视频:https://www.bilibili.com/video/BV12E411A7ZQ的笔记
Linux安装python环境
建议安装桌面linux组件
- 到官网下载linux的tar安装包
tar -zxf Python-3.7.3.tar.xz
- 安装需要的环境附属
yum install -y gcc zlib zlib-devel openssl-devel readline readline-develide
- 进入解压的安装包中进行编译
./configure --prefix=/usr/local/python --with-ssl
- 编译安装
make && make install
- 配置环境变量
export PYTHON_HOME=/usr/local/python3.10export PATH=${PYTHON_HOME}/bin:$PATH
此时使用命令:pyhthon3 就可以进入python3环境了。
Linux下IDE的安装
- 到pycharm下载安装包,要是.tar结尾的!
tar -zxf pycharm
- 进入解压的文件夹中的bin目录,执行./pycharm.sh
cd pycharm
cd bin && ./pycharm.sh
Linxu创建虚拟环境
python3 -m venv ~/mypysource ~/mypy /bin/activate
Python语法基础
print 输出
输出
age = 18 #创建变量print("我的名字是%s,我的国籍是%s" %("里奥","中国")) #输出占位符print("我的年龄是:%d岁" %age) #输出变量
- %s 字符占位符
- %d 数字占位符
sep 设置输出时连接符号
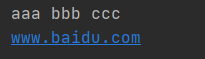
print("aaa","bbb","ccc") #python会默认用 空格 连接print("www","baidu","com",sep=".") #sep 设置连接符号
end 设置末尾操作
因为print是默认换行的,所以可以在末尾添加 end="" 进行操作和限制
print("www",end="") #取消换行print("wuhu",end="\t") #多一段距离print("world",end="\n")#换行
- \t 如同按一下Tab键
- \n 进行换行
input 输入
获取用户在键盘上的输入信息
password = input("请输入密码") #获取键盘的输入,并转为stringprint("您输入的密码为:%s" %password)
type() 查看数据类型
type(a) 查看变量a的数据类型
a,b,c,d = 20 , 5.5 , True , 4+3aprint(type(a),type(b),type(c),type(d))#运行:<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
类型转换
| 函数 | 说明 |
|---|---|
| int(X) | 转换为整数 |
| float(x) | 转换为浮点数 |
| str(x) | 转换为字符串 |
| bool(x) | 转换为布尔型 |
注意:布尔型转换时,true为1flase为0。
运算符
算数运算符
两个比较特殊的>>> 2 // 4 # 除法,得到一个整数0>>> 2 ** 5 # 乘方32
成员运算符
in 如果在指定的序列中找到值,返回true,否则返回falsenot in 如果在指定的序列中没有找到值,返回false,否则返回true
身份运算符
is 判断两个标识符是否引用同一个对象 x is y 类似 id(x) == id(y)is not 判断两个标识符是否引用不同对象 x is not y 类似 id(a) != id(b)
id(x) 是取对象的内存地址
逻辑运算符
and or not 与 或 非。
逻辑运算符的特殊用法:
a = 36a < 10 and print("hello world")#当and前面的结果是false的情况下,后面的结果不会执行。a = 50a > 10 or print("hello world")#因为前面的等式成立了,所以后面的代码并不会执行
判断语句和循环语句
循环时不需要使用{} 大括号,只需使用缩进,对其即可。
: 不能缺少代表着 条件 的结束 语句 的开始。
if True:print("true")else:print("false")
如果出现没有对齐的情况,要么报错,要么执行位置不对:
if True:print("qwq")print("qwq")print("false") #第四行出现错误else:print("false")print("false")#此行少了一格,如果没有第四行#则会直接输出,不会进行if中的判断
多重条件判断
python的if语句中的多重判断,不是else if : 而是 elif :
score = 70if score <=100 and score >=90:print("考试成绩优秀")elif score < 90 and score >=80:print("还可以")else:print("及格")
只有在最后时,才是else,其余的多重条件判断都用elif
if嵌套
因为没了{} 所以嵌套时要注意缩进各个代码之间的位置。
并且为了方便写代码,部分编辑器在嵌套时会有提示线
xingbie = 1danshen = 1if xingbie == 1:print("男生") #执行语句和条件语句位置一样if danshen == 1:print("我现在单身,帅哥一枚")else:print("我不是单身")else :print("女生")if danshen == 1:print("我是单身,求撩啊!")else:print("我不是单身!")
随机数
import random 导入随机数库,可以使用其中的函数了!
