ELK:ES核心概念
索引
一个索引就是拥有一个拥有几分相似特征的文档的合集。比如说你可以有一个商品数据的索引,一个订单数据的索引,一个用户数据的索引。一个索引由一个名字来标识(必须全部小写字母),并且当我们要对这个索引中的文档进行索引,搜索时,都要用到这个名字
索引——数据库
映射
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。在默认配置下,ES可以根据插入的数据自动地创建mapping,也可以手动创建mapping。mapping中主要包括字段名,字段类型等!
文档
文档是索引中存储的一条条数据,一条文档是一个可被索引的最小单元。ES中的文档采用了轻量级的JSON格式数据来表示。
倒排索引和正排索引
正排索引:
一个对着一个搜索时直接通过id找到内容。但是如果要查找关键字,比如zhang san,就要遍历所有内容并进行匹配了,会非常消耗资源。
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
倒排索引:
我们将一些重复的字段和id向匹配,查找时除了可以通过id查找,还可以通过关键词查找到id再获取数据。并且极大的解决性能,效率高。
| keyword | id |
|---|---|
| name | 1001,1002 |
| zhang | 1001 |
ELK:ES的基本操作
索引的学习
查看索引
进入到Kibana网页,Dev tools ,在控制台中写入命令:
GET /_cat/indices #查看ES的索引GET /_cat/indices?v #查看索引并显示标题行号
| 标题 | 作用 |
|---|---|
| health | 健康状态 |
| status | 是否开启 |
| UUID | 索引的唯一标识 |
| pri | 主分片 |
| rep | 副本分片 |
| docs.count | 文档数量 |
| docks.deleted | 文档删除数量 |
| store.size | 存储大小 |
| pri.store.size | 主分片存储大小 |
前面带有 “.”的索引代表这是系统创建的隐藏索引。

创建索引
使用PUT命令
PUT /products #创建索引acknowledged: true #代表创建成功shards_acknowledged: true #碎片创建成功index: "products" #索引创建成功
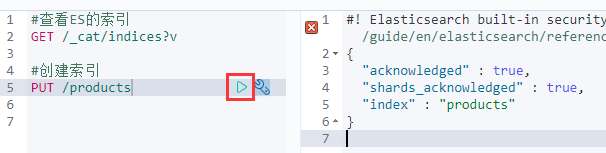
此时我们查询索引
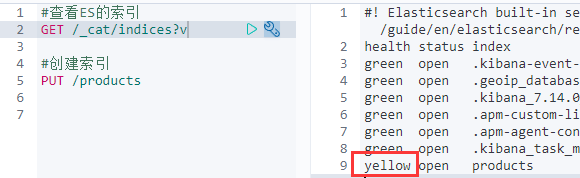
GET /_cat/indices?v
会发现我们这里的yellow,目前可以理解为,索引可以使用,但是备份的数据和索引数据在同一台机器中!不安全,但能用。
我们也有办法让我们创建的数据变成green,原理就是不创建副本,副数据块。
PUT /oders{"settings": {"number_of_shards": 1, "number_of_replicas": 0}}#创建数据时不创建副本数据块
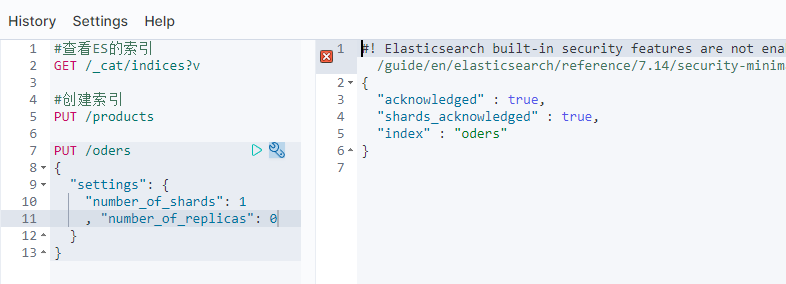
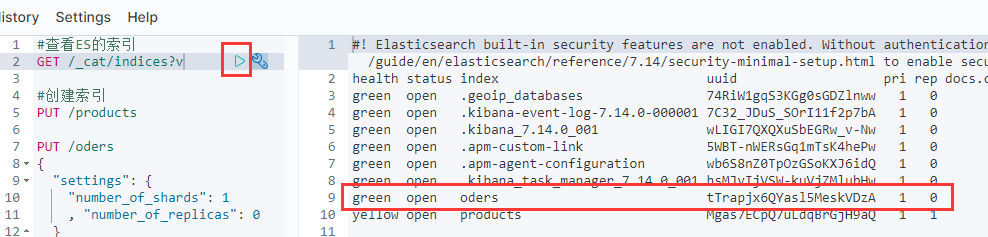
此时的oders就是green
删除索引
使用DELETE命令进行删除
DELETE /products #删除索引
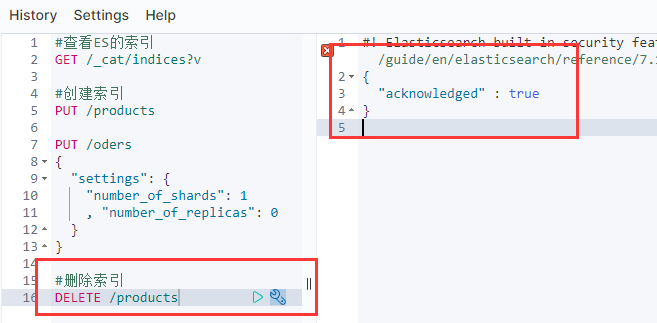
此时再查询就没有数据了哦!
注意!!!!!
ES并没有修改操作!!!!!
