程,连接到它们输入/输出/错误管道,并获得它们的返回代码
- 本模块指在替换几个较早的功能和模块,如os.system,os.spawn
run方法
用来在python中执行linux的命令
subprocess.run(['ls']) # 执行一次lssubprocess.run(['ls', '/home']) # 使用列表的方式执行 ls /homesubprocess.run('ls /home', shell=True) # 使用字符串执行ls /home 必须设置shell=truesubprocess.run('echo $HOME',shell=True) # 输出内置变量
程序的输出和错误
程序每运行一个命令,就会打印出命令的执行效果
result = subprocess.run(['ls'],stdout=subprocess.PIPE,stderr=subprocess.PIPE) #此时不会显示任何东西,因为数据都在stdout和stderr中print(result)CompletedProcess(args='ls ..' , returncode=0)result.args 'ls ..'result.returncode 0 #echo $? 查看命令执行状态result.stdout.decode() #标准输出 存储命令打印的数据result.stderr.decode() #标准错误 存储命令的报错
time模块
用来获取时间和停留的模块
import timeprint(time.time()) #获取当前时间戳print(time.ctime()) #获取当前星期-月-日-时间-年份x = time.localtime() #以元祖的形式获取当前时间print(x)print(x.tm_year,x.tm_mon)print(time.localtime(time.time())) #将时间戳转换成元祖的形式time.sleep(1) #到当前位置停留一秒print(time.strftime('%Y-%m-%d %H:%M:%S')) #自定义格式输出当前时间print(time.strptime('2020-10-12 7:12:19','%Y-%m-%d %H:%M:%S')) #将一段时间自定义输出print(time.asctime(time.localtime(time.time()))) #将元祖形式的时间转换读取为当前时间
| 函数 | 作用 |
|---|---|
| time.time() | 获取当前时间戳 |
| time.ctime() | 获取当前星期-月-日-时间-年份 |
| time.localtime() | 以元祖的形式获取当前时间 |
| time.localtime(time.time()) | 将时间戳转换成元祖的形式 |
| time.sleep(1) | 停留一秒 |
| time.strftime(‘%Y-%m-%d %H:%M:%S’) | 自定义格式输出当前时间 |
| time.strptime(‘2020-10-12 7:12:19’,’%Y-%m-%d %H:%M:%S’) | 将一段时间按照格式转为元祖,用来比较时间大小 |
| time.asctime(time.localtime(time.time())) | 将元祖形式的时间转换读取为当前时间 |
#小火车import timeprint('#' * 20, end='')counter = 0while 1:print('\r%s@%s' % ('#' * counter, '#' * (19 - counter)),end='')counter += 1time.sleep(0.3)if counter == 20:counter = 0for i in range(10):priny("\r"+"#" *i,end="")time.sleep(0.5)
datetime
from datetime import datetimeprint(datetime.now()) #获取当前时间t = datetime.now()print(t.date()) #获取当前年月日print(t.time()) #获取当前时分秒print(t.today()) #获取当前时间print(t.ctime()) #获取当前星期-月-日-时间-年份print(t.strftime('%Y-%m-%d %H:%M:%S'))print(t.strptime('2020-10-20 9:19:12',"%Y-%m-%d %H:%M:%S"))
时间的计算
from datetime import datetime,timedeltat = datetime.now() #获取当前时间days = timedelta(days=100,hours=2) #设置一个时间变量,设置为100天又2小时print(t - days) #当前时间 - 100天又2小时
日志读取
from datetime import datetimet9 = datetime.strptime('2020-1-4 20:00:00', "%Y-%m-%d %H:%M:%S")t12 = datetime.strptime('2020-1-4 22:59:59', "%Y-%m-%d %H:%M:%S")with open('myweb.log') as f:for i in f:t = datetime.strptime(i[0:17], "%Y-%m-%d %H:%M:%S")if t > t12:breakif t >= t9:print(i,end='')# if t9 <= t <= t12:# print(i,end="")
os模块
常用的简单操作
| 方法 | 作用 | 用法 |
|---|---|---|
| rename() | 重命名 | os.rename(“1.txt”,”2.txt”) |
| mkdir() | 创建文件夹 | os.mkdir(“/tmp/aaa”) |
| rmdir() | 删除文件夹 | os.rmdir(“/tmp/aaa”) |
| getcwd() | 获取当前路径 | os.getcwd() |
| remove() | 删除文件 | os.remove(“2.txt”) |
| chdir() | 改变路径 | os.chdir(“/etc”) |
| listdir() | 获取目录文件列表,以列表形式存储 | os.listdir(“/etc/sysconfig”) |
| symlink() | 设置快捷方式(软链接) | os.symlink(“/etc/host”,”links”) |
| unlink() | 删除连接文件 | os.unlink(“/etc/links”) |
| chmod() | 修改权限(Linux,八进制) | os.chmod(“host”,0o660) |
import osos.rename("test.txt","test123.txt") #修改名称os.mkdir("fild") #创建文件夹os.getcwd #获取当前目录os.remove("test123.txt") #删除文件os.chdir("../") #改变默认目录os.listdir("./") #获取目录列表os.rmdir("fild") #删除文件夹os.path.exits(路径) #查看文件是否存在
常用的path操作
| 方法 | 作用 | 用法 |
|---|---|---|
| path.abspath() | 获取文件的绝对路径 | os.path.abspath(“awa”) |
| path.exists() | 确认文件是否存在 | os.path.exists(“2.txt”) |
| path.basename() | 获取最终文件/目录的名称 | os.path.basename(“/etc/tmp/aaa”) |
| path.dirname() | 获取末尾文件前的文件路径 | os.path.dirname(“/etc/aaa”) |
| path.split() | 路径与末尾文件名以元组来存储 | os.path.split(“/etc/aaa”) |
| path.splitext() | 切割了的文件前缀与后缀以元组来存储 | os.path.splitext(“/etc/aaa”) |
| path.join() | 拼接两个字符,如果是路径则用/拼接 | os.path.join(“/etc”,”aaa”) |
| path.sep | 逐个分割路径 | a= ‘C:\\Windows\\System32\\calc.exe’ a.os.path.seq |
| path.getsize() | 获取文件的大小 | os.path.getsize(a) |