import random #导入库x = random.randint(0,10) #设置x为int类型的0-10的随机数print(x)
循环语句
for循环
for i in range(5): #从0开始到4,每次加1print(i)#range():范围for i in range(0,10,3): #从0开始每次加3,峰值为10print(i)for i in range(-10,-100,-30): #哪怕是负数都可以print(i)name = 'liao'for x in name:print(x,end='\t') #是字符的话,会逐个打印字符串内容a = ["aa","bb","cc"] #列表也可以自动遍历for i in a: #遍历列表的字符print(i)for i in range(len(a)): #遍历列表的数量+字符print(i,a[i])
while循环
i = 0while i<5:print("当前是第%d次循环"%(i+1))print("i=%d"%i)i+=1
1-100求和
i = 1sum = 0while i <= 100:sum += ii += 1print(sum)
while中的else
当跳出while循环时,会执行的命令。
count = 0while count < 5:print(count,"small than 5")count += 1else:print(count,"no small than 5")
break,continue和pass
break:跳出for,while循环
continue:跳过当前循环,进入下一个循环
pass:空语句,常用来当做占位符,不做任何事
1-50偶数的和
i = 0sum = 0while i <= 50:i += 1if i%2==1:continuesum += iprint(sum)
字符串,列表,元祖,字典
String
python中字符串可以用,单引号,双引号,三引号括起来。使用反斜杠转义特殊字符。
word = '字符串'wuhu = "这是一个芜湖"duanluo = """这是 一个 段落我 在这里 能随便写"""print(word)print(wuhu)print(duanluo)
单引与双引号中的转义字符
stu = "I'm stu"print(stu)#I'm stustu = 'I\'m stu'print(stu)#I'm stustu = "Jason said \"I like you\"".print(stu)#Jason said "I like you"
字符串截取
str = "liaowuhu"print(str[2]) #取单个字符print(str[1:]) #取第2个之后的全部字符print(str[1:5]) #取第2到6个字符print(str[0::3]) #取第1到之后的全部字符,每次跳3print(str[:7:3]) #取第8个之前的全部字符,每次跳3print(str[0:8:2]) #取第1到8个个字符,每次跳2
字符串的一些用法
#字符串的链接print(str + ',你好') #直接添加字符print(str,",芜湖~") #直接添加字符,默认会有个空格#字符串的复制print(str*3) #将字符str 复制3个并打印。
转义字符
print('wewqe\nqwe') #\n 会给字符回车print(r'wewqe\nqwe') #在前面加个r 会取消全部的转义字符
字符串高级用法
| 代码 | 函数用法 | 代码实例 |
|---|---|---|
| len | 获取字符串长度 | print(len(s)) |
| find | 查找指定内容是否在某位置中 | print(s.find(“a”)) |
| startswith/startswith | 判断字符串是否以xxx开头/结尾 | print(s.startswith(“c”)) |
| count | 计算出现次数 | print(s.count(“i”)) |
| replace | 替换字符 | print(s.replace(“c”,”C”)) |
| split | 通过参数的内容切割字符串 | print(s.split(“c”)) |
| upper/lower | 将字符串中的大小写替换 | print(s.upper()) |
| strip | 去除空格 | print(s.strip()) |
| join | 字符串拼接 | print(s.join(“1a”)) |
列表
List
- 列表可以完成大多数集合类的数据结构实现,列表中元素的类型可以不相同,他支持数字,字符,包括嵌套。
- 列表卸载方括号[]之间,用逗号分隔开的元素列表。
- 列表索引开头是以0开始,末尾是以-1开始。
- 列表可以使用 + 操作服进行拼接,用 * 表示重复。
- 当我们获得多个数据的时候,那么我们可以将它储存到列表中,然后直接列表访问。
#打印namelistnamelist = ["里奥",'liao',123,'test',1.213]print(namelist[0])print(namelist[3])for name in namelist: #for循环遍历print(name)print(len(namelist))length = len(namelist) #获得长度值赋给lengthi = 0while i < length:print(namelist[i])i += 1
增删改查
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 【增】新增一个数据到列表尾部 | append | list.append(‘芜湖’) |
| 【增】在指定位置插入 | insert | list.insert(1,3) |
| 【增】将一个列表的元素添加到另一个列表 | extend | list.extend(a) |
| 【删】直接删除某个值,有重复的删掉第一个 | remove | list.remove(‘里奥’) |
| 【删】删除指定位置的一个元素 | del | del namelist[2] |
| 【删】删除列表中的一个元素,默认最后一个 | pop | list.pop(1) |
| 【改】直接修改执行下标进行修改 | list[1] | namelist[1] = “test” |
| 【改】修改范围内的数据 | list[1:3] | list[1:3]=”123”,7.3 |
| 【查】判断是否有某个值 | in | if x in list: |
| 【查】判断是否没有某个值 | not in | if x not in list: |
常用操作
index:查找第一次出现的下标,并且告诉你在列表中的位置。找不到就报错
a = ["a","as","e3","wda","das","sadc"]print(index("wda",2,5))#3
count:统计出现的次数
a = ["a","as","e3","wda","das","sadc","a","a"]print(a.count("a"))#3
reverse:将列表所有元素反转
a = ["a","as","e3","wda","das","sadc","a","a"]a.reverse()print(a)#反转输出
sort:排序输出
a = [1,213,34789,67,590,556,423,316,24,6,93]a.sort() #正序排序print(a)a.sort(reverse=True) #倒叙排序print(a)
二维数组
schoolName = [['123',123],[123,676],["12312","56756"]]print(schoolName[1][0])
实例:
import randomoffices = [[],[],[]]names = ["1","2","3","4","5","6","7","8"]for name in names:index = random.randint(0,2)offices[index].append(name)i = 1for office in offices:print("office:%d number:%d"%(i,len(office)))i+=1for name in office:print("%s"%name,end="\t")print("\n")
元组
tuple与list类似,不同之处在于tuple的元素不能修改。tuple写在小括号里,元素之间用逗号隔开。
元祖的元素不可变,但可以包含可变对象。如list
tup1 = ()print(type(tup1)) #输出tupletup2 = (123) #inttup3 = (123,) #tupletup4 = (123,48,16,"aaa") #tupleprint(tup4(0)) #123print(tup4(-1)) #aaaprint(tup4(1:3)) #48,16,aaa
增:
- 两个元祖添加,并且赋值给另一个元祖
tup1 = (123,1232,312)tup2 = ("WQe","WDs","jy")tup = tup1+tup2#(123,1232,312,"WQe","WDs","jy")
删:
- def直接删除整个元祖
tup1 = (123,123,54)del tup1print(tup1) #报错
改:
- 不支持直接赋值修改
tup1=(123,12312,12312)tup1[0] = 123 #这是错误的
字典
- 字典是无序的对象集合,使用键-值(key-value)存储,具有极快的查找速度。
- 键(key)必须使用不可变类型
- 同一个字典中,键(key)必须是唯一的
- 爬虫中经常使用字典。
info = {"name":"liao","age":19} #定义字典print(info["name"]) #字典的访问print(info.get["gender","没有这个键"])#如果没有这个键,则返回指定字符
增:
直接添加就好了
info = {"name":"里奥","age":18}newID= input("请输入学号:")info["id"]=newIDprint(info["id"])print(info)#10#{'name': '里奥', 'age': 18, 'id': '10'}
删:
- del 删除。删除的是全部键值队。
- clear 清空。将全部键值队清空,但是字典还在。
改:
直接修改
info = {"name":"里奥","age":18}info["age"] = 20print(info["age"])
查:
- info.keys() #列出所有的键
- info.values() #列出所有的值
- info.items() #列出所有的项,每个键就是一个元祖