映射的学习
创建映射
字符串类型: keyword(关键词),text(一段文本)
数字类型: integer long
小数类型: float double
布尔类型: boolean
日期类型: date
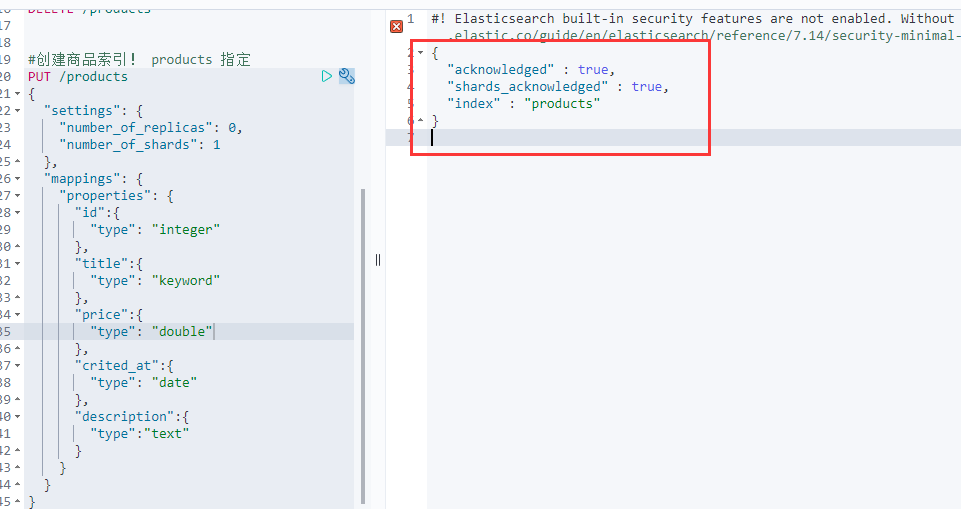
PUT /products{"settings": {"number_of_replicas": 0,"number_of_shards": 1},"mappings": {"properties": {"id":{"type": "integer"},"title":{"type": "keyword"},"price":{"type": "double"},"crited_at":{"type": "date"},"description":{"type":"text"}}}}
此时索引创建成功,里面的映射也没有问题!
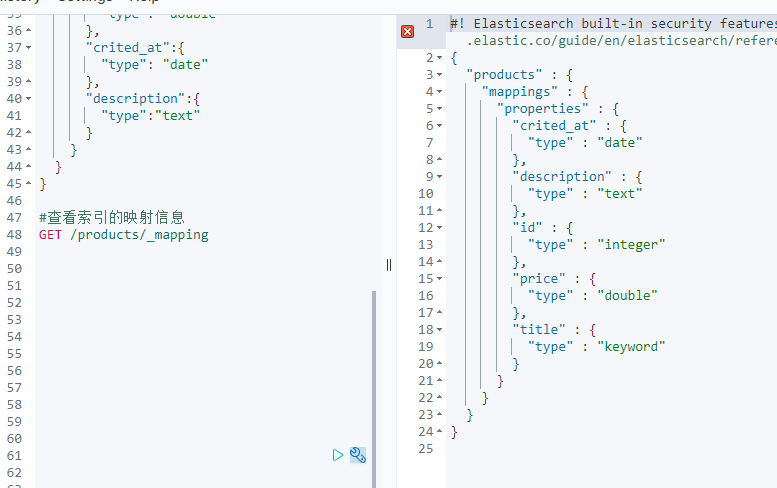
查看映射
依然使用GET语法
GET /products/_mapping #查看索引的映射信息
文档的学习
添加文档
使用post添加文档
POST /products/_doc/1{"id":1,"title": "小浣熊","price":0.5,"created_at":"2022-1-1","description": "芜湖~"}
此时就创建成功了,出现了created。不过这里我们是自己指定了ID。当然也可以让系统自动生成。
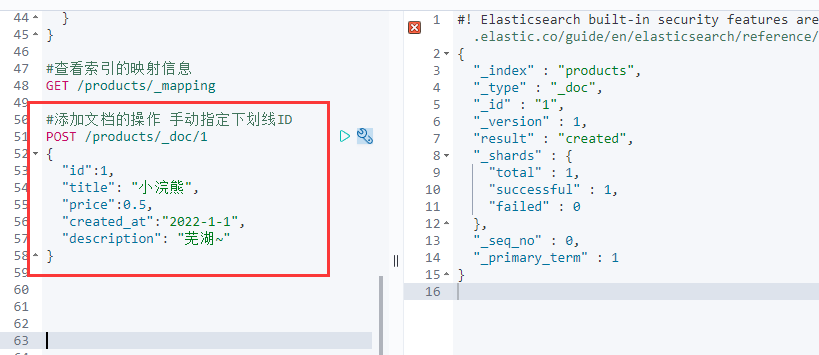
自动创建文档的id
POST /products/_doc{"title": "辣条","price":1.5,"created_at":"2022-1-2","description": "芜湖~"}
命令我们并没有输入ID,并且给”id”去掉了
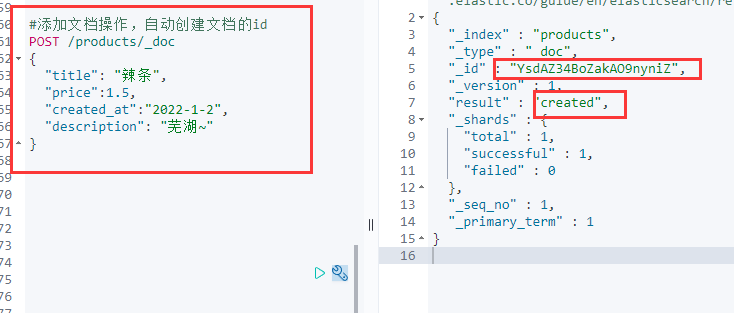
文档查询
使用GET命令,查询文档。
GET /products/_doc/Y8dHZ34BoZakAO9nkngo
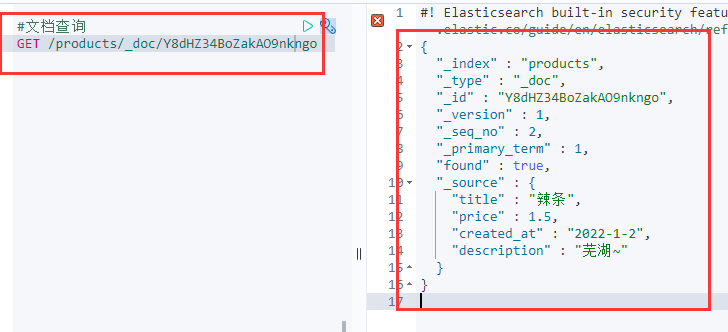
删除文档
使用DELETE命令
DELETE /products/_doc/Y8dHZ34BoZakAO9nkngo #删除文档
此时出现了deleted 关键字。并且无法再查询到文档了。
更新文档
使用PUT命令
PUT /products/_doc/1 #删除原始文档,再重新添加文档{"title":"脆司令"}GET /products/_doc/1 #查询文档
此时只有title了!!!所以该命令是删除原始文档,再重新添加文档
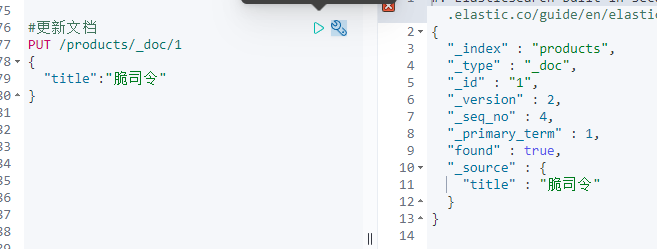
两种方法更新保留原始字段
方法1:重新传入一份