import osprint(os.getcwd()) #打印当前所在位置os.chdir(r'D:\Book') #进入指定位置totalsize = 0for filename in os.listdir(r"C:\Windows\System32"): #获取文件夹下的所有文件totalsize = totalsize + os.path.getsize(os.path.join(r'C:\Windows\System32',filename)) #计算该文件夹下的所有文件的内存print(totalsize)
常用的path判断操作
| 方法 | 作用 | 用法 |
|---|---|---|
| path.isabs() | 判断是否为绝对路径,不管文件是否存在 | |
| path.isdir() | 判断是否为文件夹,并且判断文件夹是否存在 | |
| path.isfile() | 判断是否为普通文件 | |
| path.islink() | 判断是否为软链接 | |
| path.ismount() | 判断是否为挂载点 |
pickle模块
把数据写入文件时,常规的文件方法只能把字符串对象写入。其他数据需先转换成字符串再写入文件。当用pickle方法读取时也是以字典形式。
存储与写入数据
import pickle #导入pickle文件user = {'name':'tom','age':"20"} #创建一个字典with open('wuhu.txt','wb') as f:pickle.dump(user,f) #使用dump方法存储数据,此时导入的数据在文本中是一串代码,而不是所见即所得的。with open('wuhu.txt','rb') as f:adict = pickle.load(f) #使用load方法读取数据并且赋值,取出时依然是字典类型print(adict)
shelve模块
利用 shelve 模块,你可以将 Python 程序中的变量保存到二进制的 shelf 文件中。 这样,程序就可以从硬盘中恢复变量的数据。shelve 模块让你在程序中添加“保存” 和“打开”功能。例如,如果运行一个程序,并输入了一些配置设置,就可以将这 些设置保存到一个 shelf 文件,然后让程序下一次运行时加载它们。
import shelve #导入模块shelfFile = shelve.open("test.data") #打开/创建数据存储文件cats = ["qwq","awa","QAQ"] #创建列表内容shelfFile["cats"] = cats #shelfFile对象中创建cats列表 内容为cat列表的内容shelfFile.close() #关闭shelfFile = shelve.open("test.data") #此时再打开存储文件print(shelfFile['cats']) #打印出内容shelfFile.close()
要利用shelve 模块读写数据,首先要导入它。调用函数shelve.open()并传入一个文件 名,然后将返回的值保存在一个变量中。可以对这个变量的 shelf 值进行修改,就像它是 一个字典一样。当你完成时,在这个值上调用close()。这里,我们的shelf 值保存在shelfFile 中。我们创建了一个列表cats,并写下shelfFile[‘cats’] =cats,将该列表保存在shelfFile 中, 作为键’cats’关联的值(就像在字典中一样)。然后我们在shelfFile 上调用close()。
ZIPFile模块
你可能熟悉 ZIP 文件(带有.zip 文件扩展名),它可以包含许多其他文件的压缩 内容。压缩一个文件会减少它的大小,这在因特网上传输时很有用。因为一个 ZIP 文 件可以包含多个文件和子文件夹,所以它是一种很方便的方式,将多个文件打包成一 个文件。这个文件叫做“归档文件”,然后可以用作电子邮件的附件,或其他用途。
import zipfilenewzip = zipfile.ZipFile('new.zip','w')#创建压缩包名称newzip.write('123.txt',compress_type=zipfile.ZIP_DEFLATED) #创建压缩包newzip.extractall() #解压全部文件newzip.extract('123.txt',"c:\\") #解压指定文件到指定位置newzip.close()
字符串
fromat()方法格式
就是给变量添加一个{},使得通过format方法,可以将字符添加进去。
name = "张倩"age = 25string1 = "姓名: {} \n年龄: {}"print(string1.format(name,age))姓名: 张倩年龄: 25
甚至可以设置顺序
name = "张倩"age = 25string1 = "姓名: {1} \n年龄: {0}"print(string1.format(age,name))姓名: 张倩年龄: 25
甚至指定名称进行赋值
name = "张倩"age = 25weight = 100string1 = f"姓名: {name} \n年龄: {age} \n体重: {weight}kg"print(string1.format(name=name,age=age,weight=weight))
f-string()
将上面的字符串中的变量名直接带入
name = "张倩"age = 25print(f"姓名: {} \n年龄: {}")姓名: 张倩年龄: 25
字符串的常见操作
1.find字符串查找
查找字符串中是否包含某字符串,并且输出首次出现的位置
str.find(sub[,strat[,end])
word = 't'string = "nuttertools"result = string.find(word)print(result)2
2.replace字符串替换
将当前字符串中的制定子串替换成新的子串
word = 't'string = "nuttertools"result = string.replace(word,"T")print(result)nuTTerTools
字符串的分割与拼接
1.split字符串切割
按照指定分隔符对字符串进行分割,返回由分割后的子串组成的列表
juzi = "Any harvest is not a coincidence, but daily efforts and persistence."print(juzi.split()) #用空格分割print(juzi.split("a")) #用字符“a”切割print(juzi.split("a",2))#用字符“a”切割两次
2.join字符串拼接
将指定字符串挨个插入到其他字符串中拼接成一个新的字符串
w = "-"str1 = "Python"print(w.join(str1))P-y-t-h-o-n#当然我们还可以使用 + 来拼接x1 = "pyt"x2 = "hon"print( x1 + x2 )python
删除字符串的指定字符
| 方法 | 语法格式 | 功能说明 |
|---|---|---|
| strip() | str.strip(x) | 删除字符串头部和尾部的指定字符 |
| lstip() | str.lstip(x) | 删除字符串头部的指定字符 |
| rstrip() | str.rstrip(x) | 删除字符串尾部的指定字符 |
string1 = " Lift is short, Use Python "print(string1.strip()) #删除两边的空格print(string1.lstrip()) #删除前面的空格print(string1.rstrip()) #删除后面的空格
字符串大小写转换
| 方法 | 功能说明 |
|---|---|
| upper() | 小写转大写 |
| lower() | 大写转小写 |
| capitalize() | 只有该字符串首字母大写,其余全部小写 |
| title() | 每个单词的首字母大写 |
str1 = "i'm your father,WUHU"print(str1.upper())print(str1.lower())print(str1.capitalize())print(str1.title())I'M YOUR FATHER,WUHUi'm your father,wuhuI'm your father,wuhuI'M Your Father,Wuhu
字符串对齐
| 方法 | 语法格式 | 功能说明 |
|---|---|---|
| center() | str.center(10,”-“) | 返回长度为10的字符串,字符居中显示用”-“填补 |
| ljust() | str.ljust(10,”-“) | 返回长度为10的字符串,字符左对齐显示用”-“填补 |