info = {"name":"里奥","age":18,"id":1}print(info.keys()) #列出所有的键print(info.values()) #列出所有的值print(info.items()) #列出所有的项,每个键就是一个元祖#打印遍历for key,value in info.items():print("key=%s,value=%s"%(key,value))
枚举函数,同时获得下标和数值
mylist = ["a","b","c","d","e"]for i,x in enumerate(mylist):print(i+1,x)
set集合
set和dict类似,也是一组key的组合,但是不存储value。由于key不能重复,所以在set中,没有重复的key。会去除重复。
set是无序的,重复元素在set中自动被过滤。
函数
def 函数名():代码
定义与调用
def printinfo():print("-------------------")print(" 人生苦短,我用python ")print("-------------------")printinfo()
有参函数
def addNum(x,y):print(x+y)addNum(10,20)
带返回值
def addNums(x,y):return x+yprint(addNums(17,29))
返回多个值
def chuyi(x,y):shang = x/yyu = x%yreturn shang,yuchu,yu = chuyi(20,2) #需要多个值保存返回内容print(chu,yu)
全局变量和局部变量
在函数中的全局变量使用global 进行修改,并且之后使用会生效。
lambda
sum = lambda x,y:x+yprint(sum(7,6))
lambda操作简单,适合实现一些简单的函数操作
eval
num = 10result = eval("3 * num")print(result)list_str = "[1,2,3]"tuple_str = "(1,2,4)"dict_str = "{1:'wd',2:'dsad',3:'qwed'}"list_eval = eval(list_str)tuple_eval = eval(tuple_str)dict_eval = eval(dict_str)print("[list]序列数据:%s,序列类型%s"%(list_eval,type(list_eval)))print("[tuple]序列数据:%s,序列类型%s"%(tuple_eval,type(tuple_eval)))print("[dict]序列数据:%s,序列类型%s"%(dict_eval,type(dict_eval)))
eval可以不用进行强制转换,运行字符串中的程序代码。但是只能解析其中的单个字符串的信息
exec
作用和eval差不多,但是可以进行多行的字符串操作
文件操作
打开/创建文件
f = open("test.txt","w") #打开文件,文件不存在,就新建。f.close()
访问模式
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
给文件内容编辑
#写入f = open("test.txt","w")f.write("芜湖~~")f.close() #必须执行关闭,才会保存你的操作。#读 开始时定位在文件头部,每次执行一次向后移动指定字符数f = open("test.txt","r")content = f.read(3) #读取5个字符print(content)f.close()#一次读取全部信息f = open("test.txt","r")content = f.readlines() #读取全部内容为列表i = 1for temp in content:print(i,temp)i+=1f.close()#读取单行信息f = open("test.txt","r")content = f.readline()print(content)content = f.readline()print(content)content = f.readline()print(content)content = f.readline()print(content)f.close()
文件的序列化和反序列化
默认情况下,我们只能将字符串写入到文件中。所以无法写入对象。不过可以通过序列化写入到文件中。
序列化的两种方式
import json
dumps():将对象转换为字符串
import json#导入json模块到文件中,序列化f=open('test.txt',"w")#创建文件name = ["QWeqw",123123,"xcawe"]#定义一个列表name_list = json.dumps(name)#将python对象变成json的字符串print(type(name_list))f.write(name_list)#将转换后的对象写入到文件中f.close()
dump():在将对象转换为字符串的同时,指定一个文件夹的对象,然后把转换后的字符串写入到这个文件里。
import json#导入json包f = open('test.txt','w')name_list = ["wqexz",'vwer',12321]json.dump(name_list,f)#将name_list转换为str,并且写入到文件f中f.close()
反序列化
将json字符串转换为python对象
json.loads()
import jsonfp = open("test.txt","r")a = fp.read()#读取文件print(a)print(type(a))#读取文件类型 strb = json.loads(a)#将json字符串转换为python对象print(type(b))fp.close()
json.load()
import jsonfp = open("test.txt","r")a = json.load(fp)#直接写文件print(a)print(type(a))fp.close()
OS模块
import osos.rename("test.txt","test123.txt") #修改名称os.mkdir("fild") #创建文件夹os.getcwd #获取当前目录os.remove("test123.txt") #删除文件os.chdir("../") #改变默认目录os.listdir("./") #获取目录列表os.rmdir("fild") #删除文件夹
错误与异常
错误:不可预料,不可知的。当出现错误,后面代码无法继续执行。
异常:可预料,能改变的。
异常捕获
#单个异常捕获try:print("-"*30)f=open("123.txt","r") #只读模式,打开文件。此时文件不存在,会报错print("*"*30)except IOError: #如果是IOError的报错pass #捕获异常,使用pass占位报错。#多个异常捕获try:print(num)except (NameError,IOError): #将可能的错误都放到小括号中print("出现了名称错误")
错误信息提示
try:print(num)except (NameError,IOError) as result: #将错误提示赋值给resultprint("出现了名称错误")print(result)#name 'num' is not defined
Execption
Exception 所有异常的父类,不知道写哪个异常,用它就对了。
finally与嵌套
finally:不管有没有报错,都是会执行的。
import timetry:f = open("123.txt","r") #尝试读取123.txttry:while True: #一直循环content = f.readline() #content等于文件的行if len(content) == 0: #如果没有值,当无法被赋值,则退出breaktime.sleep(2)print(content)finally:f.close()print("文件关闭")except Exception:print("发生异常")finally:print("文件关闭")
| 异常名称 | 描述 |
|---|---|
| UserWarning | 用户代码生成的警告 |
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
python爬虫
准备工作
首行代码,使得代码包含中文。
#-*- codeing = utf-8 -*-
加入main函数用于测试程序
if _name_ == "_main_"
当程序被调用执行时,先从该代码块执行
从其他文件夹导入类
from 文件夹名 import 类名from test1 import t1
常用包
import bs4 #网页解析,获取数据import re #正则表达式,网页匹配import urllib.request,urllib.error #制定url,获取网页内容import xlwt #进行Excel操作import sqlite3 #进行sqlite数据库操作
爬虫流程
- 爬取网页
baseurl = "https://movie.douban.com/top250?start=" #设置urldef getdata(baseurl):datalist = []#逐一解析数据return datalistdatalist = getdata(baseurl) #爬取网页
- 解析数据
- 保存数据
savepath=r".\豆瓣电影top250.xls"saveDate(savepath)def saveDate(savepath):
获取数据
#得到指定的一个url网页内容def askURL(url):#首先指定头部信息,设置用户代理,告诉服务器我们是什么类型的机器。head = { #模拟浏览器"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50"}url