PUT /products/_doc/1 #使用PUT重新传入一份!{"id":1,"title": "脆司令","price":1,"created_at":"2022-1-1","description": "好吃!"}
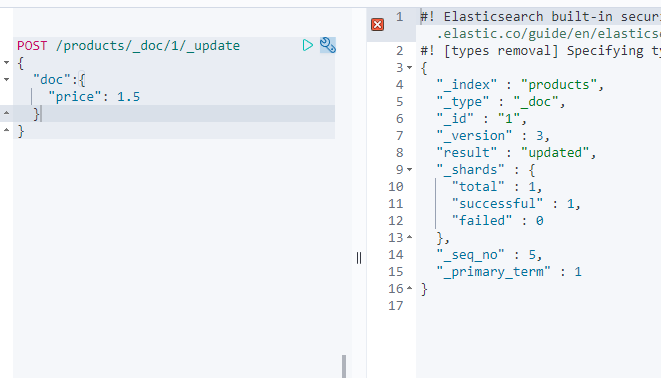
方法2:基于指定字段进行更新
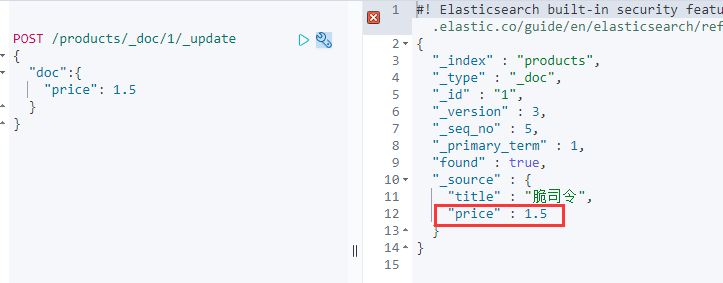
POST /products/_doc/1/_update #_update 查询并修改文档字段{"doc":{ #先查询doc中的字段"price": 1.5 #此时才能修改字段}}
price也随之变换
★文档的批量操作
有时候我们可能会同时需要添加/删除/修改多个文档映射之类的,_bulk就起作用了。
添加多个文档
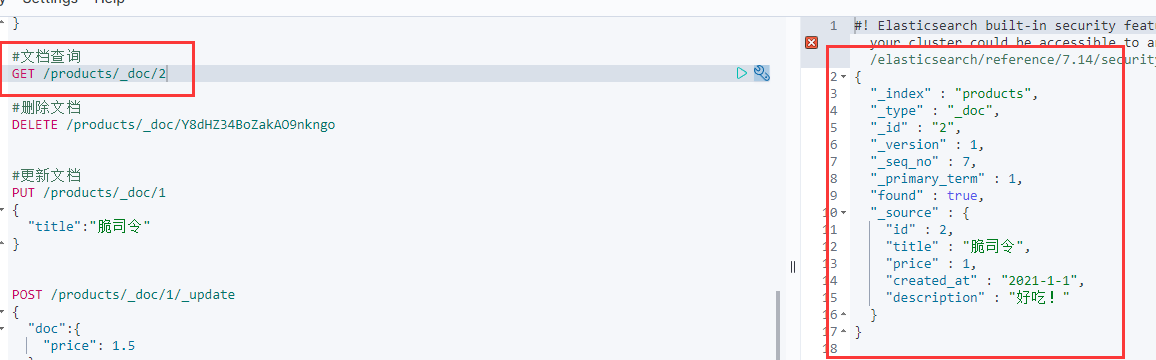
POST /products/_doc/_bulk{"index":{"_id":2}} #添加索引 id为2{"id":2,"title":"脆司令","price":1,"created_at":"2021-1-1","description":"好吃!"}{"index":{"_id":3}}{"id":3,"title":"卫龙辣条","price":2.5,"created_at":"2021-1-1","description":"好辣!"}#注意,添加数据的时候,不能有空格,"运行"旁边的扳手 可以帮我们规范格式
出现右边的参数就代表添加成功。
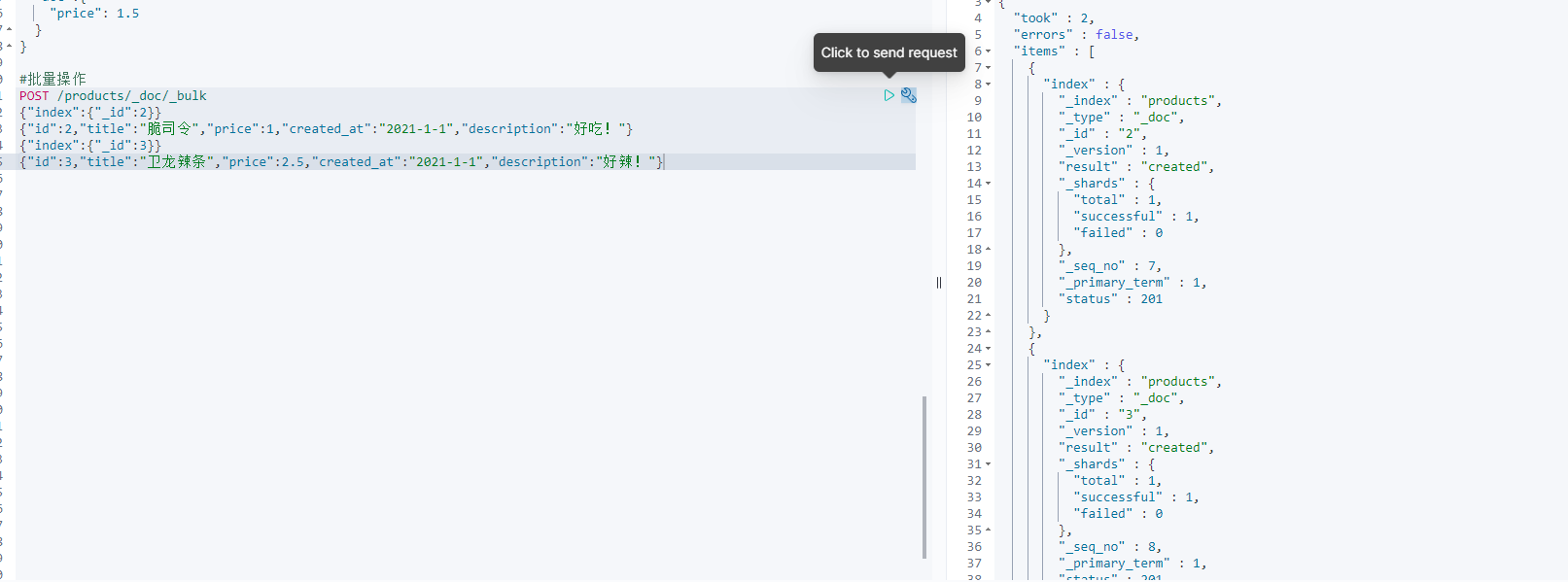
此时我们查询,也有2号文档
批量添加更新删除
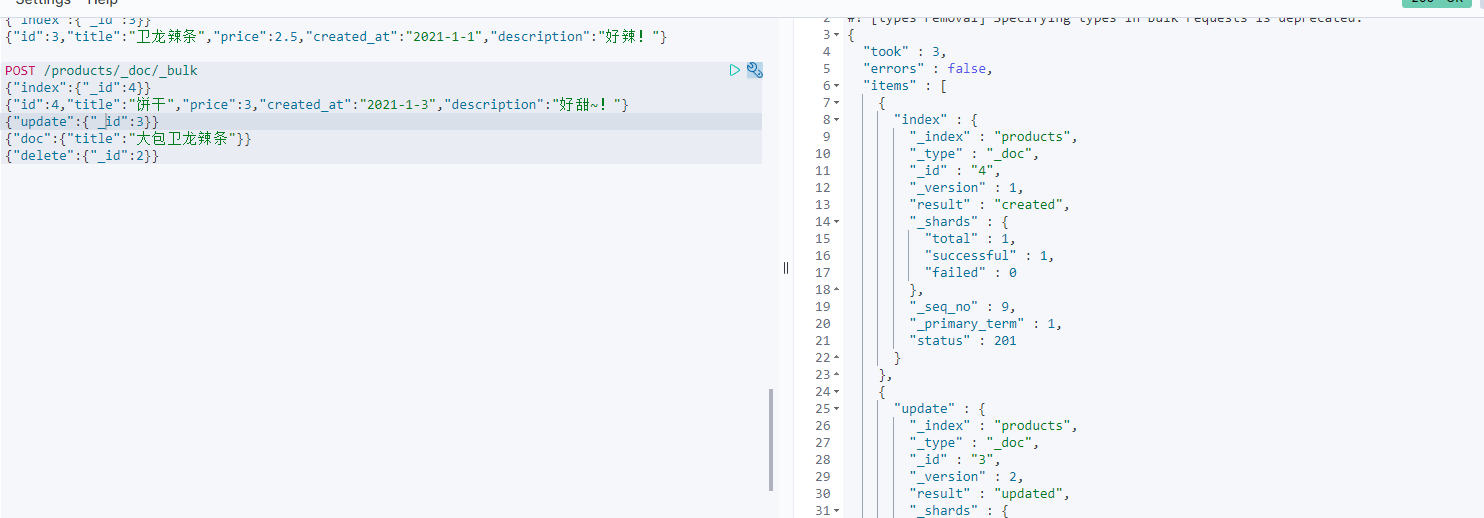
POST /products/_doc/_bulk{"index":{"_id":4}} #添加新的索引{"id":4,"title":"饼干","price":3,"created_at":"2021-1-3","description":"好甜~!"}{"update":{"_id":3}} #更新文档{"doc":{"title":"大包卫龙辣条"}}{"delete":{"_id":2}} #删除映射
ELK:ES的高级查询
说明
ES中提供了一种强大检索数据方式,这种检索方式称之为 Query DSL,利用Rest API传递JSON格式的请求体数据与ES进行互动。这种方式的丰富查询语法让ES检索变得更强大简洁。
常见检索
查询所有[match_all]
match_all关键字:返回索引中全部的文档
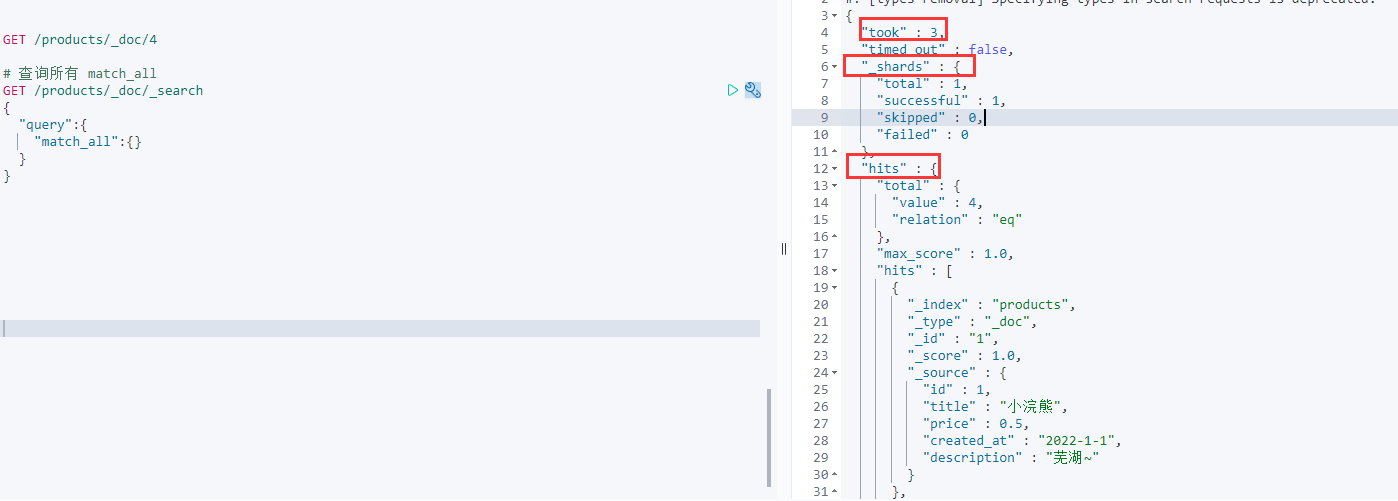
GET /products/_doc/_search{"query":{"match_all":{} #查询所有}}
took:使用时间/毫秒
shards:碎片
hits:击中/查询到的数据
关键词查询[term]
term关键字:用来使用关键词查询
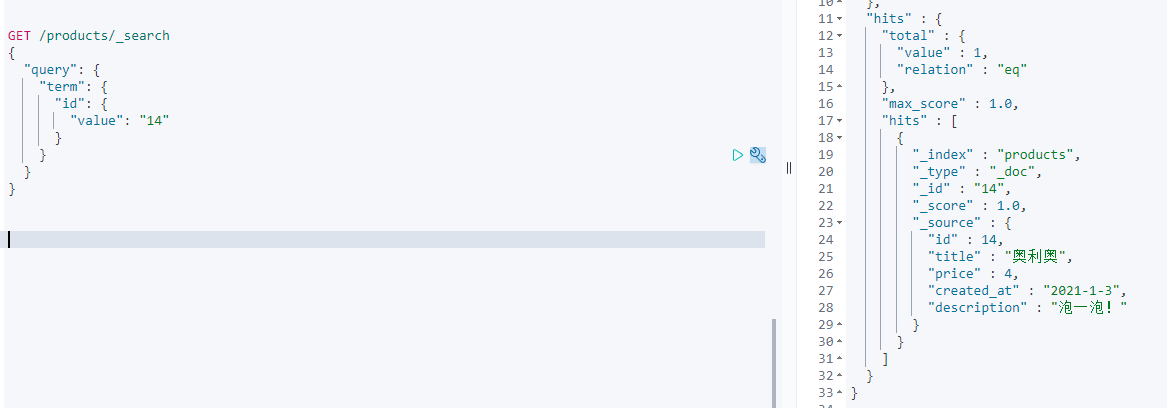