| rjust() | str.rjust(10,”-“) | 返回长度为10的字符串,字符右对齐显示用”-“填补 |
str1 = "Hello python"print(str1.center(15,"-"))print(str1.ljust(15,"="))print(str1.rjust(15,"*"))--Hello python-Hello python===***Hello python
字符串的特殊操作
单引与双引号中的转义字符
stu = "I'm stu"print(stu)#I'm stustu = 'I\'m stu'print(stu)#I'm stustu = "Jason said \"I like you\"".print(stu)#Jason said "I like you"
字符串截取
str = "liaowuhu"print(str[2]) #取单个字符print(str[1:]) #取第2个之后的全部字符print(str[1:5]) #取第2到6个字符print(str[0::3]) #取第1到之后的全部字符,每次跳3print(str[:7:3]) #取第8个之前的全部字符,每次跳3print(str[0:8:2]) #取第1到8个个字符,每次跳2
字符串的一些用法
#字符串的链接print(str + ',你好') #直接添加字符print(str,",芜湖~") #直接添加字符,默认会有个空格#字符串的复制print(str*3) #将字符str 复制3个并打印。
转义字符
print('wewqe\nqwe') #\n 会给字符回车print(r'wewqe\nqwe') #在前面加个r 会取消全部的转义字符
字符串高级用法
| 代码 | 函数用法 | 代码实例 |
|---|---|---|
| len | 获取字符串长度 | print(len(s)) |
| find | 查找指定内容是否在某位置中 | print(s.find(“a”)) |
| startswith/endswith | 判断字符串是否以xxx开头/结尾 | print(s.startswith(“c”)) |
| count | 计算出现次数 | print(s.count(“i”)) |
| replace | 替换字符 | print(s.replace(“c”,”C”)) |
| split | 通过参数的内容切割字符串 | print(s.split(“c”)) |
| upper/lower | 将字符串中的大小写替换 | print(s.upper()) |
| strip | 去除空格 | print(s.strip()) |
| join | 字符串拼接 | print(s.join(“1a”)) |
| isdigit | 判断字符串是否全为数字 | print(s.isdigit()) |
| capitalize | 把字符串第一个字符大写 | print(s.capitalize()) |
| islower/isupper | 判断是否全为小写/大写 | print(s.islower) |
| isalpha/isalnum | 判断是否全为字母/全为大小写 | print(s.isalpha()) |
| center | 把字符串居中,多余的用空格填补 | print(s.center(10)) |
循环语句
for循环
for i in range(5): #从0开始到4,每次加1print(i)#range():范围for i in range(0,10,3): #从0开始每次加3,峰值为10print(i)for i in range(-10,-100,-30): #哪怕是负数都可以print(i)name = 'liao'for x in name:print(x,end='\t') #是字符的话,会逐个打印字符串内容a = ["aa","bb","cc"] #列表也可以自动遍历for i in a: #遍历列表的字符print(i)for i in range(len(a)): #遍历列表的数量+字符print(i,a[i])
while循环
i = 0while i<5:print("当前是第%d次循环"%(i+1))print("i=%d"%i)i+=1
1-100求和
i = 1sum = 0while i <= 100:sum += ii += 1print(sum)
while中的else
当跳出while循环时,会执行的命令。
count = 0while count < 5:print(count,"small than 5")count += 1else:print(count,"no small than 5")
break,continue和pass
break:跳出for,while循环
continue:跳过当前循环,进入下一个循环
pass:空语句,常用来当做占位符,不做任何事
1-50偶数的和
i = 0sum = 0while i <= 50:i += 1if i%2==1:continuesum += iprint(sum)
列表,元祖,字典
列表
List
- 列表可以完成大多数集合类的数据结构实现,列表中元素的类型可以不相同,他支持数字,字符,包括嵌套。
- 列表卸载方括号[]之间,用逗号分隔开的元素列表。
- 列表索引开头是以0开始,末尾是以-1开始。
- 列表可以使用 + 操作服进行拼接,用 * 表示重复。
- 当我们获得多个数据的时候,那么我们可以将它储存到列表中,然后直接列表访问。
#打印namelistnamelist = ["里奥",'liao',123,'test',1.213]print(namelist[0])print(namelist[3])for name in namelist: #for循环遍历print(name)print(len(namelist))length = len(namelist) #获得长度值赋给lengthi = 0while i < length:print(namelist[i])i += 1
增删改查
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 【增】新增一个数据到列表尾部 | append | list.append(‘芜湖’) |
| 【增】在指定位置插入 | insert | list.insert(1,3) |
| 【增】将一个列表的元素添加到另一个列表 | extend | list.extend(a) |
| 【删】直接删除某个值,有重复的删掉第一个 | remove | list.remove(‘里奥’) |
| 【删】删除指定位置的一个元素 | del | del namelist[2] |
| 【删】删除列表中的一个元素,默认最后一个 | pop | list.pop(1) |
| 【改】直接修改执行下标进行修改 | list[1] | namelist[1] = “test” |
| 【改】修改范围内的数据,数据不够.会删除后面数据 | list[1:3] | list[1:3]=”123”,7.3 |
| 【查】判断是否有某个值 | in | if x in list: |
| 【查】判断是否没有某个值 | not in | if x not in list: |
| 【清空】直接清空列表,但是列表还在 | clear | list_one.clear() |
常用操作
index:查找第一次出现的下标,并且告诉你在列表中的位置。找不到就报错
哪怕设置寻找范围,数值依然不会变。
a = ["a","as","e3","wda","das","sadc"]print(a.index("wda",2,5))#3
count:统计出现的次数
a = ["a","as","e3","wda","das","sadc","a","a"]print(a.count("a"))#3
reverse:将列表所有元素反转
a = ["a","as","e3","wda","das","sadc","a","a"]a.reverse()print(a)#反转输出
sort:排序输出
a = [1,213,34789,67,590,556,423,316,24,6,93]a.sort() #正序排序print(a)a.sort(reverse=True) #倒叙排序print(a)
二维数组
schoolName = [['123',123],[123,676],["12312","56756"]]print(schoolName[1][0])
实例:
import randomoffices = [[],[],[]]names = ["1","2","3","4","5","6","7","8"]for name in names:index = random.randint(0,2)offices[index].append(name)i = 1for office in offices:print("office:%d number:%d"%(i,len(office)))i+=1for name in office:print("%s"%name,end="\t")print("\n")