from bs4 import BeautifulSoupimport urllib.requestimport urllib.errorimport sqlite3import xlwtimport redef main():baseurl = "https://movie.douban.com/top250?start=" #设置urldatalist = getdata(baseurl) # 爬取网页savepath = r".\豆瓣电影top250.xls"#saveDate(savepath)askURL("https://movie.douban.com/top250?start=")def getdata(baseurl):datalist = []#逐一解析数据return datalist#得到指定的一个url网页内容def askURL(url): #首先指定头部信息head = {"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50"}requests = urllib.request.Request(url,headers=head)html = ""try:response = urllib.request.urlopen(requests)html = response.read().decode("utf-8")print(html)except urllib.error.URLError as e :if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)#return htmldef saveDate(savepath):print()if __name__ == '__main__':main()
urllib
获取baidu的页面代码
import urllib.request#1.定义一个url,就是你需要访问的数据url = 'http://www.baidu.com'#2.模拟浏览器向服务器发送请求,此时服务器会给你一个响应反馈#response 响应response = urllib.request.urlopen(url)#3获取响应中的页面源码#content内容#read方法 返回字节形式的二进制数据。要将二进制的数据转换为字符串#二进制 -》字符串 解码 decode('编码格式')content = response.read().decode('utf-8')#4打印数据print(content)
1个类型和6个方法
import urllib.requesturl = 'http://www.baidu.com'response = urllib.request.urlopen(url)#模拟浏览器想服务器发送请求#一个类型和六个方法#print(type(response))#<class 'http.client.HTTPResponse'>#按照一个字节一个字节的读content = response.read(5)print(content)#读取一行content = response.readline()print(content)#读取全部content = response.readlines()print(content)#返回状态码 200就是没问题print(response.getcode())#返回url地址print(response.geturl())#获取一些状态信息print(response.getheaders())
下载图片/视频/网页
import urllib.request#下载网页url = 'http://www.baidu.com'#url代表下载路径,filename文件的名字urllib.request.urlretrieve(url,'baidu.html')#下载图片url_img = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fb-ssl.duitang.com%2Fuploads%2Fitem%2F201608%2F20%2F20160820091644_etiFR.jpeg&refer=http%3A%2F%2Fb-ssl.duitang.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1638861798&t=667fc36288ddaf4cb6dd24d9cd129af8'urllib.request.urlretrieve(url_img,'leimu.jpg')#下载视频url_video = 'https://vd3.bdstatic.com/mda-mjvdqf1qkkijh90e/sc/cae_h264_clips/1635589295180348540/mda-mjvdqf1qkkijh90e.mp4?auth_key=1636271907-0-0-3d7d201b6754c7c0d6fd76f777c0b472&bcevod_channel=searchbox_feed&pd=1&pt=3&abtest='urllib.request.urlretrieve(url_video,'test.mp4')
请求对象的定制
大部分网站都是https的协议,这个自带一个反爬。需要在爬时,添加请求头,使用Request方法。
URL = 'https://www.baidu.com'headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"}#正常来说,咱们使用urlopen。会被https反爬,此时需要用到Request,将header添加进来response = urllib.request.urlopen(url)#因为urlopen的方法中,不能存储字典,所以header不能传进去#请求对象的定制request = urllib.request.Request(url=URL,headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf8')print(content)
Get请求的quote方法
import urllib.requestimport urllib.parse #该库用来设置quote#获取该网页的源码,此时wd=后面没有写东西URL = 'https://www.baidu.com/s?wd='#设置请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"}#将 蕾姆 变成unicode编码的格式#我们将依赖urllib.parsename = urllib.parse.quote('蕾姆')URL = URL + name#请求对象定制request = urllib.request.Request(url=URL,headers=headers)#模拟浏览器想服务器发送请求response = urllib.request.urlopen(request)#获取响应的内容content = response.read().decode('utf-8')print(content)
Get请求的urlencode方法
有时候会有很多的字符需要转换成unicode编码
import urllib.requestimport urllib.parse#获取该网页的源码URL = 'http://www.baidu.com/s?'#将字符转换成unicode编码data = {'wd':'蕾姆','sex':'女','location':'异世界'}new_data = urllib.parse.urlencode(data)url = URL + new_dataheader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"}#请求对象的定制requests = urllib.request.Request(url=url,headers=header)#模拟浏览器想服务器发送请求response = urllib.request.urlopen(requests)#获取网页源码的数据content = response.read().decode('utf-8');print(content)
Post请求百度翻译①
post请求的参数,是不会拼接在url后面的 而是需要放在请求对象定制的参数中
设置请求头——设置post请求数值——将请求参数进行编码——模拟浏览器发送请求——请求对象的定制——模拟浏览器想服务器发送请求——获取响应的数据——将响应的数据转换为python变量
import urllib.requestimport urllib.parseimport jsonurl = 'https://fanyi.baidu.com/sug' #设置urlheader = { #设置请求头"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"}data = {'kw':'apple'}#post的请求的参数必须要进行编码data = urllib.parse.urlencode(data).encode('utf-8')#post请求的参数,是不会拼接在url后面的 而是需要放在请求对象定制的参数中#post请求的参数,必须要执行编码#请求对象的定制requests = urllib.request.Request(url=url,data=data,headers=header)#模拟浏览器向服务器发送请求response = urllib.request.urlopen(requests)#获取响应的数据content = response.read().decode('utf-8')print(content) #此时还是json对象#post请求的参数 必须编码 data = urllib.parse.urlencode(data)#编码之后必须调用encode方法 data = urllib.parse.urlencode(data).encode('utf-8')#参数是放在请求对象定制的方法中 requests = urllib.request.Request(url=url,data=data,headers=header)a = json.loads(content)print(a)
Post请求百度翻译②