GET /products/_search{"query": {"term": { #term关键词"id": { #查询类型为id"value": "14" #查询14}}}}
keyword interger double data 类型 不分词。
text 类型 分词。默认使用es标准分词,中文单个字分词,英文单词分词。
在ES中除了text类型分词,其他都不分词。并且使用标准分词器。
范围查询[range]
range关键字:用来查询指定范围内的文档
GET /products/_search{"query": {"range": {"price": {"gte": 2, #小于等于"lte": 5 #大于等于}}}}
前缀查询[prefix]
prefix关键词:用来检索含有指定前缀的关键词的相关文档
GET /products/_search{"query": {"prefix": {"title": {"value": "饼" #我的某个开头是饼干 所以这里填写饼}}}}
通配符查询[wildcard]
wildcard 关键字
GET /products/_search{"query": {"wildcard": {"price": {"value": "44.45*"}}}}
?:查询匹配一个字符
*:查询匹配多个字符
多ID查询[ids]
ids关键字:值为数组类型,用来根据一组id获取多个对应的文档
通过创建一个数组,使用数组查询ID
GET /products/_search{"query": {"ids": {"values": [1,2,4]}}}
模糊查询[fuzzy]
fuzzy关键字:用来模糊查询含有指定关键字的文档
GET /products/_search{"query": {"fuzzy": {"description": "taste"}}}
注意:模糊查询是有限制的,最大模糊错误必须在0-2之间
- 搜索关键词长度为2不允许存在模糊
- 搜索关键词长度为3-5允许一次模糊
- 搜索关键词长度大于等于5允许最大2个模糊
布尔查询[bool]
bool关键字:用来组合多个条件实现复杂查询
must:相当于&& 同时成立should:相当于|| 成立一个就行must_not:相当于! 不能满足任何一个
GET /products/_search{"query": {"bool": { #使用布尔查询"must": [ #must关键字{"ids": { #以ids查询"values": [1]}},{"term": { #以关键字查询"title": {"value": "小浣熊"}}}]}}}
多字段查询[multi_match]
multi_match关键字:以一个关键字,查询多个映射
注意:query可以输出关键词,也可以输出一段文本。
GET /products/_search{"query": {"multi_match": { #"query": "小浣熊", #这里的小浣熊,默认会用分词器给你拆开"fields": ["title","description"] #查询title description映射}}}