元组
tuple与list类似,不同之处在于tuple的元素不能修改。tuple写在小括号里,元素之间用逗号隔开。
元祖的元素不可变,但可以包含可变对象。如list
tup1 = ()print(type(tup1)) #输出tupletup2 = (123) #inttup3 = (123,) #tupletup4 = (123,48,16,"aaa") #tupleprint(tup4(0)) #123print(tup4(-1)) #aaaprint(tup4(1:3)) #48,16,aaa
增:
- 两个元祖添加,并且赋值给另一个元祖
tup1 = (123,1232,312)tup2 = ("WQe","WDs","jy")tup = tup1+tup2#(123,1232,312,"WQe","WDs","jy")
删:
- def直接删除整个元祖
tup1 = (123,123,54)del tup1print(tup1) #报错
改:
- 不支持直接赋值修改
tup1=(123,12312,12312)tup1[0] = 123 #这是错误的
字典
- 字典是无序的对象集合,使用键-值(key-value)存储,具有极快的查找速度。
- 键(key)必须使用不可变类型
- 同一个字典中,键(key)必须是唯一的
- 爬虫中经常使用字典。
字典的创建
info = {"name":"liao","age":19} #定义字典print(info["name"]) #字典的访问print(info.get["gender","没有这个键"])#如果没有这个键,则返回指定字符
dict创建
通过字符/列表/数字创建,并且必须是两个字符才行。字符串“ab”都必须是两位,哪怕是双数都不行。
x = dict(['ab',('name','tom'),['age','20']])print(x){'a': 'b', 'name': 'tom', 'age': '20'}
fromkeys创建
如果一堆数值有的一个key是相同的,就用fromkeys
y = {}.fromkeys(("tom","jerry","bob"),19)print(y){'tom': 19, 'jerry': 19, 'bob': 19}
字典的一些特殊用法
关于循环
在列表中,使用循环遍历会一次性遍历全部的数值。但是字典则不一样。
info = {"name":"liao","age":19}print("liao" in info) #False 因为这个in匹配的是键值print("name" in info) #True name是键值for i in info:print(i,info[i])name liaoage 19
关于字符引用
info = {"name":"liao","age":19}print("%s is %s years old" %(info['name'],info['age'])) #这样很麻烦print("%(name)s is %(age)s years old" %info) #字典的特殊用法
字典的函数
- len() 返回字典中元素的数目
- hash() 虽然不是为字典设计,但是可以判断是否能称为字典的键 | 函数与方法 | 作用 | 用法 | | —- | —- | —- | | get()【查】 | 括号中写入键值,获取键值的数值,并且没数据时不会报错 | get(‘键值’,’返回值’) | | keys()/values()【查】 | 只获得字典中的键值/数值 | s.keys()/s.values | | items()【查】 | 同时获得键值对,并且转为列表形式 | s.items() | | setdefault()【增】 | 直接输入键值对来添加 | s.setdefault(“name”,”age) | | dict()【增】 | 通过字符/列表/数字创建,并且必须是两个字符才行 | dict([“ab”,[“qwq”,”123”]]) | | fromkeys()【增】 | 将一堆键值设置同一个数值 | {}.fromkeys = ((“tom”,”liao”),19) | | del()【删】 | 直接删除字典 | del s | | clear()【删】 | 清空字典中的键值对 | s.clear | | pop()【删】 | 删除其中一个键值对,并且写的是键值 | s.pop(“name”) | | popitem()【删】 | 随机删除一个键值对 | s.popitem |
增删改查
增:
直接添加就好了
info = {"name":"里奥","age":18}newID= input("请输入学号:")info["id"]=newIDprint(info["id"])print(info)#10#{'name': '里奥', 'age': 18, 'id': '10'}
或者使用setdefault()
info = {"name":"里奥","age":18}info.setdefault("gender","男")
删:
- del 删除。删除的是全部键值队。
- clear 清空。将全部键值队清空,但是字典还在。
- pop(“字典变量”) 删除该字典变量和对应的键值
- popitem(“字典变量”) 随机删除键值
改:
直接修改
info = {"name":"里奥","age":18}info["age"] = 20print(info["age"])
查:
- info.keys() #列出所有的键
- info.values() #列出所有的值
- info.items() #列出所有的项,每个键就是一个元祖
info = {"name":"里奥","age":18,"id":1}print(info.keys()) #列出所有的键print(info.values()) #列出所有的值print(info.items()) #列出所有的项,每个键就是一个元祖#打印遍历for key,value in info.items():print("key=%s,value=%s"%(key,value))
枚举函数,同时获得下标和数值
mylist = ["a","b","c","d","e"]for i,x in enumerate(mylist):print(i+1,x)
set集合
set和dict类似,也是一组key的组合,但是不存储value。由于key不能重复,所以在set中,没有重复的key。会去除重复,所以常被用来去重操作。
set是无序的,重复元素在set中自动被过滤。
| 常见方法 | 说明 |
|---|---|
| add(x)【增】 | 向集合添加元素x,x若存在则不做处理 |
| update()【增】 | 如果是字符逐个字添加,如果是元祖则逐个词添加 |
| remove(x)【删】 | 删除集合中的元素x,如果不存在抛出异常KeyError |
| discard(x)【删】 | 删除集合中的元素x,如果不存在则不做处理 |
| pop()【删】 | 随机删除集合中的元素,同时删除该元素,集合为空抛出异常 |
| clear()【删】 | 清空合集 |
| copy() | 复制集合,返回值为集合 |
| isdisjoint(T) | 判断集合与集合T是否没有相同的元素,没有返回Ture,有则返回False |
| a.issupperset(b) | a集合是否为b集合的超集(a完全包含了b) |
| b.issubest(a) | b集合是否为a集合的字集(b完全被包含了a) |
| a.intersection(b) | a与b的交集 |
| a.union(b) | a与b的并集 |
| a.difference(b) | a与b的插补 |
集合的特殊用法
交集,并集,插补
aset = set('qwer') #设置集合bset = set('qwqx')print(aset)print(bset)print(aset & bset) #计算交集print(aset - bset) #插补操作{'q', 'r', 'e', 'w'}{'q', 'x', 'w'}{'q', 'w'} #交集{'q', 'w', 'x', 'e', 'r'} #并集,数值顺序是随机的{'e', 'r'} #插补,在a中有但是b中没有的
函数
Python中的函数分为以下几种类型:
- 内建函数
- print,input这些已经给我们写好的
- map,reduce高阶函数
- 用户自定义函数
- 通过def,lambda关键字构造的函数
- 第三方工具包中的函数
自定义函数关键字
- 在Python中用关键字def声明函数,后面跟函数名和小括号,括号内可以放置所需参数