import urllib.requestimport urllib.parseimport jsonurl = "https://fanyi.baidu.com/v2transapi?from=en&to=zh"header = {'Cookie': 'FANYI_WORD_SWITCH=1; REALTIME_TRANS_SWITCH=1; SOUND_SPD_SWITCH=1; HISTORY_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1636282101,1636283407; BAIDUID_BFESS=D97104299B0231E843C8B065363FA834:FG=1; BAIDUID=D97104299B0231E852C4592CEFEF4223:FG=1; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1636285675; __yjs_duid=1_2528c66efbdff8f58d954589e0c966b71636285675145; __yjs_st=2_Y2Q2YzJkOGVlZGUzYTNlNzAyMGFkMDZhNDA3YjM1YTA2MjUwNTA4M2MwZDU1MTQ2ODc5YjkwMDNjN2YwMTgwZWIzMGJkNzI5M2RiMWVjMjkzYzI5NzU5ZDhiN2EyODA3MzA3MzkyMWMzOWJiMDYwODRkYjlhNTkzZGViOWVhMTdmMTNhZDRiYWU4NzRkOGU1NzI1MjA5MGYzYTZlNzQyZTU4MThkNjg5MTU0NGRkNzk5NDRmZWEyZmE0NTZkODMzYjMyYTNhMGE5ZmE5YTY1ODQwNTFkZDI4MzI1OTgwZTczOTQ5ODE3YTAzYTk0OWI4MDg3Y2I1YTY2NDZjZDFmNl83X2I3ZDViNWY0; ab_sr=1.0.1_MWYyYjA3ZjgyNzIwNmQyNTdhZTNlNzYzODgxZDYwZWQ2OThlMzJmMjc0ZWIxYjdlYjE0ZGJhZDQ0OTk1MmY3NGJiNzk0NDU2MjVjMDI3N2Y3ZDM0YzRlZTgxYTg5NTE2MmUyZTFlOGVmYjcyMjg2ZTFkYjJiYWZjZmY2OTVhNWRkMWJjNjhkMzI0YzkzM2U4N2I0ZjliYmNlZDg5NzFiNQ==','User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40',}data = {"from": "en","to": "zh","query": "eat","transtype":"realtime","simple_means_flag": 3,"sign": "25728.296881","token": "f2f58e3277099aae3d46dad701d019a8","domain": "common",}#post请求的参数data = urllib.parse.urlencode(data).encode('utf-8')#请求对象定制request = urllib.request.Request(url = url,data = data,headers = header)#模拟浏览器向服务器发送请求response = urllib.request.urlopen(request)#获取响应的数据content = response.read().decode('utf-8')a = json.loads(content)print(a)
ajax的get请求①
爬取豆瓣电影的第一页
import urllib.requesturl = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}# (1) 请求对象的定制request = urllib.request.Request(url=url,headers=headers)# (2)获取响应的数据response = urllib.request.urlopen(request)content = response.read().decode('utf-8')# open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8# encoding = 'utf-8'fp = open('douban1.json','w',encoding='utf-8')fp.write(content)with open('douban1.json','w',encoding='utf-8') as fp:fp.write(content)
ajax的get请求②
import urllib.requestimport urllib.parsedef create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'#设置urldata = {'start':(page - 1)*20,'limit':20}#设置get请求数据header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}data = urllib.parse.urlencode(data) #将get数据转换编码url = base_url + datarequest = urllib.request.Request(url=url,headers=header) #请求对象定制return requestdef get_content(request):#模拟浏览器向服务器发送请求response = urllib.request.urlopen(request)#获取响应的数据content = response.read().decode('utf-8')return contentdef down_load(page,content):#str(page) page本来是int形,需要强制转换为strwith open("douban" + str(page) + '.json','w',encoding='utf-8') as fp:fp.write(content)#程序入口if __name__ == '__main__':start_page = int(input('起始的页码'))#先获取起始和结束的页码end_page = int(input('结束的页码'))for page in range(start_page,end_page + 1):request = create_request(page)#获取响应的数据content = get_content(request)down_load(page,content)
ajax的post请求
import urllib.requestimport urllib.parsedef create_request(page):base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data = {"cname": "郑州","pid":"","pageIndex": page,"pageSize": 10,}data = urllib.parse.urlencode(data).encode('utf-8')header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}request = urllib.request.Request(url=base_url,data=data,headers=header)return requestdef get_content(request):reponse = urllib.request.urlopen(request)content = reponse.read().decode('utf-8')return contentdef down_load(page,content):with open('kfc_' + str(page) +'.json','w',encoding='utf-8') as fp:fp.write(content)if __name__ == '__main__':star_page = int(input('请输入起始页码'))end_page = int(input('请输入结束页码'))for page in range(star_page,end_page+1):#请求对象的定制request = create_request(page)#获取网页源码content = get_content(request)#下载down_load(page,content)
cookie登录
#适用场景:数据采集的时候,需要绕过登录,然后进入到某个页面#个人信息的页面是utf-8 但还是报错了编码错误,因为并没有进入到个人信息页面,而是进入到了登录界面import urllib.requestimport urllib.parseurl = 'https://weibo.cn/6872551356/info'header = {'cookie':' SUB=_2A25MjWedDeRhGeBG7FAU9S_PzjqIHXVvjgnVrDV6PUJbktCOLXfakW1NQe-etiou_OIg_KitV9VcRpKy7ytNczHc; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF1PU1h6j8LkpZp6uVUOUjn5NHD95Qc1hMESK-pe0-cWs4DqcjPi--4iKnNiKyhi--fi-2fi-2fqgY7eK2t; SSOLoginState=1636374477; _T_WM=37a11b096a235bbb73e9bf73cb5c1690',#防盗链 判断当前是否从上一个路径进来的 一般是作用图片的防盗链'referer': 'https://weibo.cn/','user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'}#请求对象定制request = urllib.request.Request(url=url,headers=header)#模拟浏览器向服务器发送请求response = urllib.request.urlopen(request)#获取响应的数据content = response.read().decode('utf-8')#将数据保存到本地with open('weibo.html','w',encoding='utf-8')as fp:fp.write(content)
handler处理的基本使用
#使用handler来访问百度import urllib.requestimport urllib.parsebase_url = 'http://www.baidu.com/s?ie=utf-8&wd=ip'header = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 95.0.4638.69Safari / 537.36Edg / 95.0.1020.44"}#请求对象定制request = urllib.request.Request(url=base_url,headers=header)#handler builder_opener open#1,获取handler对象handler = urllib.request.HTTPHandler()#2,通过hendler获得opener对象opener = urllib.request.build_opener(handler)#3,调用open方法response = opener.open(request)#4,获取响应数据content = response.read().decode('utf-8')print(content)