默认字段分词[query_string]
query_string关键字:以映射作为对比,查询关键字
GET /products/_search{"query": {"query_string": {"default_field": "description", #查询的映射"query": "芜湖"}}}
高亮查询[highlight]
highlight关键字:可以让符合条件的文档中的关键词高亮
GET /products/_search{"query": {"query_string": { #默认字段查询"default_field":"description", #查询映射"query": "芜湖"}},"highlight": { #设置高亮"pre_tags": ["<span style='color:red;'>"], #高亮开头"post_tags": ["<span/>"], #高亮结尾"fields": { #需要给那些字段高亮"*":{} #全部}}}
返回指定条数[size]
size关键字:指定查询结果中返回指定条数。默认返回10条
GET /products/_search{"query": {"range": { #查询范围"price": { #价格映射的0.5-20元"gte": 0.5,"lte": 20}}},"size": 2 #数量为2}
分页查询[form]
from关键字:指定起始返回位置,和size关键字连用可以实现分页效果。
范围查询price映射,0.5-20区间。总共查询6个,从第(2+1)个开始显示
GET /products/_search{"query": {"range": {"price": {"gte": 0.5,"lte": 20}}},"size": 6 #总共查询6个, "from": 2 #从第(page-1)*size个开始}
指定字段排序[sort]
GET /products/_search{"query": {"range": {"price": {"gte": 0.5,"lte": 20}}},"size": 5, "from": 0, "sort": [{"price": { #以价格映射"order": "desc" #降序排序 (asc升序)}}]}
返回指定字段[_source]
_source关键字:是一个数组,在数组中用来指定展示那些字段
GET /products/_search{"query": {"range": {"price": {"gte": 1,"lte": 20}}},"_source": ["id","title"]}
索引原理
倒排索引
倒排索引也叫反向索引,有反向索引必有正向索引。通俗来讲,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时底层使用的就是倒排索引。
索引模型
ES的底层架构是用索引区和元数据区来划分存储数据的!