- def定义的函数,是我们平时所说的函数,也是最常用的。
- 使用lambda定义的函数,被称之为匿名函数
- 比较简洁,适用一些小功能场景,并且比较吃技术能力
def add(a,b):"""输入a和b的参数,进行相加"""return a+b #返回值为a与b的和print(add(10,20))30
函数的参数
函数的参数分为以下几种形式:
- 必备参数:必备参数须以正确的顺序传入参数,调用时的数量必须和声明时的一样
function(a,b)
- 关键字参数:函数调用时使用等号赋值的形式传入参数
function(a=1,b=3)
- 默认参数:调用函数时,缺省参数的值如果没有传入,则被认为时默认值
def add(a=10,b=20):return a+bfunction(15)function(15,30)3545
- 不定长参数:有时候可能会需要一个函数能处理更多参数,我们不能写非常多个。使用不定长参数即可。
*arg,**kwargs:加了 星号 的变量会存放所有未命名的参数,args为元祖,而kwargs会存放命名参数,即形如key=value的参数,kwargs为字典。
def add(*a):print(a)add(1,2,3,4,5,6,7,8)[1,2,3,4,5,6,7,8]
参数的顺序:def func(必备参数,关键字参数,默认参数,不定长参数)
全局变量和局部变量
name = "吴彦祖"def func():name="小吴"print(name)func()print(name)小吴吴彦祖
在函数中的局部变量中添加global name,就是使用全局变量。
匿名函数
常用lanbda来创建匿名函数
- lambda只是一个表达式,简单
- lambda不是一个代码块,只能写有限的逻辑
- lambda函数有自己命名空间,且不能访问自有参数之外或全局命名空间里的参数
lambda 参数:函数体lambda x:x+1
- 使得代码更简洁
x=3l = [lambda x: x**2,lambda x:x**3,lambda x:x**4]for i in l:print(i(x))92781list1 = [{"name": "liao4", "age": 18}, {"name": "liao9", "age": 19}, {"name": "liao3", "age": 20}]def GetKey(x):return x["name"]x = sorted(list1,key=lambda x:x["name"])print(x)
Py函数的特点
- 函数本身可以作为参数和返回值
- 函数就是面向过程的程序设计的基本单元
- 函数式编程思想更接近数学计算
- 函数式编程就是一种抽象程度很高的编程范式
- 函数式编程的一个特点就是允许把函数本身作为参数传入另一个函数,还允许返回一个函数
偏函数
当我们写一个参数比较多的函数时,如果有些参数,大部分场景下都是某一个固定值,那么为了简化使用,就可以创建一个新函数,指定我们要使用的函数的某个参数,为某个固定的值;这个新函数就是”偏函数”。
def xyz(a, b, c, d=2):print(a + b + c + d)xyz(1, 4, 7)import functoolsxyz1 = functools.partial(xyz, c=10)xyz1(1, 4)
高阶内建函数
既然变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数
高阶函数有以下特点:
- 变量可以指向函数
- 可以传入函数
变量指向函数
x = abs(10)print(x)10f = absprint(f(111))111
函数中传入函数
def add(x,y,z):return f(x)+f(y)print(add(5,-6,abs))11
map函数
内建map函数,接收两个参数一个是函数,一个是Iterable对象
def f(x):return x**2r = map(f,[1,2,3,4,5,6] #前面写函数,后面写数值list(r)1,4,9,16,25,36
reduce函数
闭包
reduce把一个函数作用在一个序列[x1,x2,x3]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
f(f(f(x1,x2),x3),x4)
from functools import reducedef fn(x,y):return x *10 + yreduce(fn,[1,3,5,7,9])13579
filter函数
和map函数类似,也是一个函数一个序列。和map不同的是,filter把传入的函数依次作用于每个元素,然后根据返回值是true还是false决定保留还是丢弃该元素。
def not_empty(s):return s and s.strip()list(filter(not_empty,["A","B",None,"C"," "]))["A","B","C"]
sorted函数
排序函数,通过接收一个key函数来实现自定义的排序。自定义排序。
sorted(['bob','about','Zoo'],key=str.lower)list1 = [{"name": "liao4", "age": 18}, {"name": "liao9", "age": 19}, {"name": "liao3", "age": 20}]def GetKey(x):return x["name"]x = sorted(list1,key=GetKey)print(x)
enumerate函数
返回一个由元祖构成列表。
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
user = ['tom','jerry','mariao','bob']print(list(enumerate(user)))for i in enumerate(user):print(i)for x,y in enumerate(user):print(x,y)(0, 'tom')(1, 'jerry')(2, 'mariao')(3, 'bob')0 tom1 jerry2 mariao3 bob
reversed函数
翻转列表的数值,颠倒顺序
user = ['tom','jerry','mariao','bob']print(list(reversed(user)))['bob', 'mariao', 'jerry', 'tom']
eval
num = 10result = eval("3 * num")print(result)list_str = "[1,2,3]"tuple_str = "(1,2,4)"dict_str = "{1:'wd',2:'dsad',3:'qwed'}"list_eval = eval(list_str)tuple_eval = eval(tuple_str)dict_eval = eval(dict_str)print("[list]序列数据:%s,序列类型%s"%(list_eval,type(list_eval)))print("[tuple]序列数据:%s,序列类型%s"%(tuple_eval,type(tuple_eval)))print("[dict]序列数据:%s,序列类型%s"%(dict_eval,type(dict_eval)))
eval可以不用进行强制转换,运行字符串中的程序代码。但是只能解析其中的单个字符串的信息
exec
作用和eval差不多,但是可以进行多行的字符串操作
闭包函数
在函数嵌套的前提下
内层诬数引用了外层函数的变量(包括参数)
外层函数又把内层函数当做返回值进行返回
一个函数计算一样时,但是需要内容不一样,并且多次调用,使用闭包函数就很好解决问题。
def test():a = 10def test2():print(a)return test2()test()10def line_config(connect, length):def line():print("-" * (length // 2) + connect + "-" * (length // 2))return lineline1 = line_config("wuhu", 10)line1()line1()line1()line2 = line_config("wuhu1", 15)line2()line2()line2()-----wuhu----------wuhu----------wuhu------------wuhu1--------------wuhu1--------------wuhu1-------
可以使用nolocal将变量设置为非内部的。
闭包案例/装饰器