handler访问百度
#使用handler来访问百度import urllib.requestimport urllib.parsebase_url = 'http://www.baidu.com/s?ie=utf-8&wd=ip&usm=3&rsv_idx=2&rsv_page=1'header = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 95.0.4638.69Safari / 537.36Edg / 95.0.1020.44"}#请求对象定制request = urllib.request.Request(url=base_url,headers=header)#模拟浏览器访问服务器#response = urllib.request.urlopen(request)proxies = {'http':'112.194.204.79:8085'}handler = urllib.request.ProxyHandler(proxies=proxies)opener = urllib.request.build_opener(handler)response = opener.open(request)#获取响应的信息content = response.read().decode('utf-8')with open('daili.html','w',encoding='utf-8') as fb:fb.write(content)
handler代理池
import urllib.requestimport urllib.parseimport randomproxies_pool = [ #选择性代理{'http':'221.125.138.189:8193'},{'http':'222.78.6.190:8083'},]proxies = random.choice(proxies_pool)base_url = 'http://www.baidu.com/s?ie=utf-8&wd=ip'header = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 95.0.4638.69Safari / 537.36Edg / 95.0.1020.44"}#请求对象定制request = urllib.request.Request(url=base_url,headers=header)#获取handler对象handler = urllib.request.ProxyHandler(proxies)#通过hendler获得opener对象opener = urllib.request.build_opener(handler)#调用open方法response = opener.open(request)#获得响应数据content = response.read().decode('utf-8')with open('daile1.html','w',encoding='utf-8') as fp:fp.write(content)
xpath解析
xpath基本语法:1.路径查询//:查找所有子孙节点,不考虑层级关系(找寻他的所有子节点)/:找直接子节点(找寻一层节点)2.谓词查询//div[@id="test"] #查找id为test的值3.属性查询//@class #查找带有class属性的的值4.模糊查询//div[containse(@id,"he")]//div[starts-with(@id,"he")]5.内容查询//div/h1/text()6.逻辑运算//div[@id="head" and @class="s_down"]//title | //price
例子:
from lxml import etree#lxml解析#1.本地文件 etree.parse#2.服务器响应数据 response.read().decode('utf-8') 常用! etree.HTML()#xpath解析本地文件tree = etree.parse('test.html')print(tree)#tree.xpath('xpath路径')# #查找ul下面的lili_list = tree.xpath('//body/ul/li')#查找所有有id的属性li标签#text() 获取标签内容li_list = tree.xpath('//ul/li[@id]/text()')#找到id为l1的li标签li_list = tree.xpath('//ul/li[@id="l1"]/text()')#查找到id为l1的li标签的class属性值li_list = tree.xpath('//ul/li[@id="l1"]/@class')#查询id中包含l的li标签li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')#查询id的值,以l开头的li标签li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')#查询id为l1和class为c1的标签li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')#判断列表的长度print(li_list)print(len(li_list) )
获得百度搜索中的百度一下
# -*- coding: utf-8 -*-#1.获取百度源码#2.解析 解析服务器响应的文件#3.打印import urllib.requestimport urllib.parsefrom lxml import etreeurl = 'https://www.baidu.com/'header = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 95.0.4638.69Safari / 537.36Edg / 95.0.1020.44"}#请求对象定制request = urllib.request.Request(url=url,headers=header)#模拟浏览器访问服务器response = urllib.request.urlopen(request)#获取网页源码content = response.read().decode('utf-8')#解析网页源码,获取我们想要的数据#解析服务器相应的文件tree = etree.HTML(content)#获取想要的数据 xpath返回值是列表数据result = tree.xpath('//input[@id="su"]/@value')[0]print(result)
爬取站长之家图片
# -*- coding: utf-8 -*-import urllib.requestimport urllib.parsefrom lxml import etree#1.请求对象定制#2.获取网页源码#3.下载#需求:获取前十页的图片#https://sc.chinaz.com/tu/qinglvtupian.html#https://sc.chinaz.com/tu/qinglvtupian-2-0-0.htmldef create_request(page):if(page == 1):url = "https://sc.chinaz.com/tu/qinglvtupian.html"else:url = "https://sc.chinaz.com/tu/qinglvtupian-"+str(page)+"-0-0"+".html"header = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 95.0.4638.69Safari / 537.36Edg / 95.0.1020.44"}request = urllib.request.Request(url=url,headers=header)return requestdef get_content(request):response=urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef down_load(content):#下载图片,并不是下载页面#urllib.request.urlretrieve("图片地址","文件名称")tree = etree.HTML(content)name_list = tree.xpath('//div[@id="ulcontent"]//a/img/@alt')#一般涉及到图片的网站,涉及到懒加载(此时是src2)src_list = tree.xpath('//div[@id="ulcontent"]//a/img/@data-src')for i in range(len(name_list)):name = name_list[i]src = src_list[i]src1 = src.replace('\\','/')print(src1)url = "https:"+src1urllib.request.urlretrieve(url=url,filename='./picture/'+name+".jpg")if __name__ == '__main__':start_page=int(input("请输入起始页码"))end_page=int(input("请输入结束页码"))for page in range(start_page,end_page+1):#1.请求对象定制request = create_request(page)#2.获取网页源码content = get_content(request)#3.下载down_load(content)
jsonpath
{ "store": {"book": [{ "category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95},{ "category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99},{ "category": "fiction","author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99},{ "category": "fiction","author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "red","author": "liao","price": 19.95}}}