比如我们有如下数据
| _id | title | price | decription |
|---|---|---|---|
| 1 | 洗衣液 | 19.9 | 洗衣液好用 |
| 2 | iphone13 | 19.9 | 手机好玩 |
| 3 | 干脆面 | 1.5 | 零食好吃 |
当我们录入数据时,可以分词的类型,会进行分词,就比如上面的数据。在ES底层的索引区的存储样式大概为:
- title字段 | term | _id | | —- | —- | | 洗衣液 | 1 | | iphone | 2 | | 干脆面 | 3 |
- price字段
因为洗衣液和iphone的数据价格一样,所以一个数据,有两个引用ID
| term | _id |
|---|---|
| 19.9 | [1,2] |
| 1.5 | 3 |
- description字段
这个 好 被多个ID记录,并且还会显示在文档中的次数与长度。并且这个长度和次数还会在查询是作为打分的依据。
| term | _id | term | _id | term | _id |
|---|---|---|---|---|---|
| 洗 | 1 | 手 | 2 | 零 | 3 |
| 衣 | 1 | 机 | 2 | 食 | 3 |
| 液 | 1 | 玩 | 2 | 吃 | 3 |
| 好 | [1:1:5,2:1:4,3:1:4] | ||||
| 用 | 1 |
ELK:ES的分词器
分词器
Analysis和Analyzer
Analysis:文本分析是把全文转换一系列单词(term/token)的过程,也叫分词(analyzer)。Analysis是通过Analyzer来实现的。分词就是将文档通过Analyzer分成一个一个的Term(关键字查询),每个Term都指向包含这个Term的文档。
Analyer组成
- 注意:在ES中默认使用标准分词器:StandardAnalyzer特点:中文单字分词,单词分词。
分析器(analyzer)都由三种构件组成,character filters,tokenizers,token filters。
- character filters 字符过滤器
- 在一段文本进行分词前,先进行预处理,比如最常见的是:过滤html标签。
- tokenizers 分词器
- 英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
- token filters Token过滤器
- 将切分的单词进行加工。大小写转换-去掉停用词(a and the)-加入同义词(jump leap)
注意:
三者顺序:character filters——tokenizers——token filters
三者个数:character filters(0个或多个)+tokenizers+token filters(0个或多个)
内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
内置分词器测试
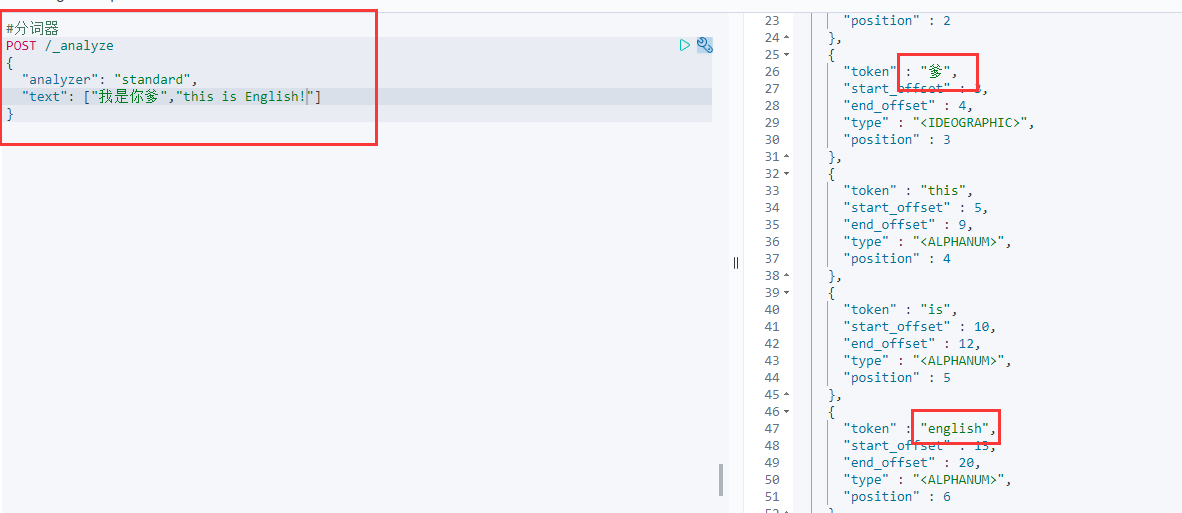
标准分词器[standard]
特点:按照单词分词,英文统一转为小写,过滤标点符号,中文单词分词。
POST /_analyze #使用分词器语法{"analyzer": "standard", #分词器:分词类型为标准分词器"text": ["我是你爹","this is English!"]#注意这里有大写和标点符号}