def checkLogin(func):def Check():print("登录验证...")func()return Check@checkLogin # fss = checkLogin(fss)# 等同于 函数名 = 闭包函数(函数名)def fss():print("发说说")@checkLogindef ftp():print("发图片")indexNumber = 2if indexNumber == 1:fss()else:ftp()
def ccc(char):def bbb(func):def inner():print(char * 30)func()return innerreturn bbb@ccc("*")def aaa():print(666)aaa()
生成器
是一个特殊的迭代器,迭代器抽象层级更高。
迭代器的特性:
- 惰性计算数据,节省内存
- 能够记录状态,并通过next()函数访问下一个节点
- 具备可迭代特性
但是如果打造一个自己的迭代器,比较复杂。
#创建方式1num = (i for i in range(0,100) if i % 2 == 0)print(num) #<generator object <genexpr> at 0x000001D5EA4E9B60>print(next(num)) # 0print(next(num)) # 2for i in num:print(i) # 4 6 8 10...# 创建方式2def test():print("xxx")yield 1print("a")yield 2print("b")yield 3print("c")yield 4print("d")yield 5print("e")a = test()print(a)print(next(a))print(next(a))<generator object test at 0x000001665D6F9A10>xxx1a2
yield,可以去阻断当前的函数技行,然后,当使用next()函数,或者,next(),都会让函数继续执行,然后,当执行到下一个yield语句的时候,又会被暂停
操作方式
send() 方法
send方法有一个参数,指的是上一次被挂起的yield语句的返回值
注意第一次调用 t.send(None)
def test():print("xxx")res = yield 1print(res)print("123")res2 = yield 2print(res2)g = test()print(g.__next__())print(g.send("test123"))xxx1test1231232
close()方法
关闭生成器,本质是直接迭代到最后一个,也就是无法再调用。并不是重新回到开头
def test():yield 1print("aaa")yield 2print("bbb")yield 3print("ccc")yield 4print("ddd")g = test()print(g.__next__())print(g.__next__())g.close()
注意:如果碰到return 会直接终止 抛出StopIteration异常提示。想多次遍历,再重新创建一次即可。
递归函数
函数内部中,继续调用函数。
概念:递归,回归。
def test(n):if n == 1:return 1#n * n-1return n * test(n-1)print(test(9))
文件操作
打开/创建文件
f = open("test.txt","w") #打开文件,文件不存在,就新建。f.close()
访问模式
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则 将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
给文件内容编辑
常用readline多使用几次,另外两个不安全并且占用内存大
#写入f = open("test.txt","w")f.write("芜湖~~")f.writelines()f.close() #必须执行关闭,才会保存你的操作。#读 开始时定位在文件头部,每次执行一次向后移动指定字符数f = open("test.txt","r")content = f.read(3) #读取5个字符print(content)f.close()#一次读取全部信息f = open("test.txt","r")content = f.readlines() #读取全部内容为列表i = 1for temp in content:print(i,temp)i+=1f.close()#读取单行信息f = open("test.txt","r")content = f.readline()print(content)content = f.readline()print(content)content = f.readline()print(content)content = f.readline()print(content)f.close()
文件的定位读写
tell
返回文件的当前位置,即文件指针当前位置。想获得当前读取位置时使用
with open("123.txt",encoding="utf-8")as f:print(f.tell()) #获取当前文件读取位置print(f.read(5)) #移动文件读写位置print(f.tell()) #读取当前位置0#文本5
seek
方法用于移动文件读取指针到指定位置。重新从头读取文件时,或者冲其他位置读取文件时使用。
with open("123.txt",encoding="utf-8")as f:print(f.name)print(f.readline())print(f.seek(0,0))print(f.readline())
文件的序列化和反序列化
默认情况下,我们只能将字符串写入到文件中。所以无法写入对象。不过可以通过序列化写入到文件中。
序列化的两种方式
import json
dumps():将对象转换为字符串
import json#导入json模块到文件中,序列化f=open('test.txt',"w")#创建文件name = ["QWeqw",123123,"xcawe"]#定义一个列表name_list = json.dumps(name)#将python对象变成json的字符串print(type(name_list))f.write(name_list)#将转换后的对象写入到文件中f.close()
dump():在将对象转换为字符串的同时,指定一个文件夹的对象,然后把转换后的字符串写入到这个文件里。
import json#导入json包f = open('test.txt','w')name_list = ["wqexz",'vwer',12321]json.dump(name_list,f)#将name_list转换为str,并且写入到文件f中f.close()
反序列化
将json字符串转换为python对象
json.loads()
import jsonfp = open("test.txt","r")a = fp.read()#读取文件print(a)print(type(a))#读取文件类型 strb = json.loads(a)#将json字符串转换为python对象print(type(b))fp.close()
json.load()
import jsonfp = open("test.txt","r")a = json.load(fp)#直接写文件print(a)print(type(a))fp.close()
错误与异常
错误:不可预料,不可知的。当出现错误,后面代码无法继续执行。
异常:可预料,能改变的。
异常捕获
#单个异常捕获try:print("-"*30)f=open("123.txt","r") #只读模式,打开文件。此时文件不存在,会报错print("*"*30)except IOError: #如果是IOError的报错pass #捕获异常,使用pass占位报错。#多个异常捕获try:print(num)except (NameError,IOError): #将可能的错误都放到小括号中print("出现了名称错误")
错误信息提示
try:print(num)except (NameError,IOError) as result: #将错误提示赋值给resultprint("出现了名称错误")print(result)#name 'num' is not defined
Execption
Exception 所有异常的父类,不知道写哪个异常,用它就对了。
finally与嵌套
finally:不管有没有发生异常,都是会执行的。