# -*- coding: utf-8 -*-import urllib.requestimport jsonpathimport jsonobj = json.load(open('test.json','r',encoding='utf-8'))#书店所有的书的作者#书店下,所有书,的作者author_list=jsonpath.jsonpath(obj,'$.store.book[0].author')print(author_list)#所有的作者author_list1 = jsonpath.jsonpath(obj,'$..author')print(author_list1)#store下面的所有元素tag_list = jsonpath.jsonpath(obj,'$.store.*')print(tag_list)#store里所有的钱price_list = jsonpath.jsonpath(obj,'$.store..price')print(price_list)#第三本书book = jsonpath.jsonpath(obj,'$..book[2]')print(book)#最后一本书book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')print(book)#前两本书book_list = jsonpath.jsonpath(obj,'$..book[:2]')#$..book[0,1]print(book_list)#条件过滤需要在()前加个?#过滤出包含某数值的书book_list2 = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')print(book_list2)#那本书超过了10元book_list3 = jsonpath.jsonpath(obj,'$..book[?(@.price > 10)]')print(book_list3)
获取淘票票地址
# -*- coding: utf-8 -*-import urllib.requestimport jsonpathimport jsonurl = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1636777395914_131&jsoncallback=jsonp132&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'header = {# ':authority':' dianying.taobao.com',# ':method':' GET',# ':path':' /cityAction.json?activityId&_ksTS=1636777395914_131&jsoncallback=jsonp132&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',# ':scheme':' https',# 'accept-encoding':' gzip, deflate, br','cookie':' thw=cn; t=9ef04f246b9aed1c2e1f0236b10986e8; sgcookie=E100iZ7WJj4QacdoVsug7ML%2Box4YrnJrwZ8nuArKTbnd1xnv2%2BmbW%2F3DqKj2VPczwTwq603RD7vZiwdAP%2BkcGVryl%2FP4cYu6Pqfk7c%2BiMNx9Dbw%3D; tracknick=%5Cu91CC%5Cu5965%5Cu9171; _cc_=V32FPkk%2Fhw%3D%3D; cookie2=12e513275306c8a6337fc33148bee081; v=0; _tb_token_=3af35de6f715e; cna=64jtGcprQ3QCAQHAnALV+amn; xlly_s=1; l=eBaPEC-gOW_zmVkUBO5ZPurza77O3IRb4sPzaNbMiInca1Sf9F9cBNCdtZueWdtjgtCAdexrrNYcMRLHR3qM5c0c07kqm07t3xvO.; isg=BE1NmaUEEKNGvYrYowNhWAc3XGnHKoH8QdIFv4_SF-RThm04VXsgzP-Y8BrgRpm0; tfstk=c1e1Bp_yzFY1wc52QlsebdtmW1MVZixSc1ggfSdutMbc-vE1iCvrPc97iEHqDD1..','referer': 'https://dianying.taobao.com/','user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',}request = urllib.request.Request(url=url,headers=header)reponse = urllib.request.urlopen(request)content = reponse.read().decode('utf-8')#split 切割content = content.split('(')[1].split(')')[0]print(content)with open('taopiaopiao.json','w',encoding='gbk') as fp:fp.write(content)obj = json.load(open('taopiaopiao.json'))city_list = jsonpath.jsonpath(obj,'$..regionName')print(city_list)
Bs4
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Title</title></head><body><div><ul><li id ="liao1">张三</li><li id = "l2">李四</li><li>王五</li><a href="" class="a1">里奥奥</a><span>test hahahah</span></ul></div><a href="" title="a2">baidu</a><div id="d1"><span>笑死我了,全是男同</span></div><p id="wuhu" class="qwq">wdnmd</p></body></html>
from bs4 import BeautifulSoup#通过解析本地文件,来将bs4的基础语法进行讲解#默认打开的文件的编码格式是gbk,所以需要指定编码soup = BeautifulSoup(open('test.html',encoding='utf-8'),'lxml')#1.根据标签名字查找节点#注意:找到是第一个符合条件的数据print(soup.a) #查到第一个a标签的内容print(soup.a.attrs) #展示标签的属性和属性值#bs4的一些函数# 1.find#和soup.a差不多,不过可以使用一些条件print(soup.find('a'))print(soup.find('a',title="a2"))#根据class的值找到对应的标签对象,class是内置关键字,需要加个下划线print(soup.find("a",class_="a1"))# 2.find_all#返回一个列表,并且返回所有a标签print(soup.find_all('a'))#以列表表示,同时查找a和span标签print(soup.find_all(['a','span']))#查找所有的li标签数据,并且只查找显示前两位print(soup.find_all('li',limit=2))# 3.select(推荐)#select返回列表,并且返回多个数据print(soup.select('a'))#可以通过 “.” 代表class。该用法为类选择器print(soup.select('.a1'))#可以通过 “#” 代表idprint(soup.select('#liao1'))#属性选择器#查找到li标签中有id的标签print(soup.select('li[id]'))#查找到li标签中id为liao1的标签print(soup.select('li[id="l2"]'))#层级选择器#后代选择器#找到div下面的liprint(soup.select('div li'))#子代选择器#获取某标签的第一级子标签#注意:很多的计算机编程语言中,不加空格会出现问题print(soup.select('div > ul > li'))#找到a标签和li标签的所有对象print(soup.select('a,li'))#节点信息#获取节点内容obj = soup.select('#d1')[0]#如果标签对象中只有内容,string和get_text都可以使用。#如果标签对象中除了内容,还有标签,那么string就获取不到数据 而get_text可以# print(obj.string)print(obj.get_text()) #推荐#节点的属性obj = soup.select('#wuhu')[0]#name 是标签的名字#attrs将属性值作为字典返回print(obj.name)#获取节点的属性obj = soup.select('#wuhu')[0]print(obj.attrs.get('class'))print(obj.get('class'))print(obj['class'])
爬取星巴克数据
from bs4 import BeautifulSoupimport urllib.request#目标网站地址base_url = 'https://www.starbucks.com.cn/menu/'#模拟浏览器访问数据response = urllib.request.urlopen(base_url)#获取数据content = response.read().decode('utf-8')#通过解析,来将bs4的基础语法进行讲解soup = BeautifulSoup(content,'lxml')obj = soup.select('div > ul > li > a > strong')for i in range(len(obj)):print(obj[i].get_text())
selenium
1比1模仿浏览器访问页面,是有界面的
import urllib.requestfrom selenium import webdriver#创建浏览器操作对象path = 'msedgedriver.exe'#创建浏览器browser = webdriver.Edge(path)#访问网站base_url = 'https://www.jd.com'#打开页面browser.get(base_url)#page_source获取网页源码content = browser.page_sourceprint(content)