此时就把中文一个一个拆开了,标点符号和大小写也去掉了。
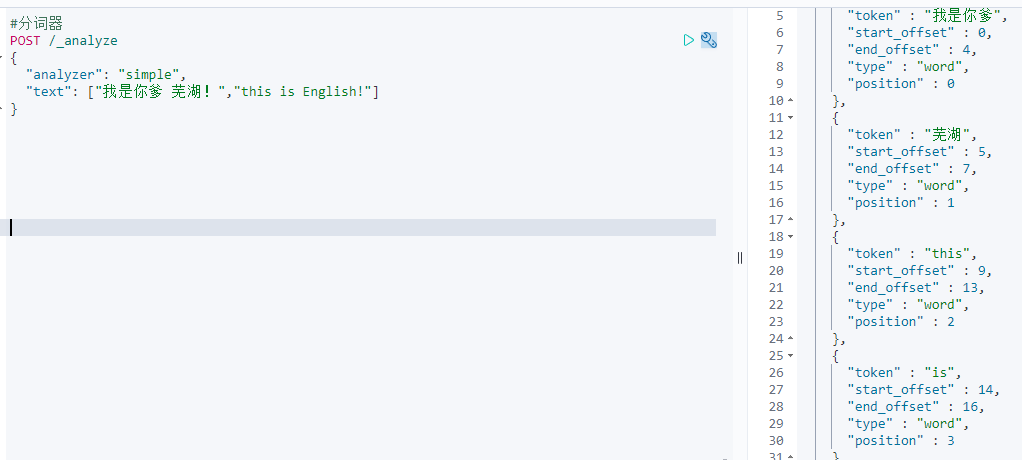
simple分词器[simple]
按照单词分词,英文转为小写,去掉标点,中文不分词,只是按照空格和标点来分词。
POST /_analyze{"analyzer": "simple","text": ["我是你爹 芜湖!","this is English!"]}
此时中文之间只是有空格/标点时,才会像英文那样分词。
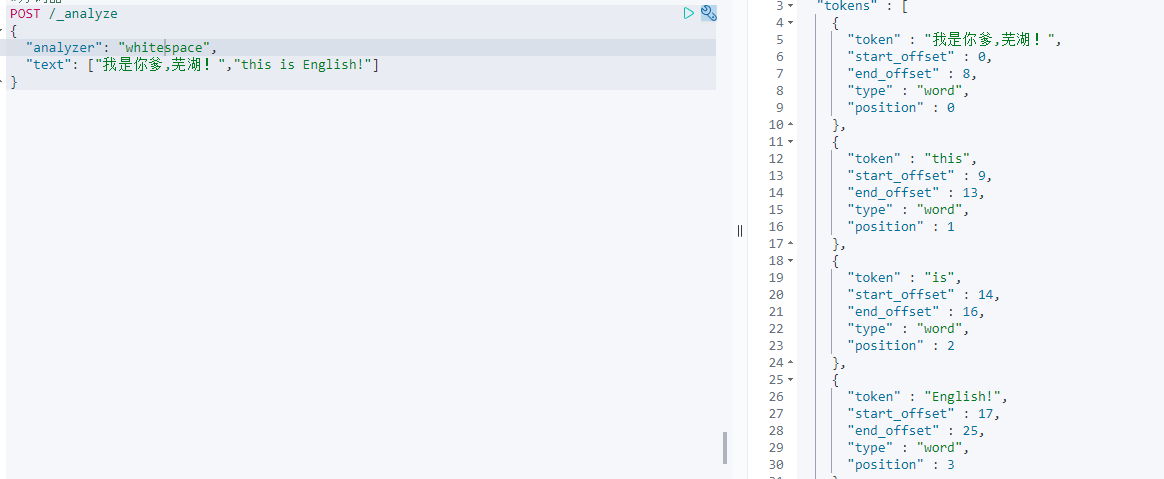
whitespace分词器[whitespace]
特点:中文 英文 按照空格分词,英文不会转为大小写,并且不去掉符号。
POST /_analyze{"analyzer": "whitespace","text": ["我是你爹,芜湖!","this is English!"]}
创建索引时指定分词器
PUT /test{"mappings": {"properties": {"title":{"type": "text","analyzer": "standard" #这里默认会用标准分词器补全}}}}
中文分词器
在ES中只会中文分词器非常多!例如smartCN IK 等,推荐IK分词器。
安装IK分词器
IK分词器是非官方的额外拓展插件,更新速度很快几乎和版本更新同步。
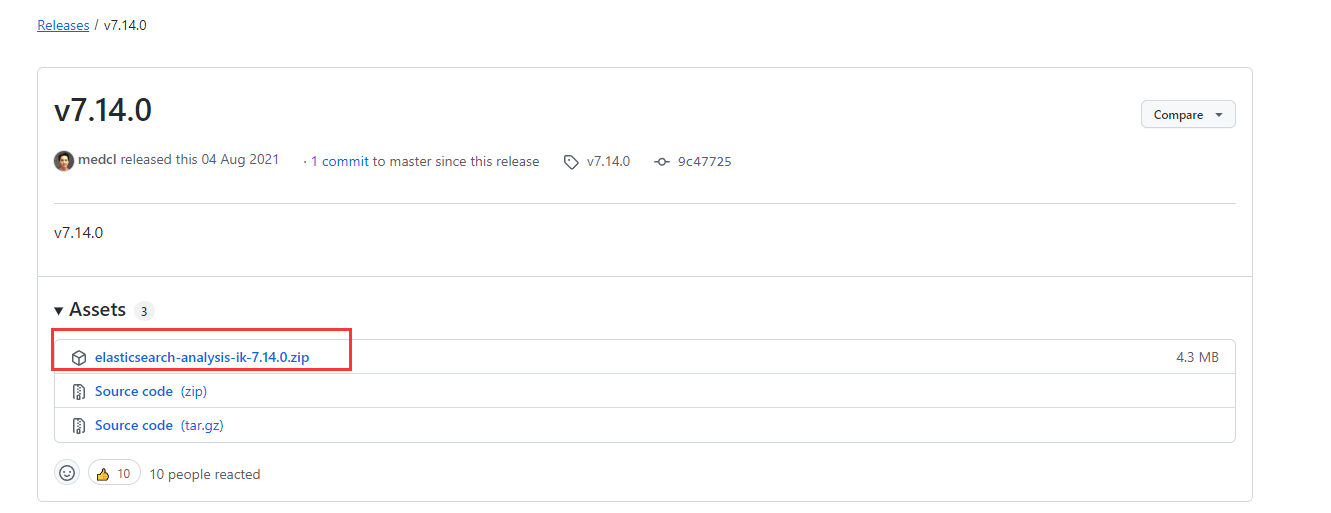
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/
前面我们用了docker,所以这里也要使用7.14.0版本,连一个小版本都不能差。下载ZIP格式的文件,已经给我们编译好了。
在Linux中创建一个文件夹,将ZIP中的程序复制/解压进去。

通过数据卷,管理插件文件夹
记得先关闭docker-compose!
修改完启动即可!
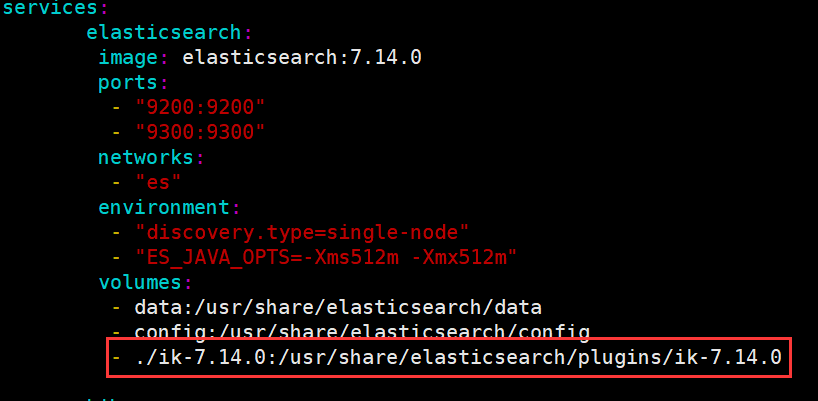
使用IK分词器
IK分词器有两个用法:
ik_smart和ik_max_word。
- ik_smart 分词比较普通,可以理解为拆分组词法来分词的。
- ik_max_word 分词非常精细,在ik_smart基础上,还会对单词逐个划分并组词。
PUT /test #创建使用ik_smart的分词器{"mappings": {"properties": {"title":{"type": "text","analyzer": "ik_smart"}}}}POST /_analyze{ #使用ik_max_word对字符分词"analyzer": "ik_max_word","text": ["我是你爹,芜湖!"]}
扩展词和停用词
IK支持自定义 扩展词典 和 停用词典
- 扩展词典
- 就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典。(比如 IK会将”里奥” 拆开,拆成”里”,“奥”。但是我们不想让他拆开,想让他作为关键词,此时就可以用扩展词典。)
- 停用词典
- 就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典。(比如IK会将”我”,”喜欢“,合成”我喜欢“。我们想让他逐个为关键字,此时就可以用停用词典)