import timetry:f = open("123.txt","r") #尝试读取123.txttry:while True: #一直循环content = f.readline() #content等于文件的行if len(content) == 0: #如果没有值,当无法被赋值,则退出breaktime.sleep(2)print(content)finally:f.close()print("文件关闭")except Exception:print("发生异常")finally:print("文件关闭")
| 异常名称 | 描述 |
|---|---|
| UserWarning | 用户代码生成的警告 |
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
自定义异常
这里并不是我们手写异常,而是当写的数据不符合预期时报一个异常
raise语句
想要引发异常,最简单的形式就是输出关键字raise,后面跟要引发的异常的名称。
执行raise语句时,会创建指定的异常类的一个对象
raise语句还可以指定对异常对象进行初始化的参数
raise ValueError('无效的数字')Traceback (most recent call last):File "D:\code-py\pyan\ceshi.py", line 1, in <module>raise ValueError('无效的数字')ValueError: 无效的数字
断言异常
断言是一句必须等价于布尔值为真的判定
此外,发生异常也意味着表达式为假
assert 10 > 100,"wrong"Traceback (most recent call last):File "D:\code-py\pyan\ceshi.py", line 3, in <module>assert 100 > 1000,'wrong'AssertionError: wrong
例子
def get_info(age,name):if not 0 < age < 120:raise ValueError("无效年龄(1-119)")else:print("%s的年龄为%s"%(name,age))def get_info2(age,name):assert 0 < age < 120,'无效的年龄'print("%s的年龄为%s" % (name, age))if __name__ == '__main__':try:get_info2(200,"liao")except (ValueError,AssertionError) as e:print('Error',e)exit()print('Done')
RE正则表达式
1.用 import re 导入正则表达式模块。
2.用 re.compile()函数创建一个 Regex 对象(记得使用原始字符串)。
3.向 Regex 对象的 search()方法传入想查找的字符串。它返回一个 Match 对象。
4.调用 Match 对象的 group()方法,返回实际匹配文本的字符串。
import re #导入包phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d') #设置正则的格式, \d 代表的是数字mo = phoneNumRegex.search('My number is 114-514-800') #mo 等于 以该正则格式搜索该字符print(mo.group()) #数值在group中114-514-800
利用括号分组 ()
一个括号才算分了一个组
import rephoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d-\d\d\d)')mo = phoneNumRegex.search('My number is 114-514-800')print(mo.group(0))print(mo.group(1))print(mo.group(2))print(mo.groups())114-514-800114514-800('114', '514-800')
利用管道匹配多个分组 |
优先匹配前面的字符,此时并不会重复匹配,所以匹配到一个随机就停止了。使用finadll()方法也行。
import rehero = re.compile(r"batman|spiderman") #匹配batman和spiderman,优先匹配前面的mo1 = hero.search("i am batman,not spiderman")print(mo1.group())mo2 = hero.search("spiderman is flying")print(mo2.group())batmanspiderman
假设你希望匹配’Batman’、’Batmobile’、’Batcopter’和’Batbat’中任意一个。因为所有这 些字符串都以 Bat 开始,所以如果能够只指定一次前缀,就很方便
batRegex = re.compile(r'Bat(man|mobile|copter|bat)')mo = batRegex.search('Batmobile lost a wheel')mo.group()'Batmobile'mo.group(1) #只是返回第一个括号分组内匹配的文本'mobile'。'mobile'
用问号实现可选匹配 ?
如果一个字符串可有可无,则可以使用该字符串。? 匹配0次或1次
batRegex = re.compile(r'Bat(wo)?man')mo1 = batRegex.search('The Adventures of Batman')mo1.group()'Batman'mo2 = batRegex.search('The Adventures of Batwoman')mo2.group()'Batwoman'
正则表达式中的(wo)?部分表明,模式 wo 是可选的分组。该正则表达式匹配的文本 中,wo 将出现零次或一次。这就是为什么正则表达式既匹配’Batwoman’,又匹配’Batman’。
用星号匹配零次或多次 *
*(称为星号)意味着“匹配零次或多次”,即星号之前的分组,可以在文本中出现任意次。它可以完全不存在,或一次又一次地重复。让我们再来看看 Batman 的例子。
batRegex = re.compile(r'Bat(wo)*man')mo1 = batRegex.search('The Adventures of Batman')mo1.group()'Batman'mo2 = batRegex.search('The Adventures of Batwoman')mo2.group()'Batwoman'mo3 = batRegex.search('The Adventures of Batwowowowoman')mo3.group()'Batwowowowoman'
用加号匹配一次或多次 +
*意味着“匹配零次或多次”,+(加号)则意味着“匹配一次或多次”。星号不要求 分组出现在匹配的字符串中,但加号不同,加号前面的分组必须“至少出现一次”。这不 是可选的。
batRegex = re.compile(r'Bat(wo)+man')mo1 = batRegex.search('The Adventures of Batwoman')mo1.group()'Batwoman'mo2 = batRegex.search('The Adventures of Batwowowowoman')mo2.group()'Batwowowowoman'mo3 = batRegex.search('The Adventures of Batman')mo3 == NoneTrue
用花括号匹配特定次数 {0,5}
如果想要一个分组重复特定次数,就在正则表达式中该分组的后面,跟上花括 号包围的数字。例如,正则表达式(Ha){3}将匹配字符串’HaHaHa’,但不会匹配’HaHa’, 因为后者只重复了(Ha)分组两次。
haRegex = re.compile(r'(Ha){3}')mo1 = haRegex.search('HaHaHa')mo1.group()'HaHaHa'mo2 = haRegex.search('Ha')mo2 == NoneTrue
贪心和非贪心匹配 {}
Python 的正则表达式默认是“贪心”的,这表示在有二义的情况下,它们会尽 可能匹配最长的字符串。花括号的“非贪心”版本匹配尽可能最短的字符串,即在 结束的花括号后跟着一个问号。
greedyHaRegex = re.compile(r'(Ha){3,5}')mo1 = greedyHaRegex.search('HaHaHaHaHa')mo1.group()'HaHaHaHaHa'nongreedyHaRegex = re.compile(r'(Ha){3,5}?')mo2 = nongreedyHaRegex.search('HaHaHaHaHa')mo2.group()'HaHaHa'