selenium的元素定位
from selenium import webdriver#设置文件路径path = 'msedgedriver.exe'#设置模拟浏览器browser = webdriver.Edge(path)base_url = 'https://www.baidu.com'#访问网页browser.get(base_url)#元素定位#根据id找到对象 ★button = browser.find_element_by_id('su')print(button)#根据标签属性的属性值来获取对象的button = browser.find_element_by_name('wd')print(button)#根据xpath语句来获取对象 ★button = browser.find_element_by_xpath('//input[@id="su"]')print(button)#根据标签名字来获取对象button = browser.find_element_by_tag_name('input')print(button)#使用bs4的语法来实现的 ★button = browser.find_element_by_css_selector('#su')print(button)#根据a标签的名称获取对象button = browser.find_element_by_link_text('直播')print(button)
selenium获取元素信息
from selenium import webdriver#设置文件路径path = 'msedgedriver.exe'browser = webdriver.Edge(path)#设置访问的网页base_url ='http://www.baidu.com'#开始访问网页browser.get(base_url)#获取元素一些变量input = browser.find_element_by_id('su')#获取元素属性print(input.get_attribute('class'))#获取元素文本a = browser.find_element_by_link_text('新闻')print(a.text)#获取元素tag标签print(input.tag_name)
selenium交互
from selenium import webdriverimport time#创建浏览器对象path = 'msedgedriver.exe'#设置需要用到的浏览器类型browser = webdriver.Edge(path)#设置需要打开的urlbase_url = 'https://www.baidu.com'browser.get(base_url)#当打开浏览器时休息两秒time.sleep(2)#获取文本框的对象input = browser.find_element_by_id('kw')#在文本框输入周杰伦input.send_keys('周杰伦') #发送一个值为周杰伦time.sleep(2)#获取百度一下的按钮button = browser.find_element_by_id('su')#点击按钮button.click()time.sleep(2)#滑倒底部js_bottom = 'document.documentElement.scrollTop=100000'browser.execute_script(js_bottom)time.sleep(2)#获取下一页那妞next_page = browser.find_element_by_xpath('//a[@class="n"]')#点击下一页next_page.click()time.sleep(2)#回到上一页browser.back()time.sleep(2)#再次回去browser.forward()time.sleep(2)#退出browser.quit()
handless
没有界面
from selenium import webdriverfrom selenium.webdriver.chrome.options import Options#封装的handlessdef share_browser():chrome_options = Options()chrome_options.add_argument('--headless')chrome_options.add_argument('--disable-gpu')# path是你自己的浏览器路径path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'chrome_options.binary_location = pathbrowser = webdriver.Chrome(chrome_options=chrome_options)return browserbrowser = share_browser()base_url = 'https://www.baidu.com'browser.get(base_url)#截图browser.save_screenshot('baidu.png')
request
r.text 获取网页源码r.encoding 访问或定制编码方式r.url 获取请求的urlr.content 响应的字节类型r.status_code 响应的状态码r.headers 响应的头信息
import requests#网页网址base_url = 'https://www.baidu.com'response = requests.get(url=base_url)#设置相应的编码格式response.encoding = 'utf-8'#一个类型和一个属性print(type(response))#以字符串的形式来返回网页的源码print(response.text)print(response.url)print(response.content)print(response.status_code)print(response.headers)
request_get请求
import requests#网页的路径url = 'http://www.baidu.com/s?'#请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"}#跟在后面的数据data = {'wd': '北京'}#使用get请求,url:地址 params:后面跟着的数据 header:请求头response = requests.get(url=url, params=data, headers=headers)#获取内容content = response.textprint(content)
request_post请求
import requestsimport jsonbase_url = 'https://fanyi.baidu.com/sug'header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"}data = {"kw": "eye"}# url 请求地址# data 请求参数# kwargs 字典response = requests.post(url=base_url, data=data, headers=header)content = response.textobj = json.loads(content)print(obj)
requests_验证码登录
# 通过登录进入到主页面import requestsfrom bs4 import BeautifulSoupimport urllib.request# 登录页面的url地址base_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"}# 获取页面的源码response = requests.get(url=base_url, headers=header)content = response.text# print(content)# 解析页面源码 然后获取 __VIEWSTAT,__VIEWSTATEGENERATORsoup = BeautifulSoup(content, 'lxml')# 获取__VIEWSTATviewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')# 获取VIEWSTATEGENERATORviewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')# 获取验证码图片code = soup.select('#imgCode')[0].attrs.get('src')code_url = 'https://so.gushiwen.cn' + code# urllib.request.urlretrieve(url=code_url, filename='yzm.jpg')#通过requests的方法,session,能使请求变为一个对象session = requests.session()#验证码url的内容response_code = session.get(code_url)#此时不能用text,要用二进制 contentcontent_code = response_code.content#wb 将二进制写入到文件with open('code.jpg','wb')as fp:fp.write(content_code)# 获取验证码之后,下载本地,然后手动输入验证码code_name = input("请输入你的验证码:")# 点击登录url_post = "https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx"data_post = {"__VIEWSTATE": viewstate,"__VIEWSTATEGENERATOR": viewstategenerator,"from": "http://so.gushiwen.cn/user/collect.aspx","email": "1182350036@qq.com","pwd": "mly118235","code": code_name,"denglu": "登录",}#此时不能用requests,必须用sessionresponse_post = session.post(url=url_post,headers=header,data=data_post)content_post = response_post.textwith open('gushiwen.html','w',encoding='utf-8')as fp:fp.write(content_post)

若有收获,就点个赞吧
0 人点赞