定义扩展词典和停用词典可以修改IK分词器中config目录中IKAnalyzer.cfg.xml
1.修改 IKAnalyzer.cfg.xml
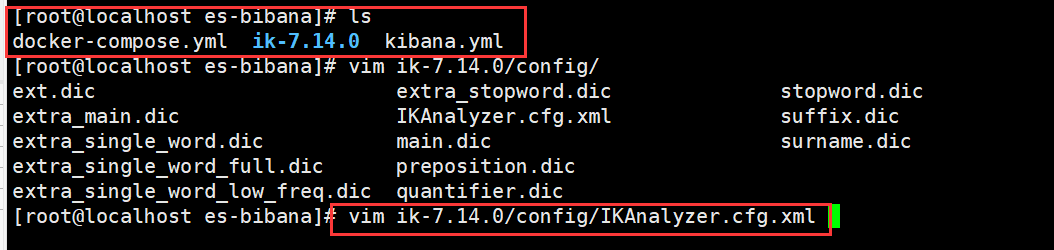
在 ext_dict 后面添加字典文件名称,可以自定义但是要以”.dic”结尾。
在当前文件夹下新建”ext.dic”文件,一行一行的写入关键字。

以行来写,一行一个词。然后重启服务。

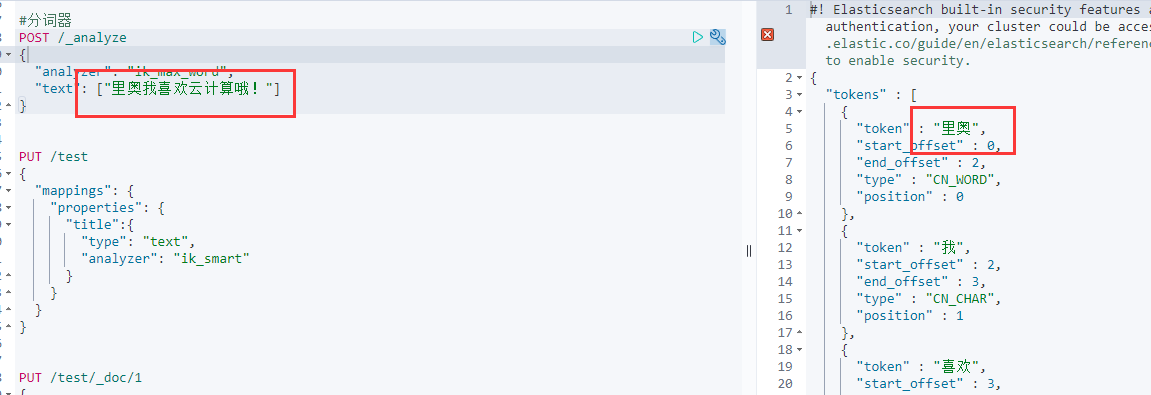
停用词也是同理
dic结尾就是IK分词器的字典文件,其中有很多自带的字典,可以使用或者修改。

ELK:ES过滤查询
过滤查询
过滤查询,其准确来说,ES中的查询有2种,查询和过滤。查询就是前面提到的query查询,它默认会计算每个返回文档的得分,然后根据得分排序。而过滤只会筛选出符合的文档,并不计算得分,而且它可以缓存文档。所以单从性能考虑,过滤比查询更快。换句话说,过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时,应先使用过滤操作过滤数据,然后使用查询匹配数据。
在过滤中,只能只用布尔查询配合filter过滤。
过滤price映射1到20的数据,并且查询全部数据
GET /products/_search{"query": {"bool": {"must": [{"match_all": {}}],"filter": [{"range": {"price": {"gte": 1,"lte": 20}}}]}}}
过滤的类型
常见类型 term terms ranage exists ids
- term:关键词查询过滤
- terms:多个关键词查询过滤
- range:范围查询过滤
- exists:以是否有某映射查询过滤
- ids:以ID号查询过滤
ELK:ES聚合查询
英文为Aggregation Aggs是es除搜索功能外提供的针对es数据做统计分析的功能。聚合有助于根据搜索查询提供聚合数据。聚合查询是数据库中重要的功能特性,ES作为搜索引擎兼数据库,同样提供了强大的聚合分析能力。它基于查询条件来对数据进行分桶计算的方法。有点类似以与SQL中的group by再加一些函数方法的操作。
text类型是不支持聚合的。
聚合查询
根据某个字段分组[terms]
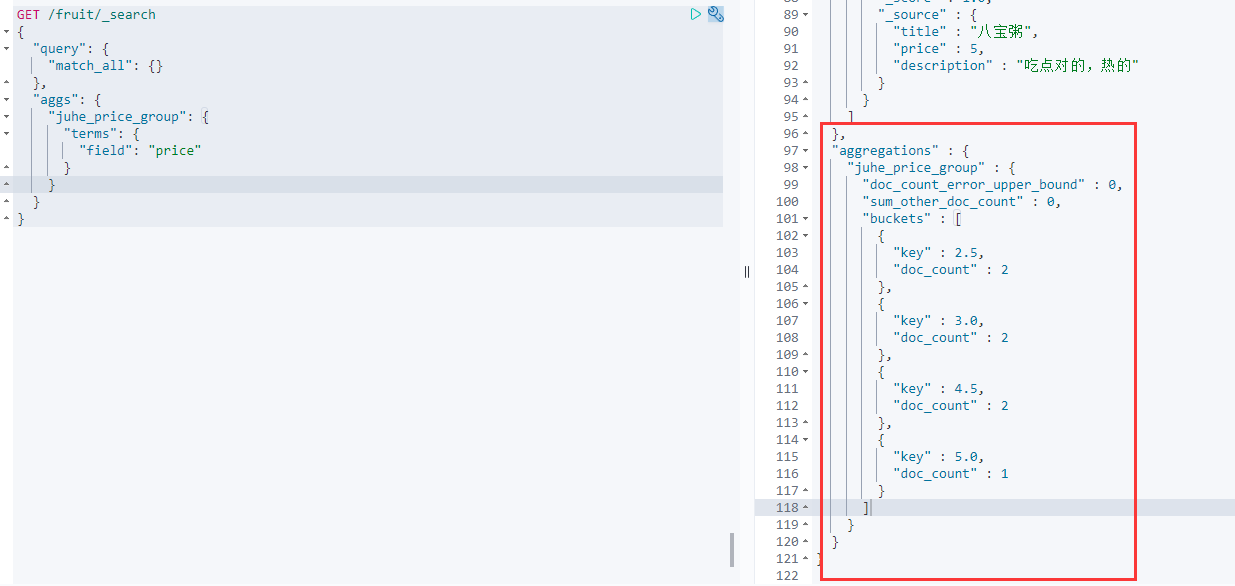
GET /fruit/_search{"query": {"match_all": {}},"aggs": { #使用聚合查询"juhe_price_group": { #组的名称"terms": { #多个关键词"field": "price" #基于price字段}}}}
aggrengations:就是聚合的数据。其中就表示了2.5元的商品为2个,3.0元的为2个,4.5元的为2个,5元的为1个。
聚合做出数值判断
“max” 这一行,可以写很多关键词函数。
- max:最大值
- min:最小值
- avg:平均值
- sum:求和
GET /fruit/_search{"query": {"match_all": {}},"size": 0, #size设置为0,则不显示前面查询的数据"aggs": {"max_price": { #组名"max": { #最大值"field": "price"}}}}

若有收获,就点个赞吧
0 人点赞