findall()方法
除了search方法外,Regex对象也有一个findall()方法。search()将返回一个Match 对象,包含被查找字符串中的“第一次”匹配的文本,而 findall()方法将返回一组 字符串,包含被查找字符串中的所有匹配。
import rephoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')print(phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000'))['415-555-9999', '212-555-0000']
如果在正则表达式中有分组,那么 findall 将返回元组的列表。每个元组表示一个找 到的匹配,其中的项就是正则表达式中每个分组的匹配字符串。
phoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)') # has groupsprint(phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000'))[('415', '555', '9999'), ('212', '555', '0000')]
字符分类
| 缩写字符分类 | 表示 |
|---|---|
| \d | 0 到 9 的任何数字 |
| \D | 除 0 到 9 的数字以外的任何字符 |
| \w | 任何字母、数字或下划线字符(可以认为是匹配“单词”字符) |
| \W | 除字母、数字和下划线以外的任何字符 |
| \s | 空格、制表符或换行符(可以认为是匹配“空白”字符) |
| \S | 除空格、制表符和换行符以外的任何字符 |
#
import rexmasRegex = re.compile(r'\d+\s\w+') #多个数字 单个字符 多个字母print(xmasRegex.findall('12 drummers, 11 pipers, 10 lords, 9 ladies, 1101 123,23 amm,69 skcas'))['12 drummers', '11 pipers', '10 lords', '9 ladies', '1101 123', '69 skcas']
建立自己的字符分类[^abcABC]
有时候你想匹配一组字符,但缩写的字符分类(\d、\w、\s 等)太宽泛。你可 以用方括号定义自己的字符分类。
vowelRegex = re.compile(r'[aeiouAEIOU]') #匹配aeiouAEIOUprint(vowelRegex.findall('RoboCop eats baby food. BABY FOOD.'))['o', 'o', 'o', 'e', 'a', 'a', 'o', 'o', 'A', 'O', 'O']
通过在字符分类的左方括号后加上一个插入字符(^),就可以得到“非字符类”。 非字符类将匹配不在这个字符类中的所有字符。
consonantRegex = re.compile(r'[^aeiouAEIOU]') #匹配除了aeiouAEIOU以外的print(consonantRegex.findall('RoboCop eats baby food. BABY FOOD.'))['R', 'b', 'c', 'p', ' ', 't', 's', ' ', 'b', 'b', 'y', ' ', 'f', 'd', '.', '', 'B', 'B', 'Y', ' ', 'F', 'D', '.']
插入字符和美元字符 [^开头结尾&]
可以在正则表达式的开始处使用插入符号(^),表明匹配必须发生在被查找文 本开始处。类似地,可以再正则表达式的末尾加上美元符号($),表示该字符串必 须以这个正则表达式的模式结束。
beginsWithHello = re.compile(r'^Hello') #以Hello开头endsWithNumber = re.compile(r'\d$') #以一个数字结尾wholeStringIsNum = re.compile(r'^\d+$') #以多个数字结尾
通配字符 .
在正则表达式中,.(句点)字符称为“通配符”。它匹配除了换行之外的所有字符。
atRegex = re.compile(r'.at')print(atRegex.findall('The cat in the hat sat on the flat mat.'))['cat', 'hat', 'sat', 'lat', 'mat']
用(.*)匹配所有字符
匹配任意字符
nameRegex = re.compile(r'First Name: (.*) Last Name: (.*)')mo = nameRegex.search('First Name: Al Last Name: Sweigart')mo.group(1)'Al'mo.group(2)'Sweigart'
点-星使用“贪心”模式:它总是匹配尽可能多的文本。要用“非贪心”模式匹配 所有文本,就使用点-星和问号。
nongreedyRegex = re.compile(r'<.*?>') #匹配最多文本mo = nongreedyRegex.search('<To serve man> for dinner.>')mo.group()'<To serve man>'greedyRegex = re.compile(r'<.*>') #匹配所有文本mo = greedyRegex.search('<To serve man> for dinner.>')mo.group()'<To serve man> for dinner.>'
用句点字符匹配换行
noNewlineRegex = re.compile('.*')noNewlineRegex.search('Serve the public trust.\nProtect the innocent.\nUphold the law.').group()'Serve the public trust.'newlineRegex = re.compile('.*', re.DOTALL)newlineRegex.search('Serve the public trust.\nProtect the innocent.\nUphold the law.').group()'Serve the public trust.\nProtect the innocent.\nUphold the law.'
正则表达式符号复习①
- ? 匹配零次或一次前面的分组。
- 匹配零次或多次前面的分组。
- 匹配一次或多次前面的分组。
- {n} 匹配 n 次前面的分组。
- {n,} 匹配 n 次或更多前面的分组。
- {,m} 匹配零次到 m 次前面的分组。
- {n,m} 匹配至少 n 次、至多 m 次前面的分组。
- {n,m} ?或*?或+?对前面的分组进行非贪心匹配。
- ^spam 意味着字符串必须以 spam 开始。
- spam$ 意味着字符串必须以 spam 结束。
- . 匹配所有字符,换行符除外。
- \d、\w 和\s 分别匹配数字、单词和空格。
- \D、\W 和\S 分别匹配出数字、单词和空格外的所有字符。
- [abc] 匹配方括号内的任意字符(诸如 a、b 或 c)。
- [^abc] 匹配不在方括号内的任意字符。
不区分大小写的匹配 re.I
robocop = re.compile(r'robocop', re.I)robocop.search('RoboCop is part man, part machine, all cop.').group()'RoboCop'robocop.search('ROBOCOP protects the innocent.').group()'ROBOCOP'robocop.search('Al, why does your programming book talk about robocop so much?').group()'robocop'
用 sub()方法替换字符串
正则表达式不仅能找到文本模式,而且能够用新的文本替换掉这些模式。Regex 对象的 sub()方法需要传入两个参数。第一个参数是一个字符串,用于取代发现的匹 配。第二个参数是一个字符串,即正则表达式。sub()方法返回替换完成后的字符串。
namesRegex = re.compile(r'Agent \w+')namesRegex.sub('CENSORED', 'Agent Alice gave the secret documents to Agent Bob.')'CENSORED gave the secret documents to CENSORED.'

若有收获,就点个赞吧
0 人点赞
